CS231n第七节:理解和可视化CNN
本系列文章基于CS231n课程,记录自己的学习过程,所用视频资料为 2017年版CS231n,阅读材料为CS231n官网2022年春季课程相关材料
1. 可视化模型所学到的
目前已经提出了几种理解和可视化卷积神经网络的方法,作为对于神经网络不可解释性的一种回应。接下来我们将简单介绍一些方法和相关工作。
1.1 可视化激活项
最直接的可视化技术是显示网络在前向传播过程中的激活情况。对于ReLU网络来说,激活图像通常一开始看起来比较粗大和密集,但是随着训练的进行,激活图像变得更加稀疏和局部。用这种可视化方法很容易注意到一个危险的陷阱,那就是一些激活图像对于不同的输入可能输出都是零,这可能表示死亡的过滤器,也可能是学习率过高的症状。
如下图是在AlexNet网络中训练的可视化效果,输入是一张猫的图片。左图是第一层卷积层的激活项的可视化,右图是第五个卷积层的激活项的可视化,每个格子表示一张激活图像,对应某个过滤器。 指的注意的是,激活图像是稀疏的(大多数值是零,在这个可视化图像中显示为黑色),而且大多是局部的。

1.2 可视化最后一层的特征
卷积神经网络的最后一层通常是一个全连接层,通过全连接,最后输出每个类别的得分。比如AlexNet中,最后一个全连接层接受 4096维的输入,输出一个1000维的向量作为类别得分。每张输入到卷积神经网络中的图片最终都会得到一个4096维的向量,我们对这些向量进行最邻近算法,和之前基于像素空间的最邻近算法的结果进行比较,如下图。
可以发现,基于像素空间的最邻近算法通过比较每个图片中相应位置的像素差异来对图片进行归类,所以归为一类的图片知识像素上类似,而不一定属于同一类别。而对4096维的向量进行最邻近算法的结果表示,他们都是属于同一类物体,尽管有些图片在像素上大相径庭。这也说明了,对着4096维的向量进行最邻近算法,实际上就是在这个特征空间中做最邻近算法。卷积神经网络的最后一层成功提取出了一个特征空间,并用一个4096维的向量表示。

1.2 可视化权重
第二个常见的策略是将权重可视化。通常第一个卷积层上的权重最容易解释,因为第一个卷积层是直接在原始图像上运行的,但有时也会可视化展示更深层网络的权重。权重的可视化是很有用的,因为训练有素的网络通常会显示出漂亮而平滑的过滤器,没有任何噪音模式。噪音的引入可能是由于一个网络没有被训练足够长的时间,或者可能是使用了一个非常低的正则化强度,导致过度拟合。
如下图是训练好的AlexNet的第一层卷积层(左)和第二层卷积层(右)的过滤器的可视化效果。请注意,第一层的权重是非常漂亮和平滑的,表明网络收敛得很好。颜色/灰度特征是集中的,因为AlexNet包含两个独立的网络并行训练,这种结构的一个明显好处是,一个网络挖掘高频的灰度特征,另一个网络挖掘低频颜色特征。第二个卷积层层的权重不那么容易解释,但很明显,它们仍然是平滑的、形成良好的、没有噪音的。

下图是一些其他网络的第一个卷积层的权重的可视化。从图中我们可以观察到卷积核在寻找什么特征,可以看出卷积核主要关注的是一些明暗的线条和颜色信息,同时卷积核从不同的角度和位置观察输入的图像,在同一个位置关注不同的特征,比如同一位置有的是绿色有的却是粉色。 这其实和人类的视觉系统早期阶段所进行的是类似的,都是观察物体的边缘和颜色信息。而且,有趣的是,无论输入的是什么数据集的图片,也无论使用什么结构的卷积神经网络,其第一层卷积层的权重都是类似的可视化结果 。

2. 模型的可解释性
2.1 检索能最大限度激活神经元的图像
一种对模型关注内容的可解释性技术是将大量的图像数据集,喂给神经网络,并跟踪哪些图像能最大限度地激活某些神经元。然后,我们可以将这些图像展示,以了解神经元在其感受野中寻找的东西。Ross Girshick等人在 Rich feature hierarchies for accurate object detection and semantic segmentation 中展示了这样一种方法。
如下图是AlexNet的第五个池化层神经元的最大激活图像。白色框内的是特定神经元的感受野,数字表示对应的激活值。可以看出,一些神经元对图像内物体的上半身、文字或镜面高光有比较好的相应。

这种方法的一个问题是,ReLU神经元本身不一定有任何语义。相反,把多个ReLU神经元看作是某个空间的基向量更合适,网络用这些基向量来表示图像块。换句话说,可视化沿着与过滤器权重相对应的(任意)轴,展示了图像云图的边缘。这也可以从卷积神经网络中的神经元对输入空间进行线性操作的事实中看出,所以任何对该空间的任意旋转都是不可行的。这一点在Szegedy等人的 Intriguing properties of neural networks 中得到了进一步的论证,他们沿着表示空间的任意方向进行了类似的可视化。
One problem with this approach is that ReLU neurons do not necessarily have any semantic meaning by themselves. Rather, it is more appropriate to think of multiple ReLU neurons as the basis vectors of some space that represents in image patches. In other words, the visualization is showing the patches at the edge of the cloud of representations, along the (arbitrary) axes that correspond to the filter weights. This can also be seen by the fact that neurons in a ConvNet operate linearly over the input space, so any arbitrary rotation of that space is a no-op. This point was further argued in Intriguing properties of neural networks by Szegedy et al., where they perform a similar visualization along arbitrary directions in the representation space.
2.2 使用t-SNE嵌入
卷积神经网络可以被解释为逐渐将图像转化为一种表示的工具,在这种表示中,类别是可以通过线性分类器分离的。我们可以通过将图像嵌入到两个维度来粗略了解这个空间的拓扑结构,此时它们的低维表示和它们的高维表示具有大致相等的距离比例。许多嵌入方法都是将高维向量嵌入低维空间,同时保持每两个点之间的距离不变。在这些方法中,t-SNE是最著名的方法之一,它始终能产生令人满意的视觉效果。
为了进行嵌入,我们可以选取一组图像,并使用卷积神经网络提取特征向量(例如在AlexNet中,最后的4096维向量在最终的线性分类器之前,可以看做是一个特征向量)。然后,我们可以将特征向量用t-SNE进行降维至2维,由于每个图像对于一个高维的特征向量,所以相应的,每个图像也有得到了一个二维的向量。将这个二维向量作为一个坐标,将所有图片放到对于坐标的网格中,得到一个可视化图像,如下图所示。
从图中可以发现,彼此相邻的图像在CNN表示空间中也很接近,这意味着CNN“认为”它们非常相似。请注意,相似性通常是基于类和语义的,而不是基于像素和颜色的。有关此可视化是如何产生相关代码的更多详细信息,以及不同尺度下的更多相关可视化,请参阅t-SNE visualization of CNN codes。

2.3 遮挡部分图像
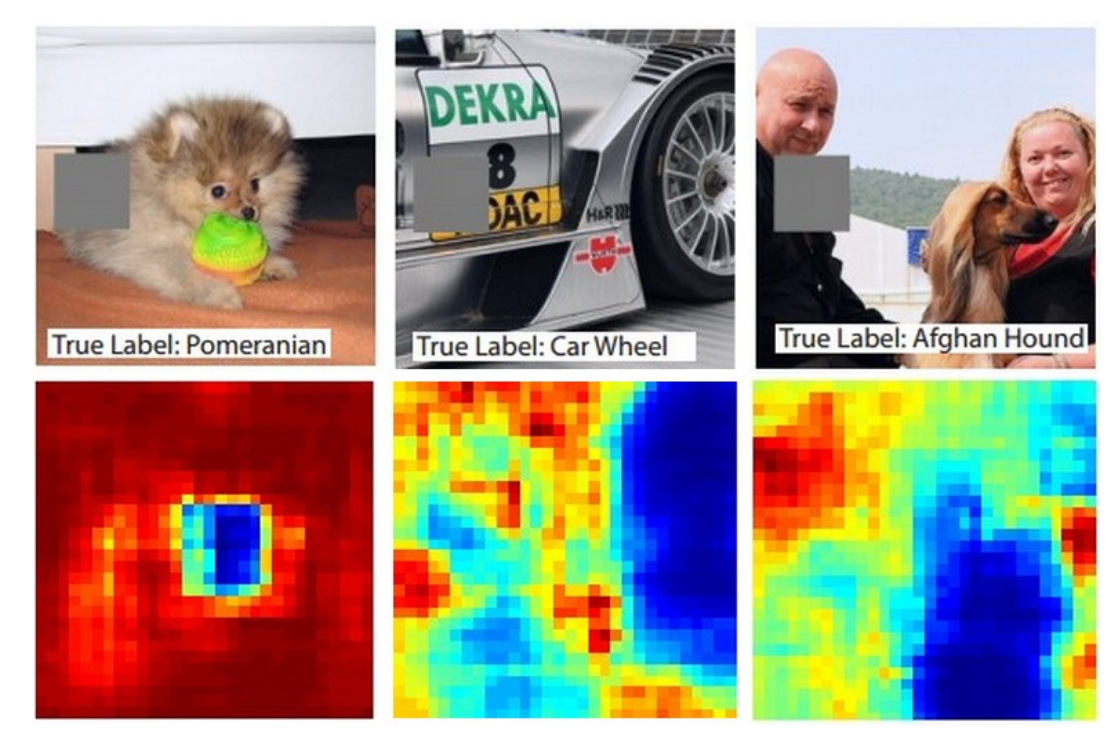
假设卷积神经网络将一张图像分类为一只狗,我们怎么能确定它实际上是在图像中找到了狗,而不是由背景或其他一些杂物得到的分类呢?研究某些分类预测来自图像的哪一部分的一种方法是通过绘制遮盖块来遮挡图像不同的区域以探究预测概率的变化。也就是说,我们迭代图像的各个区域,将图像的一个补丁设置为全零,然后查看类的概率。我们可以将概率可视化为二维热度图。这种方法已经在Matthew Zeiler的著作中得到了应用。
下图展示了三个图像示例。其中,遮盖片的区域显示为灰色。当我们将遮盖片滑动到图像上时,我们记录正确类的概率,然后将其可视化为热力地图。例如,在最左边的图像中,我们看到,当遮盖片覆盖狗的脸时,分类器预测时狗的概率暴跌,因此,可以认为狗的脸是造成高分类得分的主要原因。相反,将图像的其他部分遮盖被认为具有相对微不足道的影响。
2.4 Saliency Maps 显著图
通过计算类别得分(未进行归一化的)对于每个像素的梯度,然后取绝对值后,在RGB三个通道上保留最大的梯度,将每个像素的梯度进行可视化可以得到一张灰度图像,如下图所示,其中白色的点表示梯度大的地方,也就是说改变这些点的值会使得最终的类别得分有很大的变化,也就是说,这些位置的像素对最终类别其决定性作用。从下图中,我们也能看出,这些白色的像素点大致描绘出了物体的轮廓。这也从侧面说明了,卷积神经网络提取出了物体的一些特征。

由于,白色的像素点可以描绘出物体的轮廓,所以使用显著图,可以在没有任何标签数据的情况下进行语义分割,使用的分割算法叫做Grabcut,但是它的在神经网络中的效果其实并不是非常好,图如下。

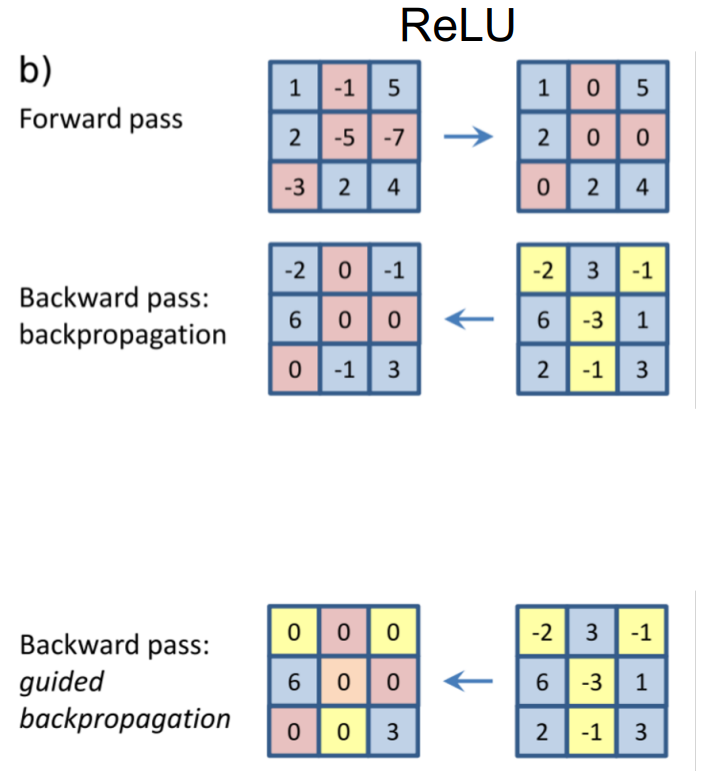
2.5 引导式反向传播
如果我们想要对中间层的某个输出进行可解释性分析,一种直观的方法是可以采用显著图,计算中间输出值关于输入像素的梯度,然后将其进行可视化,这就和反向传播很像了。 但是还有一种奇怪的反向传播规则,即引导式反向传播,使用这种方式可以使得可视化的图片更加干净好看。其规则是,在每个ReLU层只反向传播正梯度,如下图所示:
其结果如下图所示,可以看出卷积神经网络中也提取出了图片中的关键特征。

3. 梯度上升 Gradient Ascent
3.1 简述
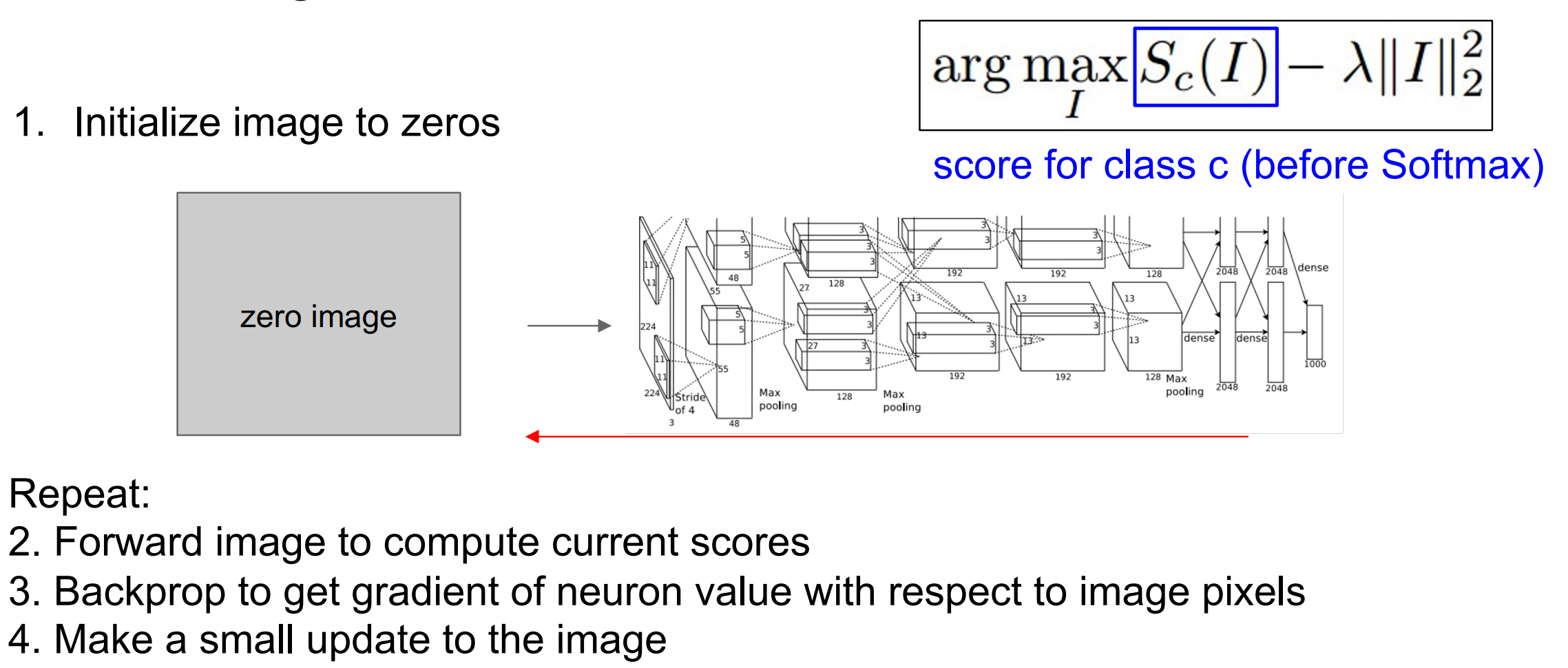
前面的显著图和引导式反向传播关注的都是输入像素对某个输出值的影响程度。如果我们在一些输入图像上移除这些依赖性,那么什么类型的输入可能会激活这个神经元呢?也就是说,我们现在反过来考虑这个过程,考虑什么样的输入会导致最大化某个类别得分的值。可以通过梯度上升算法来解决这个问题。
在训练神经网络的时候,我们使用梯度下降来更新权重,使得损失最小化。现在我们固定网络的权重不变,使用梯度上升来改变输入图像的像素值,以此最大化某些中间神经元或者最终类别得分的值。同样,我们也需要一些正则化项。类似梯度下降中,正则化项用于惩罚权重使其避免过拟合于数据集,在梯度上升中,正则化项用于防止我们生成的图像过拟合于一个特定的网络。也就是说,我们的目标包含两项,一项是尝试最大化中间神经元的输出或者某个类别得分的值,另一项是为了使得生成的图像看起来比较正常 ,即符合自然图像的统计数据,即下图所示的目标公式。
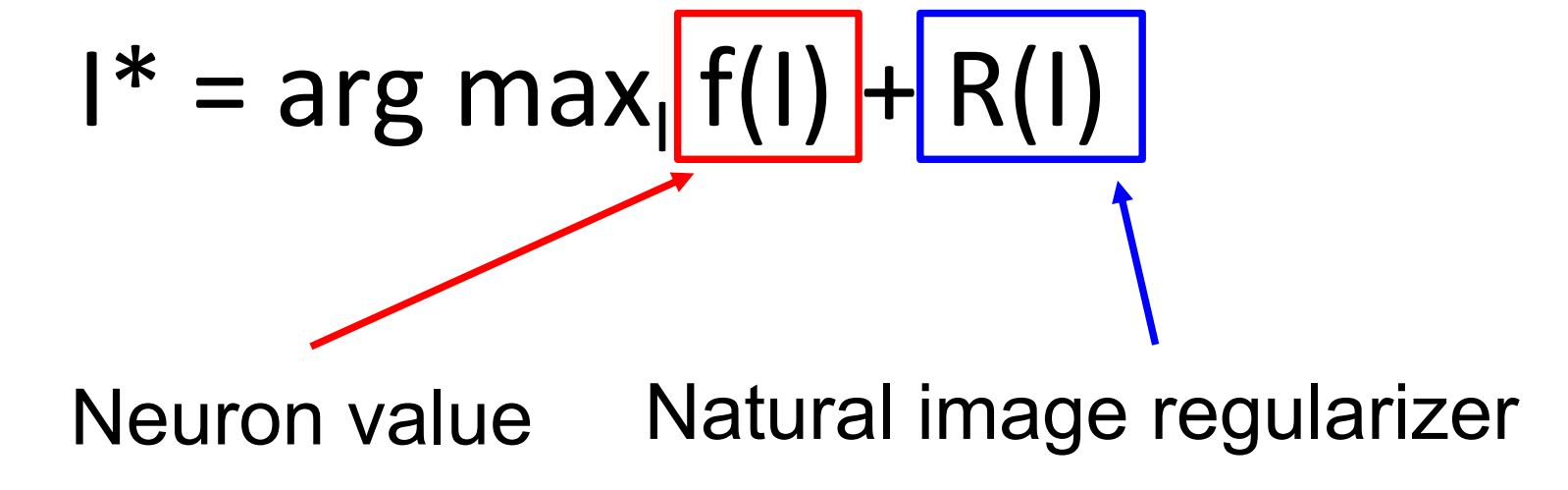
3.2 算法流程
3.3 正则化项的选择
L2正则化
一种最简单的正则化项就是惩罚生成图像的L2范数,即惩罚每个像素的L2范数。使用L2正则化其实在语义上没有什么意义,但这是在论文中使用的第一种正则化方法。使用L2正则化后的生成图像如下,看起来虽然有点抽象,但还是能依稀看出一些来的。

改进的L2正则化
在L2正则化的基础上,在优化的过程中,定期对图片进行高斯模糊,同时将图片中的小数值替换成0,将小的梯度也改为0,这样就得到了更加清晰的图像,这些图像就是最初随机初始化的四张图像经过训练后的结果:
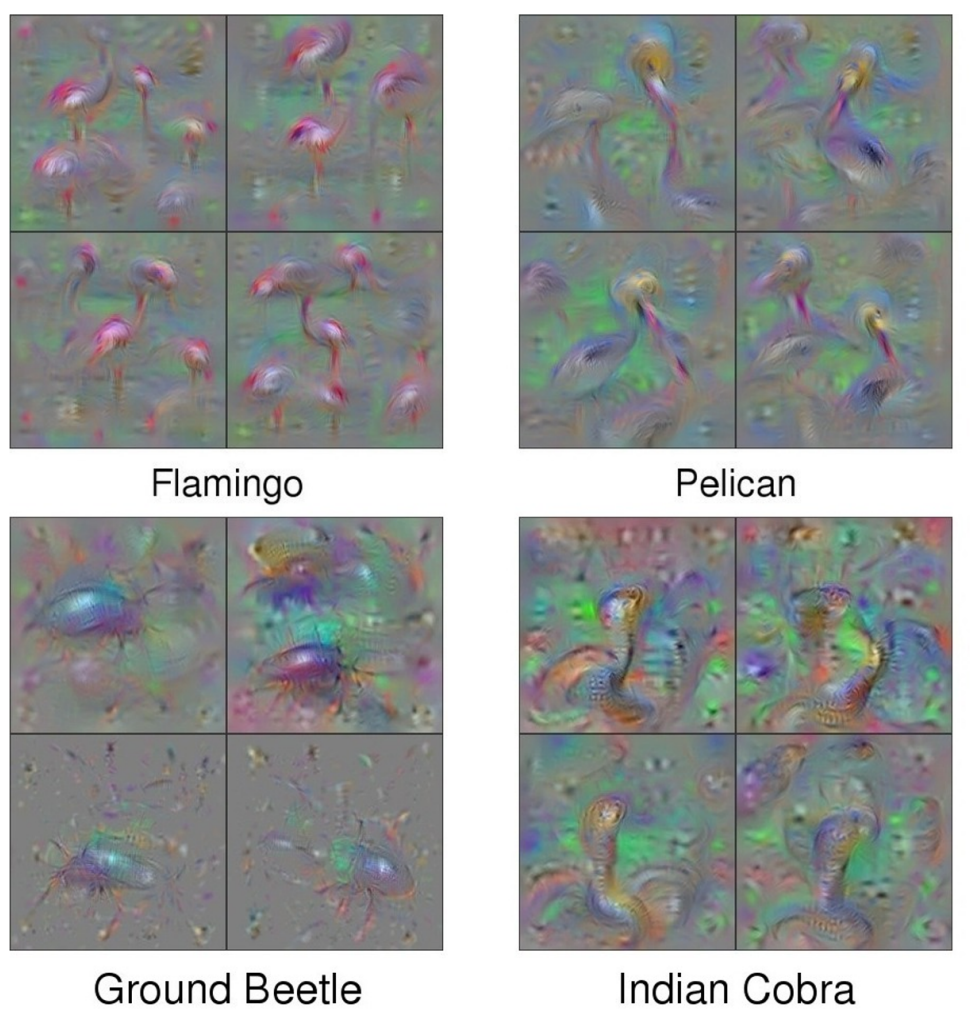
同样,我们可以用相同的方法来可视化中间层的特征,寻找神经网络在提取什么特征 :

3.4 多模态可视化
在进行优化的时候将多模态考虑进去,对于一个类别的图形运行聚类算法,将其分成几个小类,然后使得每张生成的图像朝着某个小类别去最大化,如下图所示,都是杂货铺的图像,但是可以将这些杂货铺的图像分成两类。一类是对货物的特写,另外一类是杂货铺的全局,包括货物的总览,店铺的整体以及顾客等,这两类同属于杂货铺类。然后对于生成的图形,上面的四张在优化的过程中朝着特性这一类图片最大化,下面四张朝着全局图片最大化。下图左就是生成的图像,右边是原数据集中的图像。

4. 风格迁移
4.1 Deep Dream
Deep Dream 通过改变输入图像的像素值,尝试放大网络中某一层的神经元的特征,得到了一些有趣的图像。具体来说,它是这样进行的:
- 前向传播至某一特定的层就停止继续传播,得到特征值。
- 将该层的梯度替换成特征值。
- 进行反向传播
- 更新图片像素值

对于这张天空的图片,一些效果图如下:
这张图是最大化了前面几层的特征,所以生成的图像中多是一些线条的特征。

这张图像是最大化了一些深层的特征,可以看出都是一些具体的东西,并且这些特征也相互发生了融合,对于这些融合形成的“物种”,官方还取了一些名称。在这些特征中我们可以发现,狗的特征出现的较多,这是因为训练集中狗的图片占大多数。

4.2 特征反演
给定一张图像的特征向量,生成一个新的图像,满足:
- 和给定的特征向量匹配
- 看起来比较自然(先验图像,正则化)

下图是在VGG-16中重建图像的结果,可以看到,在浅层图像的大部分细节还是能保留的,但是随着网络加深,图像的细节开始变化。

4.3 纹理合成
介绍
纹理合成问题是一个很经典的计算机问题,就是给出某种纹理的一小块图块,需要生成一个更大的图像,拥有相同的纹理。
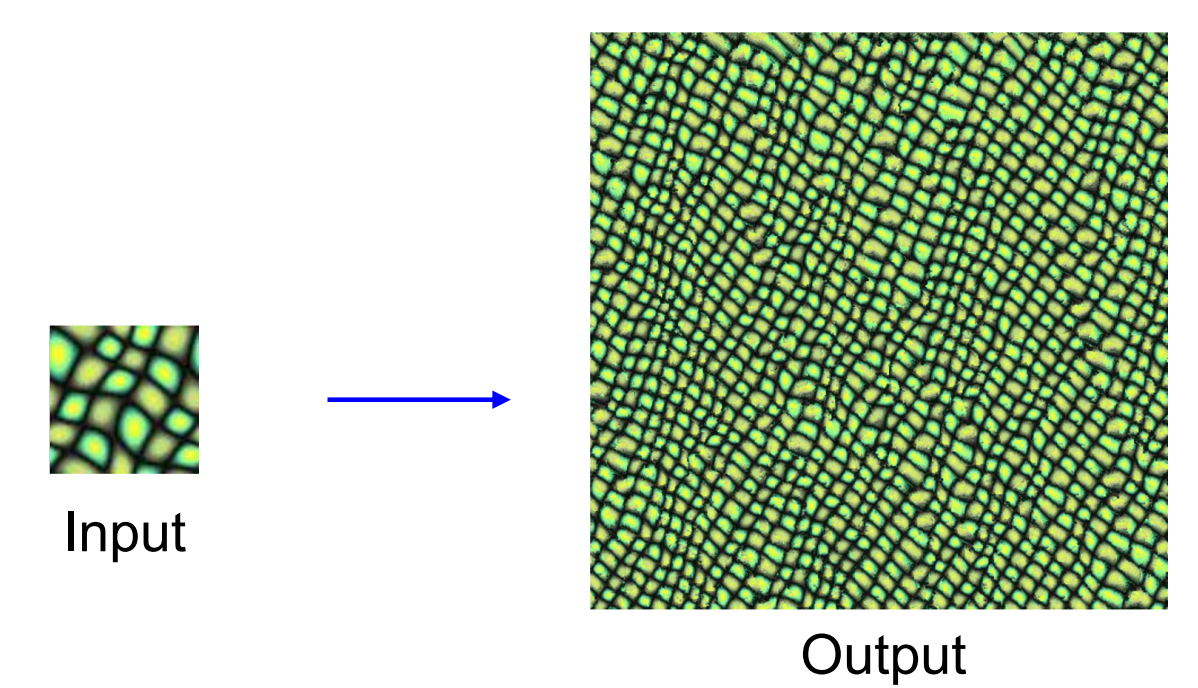
目前,有很多不用借助神经网络的方法就能生成纹理。这些算法对于简单的纹理有很好的效果,但是在复杂纹理上表现很差了。在2015年有一篇论文尝试将神经网络应用到纹理合成上。最终将问题转换成梯度上升的过程,类似于特征映射图,即将我们可以看到的图像上的特征映射到其他图像上。
Gram 格拉姆矩阵
为了使得在卷积神经网络中进行纹理合成,使用到了Gram 矩阵,用来提取网络中的特征,Gram矩阵的计算方式如下:
-
首先,将需要提取纹理特征的图片输入到网络中,假设某一层神经网络会输出一个
的特征矩阵,即 个位置的特征,每个位置的特征由一个 维的特征向量表示。 -
对任意两个
维向量进行外积,得到一个 的矩阵,这个矩阵代表了这两个特征向量代表的特征的同现关系。也就是说如果这个 的矩阵中某个位置 的值非常大,这就意味着输入向量的位置索引为 的元素值非常大,也就捕获了两个不同位置上的特征中,哪些特征倾向于在空间中的不同位置一起激活。 外积举例:
-
将所有特征向量一对一地的外积后将所有结果进行求平均,得到Gram矩阵。
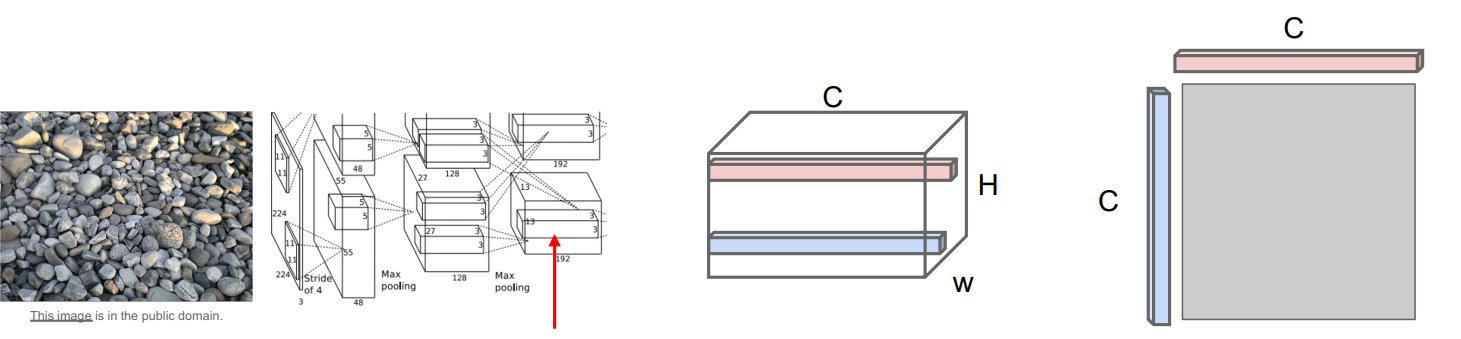
值得注意的是,Gram矩阵丢弃了特征矩阵中的空间信息,因为最终他对所有的特征向量外积进行求了平均,所以他只是捕获了特征间的二阶同现统计量。并且Gram矩阵的计算时很高效的,直接将
流程
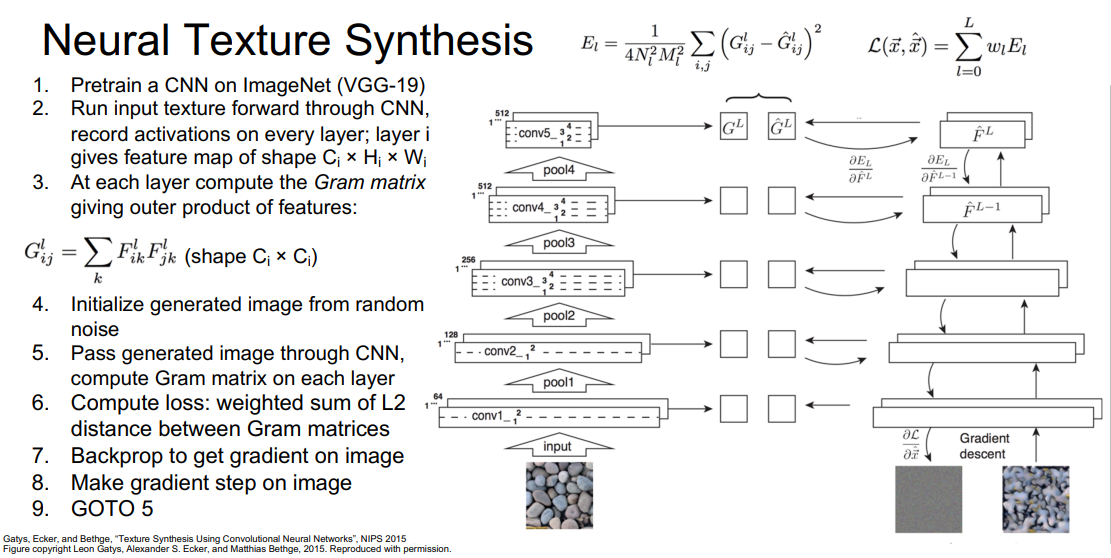
具体流程如下:
- 使用一个在ImageNet上预训练的CNN模型(如VGG-19)
- 在CNN中前向传播需要合成的纹理图片,每一层得到一个特征图,大小为
- 每一层计算一个Gram矩阵,每个矩阵的大小为
- 初始化一个随机噪声的生成图片
- 在CNN中前向传播这个生成图片,并计算每一层的Gram矩阵
- 计算损失值:生成图片的Gram矩阵和输入图片的Gram之间的经过加权的L2距离
- 使用梯度上升,计算损失值关于生成图片每个像素的梯度
- 根据梯度修改每个像素值
- 跳转到第5步重复进行。
结果
如下图是运用上述方法,在不同层生成的图像,可以发现,在浅层生成的图像捕捉到了输入图像的颜色纹理特征,但是空间结构没有很好地保留,而在更深层的网络中,生成的图像很好地保留了空间结构。

下图是将输入的纹理图像换成了一些艺术图片中,得到了一些有趣的图片:
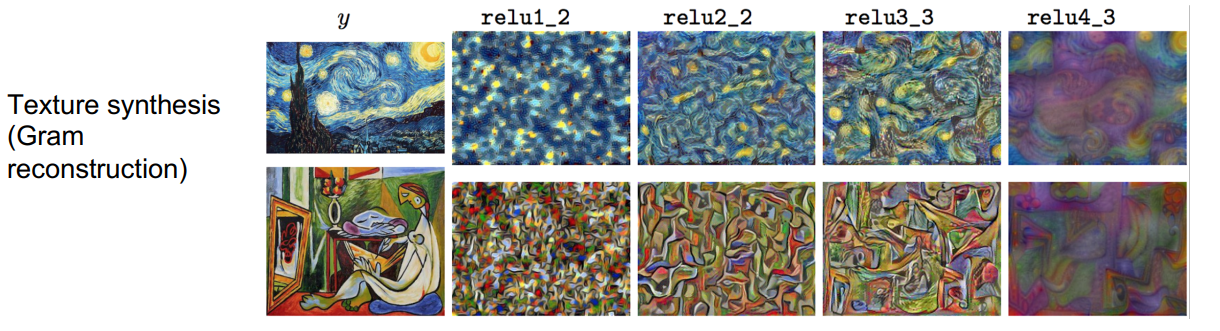
当你将纹理生成和特征反演相结合后,就可以实现风格迁移,如下图所示。
首先选取一个风格图片和一张内容图片,你想将风格图片中的风格迁移到你的内容图片中。将风格图片和内容图片都送入神经网络中运行,计算得到风格图片的Gram矩阵和内容图片的特征值。通过最小化内容图像的特征重构损失和风格图像的Gram矩阵损失,使用梯度上升改变生成图像的像素值,最终生成了一张有趣的图像。
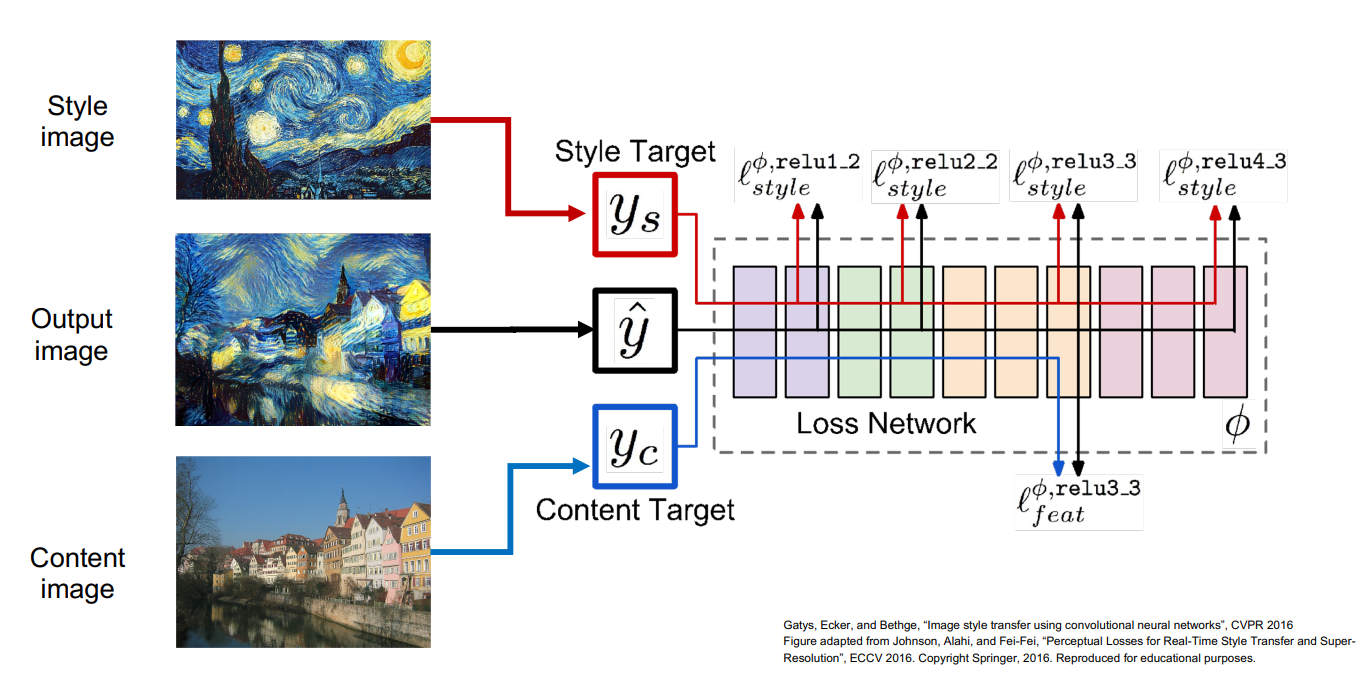
不同于前面的DeepDream,使用这种方法可以很好的控制最终期望的结果,而不是将所有的特征一股脑的放到生成图像中。
参数调整
下图是调整内容图片的损失占比和风格图片的损失值占比导致生成图片的变化。

下图是在运行前将图片大小进行缩放,使得风格发生变化。

下图是将多种风格混合生成的图片。

问题及解决方法
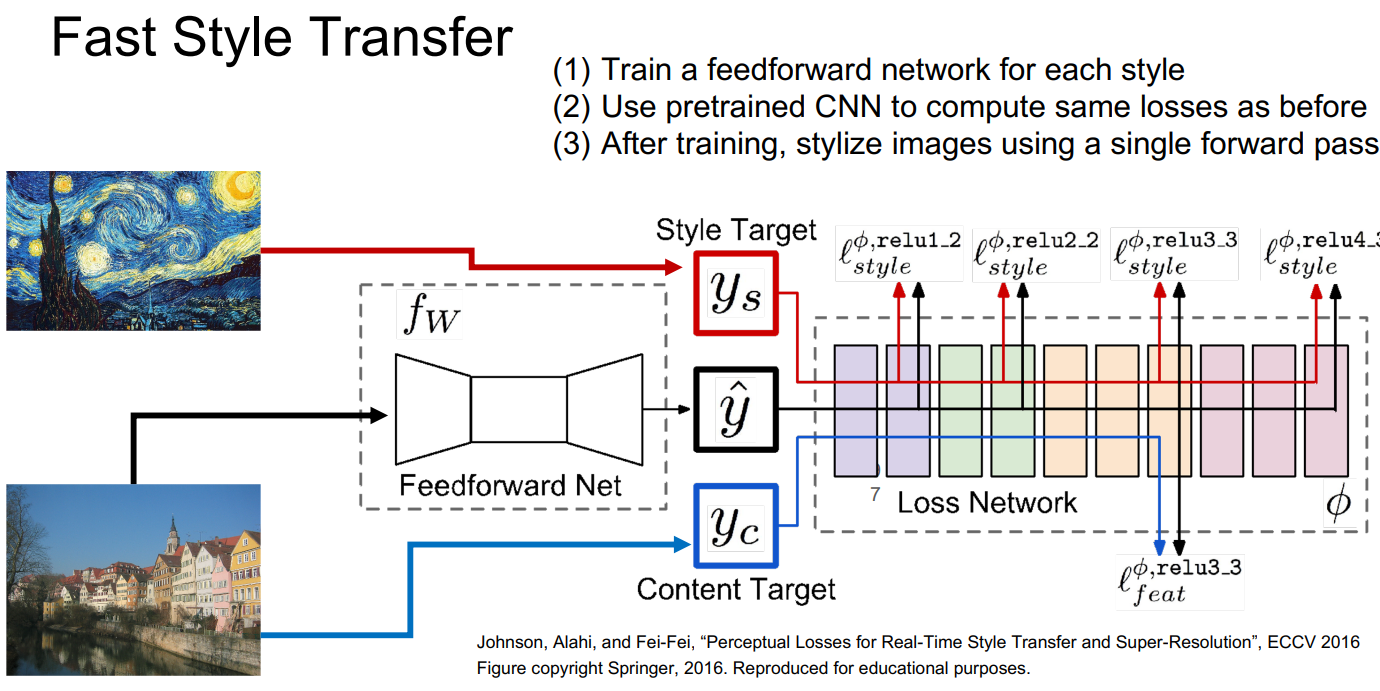
这种风格迁移的方法需要在VGG中进行大量的前向传播和方向传播,非常慢!
解决方法是,训练一个额外的网络用于实现风格迁移。即不同于之前的每次将风格图片和内容图片一起输入网络进行训练,采用固定风格的办法。即预训练一个特定风格的前馈网络,然后使用这个前馈网络就可以直接输出特定风格的图像。
5. 其他内容
下面罗列一些可视化不同的网络内容的方法论文:
