本文为论文Rotated Binary Neural Network的精读总结,该论文发布于NeurIPS 2020,提出了RBNN,通过旋转来缩小二值化后的误差,效果较好。文中部分表述为原文翻译,所有图片除非特别注明,都来自原论文。本文在多平台同步,进入主站获得更好体验。
论文链接:https://arxiv.org/abs/2009.13055
作者:Mingbao Lin, Rongrong Ji, Zihan Xu, Baochang Zhang, Yan Wang, Yongjian Wu, Feiyue Huang, Chia-Wen Lin
1. Introduction
1.1 DNN介绍
DNN(deep neural networks)在计算机视觉任务中取得了很好的效果,比如图像分类、目标检测、实例分割等。不过,大量的参数和计算的复杂度带来的高存储和高计算性能的限制,使得DNN很难应用在一些低性能的设备上。为了解决这个问题,提出了很多压缩技术:network pruning,low-rank decomposition,efficient architecture design,network quantization。其中,network quantization将全精度(full-precision)网络中的权重和激活值转换成低精度的表达。其中一个极端的情况就是 binary neural network(BNN 二值神经网络),它将权重和激活值的数值限制在两个取值:+1和-1。如此,相比全精度的网络,BNN的大小可以缩小32倍(全精度网络中一个双精度数值用32bit表示,BNN中一个数值用1bit表示),并且使用乘法和加分的卷积运算可以使用更高效的 XNOR 和 bitcount 运算代替。
1.2 BNN介绍
BNN中的卷积运算如下图所示(图源自 Binary Neural Networks: A Survey ),XNOR表示同或门,即值相同为1,不同为0,由于BNN中只有+1和-1两种数值,所以将-1看做0进行运算,对照真值表我们可以发现,对取值为+1和-1的两个变量进行乘法运算,等价于对其进行XNOR运算,于是就可以用XNOR代替卷积中的乘法运算。