Generalizing to Unseen Domains: A Survey on Domain Generalization
1. 定义
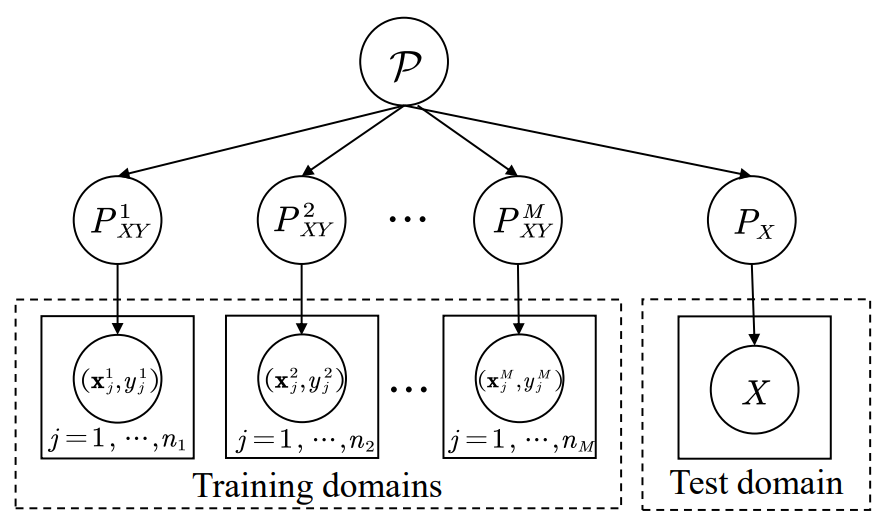
域 Domain: 假设 $X$ 为一个非空的输入空间,$Y$ 为对应的输出空间。一个域的数据由特定分布采样得来,即$S = \{(x_i,y_i)\}^n_{i=1}\sim P_{XY}$,其中$x\in X\subset \R^d, y\in Y \sub \R$,$P_{XY}$ 表示输入样本和输出标签的联合分布。
域泛化 Domain Generalization: 在域泛化任务中,我们通常给定 $M$ 个训练域(源域)$S_{train} = \{S^i|i=1,…,M\}$,其中 $S^i=\{(x^i_j,y_j^i)\}^{n_i}_{j=1}$表示第 $i$ 个源域,并且每个域之间的联合分布$P_{XY}^i$ 都是不同的。而域泛化的目标是通过 $M$ 个源域来学习一个具有鲁棒性的泛化函数$h:X\rarr Y$ ,实现在目标域上的最小预测误差,目标域的联合分布与源域也不同,如下图所示。
相关领域: 与域泛化相关的领域主要有两个,Zero-Shot Learning 和 Domain Adaptation,下面分别介绍差异。
- ZSL:该任务的目标是利用已知类的样本学习一个模型,使其能够分辨未知类的样本,其中未知类的标签信息是已知的。与域泛化任务的主要区别在于,域泛化任务的训练数据和测试数据的差异主要在输入样本本身(即$X$),而ZSL的训练数据和测试数据的差异在于标签(即$Y$),
- DA:该任务的目标是利用源域样本最大化模型在目标域的表现,与域泛化任务的区别在于,DA可以获取目标域的数据,而域泛化不能。
2. 相关理论
2.1 Domain Adaptation
Domain Adaptation 的 target risk可以用下式衡量:
$$\epsilon^{t}(h) \leq \epsilon^{s}(h)+d_{\mathcal{H} \Delta \mathcal{H}}\left(P_{X}^{s}, P_{X}^{t}\right)+\lambda_{\mathcal{H}}$$
