paper: https://drive.google.com/open?id=1mX1l3AhXz20gIajLjCRso6JMZWLRIxTB
source: ACM Trans.
1. 定义与分类
1.1 ZSL定义
零样本学习方法(ZSL),其定义是基于可见(seen)标注数据集及可见(seen)标签集合,学习并预测不可见(unseen,无标注)数据集结果,其中unseen标签集合是可获得的。Seen标签集合与unseen标签集合 交集为空。
还有一种GZSL任务,与ZSL不同的是,测试集中同时包含已知类和未知类的样本,因此该任务更加困难。
根据可用的训练数据可以划分成以下三类:
- CIII:Class-Inductive Instance-Inductive setting:只使用训练实例和seen 标签集合来训练模型;
- CTII:Class-Transductive Instance-Inductive setting:使用训练实例和seen 标签集合,外加unseen标签集合来训练模型;
- CTIT:Class-Transductive Instance-Inductive setting:使用训练实例和seen 标签集合,外加unseen标签集合,以及未标注的测试样本(属于Unseen类)来训练模型。
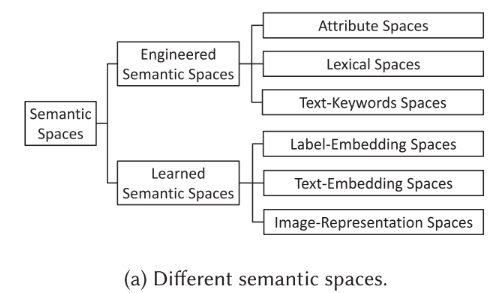
1.2 语义空间
由于不能获取未知类的示例用于训练, 为了解决ZSL问题,一些用于表示类别信息的额外辅助信息是必要的,这里称为语义空间(Semantic Space),语义空间是ZSL中非常重要的部分。根据语义空间的构建,可以划分为两大类:工程语义空间和学习语义空间,如下图。前者主要是人为构建的,具有更好的解释性但是人工成本大且性能受人为因素影响大,后者通过一些机器学习的方式获得,具有更好的性能但是可解释性较差。构建语义空间的目的是获得class prototype,用于建立已知类和未知类之间的关联。简单说明一下这两种语义空间的代表做法:
- Engineered Semantic Spaces:通过人为标注图片的属性或者提取caption的关键词作为一个类的prototype
- Learned Semantic Spaces:利用语言模型将标签或者对应的caption转换成embedding作为prototype,或者直接将image embedding作为prototype。
2. 主要方法
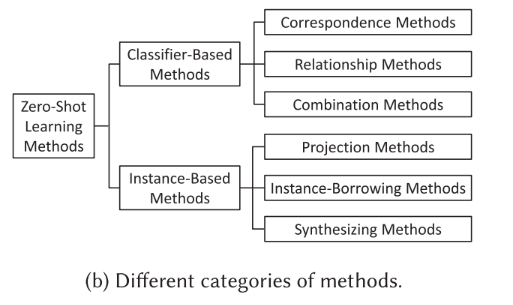
主流的ZSL方法可以分为两大类:基于分类的方法和基于实例的方法。前者主要关注如何直接学习一个分类器来处理未知类样本,后者先对未知类样本进行标注,然后再进行分类。
2.1 基于分类的方法
根据如何构建分类器,可以将基于分类的方法分成三类,下面逐一介绍。
2.1.1 Correspondence Methods