下面我们要将XNOR的结果相加,这里使用bitcount来代替加法运算。bitcount表示计算输入中1的个数,下图中对xnor的结果进行bitcount,得到1的个数为3,并且卷积核的大小是已知的(这里为9),我们就可以计算出XNOR运算后的求和结果:
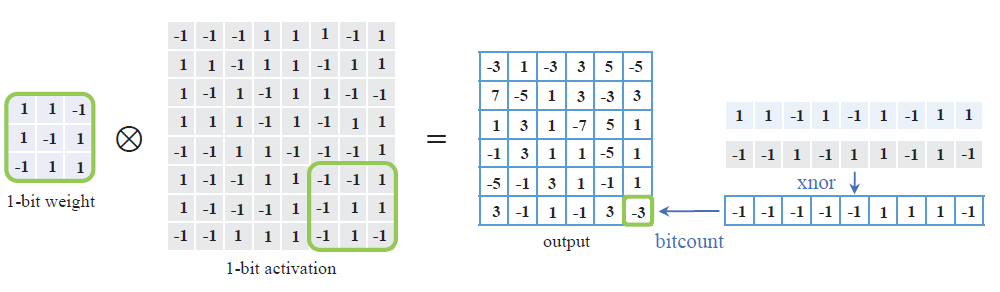
1.3 目前难点
基于上述的两个优点,BNN受到了大量的关注,不过BNN还有一个难点就是如何缩小全精度神经网络和其二值化后版本的误差。一个主要的问题就是全精度的权重向量
不过
所以,

并且,论文中指出,角度偏差
此外,BNN通过学习可以获得的信息上限为
个人理解: 当翻转的概率为50%时,无论初始权重中+1和-1的分布比例是多少,在以50%的概率翻转后都会平均分布,此时类似于质量均匀的硬币,此时的不确定性最大,信息熵就最大。
1.4 解决方案
论文中提出了 Rotated Binary Neural Network (RBNN) 来减少由角度偏差带来的量化误差。论文中一共提出了4个新的技术:首先是提出了一个角度对齐方案(angle alignment scheme),通过学习一个旋转矩阵,在每一个训练的epoch前将将全精度权重向量旋转到其二元超立方体的几何顶点上。为了降低时间和空间的复杂度,论文中没有直接学习一个大的旋转矩阵,而是介绍了一个 bi-rotation formulation 来学习两个较小的矩阵作为代替。于是,就可以交替进行优化的步骤,学习旋转矩阵和二值化参数矩阵,以此减小角度偏差带来的量化误差和二值化前后的模长误差。此外,为了摆脱优化过程中陷入局部最优解的可能性,论文中在训练时,还会动态调整旋转矩阵的参数。上述提出的旋转方案不仅可以减小角度偏差带来的量化误差,还能实现大约50%的权重翻转的概率,以此获得最多的信息。最后,论文中还提出了一个 training-aware approximation of the sign function 用于反向传播时计算梯度。
2. Approach
2.1 BNN
对于一个CNN网络,我们定义第
其中
2.2 RBNN
