一、大数据集下的梯度下降
1.2 大数据集的使用
如果我们有一个低方差的模型,增加数据集的规模可以帮助你获得更好的结果。但是大数据集意味着计算量的加大,以线性回归模型为例,每一次梯度下降迭代,我们都需要计算训练集的误差的平方和,当数据集达到上百万甚至上亿的规模时,就很难一次性使用全部的数据集进行训练了,因为内存中放不下那么多的数据,并且计算性能也达不到要求。
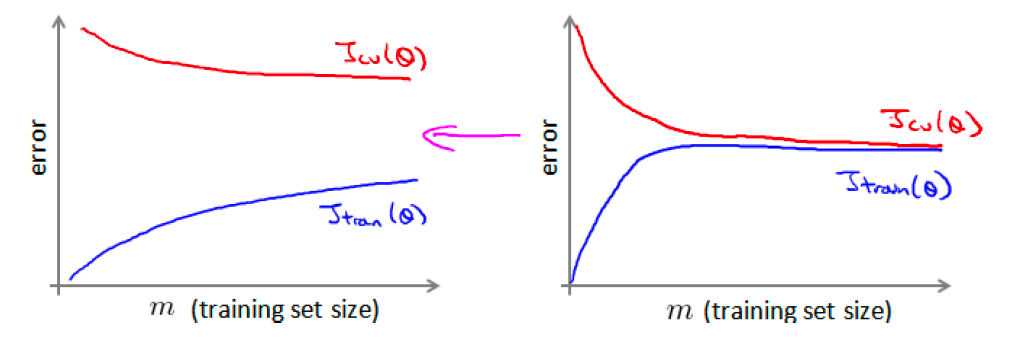
不过,在使用大数据集训练模型之前,首先应该做的事是去检查一个这么大规模的训练集是否真的必要,也许我们只用1000 个训练集也能获得较好的效果,我们可以绘制学习曲线来帮助判断,如果训练误差和验证误差如下图左所示的趋势,那么加大数据集就很可能达到右边的效果,则加大数据集是必要的。
1.2 随机梯度下降
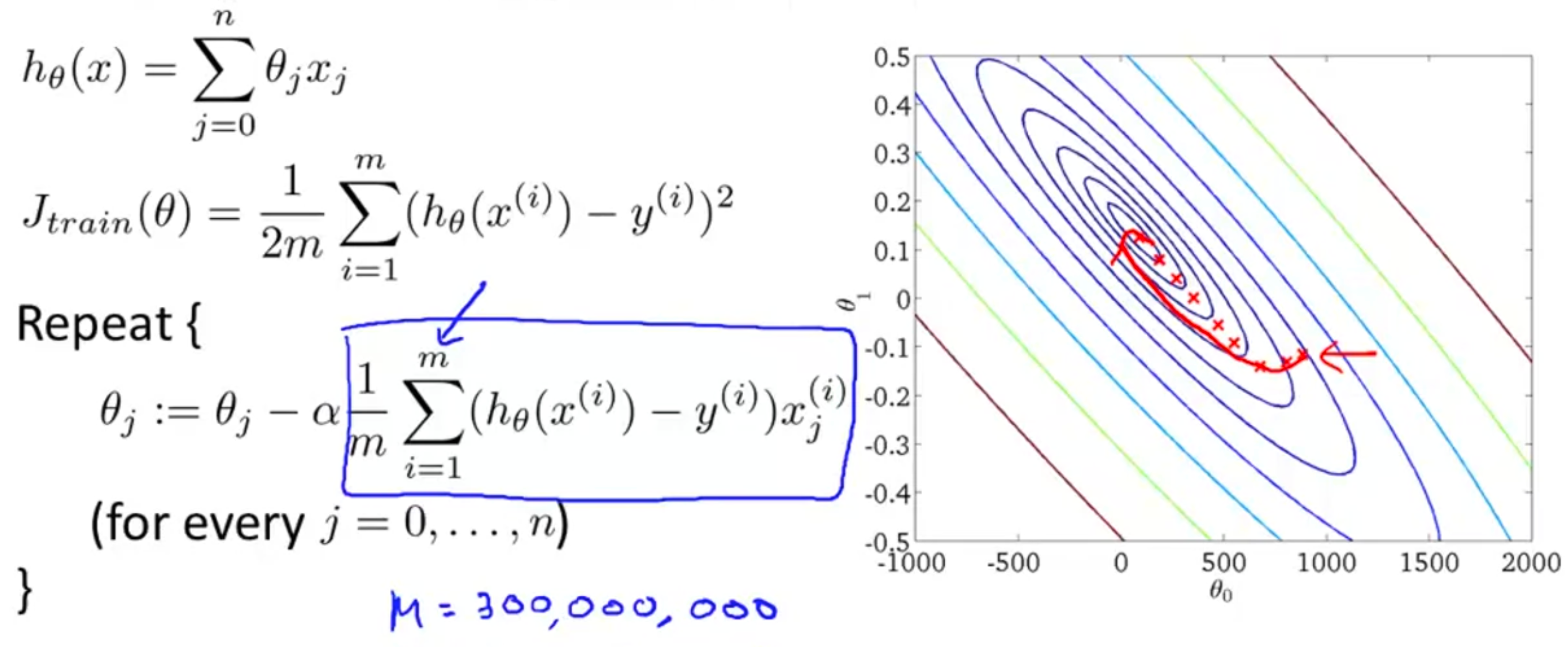
回顾线性回归中的梯度下降流程,即不断重复求偏导并更新对应
下面给出随机梯度下降的流程:

可以看到,和梯度下降不同,随机梯度下降先将数据集进行打乱,然后每次只使用数据集中的一个样本进行更新参数,然后遍历整个数据集。
1.3 小批量梯度下降
下图是小批量梯度下降法的流程,与随机梯度下降不同的是,它选取数据集的一部分进行参数更新,而不是用每个样本更新一次。这样的好处是,使用合适的向量化,可以加快运算速度。一般

1.4 随机梯度下降法的收敛方法
在批量梯度下降中,我们可以令代价函数
在随机梯度下降中,我们在每一次更新
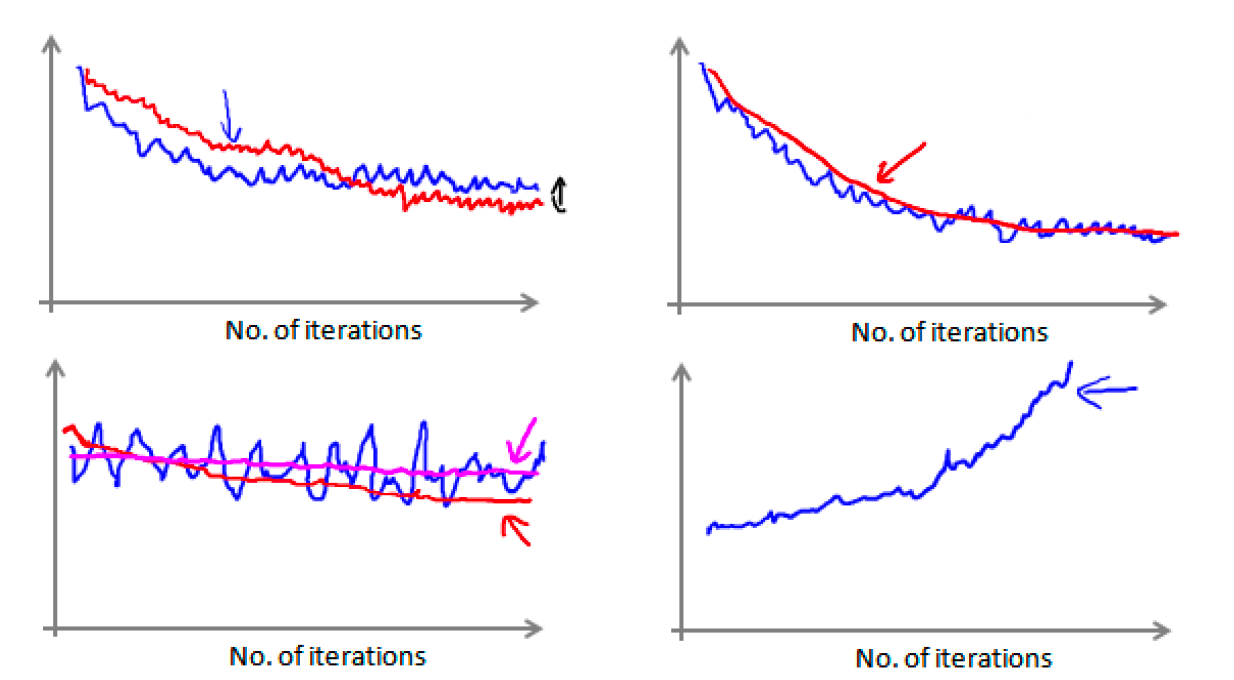
对于上面左下方的图,我们得到一个颠簸不平但是不会明显减少的函数图像(蓝线)。我们可以增加
我们也可以令学习率随着迭代次数的增加而减小,例如令:
二、高级技巧
2.1 在线学习
现在来讨论一种新的大规模的机器学习机制,叫做在线学习机制。在线学习机制让我们可以模型化问题。如果你有一个由连续的用户流引发的连续的数据流,进入你的网站,你就可以使用在线学习机制,从数据流中学习用户的偏好,然后使用这些信息来优化一些关于网站的决策(比如大数据杀熟)。
