一、优化目标
1.1 从逻辑回归模型开始
在介绍SVM之前,我们先从逻辑回归模型开始,我们知道,逻辑回归的假设函数为
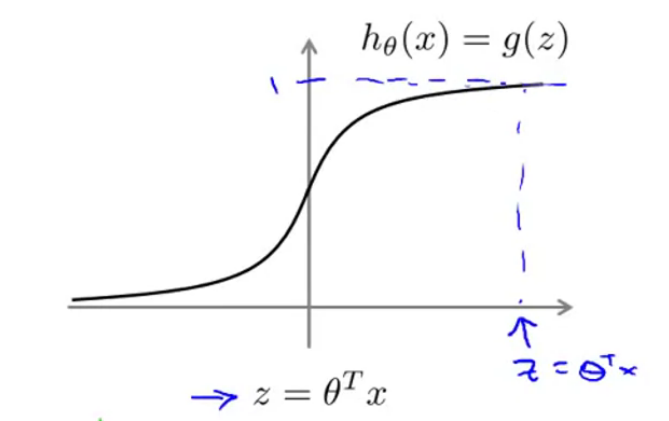
我们的目标是对于
对于
下面对逻辑回归的代价函数进行分析:
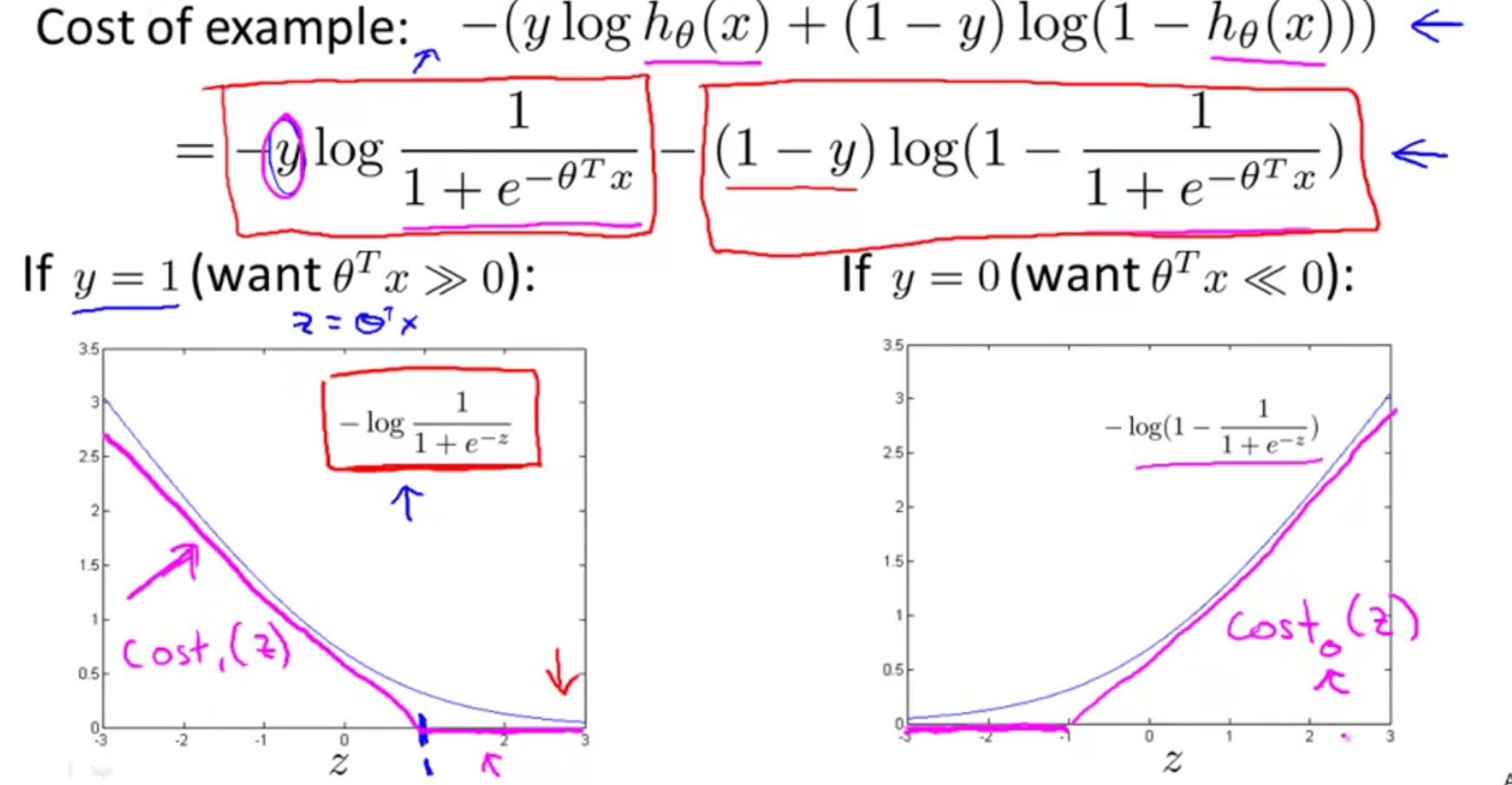
当
1.2 SVM优化目标
对于逻辑回归的优化目标如下:
对于支持向量机的优化目标如下:
对比两个表达式,首先SVM的优化目标将参数
最后有别于逻辑回归输出的概率,支持向量机所做的是它来直接预测y 的值等于1,还是等于0。因此,当
二、大边界分类器的理解
2.1 直观理解
人们有时也会将SVM称为大间距分类器,这里就来理解一下其中的原因。

如上图所示就是支持向量机的代价函数和图像,我们的目标是最小化代价函数。所以我们考虑一下最小化代价函数的必要是什么,假如现在有个正样本
当
对于这样的SVM模型,在如下图所示的数据中进行训练,通过数据分布可以看出这个数据是线性可分的,我们可以很轻松的用一条直线分开这两个数据集,如图中绿色和粉红的直线。但是当