这种方法的主旨是借助每个已知类的二元分类器以及与之对应的class prototype之间的关系来构建未知类的分类器。具体来说,在语义空间中,每个类都能用一个class prototype来表示,同时在特征空间中,每个类也能用一个二元分类器来表示。因此,可以学习一个correspondence function来建立二元分类器和对应的class prototype之间的联系。得到这样一个函数后,在测试阶段,就可以利用未知类的prototype来获得与之对应的二元分类器了。这里的未知类的prototype通过前面介绍的语义空间来获得。
2.1.2 Relationship Methods
这类方法首先将每个已知类训练一个分类器,然后计算已知类和未知类的prototype之间的关系或者使用其他的一些方法得到已知类和未知类之间的关系。然后使用这些关系将已知类的分类器构造成未知类的分类器。
2.1.3 Combination Methods
这类方法认为无论是已知类还是未知类,每一个类别都是由一组”基本元素“组合而成的,Semantic Space中的Prototype的每个维度就是一个基本元素,因此可以学习一组分类器来分辨这些基本元素。测试阶段,使用这些分类器辨别未知类的基本要素构成,然后与Prototype进行比较即可。
2.2 基于实例的方法
基于实例的方法的核心思想是,首先想方设法获得未知类的有标签样本,然后利用这些样本去学习一个分类器。根据样本的来源,可以将这类方法分为以下几类:
2.2.1 Projection Methods
这类方法的核心思想是将样本所在的特征空间和Prototype的语义空间投射到同一个空间中。在特征空间中,有已知类的样本,在语义空间中有已知类和未知类的Prototype,两者都是以向量的形式表示。因此,Prototype也可以看做是一种有标注的样本。将两种向量投射到同一个空间中,就可以使用Prototype来训练模型,实现未知类的分类。
2.2.2 Instance-Borrowing Methods
这种方法的核心思想是从已知类中“借”一点有标注的样本。举例来说,我们如果要识别卡车,虽然数据集中没有卡车的图片,但是我们有大巴车和小轿车的图片,这两种图片和卡车图片非常相似,我们就可以将这两种图片作为正样本来训练模型。这种思路其实和人类学习新事物的方法是一样的,即借助已知的知识,来迁移到未知事物中。通常训练流程如下:首先,对于每个未知类,从训练实例中借用一些实例并分配该类的标签。然后,利用这些借用的实例,学习未知类的分类器,并实现未知类的分类。然而这种方法需要提前确定未知类(即在训练阶段就获得未知类标签),因为只有这样,我们才知道要借用哪些类的实例。
2.2.3 Synthesizing Methods
这种方法的思想就是利用一些生成模型,依据未知类的标签生成未知类的样本,然后使用这些生成的样本来训练未知类的分类器。这类方法也需要提前知道未知类的标签。
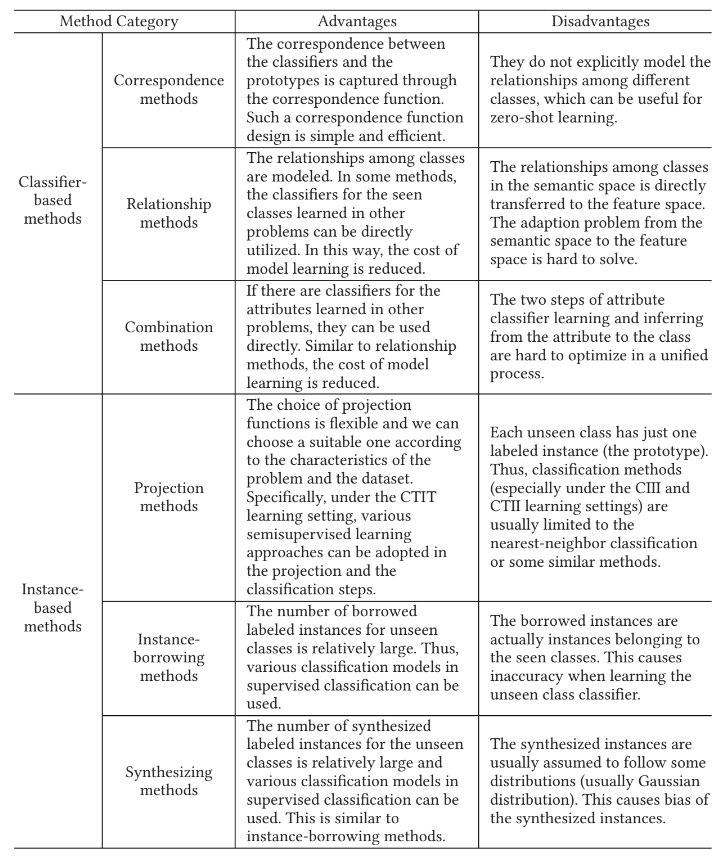
2.3 各种ZSL方法优劣比较
上述所有方法的优劣如下表所示: