
0. In the Beginning
虽然是 CVPR “首投”,但实际上是拒稿转投,前任是MM,这才是我的科研生涯中的第一次投稿,结局是WA+BA+Re顺利被拒。其实当时就想写这篇博客的,一方面因为拖延症一直拖着,另一方面也是因为当时没有清晰认知被拒的原因,只是简单归结为“审稿人误解了,运气不好”,所以不知道写啥。一篇MM的拒稿胆敢碰瓷CVPR,实属有点不自量力,所以投完稿后心态非常平静,没有投MM那次焦虑。不过,此次投稿在Z老师的帮助下,方法上进行了微小的优化,论文也基本重写了一次,收获颇丰,算是摸到了一点科研的门边边。总的来说,一个好的科研产出:首先需要一个简单而又有效的方法,同时有明确合理的动机,实验需要充分的同时保证都是必要的,具备上述三点能使你写论文时减少很多痛苦(我就是反面教材,否则你就会体会到什么叫 shit 上雕花),在写作时需要保证逻辑连贯合理,语句准确简洁,图表整洁易懂,用一个能说服读者的故事包装你的方法。
Warning:本文主要整理CVPR转投过程中,修改论文时的一些收获,自知水平有限,难免有疏漏瑕疵,欢迎评论区指出~
1. Title
题目的格式五花八门,主要包含两个方面:你解决的是什么任务?你使用了/提出了什么技术,创新点是什么? 一般不要超过12个单词,比较依靠创造力。
常见的格式为:ABC(方法名缩写):Axx Bxx Cxx (方法全称)for XXX(任务名),例如:
ProD: Prompting-To-Disentangle Domain Knowledge for Cross-Domain Few-Shot Image Classification
Position-Guided Text Prompt for Vision-Language Pre-Training
或者反过来:XXX(任务名) by/via XXX (方法名),例如:
Open-Set Fine-Grained Retrieval via Prompting Vision-Language Evaluator
或者,如果没有针对某个下游任务,而是提出一个通用性的方法,就可以只提方法名:
Diversity-Aware Meta Visual Prompting
以上都是方法类的文章,还有一些探究性的文章,题目中往往就包含他们的发现:
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution
也有一些 “现眼包” 的题目,往往一眼看不出是在干啥,强者专属取名方法,也有使用问句的形式:
Attention is All you Need
Cap4Video: What Can Auxiliary Captions Do for Text-Video Retrieval?
Can multi-label classification networks know what they don’t know?
这种夺人眼球的“标题党”一般对自己的工作很有信心,影响力很大,不然会适得其反。
2. Abstract
Abstract是整篇论文的重中之重,一般审稿人都会先看Abstract,所以Abstract的好会很大程度决定了审稿人对这篇论文的第一印象。Abstract的一句话基本对应于Introduction的一段话,一句话只讲一件事,并且每句话之间需要做到逻辑连贯,合情合理。
以提出一个方法去解决一个任务的论文为例 [1]:
This paper considers few-shot image classification under the cross-domain scenario, where the train-to-test domain gap compromises classification accuracy. To mitigate the domain gap, we propose a prompting-to-disentangle (ProD) method through a novel exploration with the prompting mechanism. ProD adopts the popular multi-domain training scheme and extracts the backbone feature with a standard Convolutional Neural Network. Based on these two common practices, the key point of ProD is using the prompting mechanism in the transformer to disentangle the
domain-general (DG) and domain-specific (DS) knowledge from the backbone feature. Specifically, ProD concatenates a DG and a DS prompt to the backbone feature and feeds them into a lightweight transformer. The DG prompt is learnable and shared by all the training domains, while the DS prompt is generated from the domain-of-interest on the fly. As a result, the transformer outputs DG and DS features in parallel with the two prompts, yielding the disentangling effect. We show that: 1) Simply sharing a single DG prompt for all the training domains already improves generalization towards the novel test domain. 2) The cross-domain generalization can be further reinforced by making the DG prompt neutral towards the training domains. 3) When inference, the DS prompt is generated from the support samples and can capture test domain knowledge through the prompting mechanism. Combining all three benefits, ProD significantly improves cross-domain few-shot classification. For instance, on CUB, ProD improves the 5-way 5-shot accuracy from 73.56% (baseline) to 79.19%, setting a new state of the art.
这类文章的Abstract:
- 开头都先一句话介绍自己的任务(定义和挑战是什么)。
- 下一句介绍现有工作如何解决前一句中提到的调整,但存在什么缺陷。(这一句有时候可以省略,如上例)
- 紧接着一句话,为了解决上述的缺陷,我们提出xxxx(介绍我们的方法是什么)
- 接着2-3句话具体介绍自己的方法,创新点在哪。
- 然后一句话介绍实验结果如何
- 最后附上匿名的开源代码链接(为了盲审)
大致的思路就是上面这样,但也需要具体情况具体分析,灵活应对。比如我这次投稿的工作,没有发现现有工作的问题,而是直接尝试使用CLIP去解决问题,发现效果不错,但仍有提升空间,然后加以改进。所以,我在第一句介绍完任务后,没有介绍现有工作,直接说最近预训练大模型是什么,在某些领域取得不错的成绩,但是仍然存在xxx问题。这样就避免了凭空捏造一个“缺陷”导致逻辑不通的问题(但这样是不好的,好的科研工作应该是Problem-Driven的)。言而总之,Abstract作为整篇故事的精简,需要保留核心内容的同时表述清晰,言之有理。
在写Abstract之前,最好理清故事脉络,确保逻辑简单,比如你的方法如果是从A发现B的问题,然后从B又发现C,C又发现D,最后从D引出你的方法。你在写的时候不能介绍那么长的逻辑链,一方面容易绕晕读者,另一方面容易挖坑(你怎么能证明从A到B的逻辑严丝合缝?)。因此,可选的方法是,直接概括ABCD中的问题,将问题并行分点介绍,而不是串行A到B到C到D。或者省略中间的一些部分,直接从A到D。
可以先写个中文的大纲,然后和别人广泛交流,听取别人的意见,一个人闭门造车往往会陷入局限。
3. Introduction
Introduction其实就是Abstract的详细版本,基本上Abstract一句话对应Introduction的一段话,但也不是绝对。在写的时候需要把握一个原则:一段话只有一个中心思想。一般来说,第一句话承接上一段,并抛出一个新话题,结尾对开头提出的话题进行总结,首尾两句话需要涵盖整段的精华,因为审稿人很可能一段只看这两句话,其他都一扫而过。
第一段一般介绍任务的背景,意义。这里值得注意的是,如果你的任务是一个热门任务,那么就可以直接介绍这个任务是什么。如果你的任务是一个小众任务,Reviewer大概率从来没听说过,那么最好是从一个限制条件更少的更大的任务开始介绍,比如介绍Open-Set Fine-Grained Retrieval,可以先介绍 Fine-Grained Retrieval,然后再引出Open-Set Fine-Grained Retrieval,这样的好处是能更清楚介绍任务的意义和定义。
第二段介绍现有工作,可以从该任务的挑战是什么开始 The core challenge for XXX is XXX. 或者在第一段已经介绍了任务的挑战,那么就直接 Generally, there are two approaches for mitigating the xxx. 简单介绍完现有工作后,点出现有工作的问题,以此作为本段结尾。在介绍现有工作的时候,不用事无巨细的把一个工作的全部细节都介绍,可以选择性的介绍 “对你有价值的”,或者对这些工作进行归类(这个归类最好能引出你后面要揭露的问题),然后提一下每项工作主要使用了什么技术。
第三段顺其自然可以介绍自己的工作,解决了上面提到的问题。首先开头一句话概括自己的方法用了什么技术,针对什么问题,达到了什么目的。然后介绍实现细节,但是需要把握好细粒度,不能太详细也不能太概括,要比Abstract详细,但又不能比Method详细。差不多是,点出方法中的所有模块名称,作用是什么,简单介绍如何训练如何测试,用了什么损失函数等。最后1-2句话讲一下实验结果,实现了多好的性能,验证了什么结论。
最后一块,就是Our main contributions can be summed as follows: ,然后分三点概括贡献,一般第一点是提出了什么方法,第二点是提出的方法能达成什么效果,第三点是进行大量实验验证方法的有效性。
目前看到一个写法感觉很不错,采用自问自答的形式,首先根据现象/实验抛出某个问题/猜想,然后后面为了解决这个问题,提出了xxx。然后再描述这个xxx时也最好可以统一起来,穿成一条线,不太好表述,直接看例子 [6] 的Introduction,文中先提出了一个疑问:
Now that there exist various self-supervisory paradigms besides CLIP, could we adaptively integrate their pre-learned knowledge and collaborate them to be a better few-shot learner?
然后介绍自己提出的方法:
To tackle this issue, we propose CaFo, a Cascade of Fooundation models blending the knowledge from multiple pre-training paradigms with a ‘Prompt, Generate, then Cache’ pipeline.
这篇文章主要贡献就是结合了多个不同的预训练模型解决few-shot问题,所以后面需要介绍每个模块(预训练模型),为了建立“革命统一战线”,作者假定了一个共同“敌人”:prior knowledge,引入CLIP为了 language-contrastive knowledge,引入DINO为了vision-contrastive knowledge,引入DALL-E为了vision-generative knowledge,引入GPT-3为了language generative knowledge。并且这几种Knowledge都进行了加粗,问句进行了斜体,使得文章整体看起来结构分明。
CVPR的论文在Introduction一般都会结合一张图介绍,针对不同文章,不同写法,整理了一下目前有以下几种:
- 与其他方法的pipeline比较图,论文中也会在合适的地方比较,比如在第二段会结合图示介绍现有工作的流程,并揭示问题,然后第三段也会call back这张图,比较自己的方法和现有工作的不同 [2]。
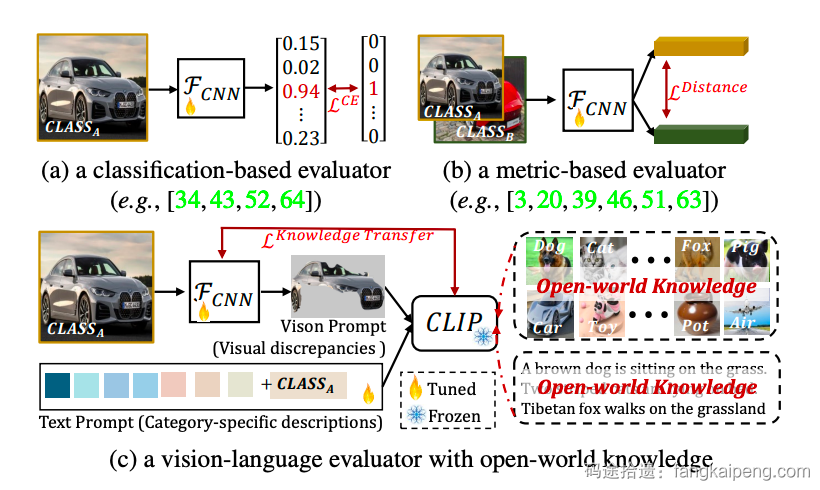
- 也有这种直接介绍本文方法的简图,区别于Method的详细版框架图,一般这里只会画出输入、输出是什么,用简单的形状代替核心的模块,不会展示具体细节的实现,如下图,还用文字点出了核心创新点 [1]。
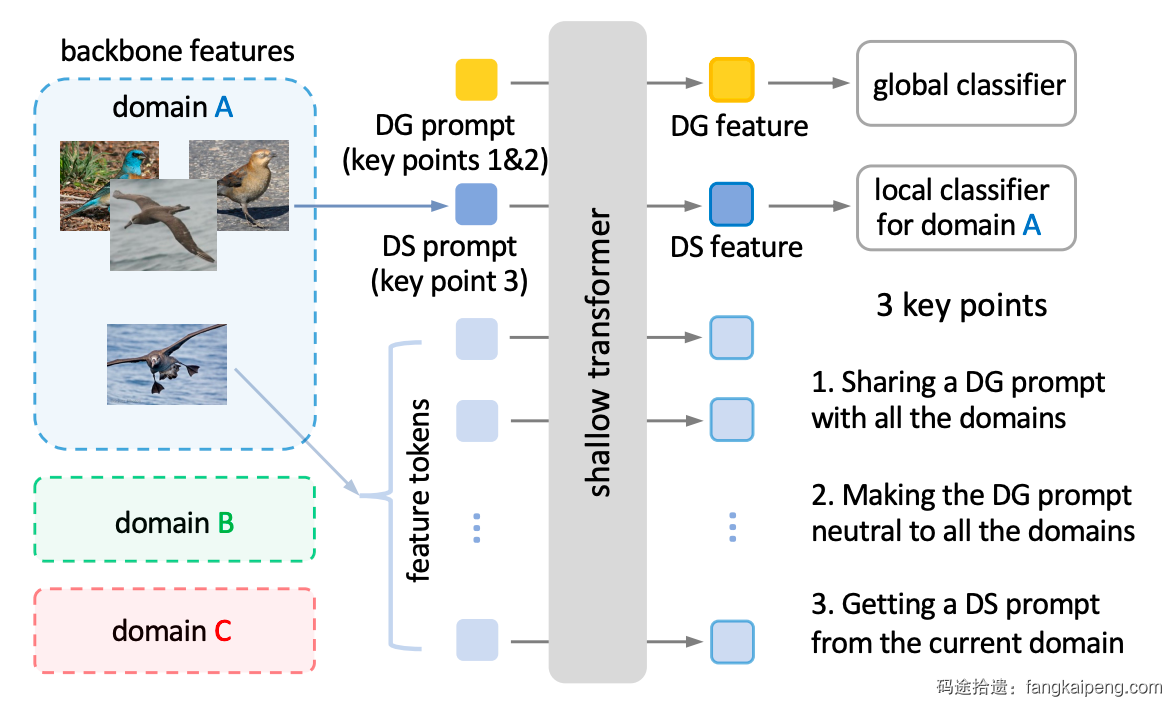
- 还有这种单纯介绍任务是什么的,一般适用于任务比较小众,而且设定比较复杂的情况 [3]。
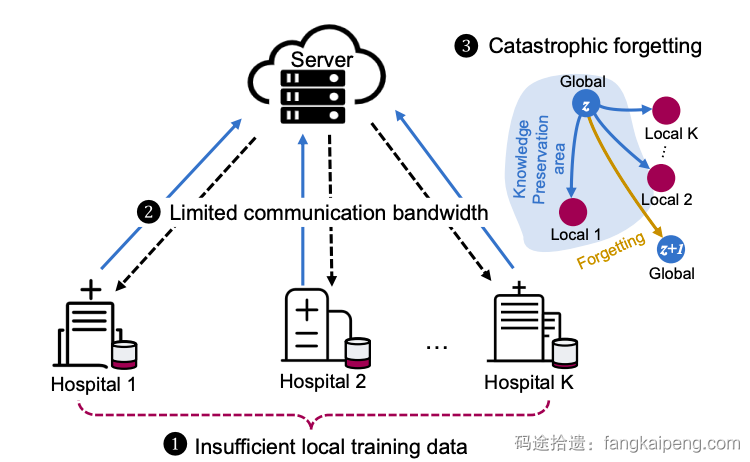
- 还有用实验数据来比较自己的方法和其他方法的,这种也是最常见的图,可以很好展示自己方法的优越性 [4]。
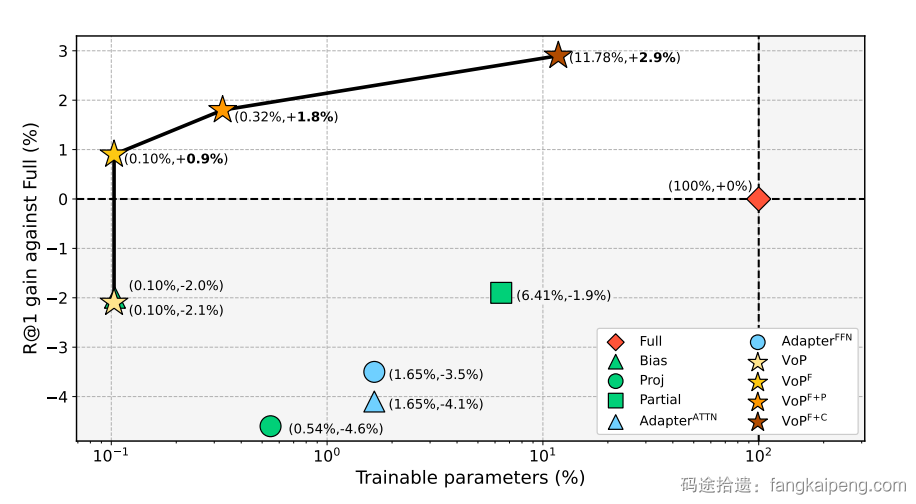
- 此外,还有一些文章将上述的图片进行拼接,以达到不同的论证效果,具体情况具体分析,比较灵活。
4. Related Work
这一节相对来说要求没那么高,就介绍2-4个相关领域的工作就行。结尾的时候主要还是要回归本文的方法,使用Therefore/Differently/To achieve xx,等转折转回介绍本文的贡献和创新,万变不离其宗——推销自己的方法。
5. Method
这一节主要介绍你的工作实现细节,包括任务的形式化定义,一些先导定义,具体的方法设计,训练步骤,如何测试等。一般在最开始先总起介绍一下方法的大体流程,然后cue一下模型框架图,再按子章节的顺序cue一下每个章节会介绍啥,示例如下 [5]:
To this end, we propose PromptCAL, which consists of two synergistic learning objectives: discriminative prompt regularization (DPR) and contrastive affinity learning (CAL). The whole framework is displayed in Fig. 2. Specifically, in the first stage, we learn warm-up representation (in Sec. 3.2) for further tuning. Our DPR loss which is applied to both stages for prompt regularization is also explained. In the second stage, we discover reliable pseudo positives on generated affinity embedding graphs based on semi-supervised affinity generation (SemiAG) mechanism (in Sec. 3.3). Next, we propose our contrastive affinity loss (in Sec. 3.4) on pseudo labels generated by online SemiAG with the support of embedding memories. Lastly, we also present PromptCAL training algorithm in Appendix E.
接着是每个小节,一般分为3小节:
- 第一节 Preliminary,主要介绍 Problem Formulation. 以及各种需要提前说明的东西。
- 第二节 一般以自己的方法名作为章节名,也可以按照模块或者流程等拆成几个小节。具体介绍每个模块的功能,设计,如何训练等。需要注意的是介绍每个模块需要点出Motivation是什么(源于某个实验/猜想/推导等),即为什么要提出这个框架,是为了解决某个问题还是实现某个目标?
- 第三节 介绍测试流程怎么进行。
然后需要注意的是,符号不能二义性,所有图表,描述中的符号都要一致,所有出现过的符号都要解释,有些符号有约定俗成的表示对象,比如
6. Experiment
这一节的写法其实非常“八股”,可以直接套模板,关键还是在于设计好实验,确保论证完整,从各个角度证明方法的有效性,不要留坑。每一个实验的介绍一般遵循:目的(为什么做这个实验,验证/说明什么?)、实验设置(使用什么数据集,进行什么任务,使用什么方法,比较对象是谁)、实验结果在哪、实验结论这四点展开,当然有些实验的设置可能是统一的,就可以在一个地方统一介绍,避免重复。这一章节一般分为四小节来展开:
-
实验设置(Experimental setting),包括数据集,评测指标,实现细节,比较的对象(Baseline)等。
- 数据集的介绍没什么好说的,采用总分结构,先说有哪些数据集,然后分点介绍每个数据集数据量多大,怎么划分,用来测试什么等。
- 评测指标也是可选的,如果你的实验用的都是简单的指标,比如Accuracy这种,就不需要介绍。否则简单介绍一下你的评测指标是什么,怎么计算的。
- 实现细节主要介绍一些超参数的选择,首先介绍模型本身的超参(使用什么Backbone,特征多少维,怎么初始化等),然后介绍训练细节(学习率,epoch,batch size,优化器等)
- Baseline的介绍也是可选的,你可以在主实验这一节介绍(Main Results),主要讲一下你和哪些方法比较了。
-
主实验(Main Results ),就和SOTA比较就行,突出自己方法的优越性。
-
消融实验(Ablation Study),验证提出各个模块的有效性,搜寻合适的超参,控制变量法进行实验。这一部分的实验需要足够的丰富,但每个实验也需要有意义,可以验证/说明你的方法/猜想等。
-
验证模块(或者Loss)时可以从0逐个增加模块(A+B
A+B+C A+B+C+D…),也可以将完整的方法分别去掉每个模块比较(Full w/o A w/o B w/o C…)。这次我使用的是“w/o”大法,但是在描述实验设置和结果的时候有点麻烦,很难兼顾简洁和详细,搜寻好久也没有比较满意的方式,之后遇见好的写法再积累吧。感觉大部分paper都是以逐个增加模块的方式为主,也有很多可以模仿,例句: From the results, we can observe that incorporating each component has a clear contribution:
-
除了模块消融,还有各种超参的消融,可以使用折线图/柱状图等绘制,实验很多的话可以多合一。具体绘图技巧后面会介绍。
-
-
其他实验(比如Qualitative Analysis), 包括各种可视化,比如特征可视化,热力图,生成的图像,检索的结果等等。
为什么说这一节重在实践,写作简单呢,因为可以套很多模板,最不容易犯错的写法是,我们从xx中可以得出以下结论:第一,第二,第三…,例如 [5]:
To vividly illustrate this point, we present the t-SNE [41] visualization results in Fig. 4 (see complete results in Appendix D.3). Here, we directly draw conclusions that:: (a) Naive KNN severely overfits Known and performs poorer (with nearly 2.8% and 7.0% accuracy drops on All and New classes, respectively) than SemiAG, due to its susceptibility to noisy neighborhoods. (b) Affinity propagation is the most consequential component (improving by 8.3% on All and 13% on New), which proves the importance of counteracting adverse effects of false negatives in contrastive loss by retrieving more reliable positives. (c) Retaining SemiCL is beneficial, which, we guess, is because it can push away noisy pseudo positive samples and, thus, prevent overfitting and degenerated solutions. (d) SemiPriori further benefits overall performance by about 5.6% on All and 7% on New, which manifests the importance of incorporating the prior knowledge to calibrate pseudo labels.
7. Conclusion
这一节没什么好说的,比较简单,多模仿几篇就行,基本上是Introduction中Contribution的扩写,讲一下提出了什么方法,用于什么任务,能实现什么功能/目的,最终的效果如何。
8. Additional Considerations
Figures:
画图是可以使用PPT或者visio,在使用PPT画图时,在画图前先设置页面大小为A4纸,如果图片只占半栏就1/2宽的A4纸,导出PDF后使用PDF编辑器裁去空白部分,这样可以保证图片和PPT中的大小一致,一般字体大小为10-12之间,不能超过论文中字号,统一使用Times New Roman字体。
绘制数据可视化图(折线图,柱状图,散点图),一般使用matplotlib绘制,保存为pdf格式,矢量图的分辨率高。一般先用代码绘制初版,美化后确定不变动了,一些小的调整可以通过pdf编辑器完成(比如一些label的位置等)。绘图时有时候不同方法的数值差异很大,在坐标轴上分布不均,导致画出来的图很难看,可以适当使用以下方法:坐标轴截断;对数/指数坐标轴;双坐标轴(适用于一图两种不同值的情况)。
绘制所有图都需要注意美观,配色最好全文统一,各种标签,图注等保证齐全,如果是对比图的画,适当突出自己的方法。一些好看的图 [7]:
Tables:
一般表格以三线表的形式呈现,除了特殊情况,一般不会有竖线。语义不同的列可以断开来使得图片更加清晰(使用\cmidrule(r){} 命令)。此外,需要注意统一表格中的小数位,可以使用Excel刷一下。
8. Thinking
周六下午四点意味着几周的Paper Writing长跑结束,说实话这一项工作拖了差不多一年,实在太久了,没有进行新工作的探索,实属有点疲惫了,改论文的最后几天几乎没了激情。唯一让我坚持下去的就是Z哥一版又一版的修改意见,让我不至于迷茫,也学到了很多。无论最终结果如何,这次的收获还是很多的。
接下来,终于可以开始新工作了!写完这篇博客就去调研,AI的发展实在太快,每天都在出现新东西。希望这次的调研能让我确定最终的研究方向吧(是的,我还没有一个确定的研究方向)。下一项工作希望能真正做到Problem-Driven,并且简单有效吧(这次的工作方法太水,写论文,画框架图的时候真的很痛苦)。同时,打算开始慢慢建立自己的语料库,记录每个章节的一些套话和高频词语。
References
[1] ProD: Prompting-to-disentangle Domain Knowledge for Cross-domain Few-shot Image Classification
[2] Open-Set Fine-Grained Retrieval via Prompting Vision-Language Evaluator
[3] Learning Federated Visual Prompt in Null Space for MRI Reconstruction
[4] VoP: Text-Video Co-Operative Prompt Tuning for Cross-Modal Retrieval
[5] PromptCAL: Contrastive Affinity Learning via Auxiliary Prompts for Generalized Novel Category Discovery
[6] Prompt, Generate, then Cache: Cascade of Foundation Models makes Strong Few-shot Learners
[7] wx公众号:阿昆的科研日常

表示从本科学到研究生(
hhh