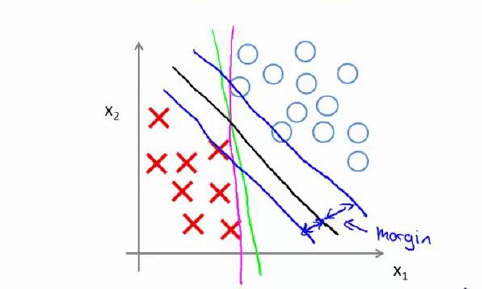
再来说一下SVM的正则化系数
总结可以得到:
- C 较大时,相当于 λ 较小,可能会导致过拟合,高方差 。
- C较小时,相当于 λ 较大,可能会导致低拟合,高偏差。
2.2 数学解释
向量内积的回顾:
向量内积在几何意义上等于 投影 乘 被投影的向量长度,在坐标意义上等于对应坐标相乘再相加,用向量表示就是第一个向量的转置乘上第二个向量。
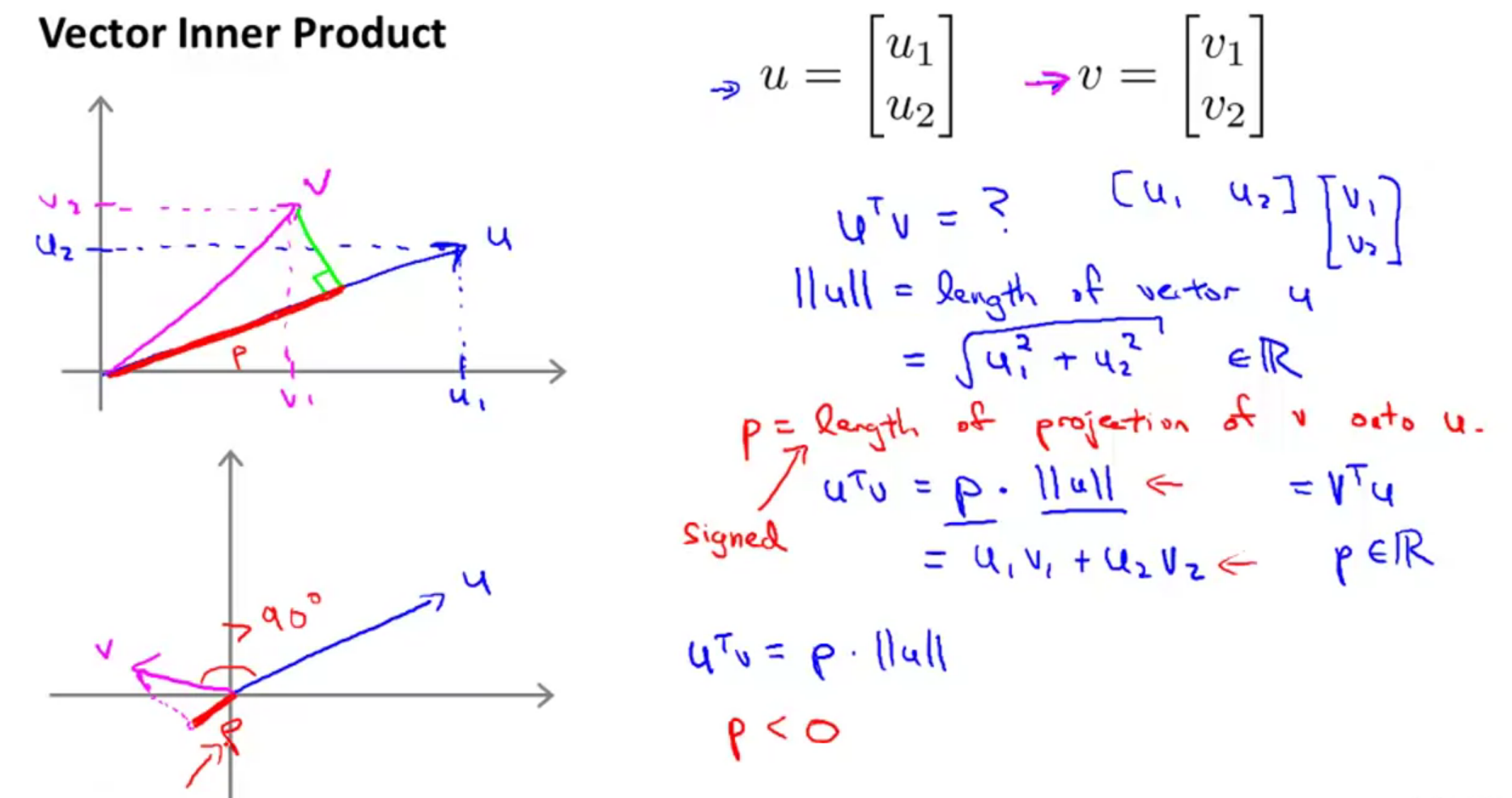
现在我们讨论的是
我们可以推得
于是,对于这样一个特殊的化简情况,我们就可以将目标函数写成:
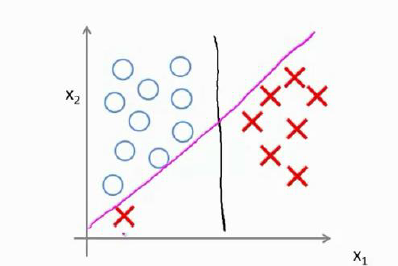
对于下图的数据集,我们随意画了一条决策边界(绿色直线),由于
对于正样本,由于
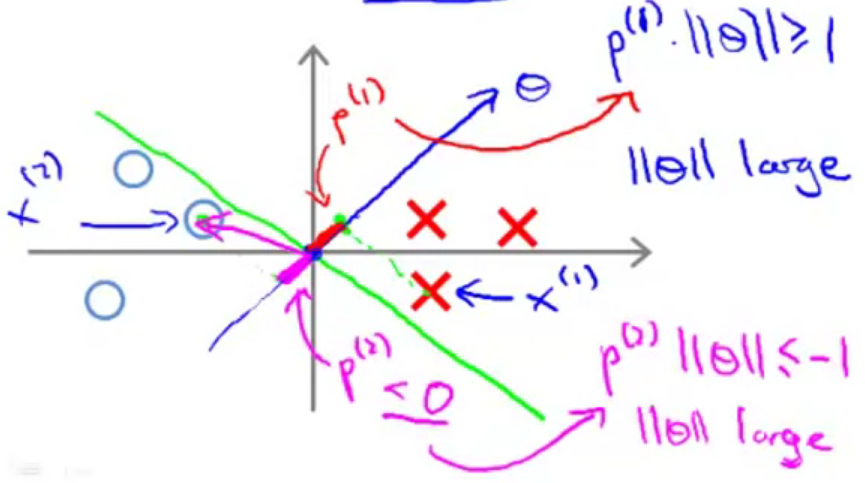
所以在目标函数的作用下,SVM会选择如下的决策边界,在这样的边界下,每个样本到
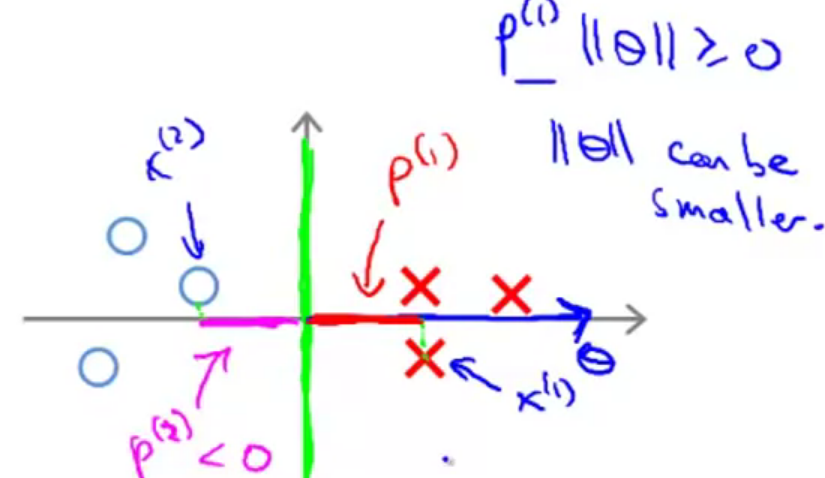
但需要注意的是,上述的推导都是基于
三、核函数
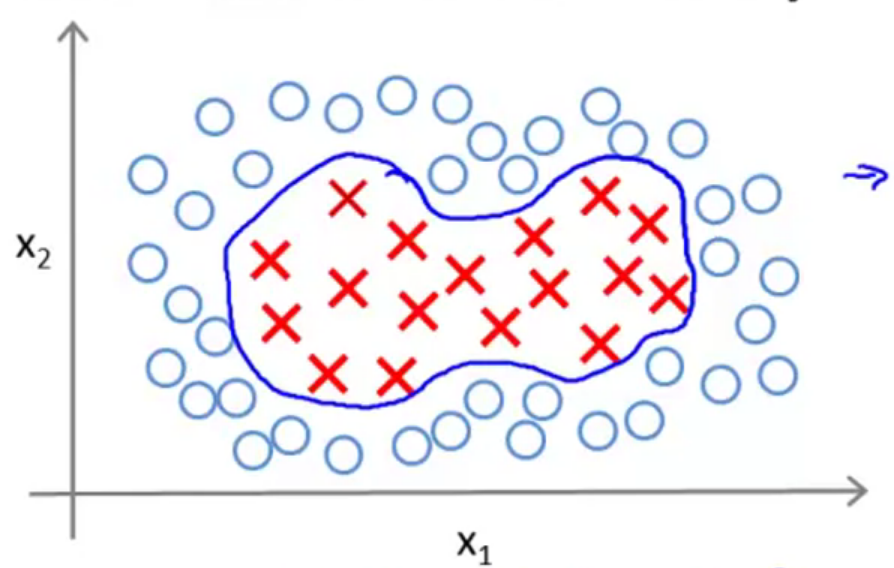
首先,先来回顾一下非线性回归问题分决策边界,如下图所示,通常情况下,对于一个非线性的问题,我们通过构造高次的特征项来解决。具体来说,我们的假设函数的定义能是当
现在我们将假设函数换一种表示方法:
3.1 高斯核函数
我们现在样本空间里随机取三个点,称为标记点(landmarks),分别标记为
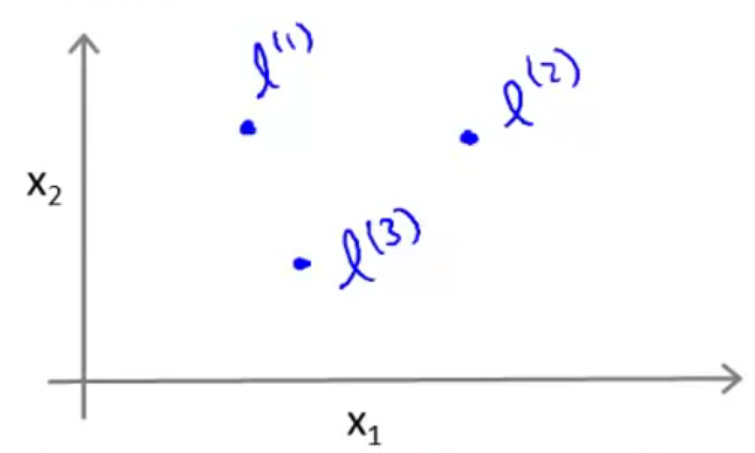
然后我们可以定义三个特征
其余两个特征的定义类似,下面我们分析一下这个表达式:
- 当样本
与 很接近时, 约等于0,则 约等于1。(exp表示 的指数, ) - 当样本
与 相差很多时, 为一个很大的数字,加上前面的负号,整体为一个很大的负数,则 约等于0。
下面再来观察
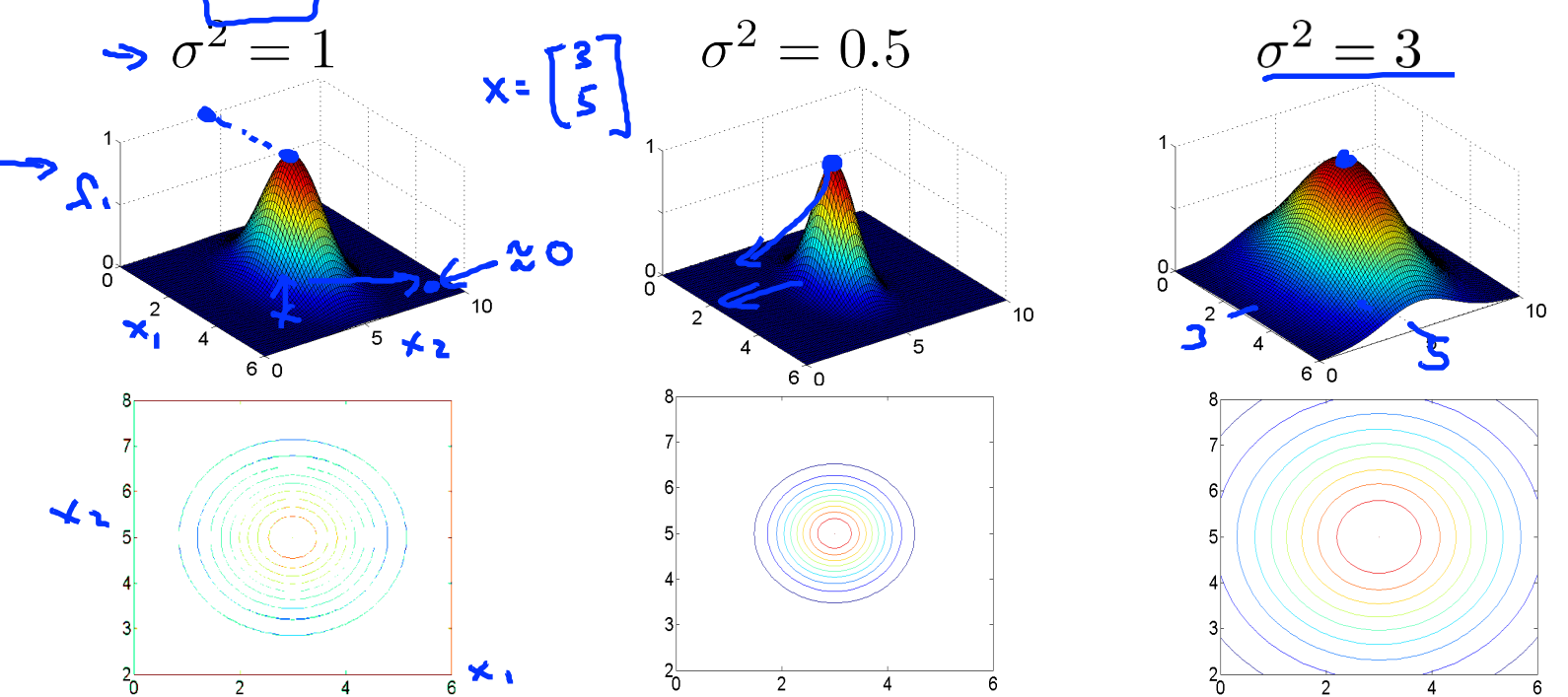
上面的这个表达式就是高斯核函数,那么使用高斯核函数为什么可以达到非线性的表达能力呢?可以看下面的例子:
假设我们的假设函数为
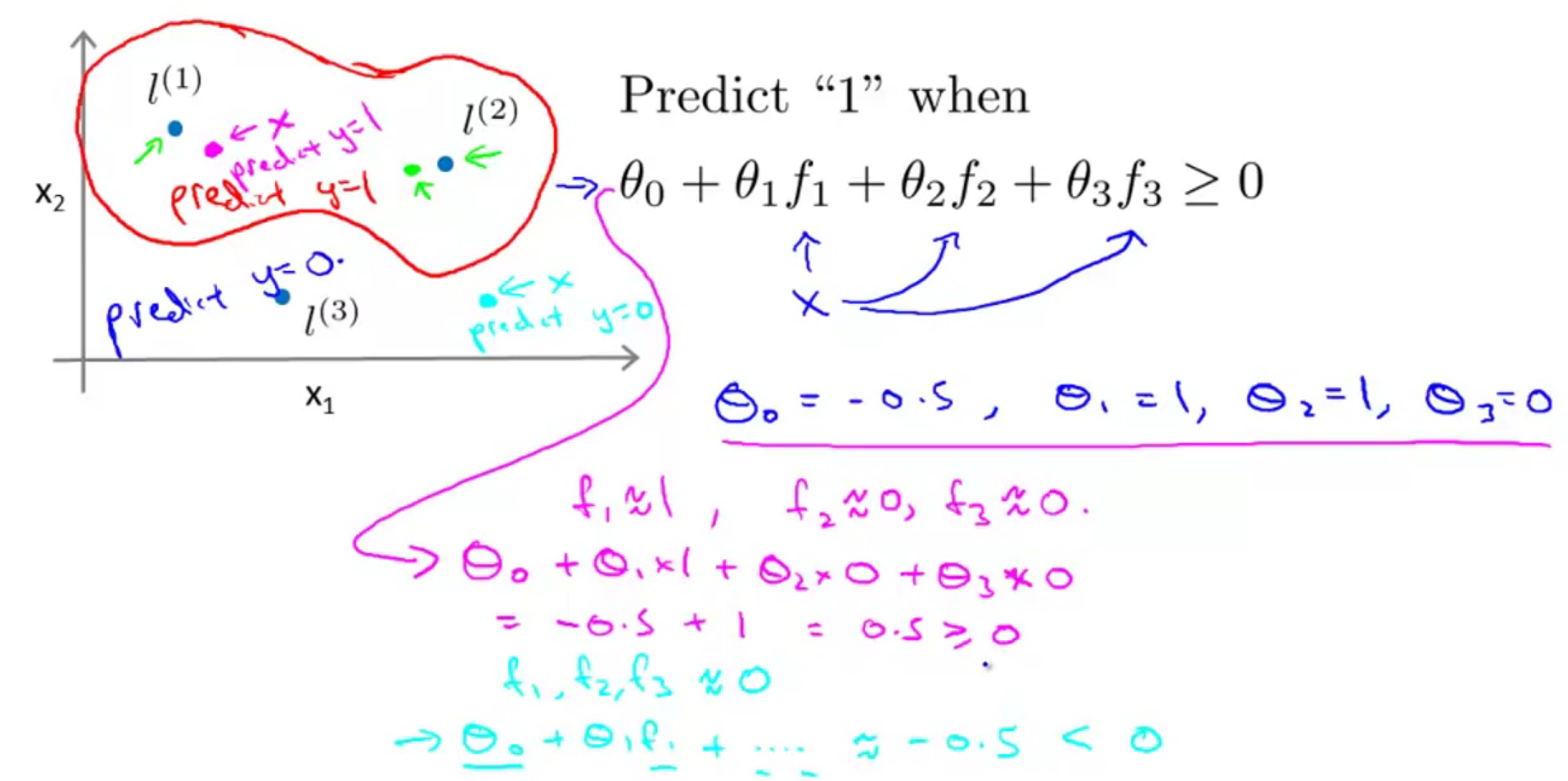
3.2 标记点的选取
前面介绍了为何核函数可以使SVM有非线性表达能力,那么我们应该如何选择标记点呢?我们通常是根据训练集的数量选择地标的数量,即如果训练集中有 m 个实例,则我们选取 m 个标记点,并且令:
下面将核函数运用到支持向量机中,修改我们的支持向量机假设函数为:
在具体实现代码的过程中,我们还需要对最后的归一化项进行些微调整,在计算
3.3 参数对模型的影响

- C是惩罚系数,即对样本分错的宽容度,因为C后面跟的是代价函数,当样本分类错误时代价函数的值就会变大。C越高,则代价函数的变大效果就会被放大,说明越不能容忍出现分错,容易过拟合。C越小,容易欠拟合。C过大或过小,泛化能力变差。
- 如果
设的太小,容易导致过拟合。因为 很小的高斯分布长得又高又瘦,会造成只会作用于支持向量样本附近,对于未知样本分类效果很差,但训练准确率可以很高,(如果让无穷小,则理论上,高斯核的SVM可以拟合任何非线性数据,但容易过拟合)。
四、应用SVM
4.1 其他核函数
在高斯核函数之外我们还有其他一些选择,如:
多项式核函数(Polynomial Kernel)
字符串核函数(String kernel)
卡方核函数(chi square kernel)
直方图交集核函数(histogram intersection kernel)
这些核函数的目标也都是根据训练集和标记点之间的距离来构建新特征,这些核函数需要满足 Mercer's 定理,才能被支持向量机的优化软件正确处理。
4.2 多分类问题
4.2.1 一对多OVA
一对多算法 (one-against-rest/one-against-all)是最简单的实现方法,也是支持向量机多类分类的最早实现方法。构造一系列两类分类机,其中的每一个分类机都把其中的一类同余下各类分划开,然后据此判断某个输入x的归属。假设一共有
4.2.2 一对一 OVO
成对分类法(one-against-one)是基于两类问题的分类方法。它的思想是利用两类SVM算法分别在每两类不同的样本之间都构造一个最优决策面,如果一共k类样本,则需要构造
4.3 SVM与逻辑回归
n 为 特征数, m 为 训练 样本数。
- 如果相较于 m 而言, n 要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
- 如果 n 较小,而且 m 大小中等,例如 n 在 1-1000 之间,而 m 在 10-10000 之间,使用 高 斯核函数的支持向量机。
- 如果 n 较小,而 m 较大,例如 n 在 1-1000 之间,而 m 大于 50000 ,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。

机器学习相关的东西以后可以多多交流呀;
怎么交换大佬的友链呀(~ ̄▽ ̄)~ 我看别人一般都是有4个项目。没看到你的在哪呀
站点名称:浮云翩迁之间
站点地址:https://blognas.hwb0307.com
站点描述:百代繁华一朝都,谁非过客;千秋明月吹角寒,花是主人。
站点图标:https://blognas.hwb0307.com/wp-content/uploads/2022/04/25b2916b5c49db617f5283.jpg
可以呀,欢迎~没听懂4个项目是什么意思
就是别人的友链都有这4条内容呀,但你好像没有指出这4条内容。它们是:站点名称、站点地址、站点描述、站点图标URL
站点名称:Here_SDUT
站点地址:https://fangkaipeng.com
站点描述:退役ACMer · ML炼丹入门学徒 · 准科研人的学习记录
站点图标:https://img.fangkaipeng.com/blog_img/20220422210154.png
很少加友链hhh,所以没搞过这些
已经在我的博客添加你的友链了。欢迎交换喔 🙂