考虑在每一个训练epoch开始前,对
同时,两向量夹角的cos值也称为两向量的余弦相似性,用于评判两个向量角度距离,值越接近1表示角度越小,代入到二值化前后的向量中,可以得到角度偏差:
其中
我们可得:
这里的推导用到了两个性质:
为了解决这个问题,受到Kroneckr product 克罗内克内积的启发,提出了一个 bi-rotation 方案,使用两个更小的旋转矩阵
其中的
最终,我们可以得到我们的优化目标:
2.3 Alternating Optimization
由于优化目标对于
1)
固定
由于
2)
固定
其中,
3)
固定
其中,
在实验中,交替更新三个变量,在三个循环后就可以达到收敛,因此,是非常高效的一种实现方式。
3.4 Adjustable Rotated Weight Vector
使用旋转矩阵对权重向量进行旋转调整后可以缩小权重向量二值化前后的角度偏差,我们可以令旋转后的权重向量为
如下图所示,其中绿色向量表示原权重向量的位置,黄色向量表示旋转后的位置,蓝色表示权重向量二值化后的位置,紫色为引入自调整策略后旋转后的向量的位置。图a表示转过头的情况,此时
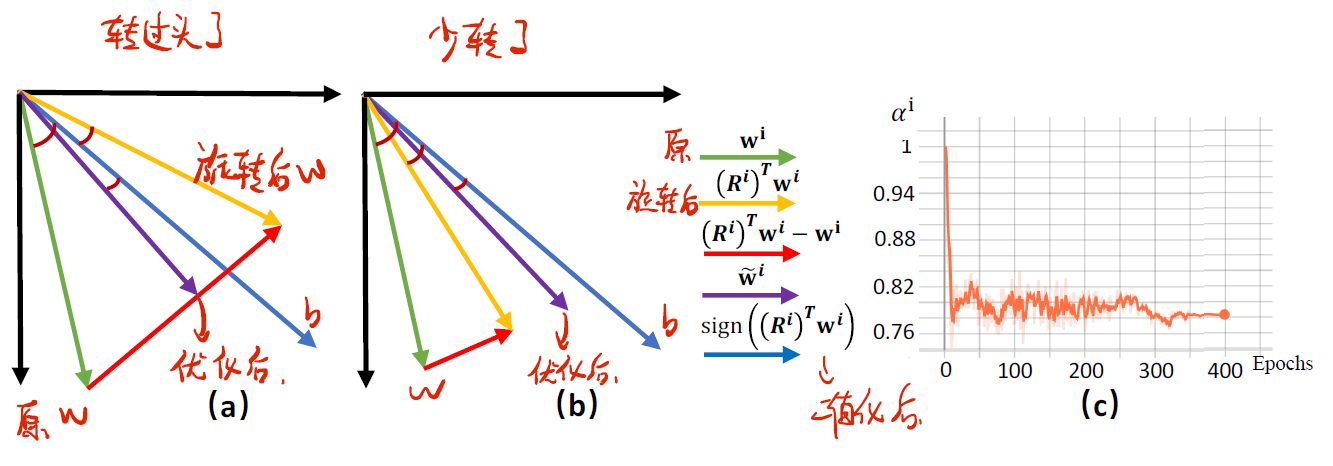
总的来说,在每个训练epoch的一开始,我们固定
3.5 Gradient Approximation
由于 sign 函数的导数几乎处处为0,这就使得训练变得很困难,为了解决这个问题,文献中提出了各种梯度近似方法,以实现梯度更新,比如说straight through estimation , piecewise polynomial function , annealing hyperbolic tangent function , error decay estimator 等,本文提出了一个 training-aware 的近似函数来代替sign函数:
其中
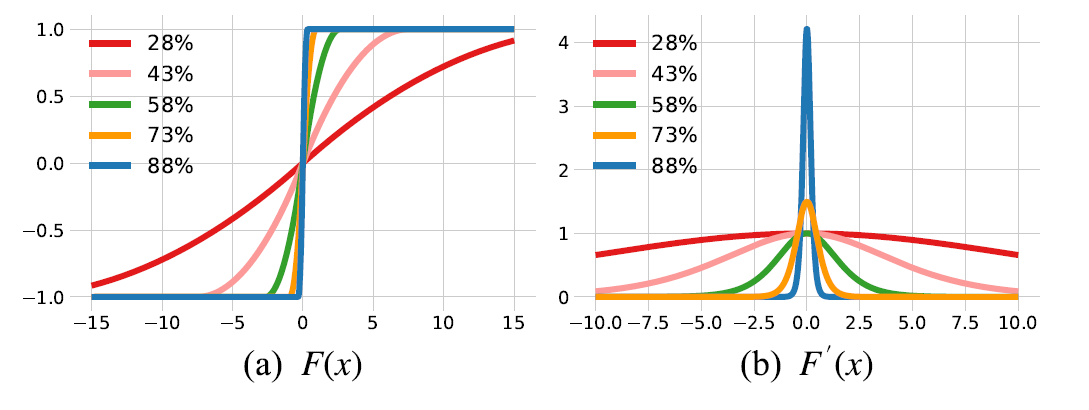
