一、聚类(K-means)
1.1 K-means算法流程
-
首先随机选择两个聚类中心(具体选择几个聚类中心根据具体问题决定,这里以两个为例)

然后将会循环执行下面的过程:
-
簇分配,按照每个样本分别到两个聚类中心的距离将样本分别归类到两个聚类中。
-
移动聚类中心,将蓝色聚类中心移动到所有蓝色点的坐标平均值上,红色聚类中心同样操作
-
-
重复上述过程,直到收敛
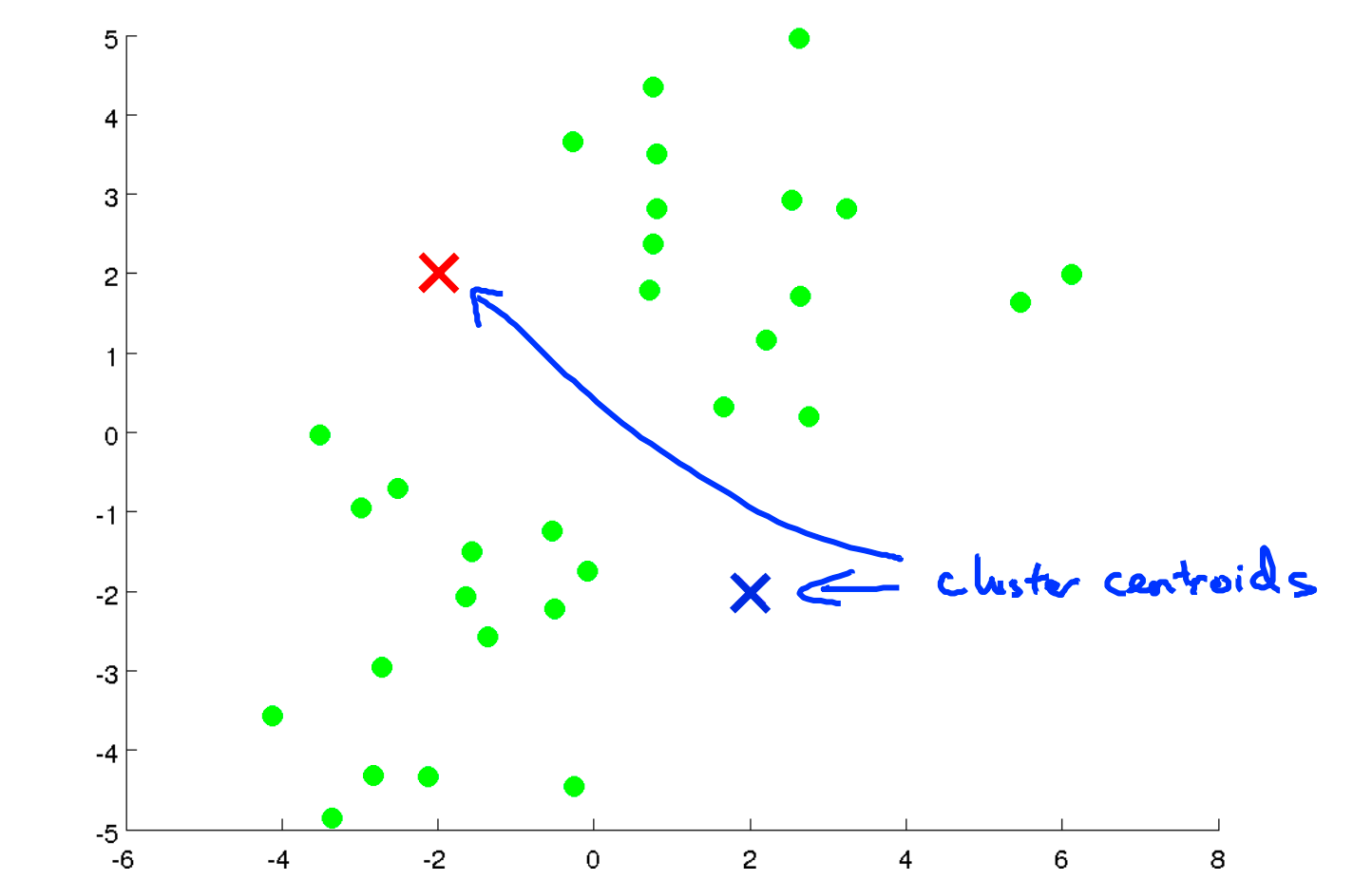
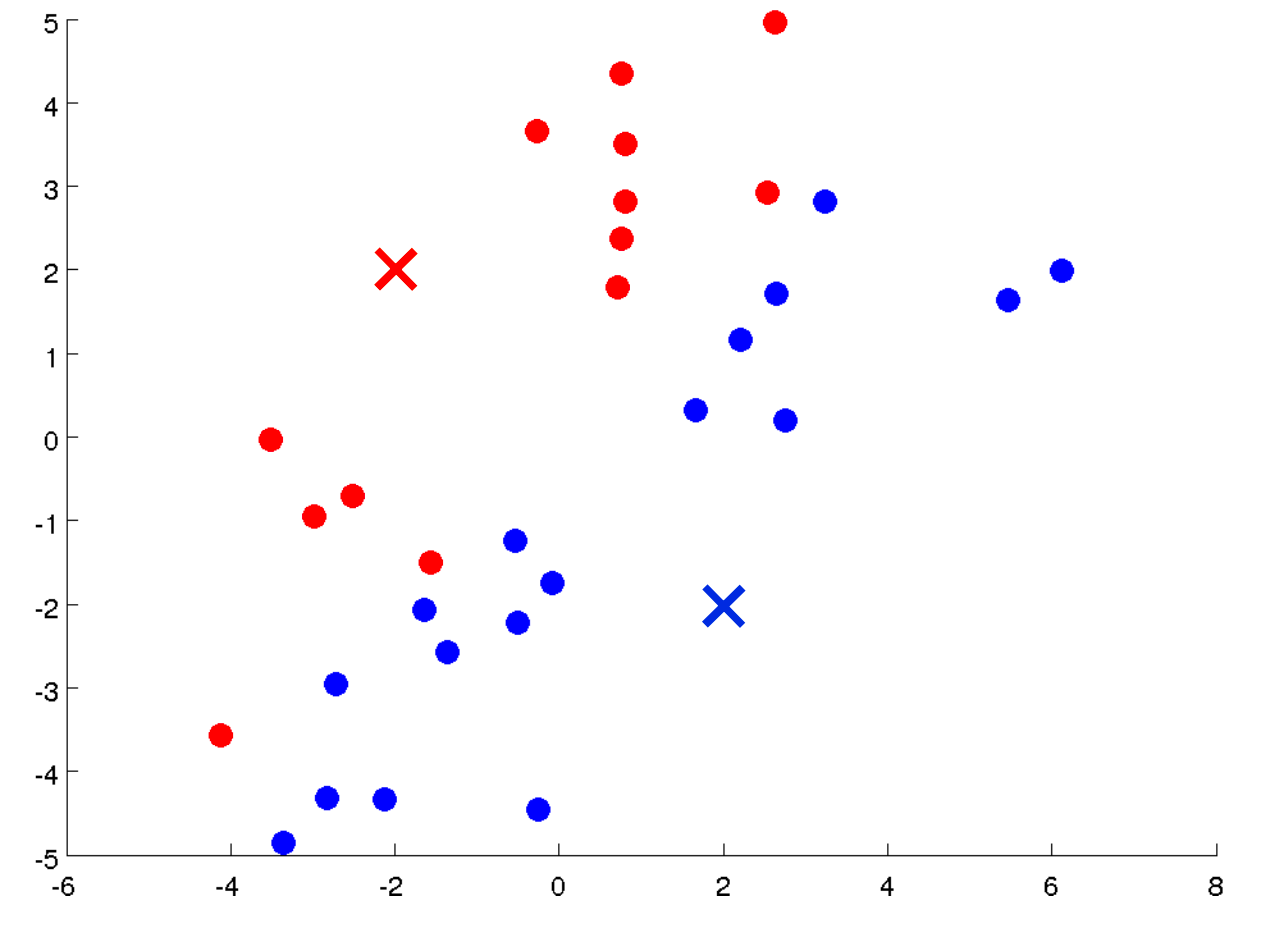

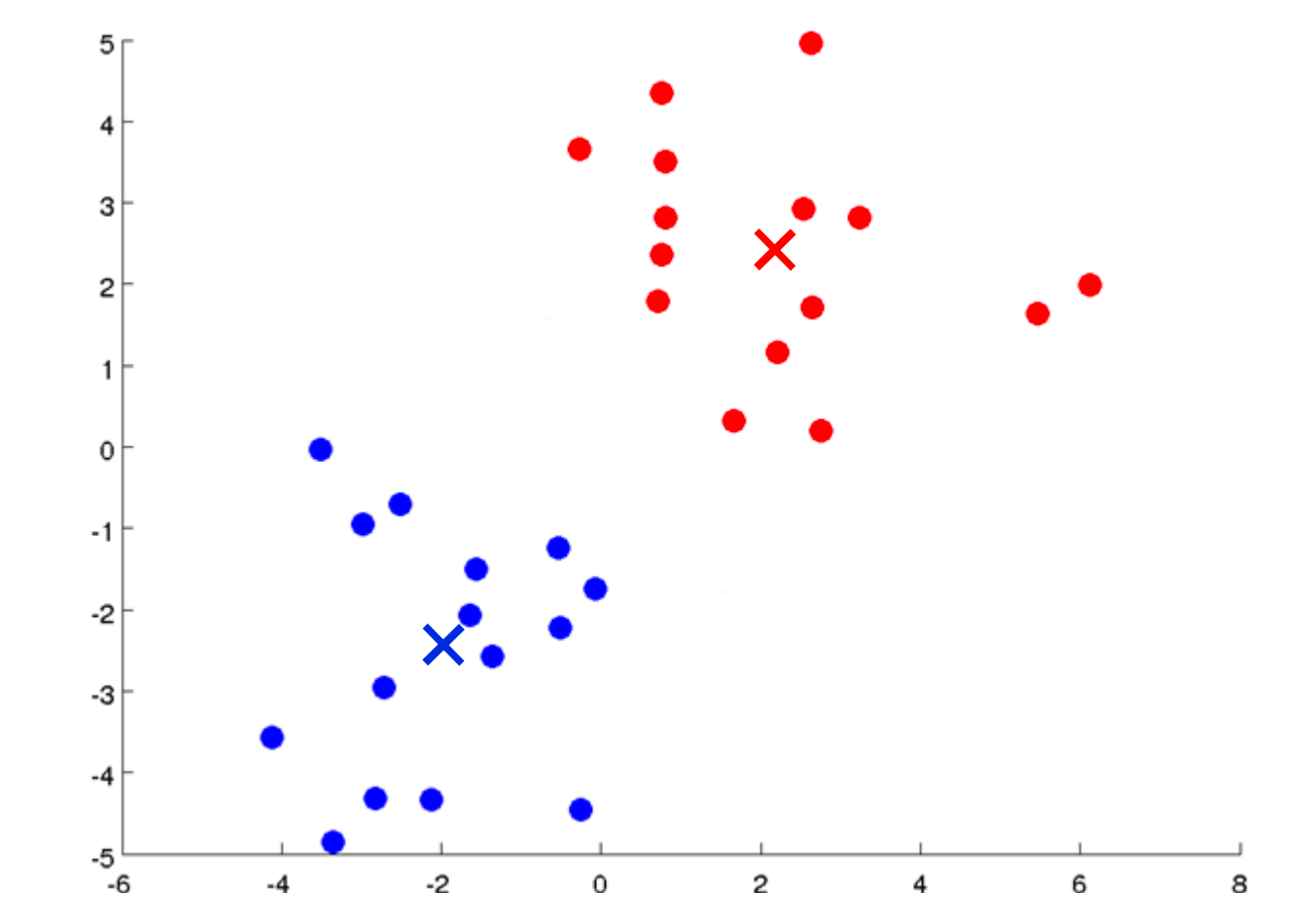
