CS231n第十二节:强化学习
本系列文章基于CS231n课程,记录自己的学习过程,所用视频资料为 2017年版CS231n,阅读材料为CS231n官网2022年春季课程相关材料
本节将介绍一些强化学习相关的内容。
1. 强化学习
1.1 定义
如下图所示,就是强化学习的工作过程。首先,存在一个环境,和一个代理,环境先给代理一个状态
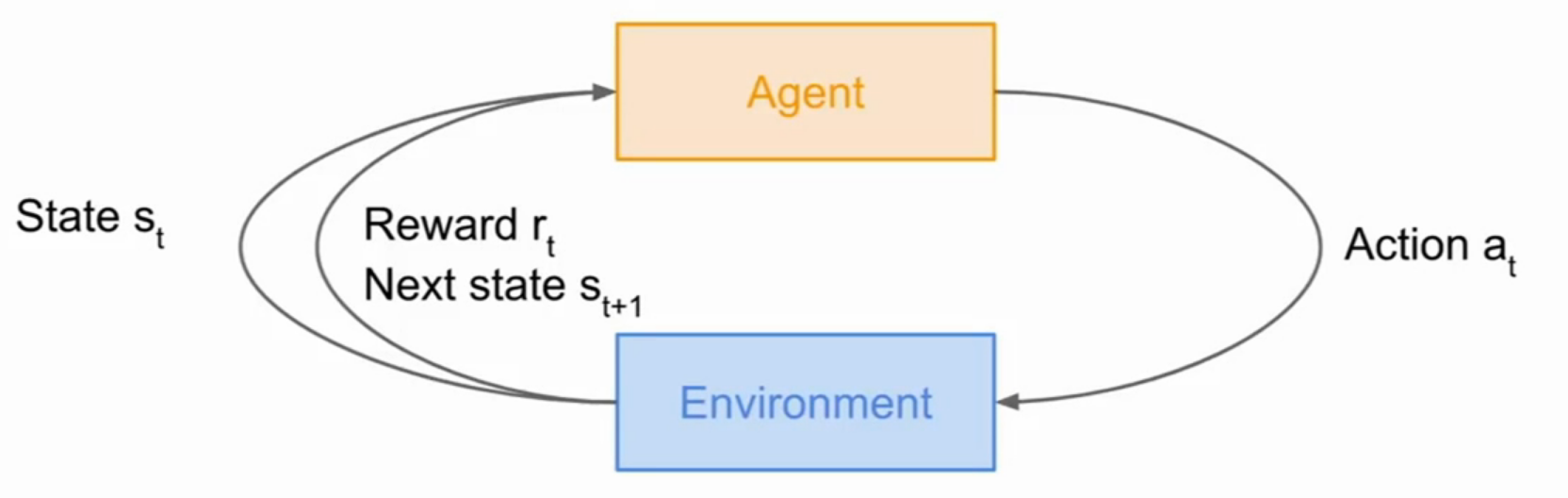
1.2 应用
强化学习有很多的应用,举几个比较常见的例子:
小车平衡问题
目标:平衡正在移动的小车上的杆使其处于上方。
状态:杆与水平线的角度,杆运动的角速度,小车位置,小车水平速度。
动作:给小车施加横向的力。
奖励:每一时刻,如果杆位于小车正上方,则得1分。

