0. 前言
前两天CVPR2024出结果了,分数从443变成444,顺利接收,作为读博的第一篇工作,历程也是比较坎坷,经历了MM2023被拒到转投CVPR2024接收,CVPR系列文章也写了两篇,CVPR2024投稿收获 和 CVPR2024 Rebuttal 收获,不过碍于没出最终结果,也就没有深入分析这篇工作,现在就来做个结尾吧。
论文目前可见 Arxiv 版本:https://arxiv.org/abs/2312.12478,初次工作,整体较为粗糙,欢迎交流指正。Code目前半开源(还需要整理一下,目前的开源版本可能跑不通)
1. Idea的由来
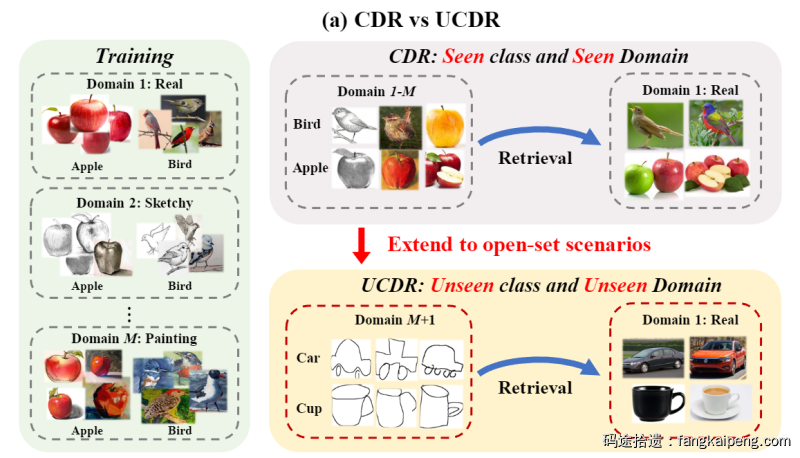
这篇工作严格来说是从23年初开始进行的,当时Target MM2023,同时顺带着完成毕设。方向是组里的一位博士师兄找的,做的是一个开集跨域的检索任务UCDR( Universal Cross-Domain Retrieval [1]在多个数据域中训练,测试使用来自未知域和未知类的样本进行检索,如下图所示),算是比较小众,竞争不是很激烈(这也是CVPR能接收的原因之一)且不耗费计算资源,非常适合我这样的小白试水。
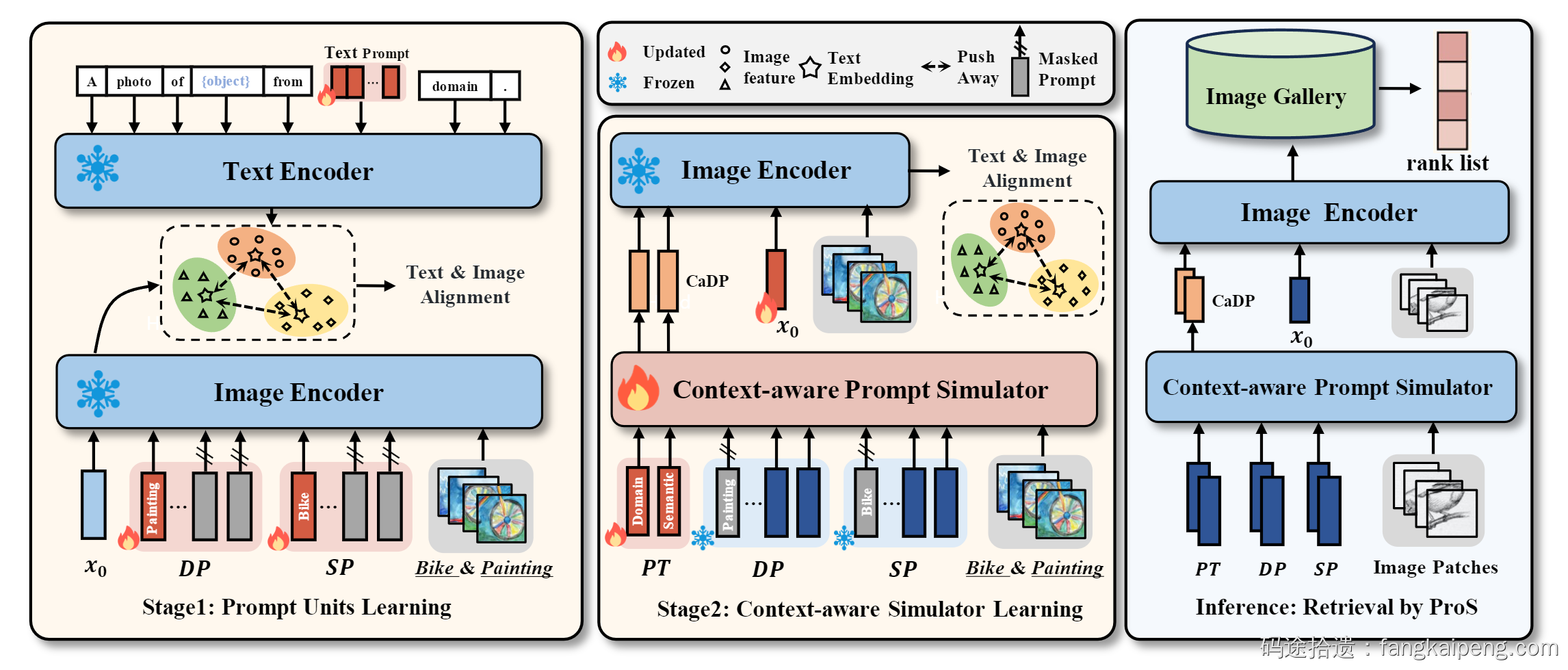
于是我便着手调研,看了仅有的两篇相关工作,一篇用ResNet作为Backbone,一篇用的是ViT。当时大火的CLIP又是一个Zero-Shot能力超强的模型,于是便想着利用CLIP的能力做点事情。首先,用CLIP直接按照任务的Setting Zero-Shot 测了一下,发现就直接吊打SOTA,相当惊艳。然后进行了Fine-Tuning,发现性能没有想象中的提升,分析原因可能是由于微调破坏了模型初始的参数 [2],导致其泛化能力受损。然后就寻找缓解泛化能力受损的办法,当时主流的方法有Adapter、Linear Probing以及Prompt Tuning,思路都是冻住预训练模型的参数,然后增加一些新的可训练参数,以此保证预训练的权重不会被更新。对这些方法都进行了复现,发现Prompt Tuning效果更好,同时在当时也是比较新的技术,比较热门。于是思考如何借助Prompt Tuning挖掘CLIP的潜力,以适配UCDR任务。经过一番调研,大致清楚了目前Prompt Tuning 的主流做法,发现大部分Prompt在训练后就不会再改变了,因此虽然Prompt Tuning可以很好的迁移预训练模型以适配某个下游任务,但缺少泛化性。虽然CoCoOp [3] 提出了一个Meta-Net,用于根据输入的图片修改Prompt,以此提高泛化能力,但不能很好适配UCDR任务,因为UCDR需要同时实现域泛化和类泛化。于是,我就在想能不能针对不同源域和不同的可见类分别训练Domain Prompt和Class Prompt。然后再训练一个模型,将这些Prompt以及样本的embedding作为输入,然后输出与样本对应的Domain Prompt和Class Prompt。在检索的时候,输入一张来自未知域和未知类的样本,也能够泛化出对应的Domain Prompt和Class Prompt。整体框架如下所示,分为两步训练,首先训练两种Prompt,然后训练用于泛化未知Prompt的模型(Context-aware Prompt Simulator)。经过几番折腾,成功实现,效果比较理想,2023年4月份完成了实验和论文,投稿MM。
2. 从被拒到接收发生了什么?