Tips:如果出现某个聚类中心没有分配到点的情况,一般是直接将这个中心去掉,如果规定必须要刚好
1.2 优化目标
变量约定:
那么K-means算法的优化目标函数如下:
从函数中我们可以看出,自变量为聚类中心和每个数据所属聚类中心的下标。优化目标是,让每个数据到它所属的聚类中心的距离之和最小。
1.3 初始化
聚类中心的选择
推荐的方法是随机在数据中选取几个点作为聚类中心,但是这样可以会进入一个局部最优解,如下图所示:
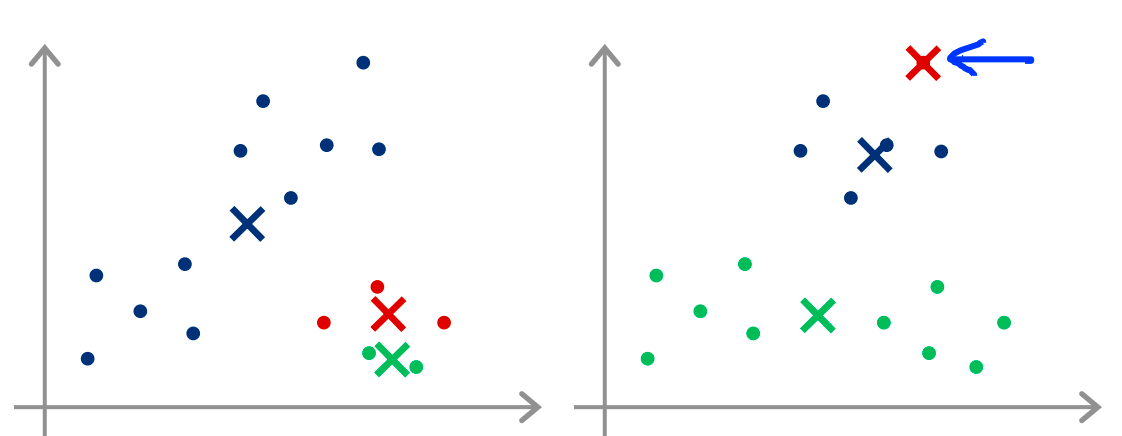
这时可以进行多次K-means,每次随机选几个聚类中心,然后在这些轮中选择最优的(代价函数值最小的)。
K值的选择
对于一个数据集采用多少个聚类中心目前还没有一个很好的办法,多数时候是手动选择的,比如可以借助数据的可视化。这里介绍一个叫做肘部法则(Elbow method)的办法。
如下图所示,我们绘制出代价函数关于聚类中心个数的函数,如果图像类似下图左的样子,则我们可以选择
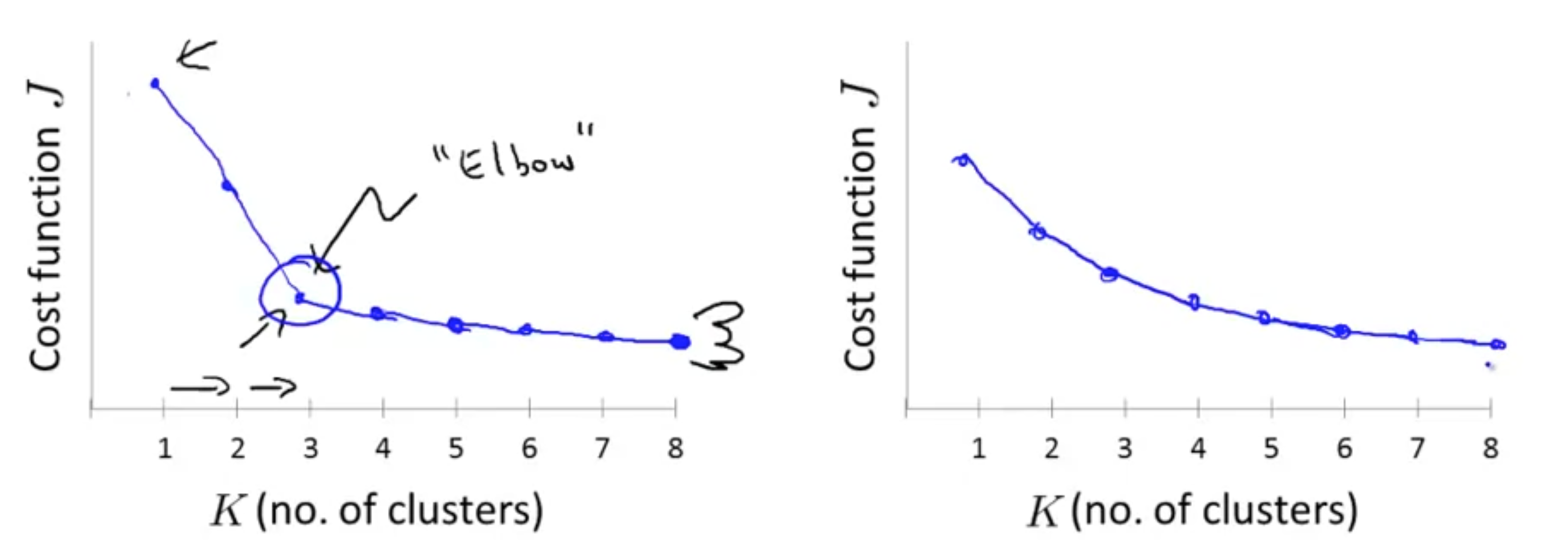
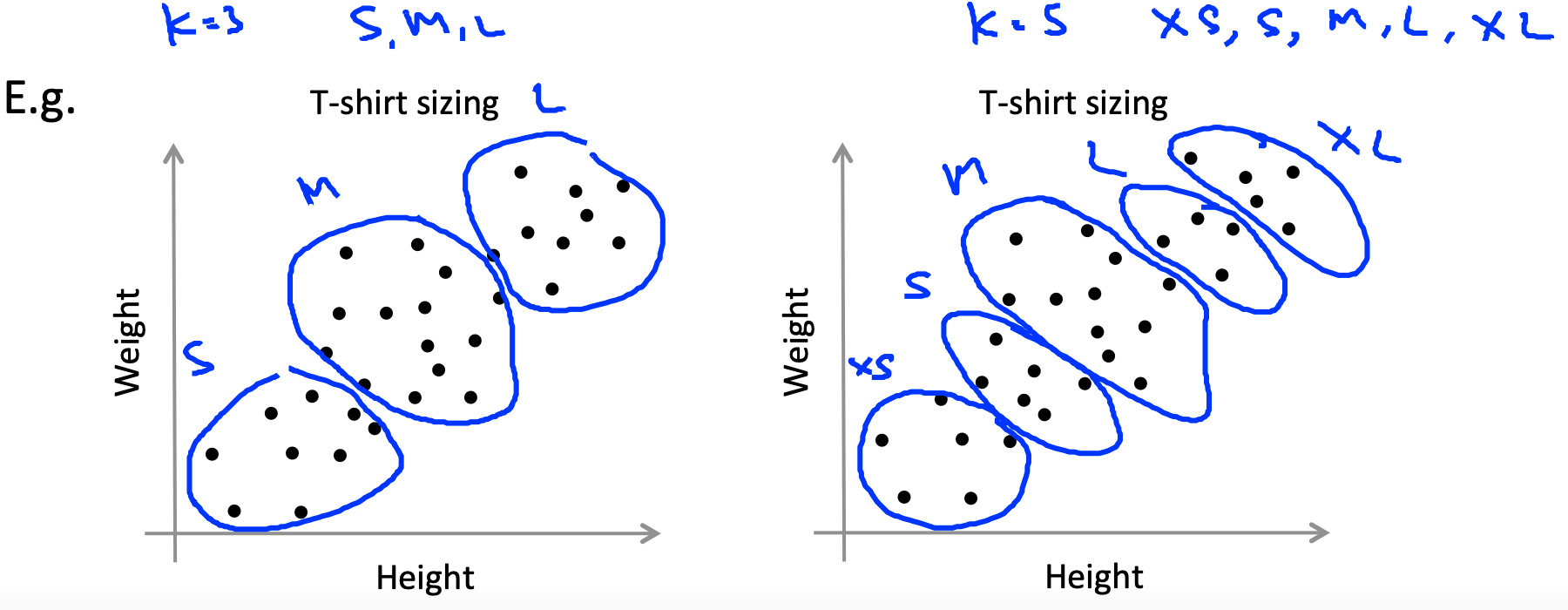
不过,还有一个很好的评判标准。聚类的作用很多情况下都是用于分析数据,然后为下面的行为服务,或者作为接下来的决策依据。那么我们就可以反向思考,考虑采用多少聚类中心可以更适合接下来的事情。举例来说:
对于T-shirt 大小的数据分析,是采用
二、降维(PCA)
2.1 目的
降维的目的主要有,数据压缩和数据可视化。
通过数据压缩,可以减少数据的存储量同时加快模型的训练速度。
通过数据可视化,可以将高维无法可视化的数据压缩到3D或2D,然后展示数据,对数据进行分析。
2.2 PCA介绍
PCA的目标
如下图的例子,将二维数据降低到一维,我们会选择图中红色这条线作为标准,然后将每个数据投影到红线上,也就是说PCA的目标是找到一个低维的超平面,使得每个数据投影到超平面的距离之和最小。这也是为什么PCA不会选择图中粉红色这一条线来投影的原因,因为他的距离太大了。其中,这里的每个数据到超平面的投影距离也称为投影误差。
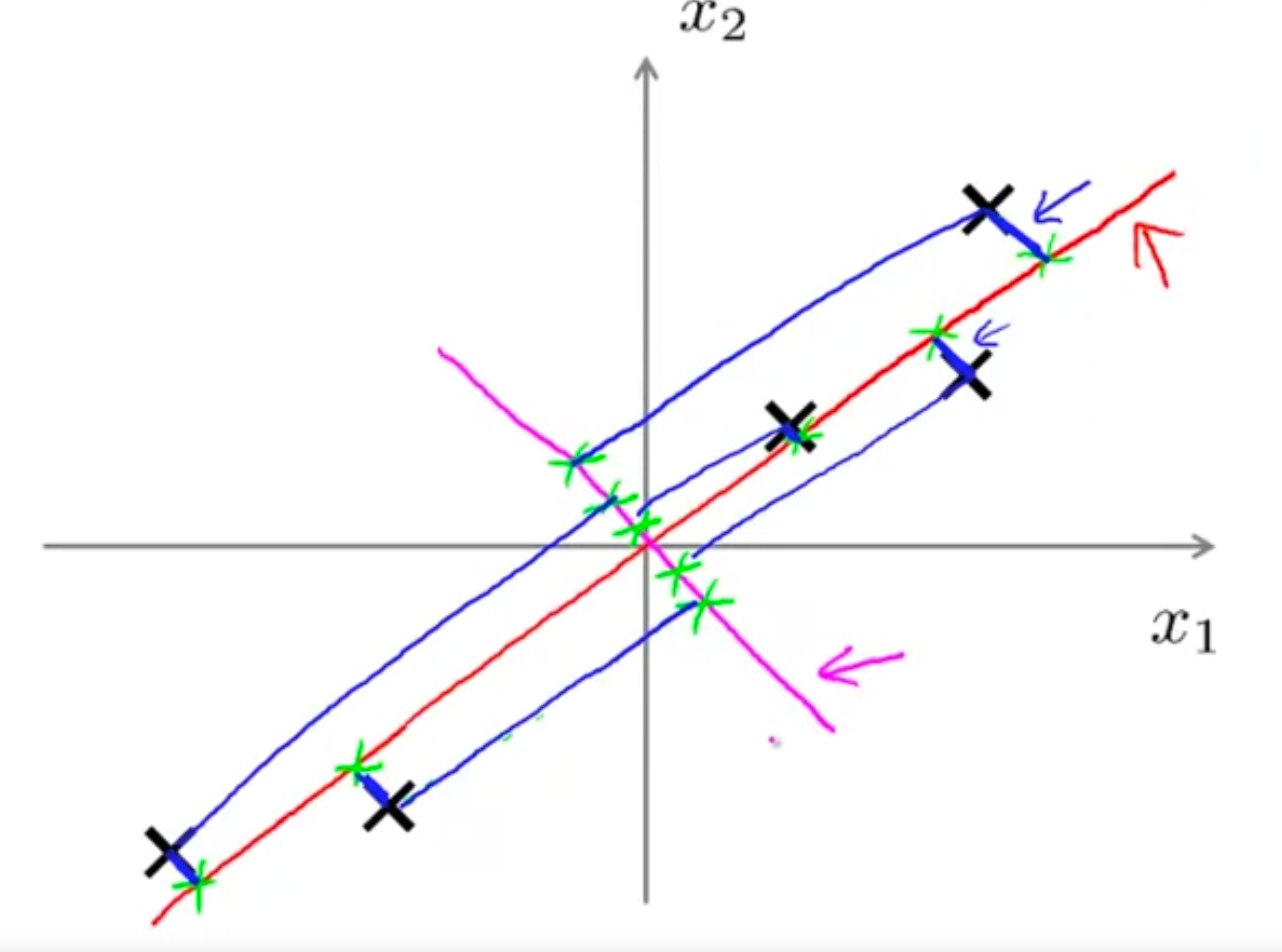
PCA与线性回归的区别
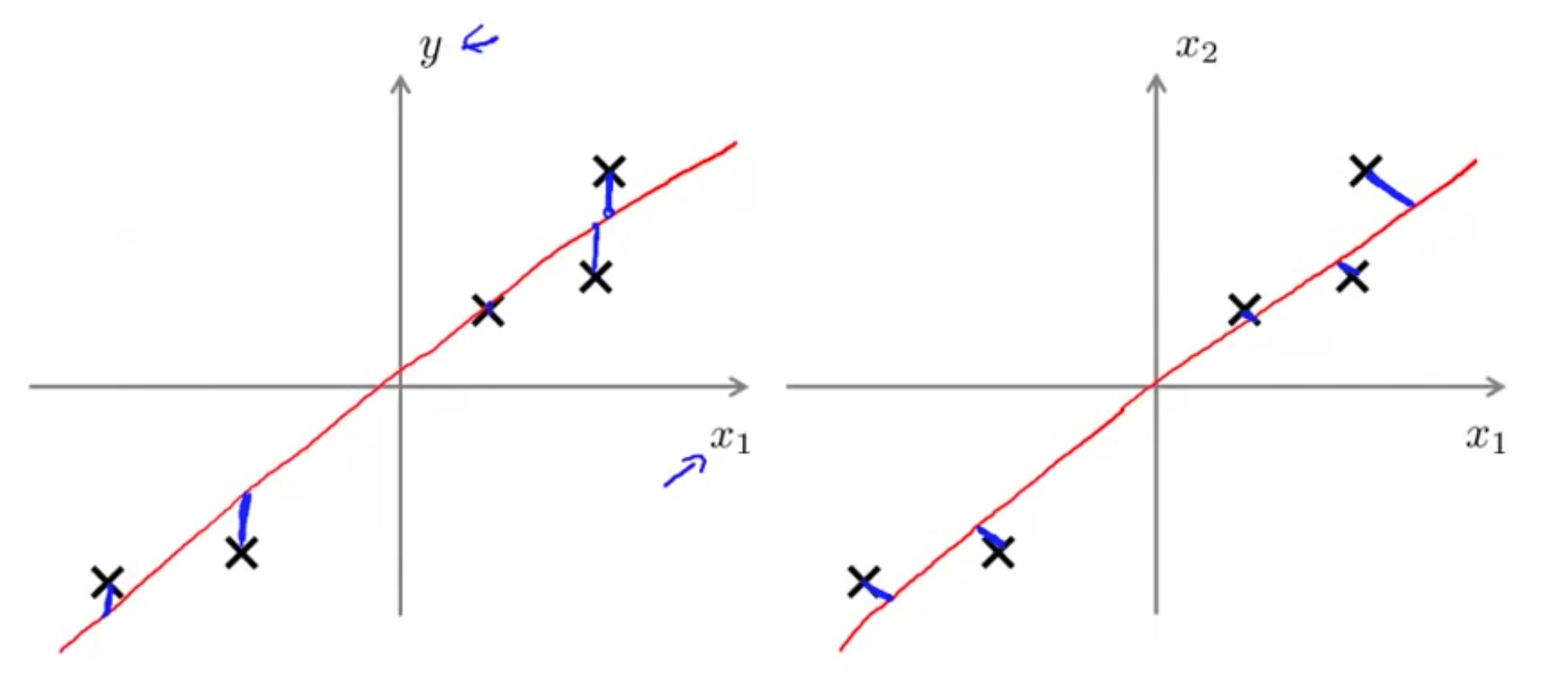
首先两者的代价函数就是不同的,这也是它们的根本区别,对于线性回归,他的目标是使得每个数据和预测的直线之间的
而对于PCA,他的目标是找到一条直线,使得每个数据到直线的投影和最小。
当然上面都是以二维数据为例的,在高维情况下也是类似的道理。
其次,线性回归是去预测
算法流程
在运行PCA算法之前,需要进行数据的预处理,主要是进行特征缩放和均值归一化。假设我们要将 $n$ 维的数据降到
-
计算协方差矩阵:
,需要注意的是协方差矩阵的符号和求和符号一样,注意不要混淆了。 -
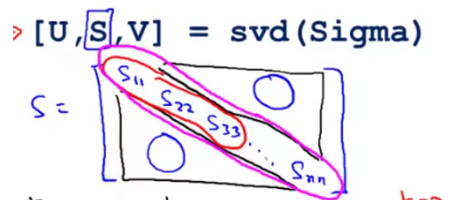
计算sigma矩阵的特征向量(eigenvectors),其中sigma矩阵就是上一步计算得到的协方差矩阵,即
,其中 svd 表示奇异值分解们用于计算特征向量,然后我们便可以得到下列所示的矩阵: 然后,我们选取前
个列向量作为用于降维的超平面。 -
则降维后的数据
,即可将原来的 的向量变成 的向量。
2.3 PCA的应用
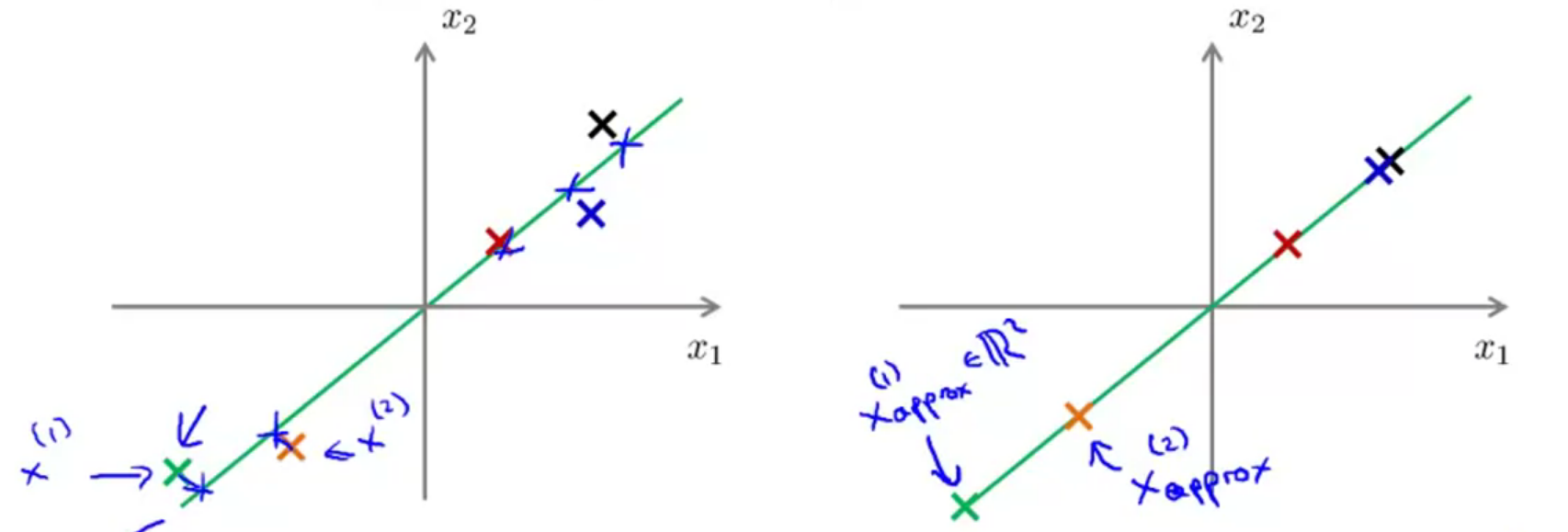
数据“解压”
PCA可以将数据降维到某一维度,那么这里介绍一下如何将降维的数据近似恢复回降维前的数据。
前面介绍到
k值的选取
PCA中
