快期末了 好久没用过C,重新打一下程设二的内容找找手感,顺便水几篇博客,简单题直接过,需要思考的会有注释或者思路,重要知识点会总结,祝大家期末都AK!!!
总题目链接
2-1数据结构实验之链表一:顺序建立链表
#include <stdio.h>
#include <stdlib.h>
typedef struct Node//使用typedef后,之后定义该类型结构体不用写struct node p,直接node p即可,后面不解释
{
int data;
struct Node *next;
}node;
node *creat(int n)
{
node *head,*p,*tail;
//初始化操作 开头节点,置空
head=(node*)malloc(sizeof(node));
head-> next = NULL;
tail=head;
for(int i=0;i<n;i++)
{
p=(node*)malloc(sizeof(node));
scanf("%d",&p->data);
p->next=NULL;
tail->next=p;
tail=p;
}
return head;
}
int main()
{
int n;
scanf("%d",&n);
node *head,*p;
head=creat(n);
p=head->next;
while(p)//遍历链表
{
if(p->next==NULL)
printf("%d",p->data);
else printf("%d ",p->data);
p=p->next;
}
return 0;
}
模拟过程
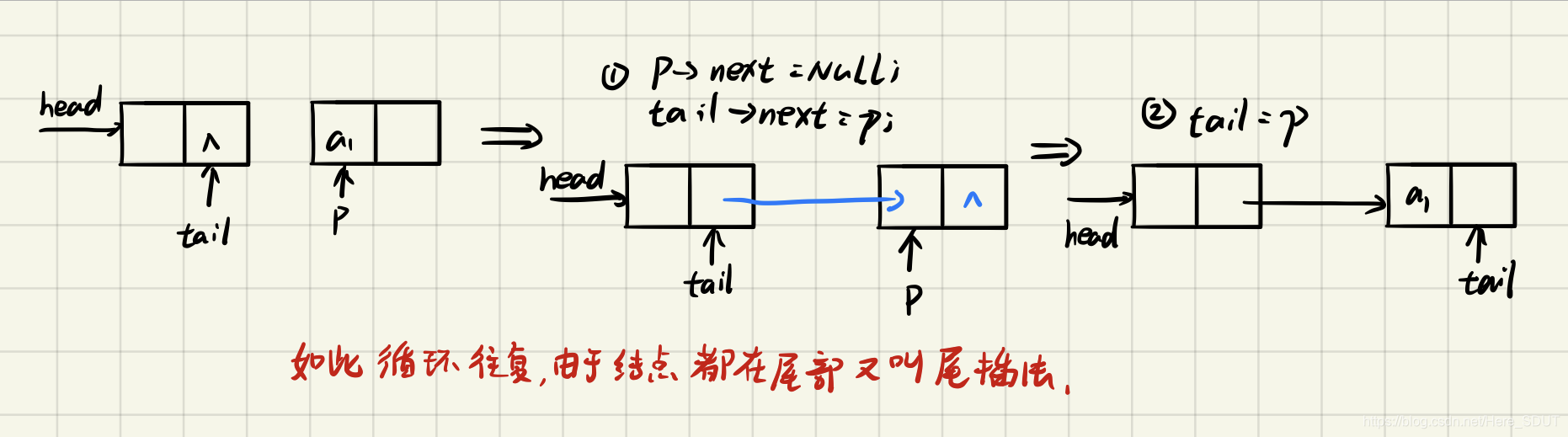
尾插法建表可以很形象的理解成每个新结点都插在尾巴后,尾巴由tail标识,而新结点的插入导致原尾结点不是尾巴了,新插入的p成为新尾巴,所以每次都要进行上面这些操作(更新尾巴 尾巴的next为NULL)
2-2数据结构实验之链表二:逆序建立链表
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
int data;
struct node *next;
}node;
node *creat(int n)
{
node *head,*p;
head=(node*)malloc(sizeof(node));
head-> next = NULL;
for(int i=0;i<n;i++)
{
p=(node*)malloc(sizeof(node));
scanf("%d",&p->data);
p->next=head->next;
head->next=p;
}
return head;
}
int main()
{
int n;
scanf("%d",&n);
node *head,*p;
head=creat(n);
p=head->next;
while(p)
{
if(p->next==NULL)
printf("%d",p->data);
else printf("%d ",p->data);
p=p->next;
}
return 0;
}
模拟过程

2-3师–链表的结点插入
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
int data;
struct node *next;
}node;
void Insert(node *head,int mi,int xi)//插入操作
{
node *q=(node *)malloc(sizeof(node)),*p=head;
q->data=xi;//准备好新节点(开空间+赋值)
for(int i=0;i<mi&&p->next!=NULL;i++)//查找第mi个,如果超过链表长度了即p->next==NULL也结束循环
{
p=p->next;
}
//下面其实类似于头插法建表的一次插入,p看成head
q->next=p->next;
p->next=q;
}
int main()
{
int n;
while(~scanf("%d",&n))
{
node *head,*p;
head=(node*)malloc(sizeof(node));
head->next=NULL;
for(int i=0; i<n; i++)
{
int mi,xi;
scanf("%d %d",&mi,&xi);
Insert(head,mi,xi);
}
p=head->next;
while(p)
{
if(p->next==NULL)
printf("%d\n",p->data);
else
printf("%d ",p->data);
p=p->next;
}
}
return 0;
}
2-4数据结构实验之链表七:单链表中重复元素的删除
思路:
首先是逆序建表不讲,然后是进行删除操作,首先我们知道删除操作需要一个伴随结点,我们定义q为p的伴随结点,至于判断是否重复可以用嵌套循环来完成,外层循环遍历整个链表,内层循环用于遍历p前面的所有元素判断p是否重复(由于逆序建表,所以最先遇到的就是最后 插入的,符合题意)
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
int data;
struct node *next;
} node;
node *creat(int n)//逆序建表
{
node *head,*p;
head=(node*)malloc(sizeof(node));
head-> next = NULL;
for(int i=0; i<n; i++)
{
p=(node*)malloc(sizeof(node));
scanf("%d",&p->data);
p->next=head->next;
head->next=p;
}
return head;
}
void pri(node *p)//输出函数
{
while(p)
{
if(p->next==NULL)
printf("%d\n",p->data);
else
printf("%d ",p->data);
p=p->next;
}
}
int main()
{
int n;
scanf("%d",&n);
node *head,*p;
