1. 引言:人形VLA的“数据困境”
通用人形机器人被视为具身智能的终极形态,但其发展长期受困于“数据孤岛”难题——不同硬件平台、任务场景和传感器差异导致机器人数据碎片化。此外,相比于机械臂,人形机器人的数据采集更耗时费力,且存在较高损坏风险,真机数据采集代价极高。缺少大规模、高质量的人形机器人数据,难以支撑大规模模型训练,使得人形VLA发展变得遥不可及。在英伟达GTC大会上最新开源的GR00T N1模型,以“数据金字塔”策略破局,通过融合人类行为视频、合成轨迹与真实机器人数据,构建了首个支持跨具身(Cross-Embodiment)的人形VLA基础模型。其双系统架构(System 2 VLM 推理 + System 1DiT动作生成)不仅实现了从“感知-决策-控制”的端到端优化,更在仿真与真实场景中展现了惊人的数据效率——仅需10%的标注数据即可超越传统方法。这一突破为低成本、高泛化的人形机器人落地按下加速键。本文将从数据获取,训练策略,实验结果等方面,对GR00T N1实现技术展开分析。
论文链接:https://d1qx31qr3h6wln.cloudfront.net/publications/GR00T_1_Whitepaper.pdf
开源数据:https://huggingface.co/datasets/nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim
2. “快与慢”:双系统架构的人形VLA
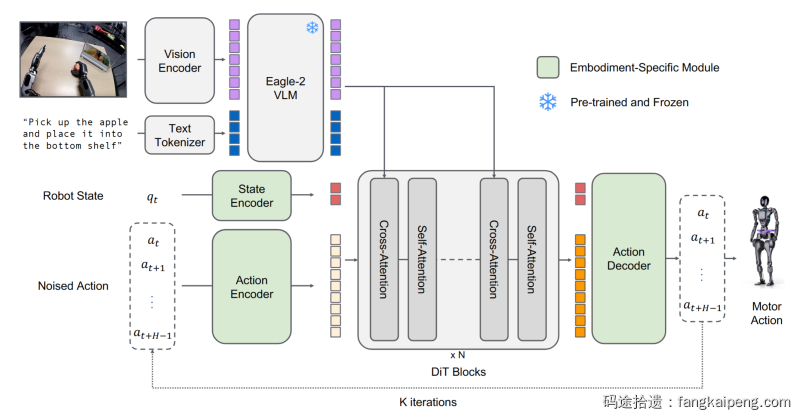
GR00T N1在模型架构设计上并没有很大的创新,其采用了一个双系统协同的架构:上层模型负责处理复杂、低频的推理任务,下层模型负责处理精确、高频的机器人控制,这在近期的Figure AI Helix [1]和Gemini Robotics[2]都有体现,笔者认为这可能是未来VLA的最终形态。在具体实现上,GR00T N1包含三个主要部分:
- State and Action Encoders: 为每个具身实体提供独立的MLP编码器,解决不同机器人的State和Action维度差异问题,将其映射到统一潜空间,然后将其作为后续模型的输入。
- Vision-Language Module (System 2): 基于预训练的 Eagle-2 VLM 模型,输入多视角图像(image)和语言指令(text),生成包含空间语义的中间表征(latent embeddings),GR00T-N1-2B 使用LLM Transformer第12层的表征。
- Diffusion Transformer Module (System 1):基于流匹配(flow-matching)的Diffusion Transformer(DiT)用于生成可执行的Action,通过cross-attention 与 system 1交互,其输入包括经过Encoder编码后的State和Noised Action向量。
System 1 以 10Hz 频率提取包含多视角图像和语言指令的环境信息,System 2 以 120Hz 高频生成精细的运动控制信号,这种分层处理机制既保留了语言引导的高层任务理解,又确保了动作生成的实时响应性。特别值得注意的是,模型通过具身感知编码器(embodiment-aware encoder)将不同机器人的关节状态映射到统一潜空间,使得单一模型参数可适配从桌面机械臂到双手机器人的多种形态(为特定机器人 fine-tune 一个编码器和解码器即可)。
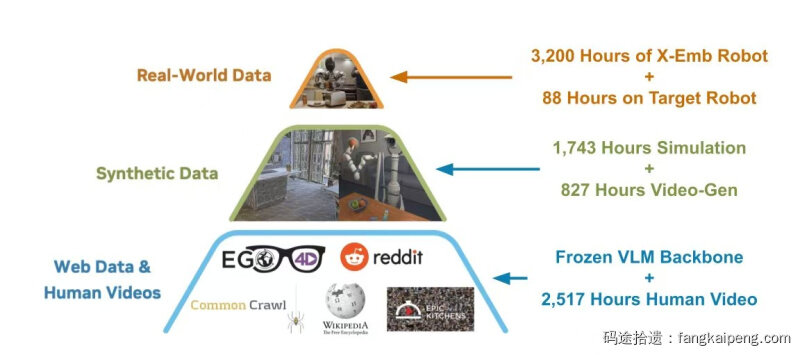
3. 数据金字塔:从Human Videos到Real-World Data的层次化训练
GR00T N1最大的贡献点个人认为在于如何获取数据以及如何利用数据训练人形机器人。人形机器人最大的问题就是数据的稀缺,因此目前的主流都是通过强化学习实现各种控制,或者利用人类数据作为先验。GR00T N1分别借助了大量第一人称的人类视频、生成的机器人数据、真机采集的机器人数据,构建了一个数据金字塔。下面介绍涉及的关于数据获取和利用的主要技术。
3.1 Latent Actions
首先,对于各种第一人称的视频数据,没有对应的Action Label,无法直接用于VLA模型的训练。GR00T N1通过训练一个VQ-VAE从连续图像帧生成Latent Action作为伪标签,具体采用LAPA[4]的方法。
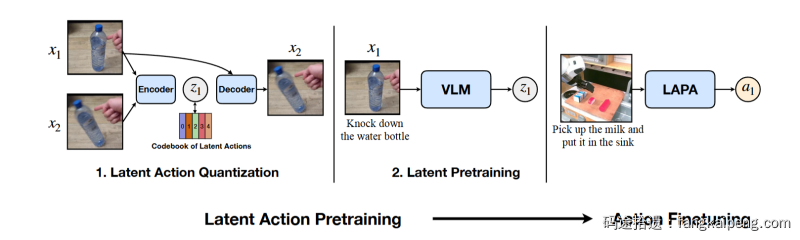
Encoder 的输入为当前帧$x_t$与未来帧$x_{t+H}$(H为固定的时间窗口),输出潜在动作$z_t$,然后将编码器输出的连续向量映射到codebook中的最近邻离散嵌入,即VQ-VAE的形式。Decoder则输入$x_t$和$z_t$,重建$x_{t+H}$。经过训练后,编码器被用作逆动力学模型(inverse dynamics model, IDM)。如此,对于一个给定的第一人称视频数据,可以提取其中连续的两帧作为Encoder的输入,生成编码后的连续向量,这个向量就包含了如何从第一张图片到第二张图片转移的信息,可以视为一种潜在的Action Label。在System 1 DiT 的预训练过程中,就可以将这个Latent Action作为去噪的目标进行训练。
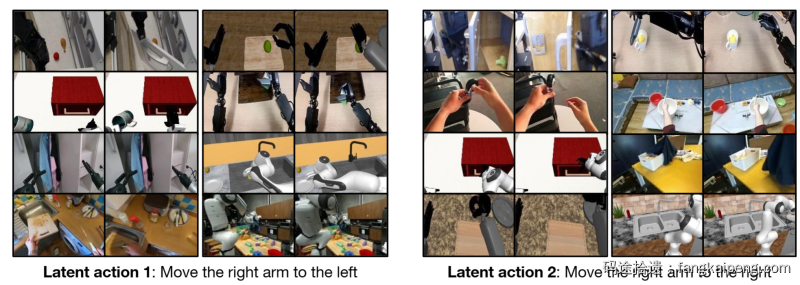
为什么这样可行呢?VAE的训练实际就是去建模$x_t$到$x_{t+H}$的状态转移分布,并且是在RBG层面的转移,因此是可以跨设备的,由于训练数据中有各种各样的设备图像,因此VAE学到的这个分布必然不是Embodied Specific的,而是General的一个语义信息,隐空间中的一个 $z$ 就表示了某种状态的转移。下面展示的是同一个 $z$ 在不同embodiments上检索出来的连续图像帧,可以看到同一个 $z$ 就能表达同一类动作。
3.2 Neural Trajectories
人类的第一人称数据始终和机械臂在视觉上有一定的Gap,而遥操作获得的机械臂第一视角数据也是有限的。GR00T N1就提出使用视频生成模型,来生成更多的机械臂第一人称视角数据。GR00T N1在自己收集的88小时遥操作视频数据上通过LoRA的形式微调了WAN2.1-I2V-14B[5]模型,并生成了827小时的视频数据。生成的方式是给定初始帧和对应的文本描述,生成对应的视频。为了保证质量,视频使用自动化的方式进行了筛选和re-caption,具体实验细节见原文,有一定的额外处理。生成得到的视频在文中被称为Neural Trajectories,通过上述提到的方式可以获得Latent Actions,或者额外训练一个IDM[6]模型预测Action。这里的IDM模型输入也是连续的两个图像帧,输出的是具体可执行的Action。之所以可以这样做,是因为视频数据是从真机遥操作采集的,有配对的真机Action。
3.3 Simulation Trajectories
从机器人上采集真实世界的数据的代价很高,于是近期有工作尝试在仿真环境中基于已有的数据生成更多的数据,GR00T N1利用了DexMimicGen [7]方法。
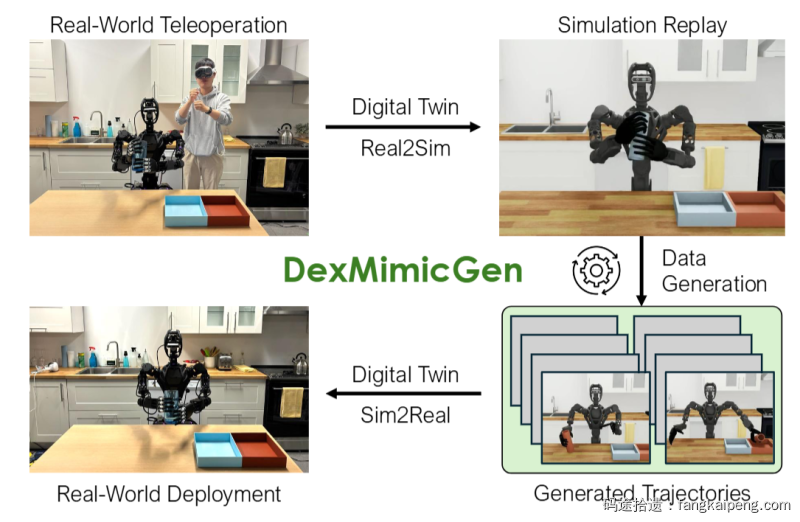
DexMimicGen 首先使用人类遥操作真实的机器人,然后Real2Sim的方式在仿真环境中复现这些demo。在仿真环境中,每个任务被分解为一系列以对象为中心的子任务,通过与对象的位置对齐来适应新环境,同时保持机器人末端执行器与对象之间的相对姿态。随后,机器人按照完整序列逐步操作,并在每一步验证任务的成功性。具体原理和细节见DexMimicGen 原论文。通过这种方式GR00T N1生成了 780,000 simulation trajectories,等于6,500小时的遥操作数据。
3.4 小结
借助上述技术,GR00T N1最终得到了以下的数据金字塔:
- 底层: Web 图文数据用于VLM预训练,人类第一视角视频用于System 1 DiT的预训练(借助Latent Actions)
- 中层:生成的数据,包括视频生成数据(借助Latent Action或者IDM生成Action)和仿真环境中生成的数据(自带State和Action)
- 顶层:自采集的88小时GR-1人形机器人数据,3200小时已有的机械臂数据OXE
4. 训练细节
4.1 预训练 Pre-training
在预训练阶段,GR00T N1 在各种实体和数据源上通过流匹配 flow-matching 损失进行训练,数据源涵盖了各种真实的和合成的机器人数据集以及人类运动数据。
- 对于人类视频,使用Latent Action作为流匹配目标。
- 对于机器人数据集,例如自己收集的 GR-1 人形机器人数据或 Open X-Embodiment 数据,同时使用真实采集的Action和Latent Action作为流匹配目标。
- 对于生成的视频数据(Neural Trajectories),使用了Latent Action以及训练的IDM预测的Action作为流匹配目标。
训练过程中,冻结LLM部分,更新 DiT 和Vision Backbone,具体使用的数据可以看原论文。
4.2 Post-training
后训练阶段(post-training)主要就是在具体的任务上进行Fine-tuning,同样冻结LLM部分,更新 DiT 和Vision Backbone。为解决数据稀缺问题,通过生成神经轨迹(Neural Trajectories)还对数据进行了增广。对于多视角任务,微调视频生成模型以生成网格化子图像;针对仿真任务,从随机初始化环境中采集初始帧;针对真实机器人任务,手动随机初始化物体位姿并记录初始观测。在实际应用中,仅使用10%真实数据及人工收集的仿真轨迹微调视频模型,并通过逆向动力学模型(IDM)或潜在动作标签生成伪动作标签,以1:1比例混合真实轨迹与神经轨迹进行策略训练,从而在有限真实遥操作数据下提升模型泛化能力。
4.3 训练开销
GR00T N1的训练基于NVIDIA OSMO管理的集群,采用配备H100 NVIDIA GPU和Quantum-2 InfiniBand高速互联的硬件架构,以fat-tree topology实现高效分布式计算。训练框架依托Ray分布式计算库构建的定制工具库,支持容错多节点训练与数据接入,单模型最多使用1024块GPU。其中,GR00T-N1-2B的预训练消耗约50,000 H100 GPU小时。在计算资源受限的微调场景下(如单块A6000 GPU),仅优化适配器层 adapter(动作/状态编码器+动作解码器)及DiT模块时,批次大小可达200;若同时调整视觉编码器,批次大小降至16。
5. 实验结果:模型泛化能力与数据效率
GR00T N1的实验中,研究团队通过系统性测试验证了模型在仿真与真实场景下的综合性能。在仿真环境中,模型在三大基准任务(RoboCasa厨房任务、DexMimicGen跨形态任务、GR-1桌面任务)中均展现出显著优势。例如,在GR-1真机上每个任务使用100条演示数据微调时,GR00T N1的成功率达到50%,较扩散策略(Diffusion Policy)基线提升17.3%。仅用10%的真实遥操作数据微调后,GR00T N1在真实场景中的平均成功率已达42.6%,接近基线模型使用全数据的性能(46.4%),这表明预训练阶段通过“数据金字塔”(人类视频、仿真轨迹、神经轨迹)注入的物理常识显著降低了微调数据需求。
研究团队特别探索了神经轨迹(Neural Trajectories)对数据扩展的贡献。通过视频生成模型将88小时真实轨迹扩展至827小时合成视频,并利用逆向动力学模型(IDM)标注伪动作标签,在仿真任务中实现了4.2%-8.8%的性能增益。例如,在RoboCasa的“转动水槽龙头”任务中,模型通过神经轨迹学习到未见于原始数据的双手协作策略,成功率提升至42.2%,远超基线的11.8%。此外,在真实机器人双臂协调任务中,预训练模型展现出零样本泛化能力:当目标物体位于左臂非工作区时,模型自主触发“左手抓取-移交右手-放置”的链式行为。

6. 讨论
这篇 “白皮书” 算是一个技术报告,本质上没有涉及太多的创新之处,实验部分也没和现有的主流VLA进行比较。其贡献主要在于开源了这样一个全套的技术栈,囊括了数据采集、生成、预训练、微调的全流程,并且模型和数据也进行了开源,高度可复现,可以预见的是后面会有大量人形机器人操作相关的文章涌现。值得注意的是,整个白皮书中涉及的核心算法和模型都是英伟达自家或者英伟达合作的。比如VLM用的Eagle 2是英伟达训的,Latent Action的论文也是英伟达参与的,Dexmimicgen生成仿真环境的数据也是英伟达的工作。
Reference
[1] https://www.figure.ai/news/helix
[2] https://storage.googleapis.com/deepmind-media/gemini-robotics/gemini_robotics_report.pdf
[3] Eagle 2: Building post-training data strategies from scratch for frontier vision-language models.
[4] Latent action pretraining from videos.
[5] Wan: Open and advanced large-scale video generative models
[6] Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos
[7] Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning.

总结的太好了!期待博主有更多的人形机器人相关论文的总结呀!
感谢