在线学习算法指的是对数据流而非离线的静态数据集的学习。许多在线网站都有持续不断的用户流,对于每一个用户,网站可以通过在线学习,在不将数据存储到数据库中便顺利地进行算法学习。在线学习的算法与随机梯度下降算法有些类似,我们对单一的实例进行学习,而非对一个提前定义的训练集进行循环。其流程如下图所示:

一旦对一个数据的学习完成了,我们便可以丢弃该数据,不需要再存储它了。这种方式的好处在于,我们的算法可以很好的适应用户的倾向性,算法可以针对用户的当前行为不断地更新模型以适应该用户。
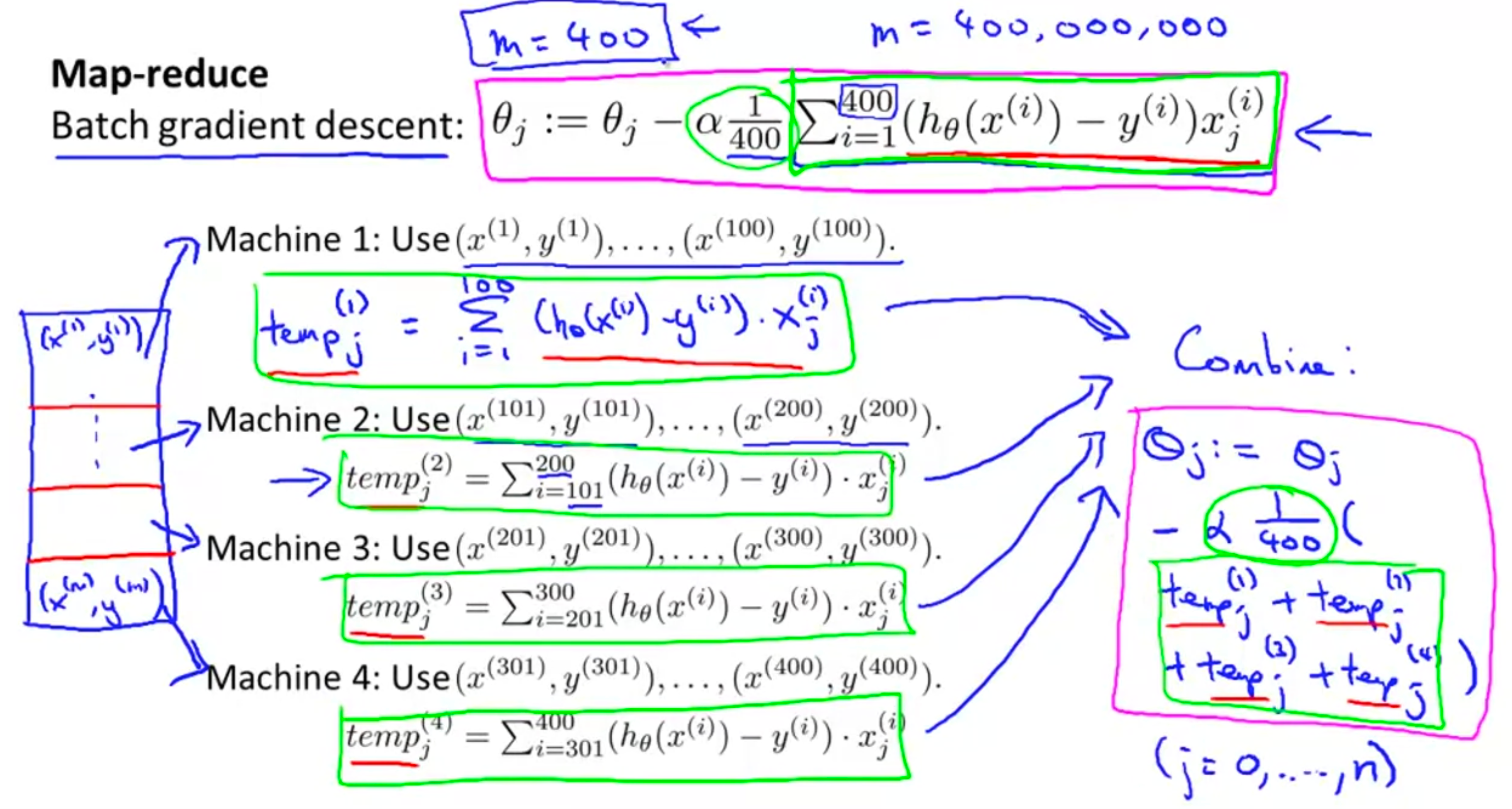
2.2 映射化简和数据并行
如下图所示,假设我们的数据集中有400条数据,我们可以将其分成4等分,分别在4台计算机中并且计算梯度,然后最后将计算出来的梯度汇总,这样就能提升4倍的速度。只要某个机器学习的算法满足起主要的运算量来自于某种求和,那么你就可以将这个求和拆分并行化处理。