head=creat(n);
//输出逆序建表后的数据
printf("%d\n",n);
pri(head->next);
//下面是删除重复数据
node *q,*k;//q作为p的跟随结点用于删除操作,k用于遍历前面不重复部分的链表来判断p是否重复
p=head->next;
q=head;
while(p)
{
int flag=1;
k=head->next;
while(k!=p)
{
if(k->data==p->data)
{
flag=0;
n--;
q->next=p->next;
p=p->next;
break;
}
k=k->next;
}
if(flag==1)
{
p=p->next;
q=q->next;
}
}
printf("%d\n",n);
pri(head->next);
return 0;
}
数据结构实验之链表三:链表的逆置
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
int data;
struct node *next;
} node;
node *creat()//顺序建表
{
int x;
node *head,*p,*tail;
head=(node*)malloc(sizeof(node));
head-> next = NULL;
tail=head;
while(~scanf("%d",&x)&&x!=-1)
{
p=(node*)malloc(sizeof(node));
p->data=x;
p->next=NULL;
tail->next=p;
tail=p;
}
return head;
}
void pri(node *p)//遍历输出
{
while(p)
{
if(p->next==NULL)
printf("%d\n",p->data);
else
printf("%d ",p->data);
p=p->next;
}
}
void reserve(node *head)//倒置
{
node *p,*q;
p=head->next;
head->next=NULL;
q=p->next;
while(p)
{
p->next=head->next;
head->next=p;
p=q;
if(q)
q=q->next;
}
}
int main()
{
node *head;
head=creat();
reserve(head);
pri(head->next);
return 0;
}
2-6数据结构实验之链表四:有序链表的归并
归并其实就是换个说法的建表——两个表取其中一个表的头节点作为新链表的头节点,然后把两个表剩余的结点以一种规定的方式插入新头节点。
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
int data;
struct node *next;
} node;
node *creat(int n)
{
node *head,*p,*tail;
head=(node*)malloc(sizeof(node));
head-> next = NULL;
tail=head;
for(int i=0;i<n;i++)
{
p=(node*)malloc(sizeof(node));
scanf("%d",&p->data);
p->next=NULL;
tail->next=p;
tail=p;
}
return head;
}
void pri(node *p)
{
while(p)
{
if(p->next==NULL)
printf("%d\n",p->data);
else
printf("%d ",p->data);
p=p->next;
}
}
node *merge(node *head1,node *head2)
{
node *p1,*p2,*tail;
p1=head1->next;
p2=head2->next;
tail=head1;
while(p1&&p2)
{
if(p1->data<=p2->data)
{
tail->next=p1;
tail=p1;
p1=p1->next;
}
else
{
tail->next=p2;
tail=p2;
p2=p2->next;
}
}
if(p1)
tail->next=p1;
else
tail->next=p2;
return head1;
}
int main()
{
int n,m;
scanf("%d %d",&m,&n);
node *head1,*head2;
head1=creat(m);
head2=creat(n);
head1=merge(head1,head2);
pri(head1->next);
return 0;
}
2-7数据结构实验之链表五:单链表的拆分
拆分就是把一个表重新建成两个,本质也是建表
#include <stdio.h>
#include <stdlib.h>
typedef struct
{
int data;
struct node *next;
} node;
int ji,ou;
node *creat(int n)
{
node *head,*p;
head=(node*)malloc(sizeof(node));
head-> next = NULL;
for(int i=0;i<n;i++)
{
p=(node*)malloc(sizeof(node));
scanf("%d",&p->data);
p->next=head->next;
head->next=p;
}
return head;
}
void pri(node *p)
{
while(p)
{
if(p->next==NULL)
printf("%d\n",p->data);
else
printf("%d ",p->data);
p=p->next;
}
}
node *split(node *head1)
{
node *head2,*p,*q;
//初始化一个新的头节点
head2=(node*)malloc(sizeof(node));
head2->next=NULL;
p=head1->next;
q=p->next;
head1->next=NULL;
//按照奇偶拆分
while(p)
{
if(p->data%2==0)
{
ou++;
p->next=head1->next;
head1->next=p;
}
else
{
ji++;
p->next=head2->next;
head2->next=p;
}
p=q;
if(q)
q=q->next;
}
return head2;
}
int main()
{
int n;
scanf("%d",&n);
node *head1,*head2;
head1=creat(n);
head2=split(head1);
printf("%d %d\n",ou,ji);
pri(head1->next);
pri(head2->next);
return 0;
}
2-8数据结构实验之链表九:双向链表
双向链表就是在每个结点里多加一个指向前一个结点的指针,其余和普通链表无异。
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
typedef struct Node
{
int data;
struct Node *next,*front;
}node;
node *creat(int n)
{
node *head,*p,*tail;
head=(node*)malloc(sizeof(node));
head->next = NULL;
head->front = NULL;
tail=head;
for(int i=0; i<n; i++)
{
p=(node*)malloc(sizeof(node));
scanf("%d",&p->data);
p->next=NULL;
tail->next=p;
p->front=tail;
tail=p;
}
return head;
}
int main()
{
int n,m;
scanf("%d %d",&n,&m);
node *head, *p;
head=creat(n);
while(m--)
{
p=head->next;
int x;
scanf("%d",&x);
while(p->data!=x)
p=p->next;
if(p->front==head)
printf("%d\n",p->next->data);
else if(p->next==NULL)
printf("%d\n",p->front->data);
else
printf("%d %d\n",p->front->data,p->next->data);
}
return 0;
}
2-9约瑟夫问题
约瑟夫问题的核心是循环链表,循环链表与普通链表最大的不同有两点:1.尾结点指向头结点而不是NULL 2.可以说没有真正的头结点,所谓的头结点是开始插入的地方,循环链表的“头结点”也存入数据(当然不存入数据也行,就把它标记为特殊的结点,遍历循环节的的时候判断一下是不是“头结点”,如果是就跳过)
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
typedef struct Node
{
int data;
struct Node *next;
} node;
node *creat(int n)
{
node *head,*p,*tail;
p=(node*)malloc(sizeof(node));
//“头结点”也有数据
p->data=1;
p->next=NULL;
head=tail=p;
for(int i=2; i<=n; i++)
{
p=(node*)malloc(sizeof(node));
p->data=i;
p->next=NULL;
tail->next=p;
tail=p;
}
tail->next=head;
return head;
}
int main()
{
int n,m;
scanf("%d %d",&n,&m);
node *head, *p,*q;
head=creat(n);
q=head;
while(q->next!=head)
q=q->next;
int con=0;
while(q->next!=q)
{
p=q->next;
con++;//每次喊数字
if(con==m)
{
q->next=p->next;
free(p);
con=0;
}
else
q=p;
}
printf("%d",q->data);
return 0;
}
2-10不敢死队问题
就是约瑟夫环问题,m人围坐着,排长编号为1,排长开始报数,报到5的出去,问排长第几个出去。
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
typedef struct Node
{
int data;
struct Node *next;
} node;
node *creat(int n)
{
node *head,*p,*tail;
p=(node*)malloc(sizeof(node));
p->data=1;
p->next=NULL;
head=tail=p;
for(int i=2; i<=n; i++)
{
p=(node*)malloc(sizeof(node));
p->data=i;
p->next=NULL;
tail->next=p;
tail=p;
}
tail->next=head;
return head;
}
int main()
{
int n;
while(~scanf("%d",&n)&&n)
{
node *head, *p,*q;
head=creat(n);
q=head;
while(q->next!=head)
q=q->next;
int con=0,ans=0;
while(q->next!=q)
{
p=q->next;
con++;
if(con==5)
{
if(p->data==1)
break;
q->next=p->next;
free(p);
con=0;
ans++;
}
else
q=p;
}
printf("%d\n",ans+1);
}
return 0;
}
小结
链表重在理解,建议画图模拟链表的各种操作,基础就是顺序建表和逆序建表,逆置,归并,拆分等操作都可以看成是建表的过程,理解指针的用处,比如删除操作的前驱指针。建议不要背代码,链表码量较大且变化灵活。