机器人移动问题
目标:让机器人学会自己向前移动
状态:关节的角度和位置
动作:施加在关节上的力矩
奖励:每一时刻如果机器人向右前方前进,则得1分

街机游戏
目标:在游戏中获得更高的分数
状态:当前游戏的元素像素值
动作:游戏中的控制,比如前后左右
奖励:由每一时刻游戏得分的升降决定

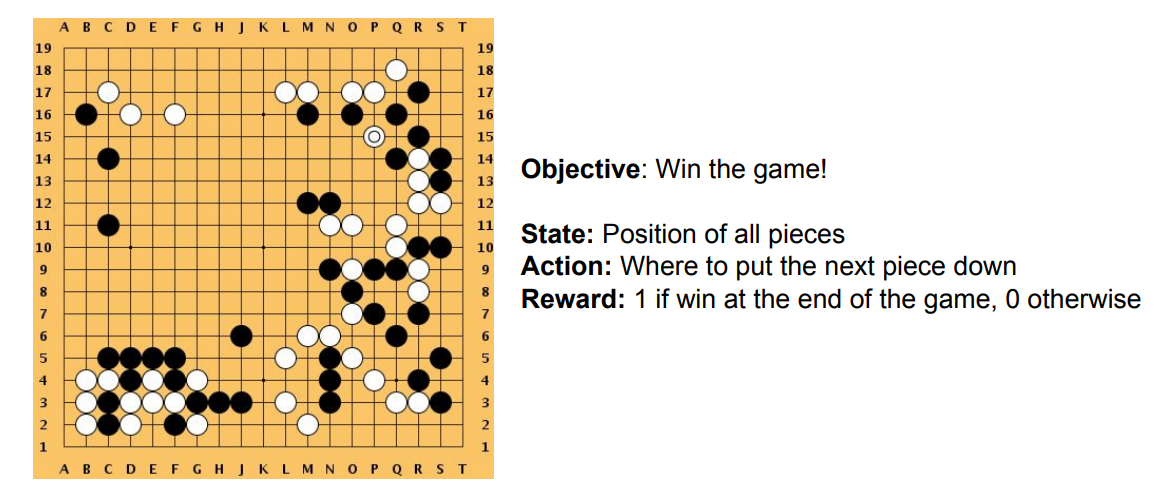
围棋
目标:获得游戏的胜利
状态:每个棋子的位置
动作:下一步应该下在什么位置
奖励:如果最终游戏胜利则得1分,否则0分
2. 马尔科夫决策过程
2.1 定义
马尔科夫决策过程就是强化学习的数学公式化,其符合马尔科夫性质——当前的状态可以完全地描述世界的状态。
马尔科夫决策过程由一个包含五个元素的元组构成:
:表示所有可能的状态的集合。 :表示所有可能的动作的集合。 :表示给定一对(状态,动作)的奖励值的分布,即一个从(状态,动作)到奖励值的映射。 :状态转移概率,即给定一对(状态,动作)时下一个状态的分布。 :折扣因子,即对近期奖励和长远奖励之间的一个权重。
2.2 工作方式
-
首先在初始阶段
时,环境会从初始状态分布 中进行采样,得到初始状态,即 -
然后,从
开始一直到整个过程结束,重复下述过程: - 代理根据当前状态
选择一个动作 - 环境采样得到一个奖励值
- 环境采样得到下一个状态
- 代理接受到奖励值
和下一个状态
- 代理根据当前状态
其中,定义一个策略
如下图的网格中,我们的状态就是这样一个网格和当前所在的位置,动作的集合为上下左右移动,每进行一次移动就会得到一个-1的奖励值。我们的目标是采取最少的步数,到达任意一个终点(星标格子)。如下图所示就是两个不同的策略,即
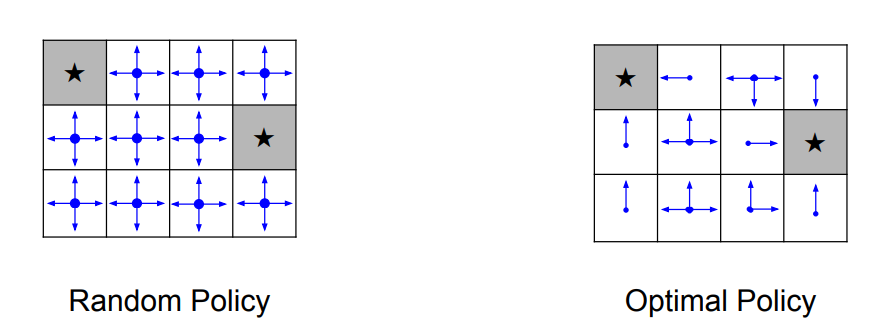
那么,我们如何寻找这样一个最优的策略
3. Q-learning
3.1 一些定义
价值函数
对于一个给定的策略
也就是说,给定一个策略
注意,价值函数评价了给定策略
Q-价值函数 Q-value
Q-价值函数则评价了给定策略
Q-价值函数由策略
贝尔曼方程 Bellman equation
现在我们固定当前状态
理解一下
理解:当我们在状态
3.2 Value iteration 算法
Bellman方程中使用 Q-value 给每次的一个情况(即一个特定的状态和动作组合)都指示了接下来转移的状态和动作,那么只要求得 所有的 Q-value ,就能找到最优策略
一个最简单的思路就是将贝尔曼方程看成一个迭代更新的式子:
即新的Q-value由旧的Q-value得到,初始时所有的Q-value为0。
具体例子可以参考:https://blog.csdn.net/itplus/article/details/9361915
那么只要迭代足够多的次数,就能得到所有的Q-value值,但是这有个问题,就是这个方法的拓展性很差。由于要求出所有的Q-value,那么对于一些任务,比如自动玩游戏,其状态为所有的像素,这样庞大的计算几乎是不可能实现的。
3.3 神经网络求Q-value
因此,我们需要使用一个函数估计器去逼近真实的Q-value,通常神经网络是一个很好的函数估计器,即:
其中的
其中,
于是,在反向传播是我们计算梯度:
下面我们以前面提到的街机游戏作为一个例子说明,首先回顾一下街机游戏的目标:
- 目标:在游戏中获得更高的分数
- 状态:当前游戏的元素像素值
- 动作:游戏中的控制,比如前后左右
- 奖励:由每一时刻游戏得分的升降决定
我们有如下一个网络结构,将最近的4帧游戏图片进行灰度化以及一些下采样等预处理后得到
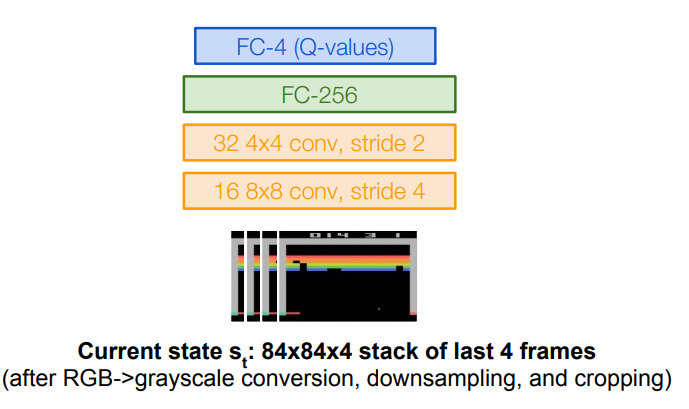
3.4 Experience Replay
但是直接训练有个问题:数据相关性。在使用神经网络逼近函数的方法里,我们修改的是参数
为了避免数据的相关性,它会有一个replay buffer,用来存储近期的一些
3.5 算法流程