然而,第一次投稿,难免会有很多问题,其中写作当属最大的问题。当时Rebuttal的时候,3位审稿人一个borderline Accept,一个Weak Accept,一个Reject(Very Confident)。虽然使用大量篇幅回答了Reject的Reviewer,但他还是坚持原来的观点,最终被拒。然而这位审稿人并没有看懂UCDR的设定,也没理解我们提出的方法,好几个问题问的都不合理。不过这也是因为我在写作的时候没有很好的说明我们的任务设定,导致审稿人的误解和困惑。
转投CVPR期间,在另外一位师兄(老师)的指导下,对文章进行了改头换面。主要对方法进行了调整,使得在性能不变的情况下,大幅轻量化了方法。同时,增加了一些图表,丰富实验,修改写作思路,对全文进行了重构。下面针对写作,挑一些核心的变动对比一下:
2.1 Title
- MM版:Learning to Prompt Adaption for Universal Cross-Domain Retrieval
- CVPR版:ProS: Prompting-to-simulate Generalized knowledge for Universal Cross-Domain Retrieval
CVPR版的更能体现论文的主要创新点 Prompting-to-simulate Generalized knowledge ,同时Introduction也围绕这句话展开。MM版本就用了一个Adaption,表达不够清楚,不仅容易带来误解,而且也不能突出论文的思想。
2.2 Introduction
写作思路其实主要就体现在Introduction上,MM版本存在表述不清,重点不够突出,没有主线的问题。
Introduction的第一段,一般介绍本篇工作做的是什么任务。由于我的任务比较小众,即使是相近方向的审稿人也大概率没见过,因此如何让审稿人快速理解任务Setting非常关键。MM版写的就不是很好,当时想的是从任务的适用场景出发来引出任务,以此突出任务的重要性,但这样没能很好的说明任务的Settin。CVPR版本从CDR任务出发(一个相对热门的任务),首先简单介绍了一下CDR任务,并指出存在的限制性。顺理成章的引出我们的任务UCDR,是用来改善CDR在某些场景下的限制。这一写法,相当于借助一个审稿人大概率熟知的任务作为跳板,同时配合任务设定的示意图,可以让审稿人快速搞清我们要解决什么样的任务。
MM版本:
In recent years, traditional image retrieval techniques achieves satisfying results thanks to the rapid development of deep learning [26 , 29 , 47 , 48]. However, they assume that training and test data are independent and identically distributed, resulting in the difficulty to apply such techniques in real-world scenarios, e.g.,e-commerce. As categories of products are constantly updated, retrieval models encounter varieties of unseen products, leading to a significant performance drop [40 , 43 ]. Therefore, deploying retrieval models in open-set scenarios becomes a rising topic, where Universal Cross-Domain Retrieval (UCDR) is the most challenging one [30].