首先,PCA算法的目标是降低平均平方映射误差(Average Squared Projection Error),即 :
还有一个定义就是数据的总变差(Total Variation):
一般来说,我们选择一个最小的
换句话说,也就是PCA降维之后的数据保留了 99% 的差异性。于是,我们就可以从
并且有一个结论就是:
于是,我们就不用重复计算svd,只要计算一次,然后逐渐改变 k 的大小,使得上述条件满足,当然我们也可以稍微化简一下,得到最终的条件:
应用PCA的建议
假使我们正在针对一张 100×100 像素的图片进行某个计算机视觉的机器学习,即总共有 10000 个特征。
-
第一步是运用主要成分分析将数据压缩至 1000 个特征
-
然后对训练集运行学习算法
-
在预测时,采用之前学习而来的 将输入的特征
转换成特征向量 ,然后再
进行预测。注:如果我们有交叉验证集合测试集,也采用对训练集学习而来的
。
错误的主要成分分析情况:
- 一个常见错误使用主要成分分析的情况是,将其用于减少过拟合(减少了特征的数量)。这样做非常不好,不如尝试归一化处理。原因在于主要成分分析只是近似地丢弃掉一些特征,它并不考虑任何与结果变量有关的信息,因此可能会丢失非常重要的特征。然而当我们进行归一化处理时,会考虑到结果变量,不会丢掉重要的数据。
- 另一个常见的错误是,默认地将主要成分分析作为学习过程中的一部分,这虽然很多时候有效果,最好还是从所有原始特征开始,只在有必要的时候(算法运行太慢或者占用太多内存)才考虑采用主要成分分析。