上面算法流程图中的过程其实就是在训练一个深度神经网络,因为神经网络是被证明有万有逼近的能力的,也就是能够拟合任意一个函数;一个 episode 相当于 一个 epoch。
4. Policy Gradients
4.1 定义
上面介绍的Q-learning有个问题就是
然后对于每个给定的参数化策略,定义其价值函数:
所以,我们的目标就变成了找到一个
4.2 REINFORCE algorithm
在数学上,我们可以将上文的价值函数换一种写法:
其中的
于是就有:
我们就可以得到下面这样的结论:

对于这样一个策略价值的梯度,有这样的解释:
-
如果
很高,那么我们就提高我们所看见的动作的概率 -
如果
很高,那么我们就降低我们所看见的动作的概率
4.3 Variance reduction
一些方法

使用Baseline

一个简单的基准就是使用目前为止,所有轨迹所经历的奖励的恒定移动平均值,即:
一个更好的基准就是从一个状态中推高一个行动的概率,如果这个行动比我们应该从该状态中得到的预期值更好。
4.4 Actor-Critic Algorithm

4.5 Recurrent Attention Model

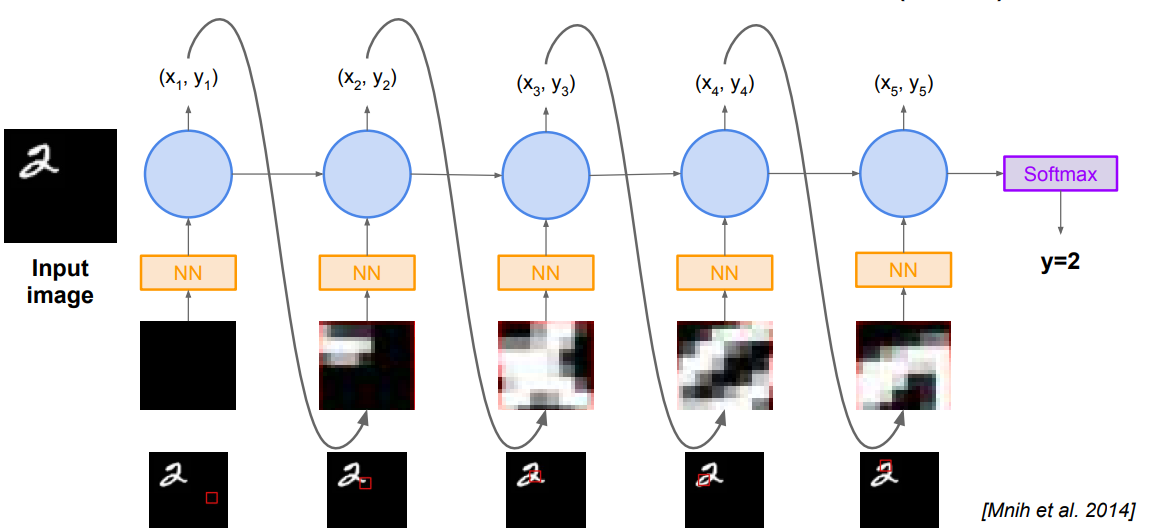
4.6 AlphaGo