CVPR版本:
Cross-Domain Retrieval (CDR) is an important task in Information Retrieval (IR) systems that utilizes data from one domain (\eg Infograph, Sketch) as a query to search semantically similar examples in another domain (\eg natural image). Despite achieving promising results, existing methods heavily follow a close-set learning setting, where domains and categories in both training and testing data are pre-defined. Such evaluation limiting the model to the training samples and unable to tackle the open-set applications such as e-commerce search and recommendation, where searched product not only comes from various new domains (\eg styles) but is also accompanied by the emergence of new categories. Towards this goal, one emerging research direction is proposed, namely Universal Cross-Domain Retrieval (UCDR), shown in Fig.1(a), for performing well under generalized test scenarios, where test data may belong to strictly unknown domains and categories.
后面就是介绍UCDR任务的难点是什么,现有方法怎么做,存在什么问题,然后引出本文的方法解决问题。相比MM版本,CVPR版本使用了一个性能比较图,将不同种类的方法在UCDR上的性能和参数量表现在了一张图里,可以很直观的展示本文方法的优越性。同时,结合实验的数据,在阐述Motivation的时候,可以更让人信服(比如我认为A比B好,原因是C,即使理由C再合理,也比不过直接放实验数据验证,事实胜于雄辩)。
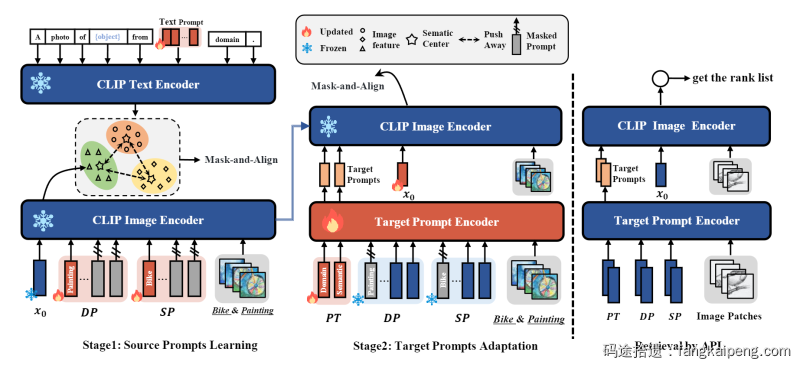
2.3 图的美观性
下图是MM版本的方法框架图,在改图的时候,翻阅了很多CVPR的论文,总结了比较适合CVPR的风格,然后模仿绘制了CVPR版本的框架图(见上文)。比较起来,CVPR版本的更为紧凑,空间利用率更高,没有过多的留白。
3. 一些思考
第一篇工作,虽然经过了两轮打磨,个人感觉还是比较粗糙,在这期间学到了很多,但仍然不具备独立科研的水平,还有很多需要学习的地方。
首先是思考问题不够深入,没能看到本质问题。引用一位博士师兄的话:科研分为三个层次,第一层是学会简单的A+B,借鉴不同的方法,解决某个问题;第二层是能发现某个领域的本质问题,并尝试解决;第三层是会挖坑,也就是开创新的科研分支,称为领头人。希望我能尽快向第二阶段靠拢,做出更加Soild的工作。同时,科研敏感性也非常重要,要紧跟潮流,有自己的思考和判断。典型就是CoOp[4]这篇工作,Prompt这一概念其实最早来自NLP领域,ChatGPT的出现带火了这一概念。CoOp是首个将Prompt Tuning用于CV领域的工作,方法和思想非常简单,Code实现也很简单,但是就称为了这一方向的奠基之作,目前收获了上千的引用。还比如CoT(思维链)刚出的时候,很快就有人跟进,搞出了TOT(思维树)和GOT(思维图)。这也是非常直觉的想法,拼的就是科研敏锐度和手速。
其次,一项工作的论文是需要深思熟虑后,经过反复打磨才可能勉强及格的,并不是和写博客一样,想到啥写啥。要站在读者的角度,考虑如何讲好一个故事?如何用通俗易懂的表达方式(包括语句和图表),最大程度展示工作的贡献和创新,语言的艺术非常重要。
最后,如何提高实验和Coding的效率?由于没有系统性学习过软件工程方面的东西,代码写的经常比较凌乱,管理的也不是很好。经常会出现实验跑废的情况(设置错了,缺少了一些点东西,或者完全没必要的实验)。以及代码的实现过程中,如何优雅的进行各功能的测试等等。慢慢学习,慢慢积累吧!
希望可以去西雅图参会,希望一切顺利!




cvpr之路之艰辛,博主牛犇! 向博主学习!