可以看到,在训练的一开始几乎处处都存在梯度,这可以克服sign的缺陷,使得整个网络都可以进行更新。而随着训练的进行,函数图像逐渐近似 sign 函数,这可以保证二值化的特性。因此,这样的近似函数是 train-aware,即可以感知训练进度的。到此,我们就可以写出损失函数关于激活值和权值的梯度:
其中:
此外,
其中,
3. Experiments
对RBNN在多个网络和多个数据集中进行了验证,实现过程中,除了第一层和最后一层,所有的卷积层和全连接层都进行了二值化,并使用SGD作为优化器。
3.1 Experimental Results
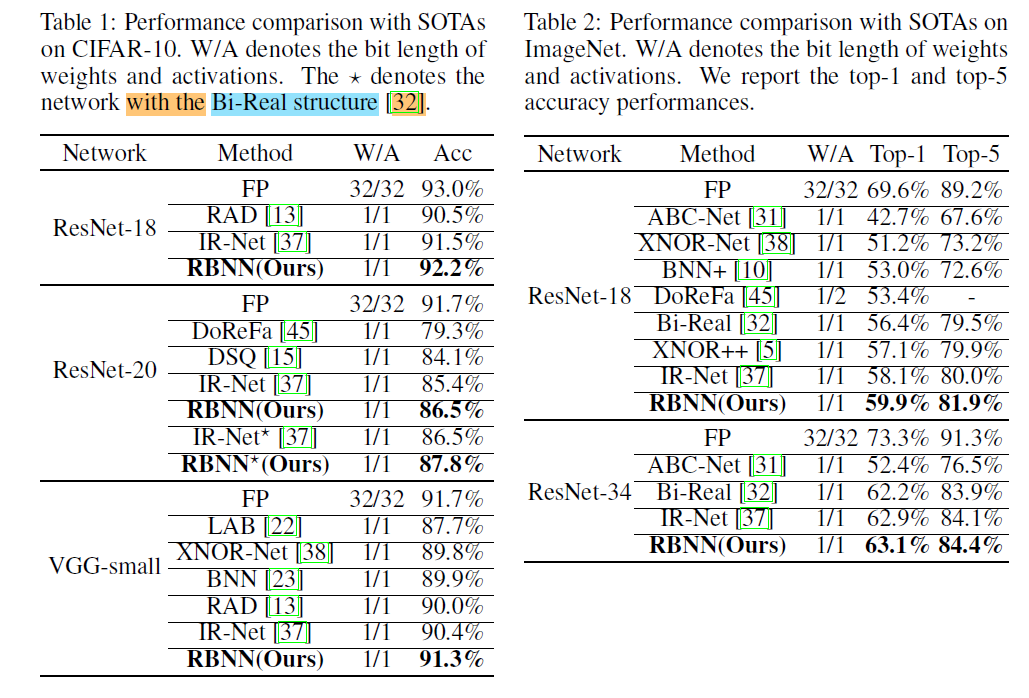
3.2 Performance Study
上一节展示了RBNN与其他SOTA网络的精度对比,可以看出RBNN的效果很好。这一节主要研究不同部分对RBNN的影响。本节所有的实验都是在CIFAR-10数据集上,使用ResNet-20以及Bi-Real结构的RBNN作为网络模型。
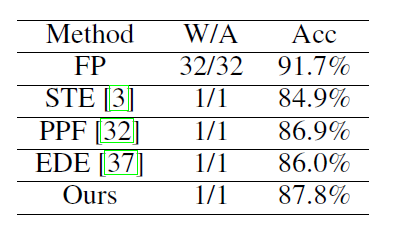
下表展示了使用RBNN作为模型,采用不同的梯度近似函数,包括STE、PPF、EDE以及本文提到的近似函数。可以看出,本文提出的表现效果最好,这也验证了本文提出的近似函数的正确性。
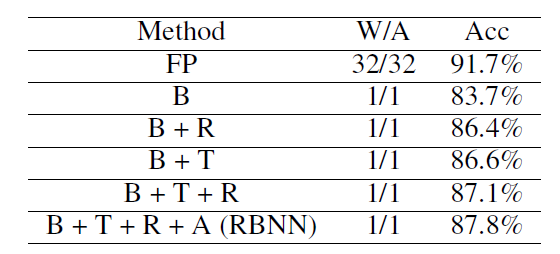
接着又进行了一次消融实验(ablation study),如下表所示,使用XNOR-Net作为网络模型(用B表示),然后再XNOR-Net中逐渐添加 权重旋转(R),training-aware 近似器(T),自调整策略(A),结果如下,可以证明,每一个部分都对精度的提升起到一定的作用。
3.3 Weight Distribution and Flips
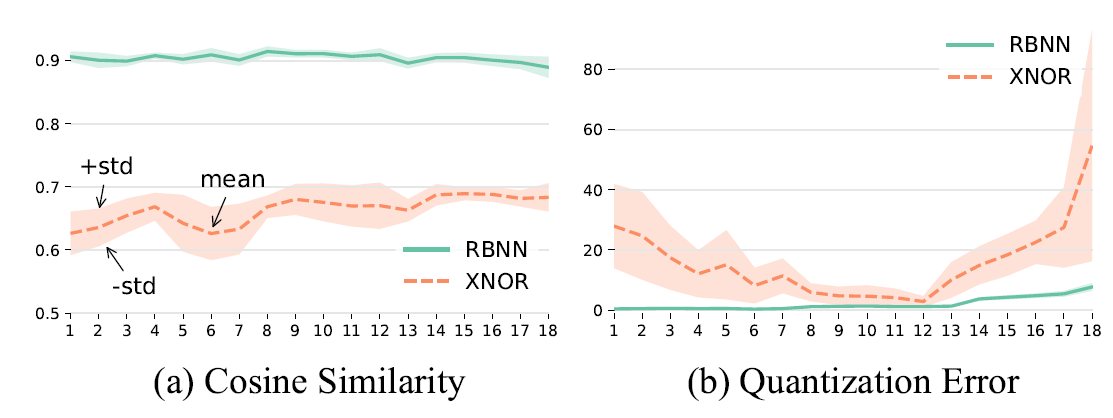
下图的直方图展示了训练后的XNOR网络和RBNN中权重在二值化之前的分布情况。我们可以看到,在XNOR中,权重在零点中心附近紧密地混合在一起,其值的大小仍然远远小于1,这样就很可能在二值化的时候造成误差,因为权重的值之间数值差距小且大部分为0,而在RBNN中,权重以0为分界点线,基本均匀分布在两侧,且值之间的差异较大.

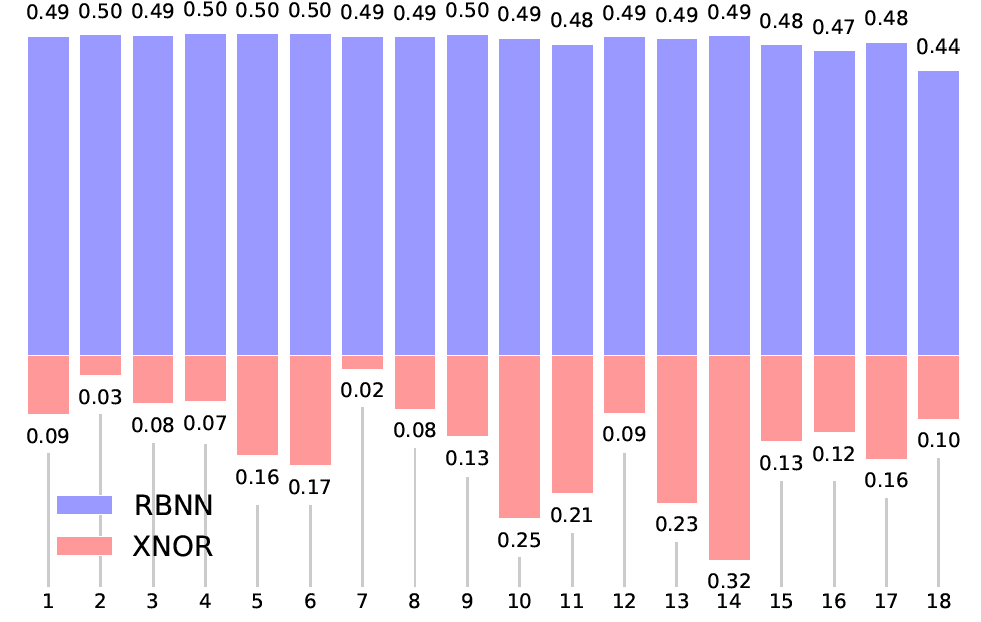
前面介绍过,当权重翻转的概率为50%的时候,BNN的学习能力达到最大。我们比较RBNN和XNOR-Net中在ResNet-20的每一层权重的翻转概率,如下所示,可以发现RBNN翻转的概率都在50%左右,而XNOR的翻转概率都普遍较低。这也说明了RBNN在训练时可以获得尽可能多的信息。
4. Conclusion
在本文中,分析了角度偏差对二元神经网络量化误差的影响,并提出了旋转二元神经网络(RBNN),以实现在每个训练epoch开始前旋转权重向量,使旋转后的向量与其二值化后的向量之间的角度对齐。我们还引入了一个涉及两个较小旋转矩阵的方案 bi-rotation,以减少学习大旋转矩阵的复杂度。在训练阶段,我们在反向传播的过程中,利用梯度来动态地调整旋转的权重向量,以克服bi-rotation优化中潜在的局部最优解的问题。我们的旋转通过实现大约50%的权重翻转,使学习BNN的信息增益最大化。为了实现梯度传播,我们设计了一个training-aware的函数来近似sign函数。大量的实验证明了我们的RBNN在减少量化误差方面的功效,以及它比几个SOTA的优势。
5. Broader Impact
优势:
二元神经网络的研究者可能从我们的研究中受益。所提出的旋转二元神经网络(RBNN)提供了一个新的视角,通过减少角度偏差来减少量化误差,这一点在以前的工作中被忽视。随着代码的公开,我们的工作也将帮助研究人员对DNN进行量化,从而使深度模型可以部署在资源有限的设备上,如手机。
劣势:
activation和其二值化之间的角度偏差仍然是一个待解决的问题,因为本论文中提出的RBNN不适合在激活值上,因为这会增加推理所需的计算资源。
结论:
网络量化的失败不会带来严重的后果,因为与其他SOTA相比,我们的RBNN造成的精度下降较少。
数据偏差:
提出的RBNN与数据选择无关,所以它不存在数据偏差问题。