其中 $\epsilon^{s}(h)$ 表示源域自身的risk,$\lambda_{\mathcal{H}}$ 一般是个常量,受特征维度的影响,$d_{\mathcal{H} \Delta \mathcal{H}}\left(P_{X}^{s}, P_{X}^{t}\right)$ 表示源域和目标域分布的差异程度。因此,为了降低DA的target risk,主要的方向就是减小 $d_{\mathcal{H} \Delta \mathcal{H}}\left(P_{X}^{s}, P_{X}^{t}\right)$ ,主要有两类方法:
- Instance Reweight,即分别在源域和目标域选择有代表性的数据,使得分布差异减低
- Domain-Invariant Feature Learning,学习跨域不变特征,以此减小两个域的分布差异。
2.2 Domain Generalization
Domain Generalization 的error bound可以用下式衡量:
$ \epsilon^{t}(h) \leq \sum_{i=1}^{M} \pi_{i}^{*} \epsilon^{i}(h)+\frac{\gamma+\rho}{2}+\lambda_{\mathcal{H},\left(P_{X}^{t}, P_{X}^{*}\right)}$
其中 $\sum_{i=1}^{M} \pi_{i}^{*} \epsilon^{i}(h)$ 表示源域上的risk,这里表示有多个源域,不同源域的risk不同,按照权重相加。$\gamma:=\min _{\pi \in \Delta_{M}} d_{\mathcal{H}}\left(P_{X}^{t}, \sum_{i=1}^{M} \pi_{i} P_{X}^{i}\right)$ 表示目标域和源域的分布之间的最小距离, $ \rho:=\sup _{P_{X}^{\prime}, P_{X}^{\prime \prime} \in \Lambda} d_{\mathcal{H}}\left(P_{X}^{\prime}, P_{X}^{\prime \prime}\right)$ 表示任意两个源域之间的最大距离,因此主要缩小的也就是 $\frac{\gamma+\rho}{2}$ 这一项。
3. 主要方法
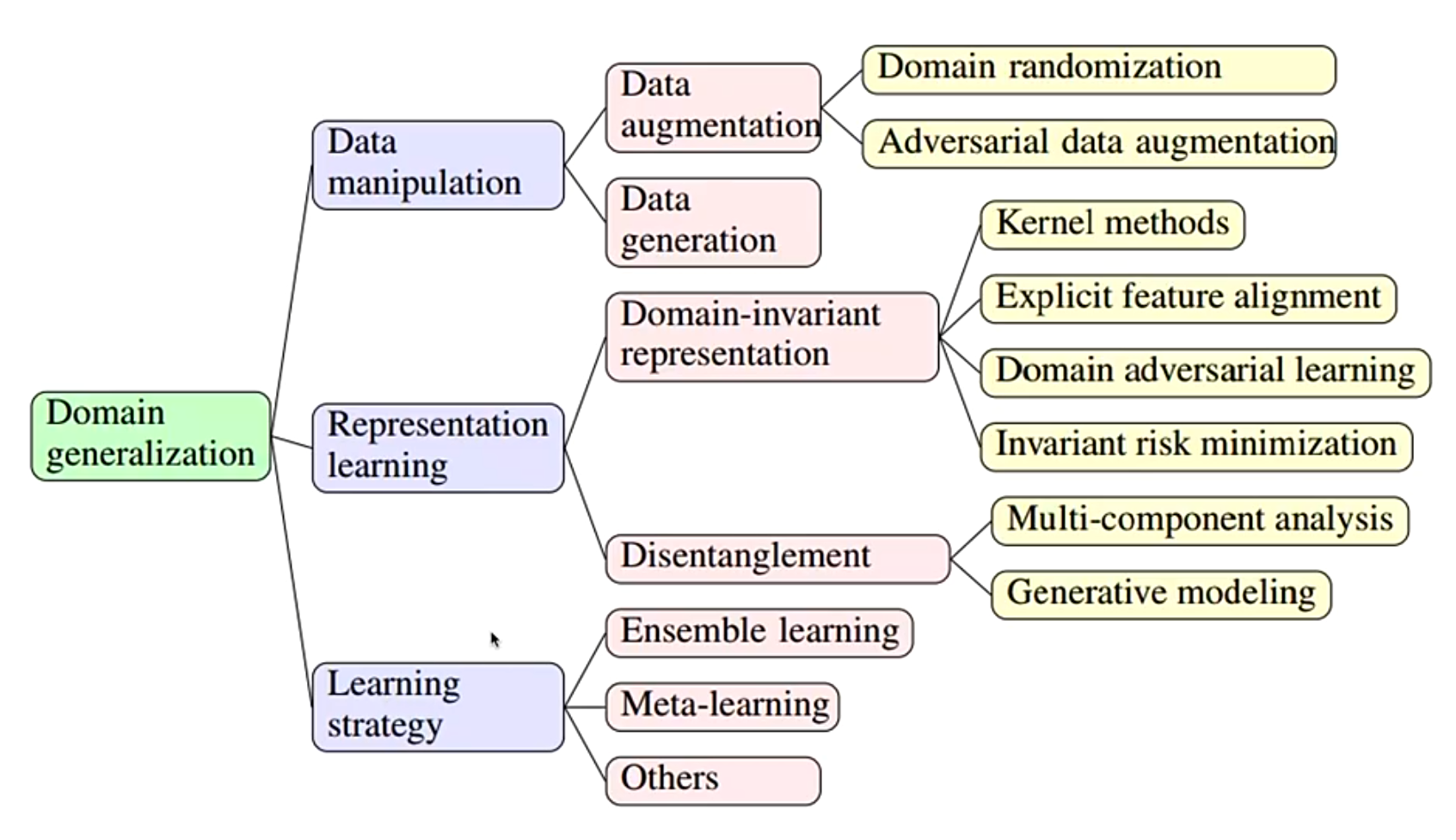
3.1 Data Manipulation
这一类方法的关键点在于增加训练数据的多样性和质量,主要包括数据增强和数据生成两类方法。增加数据的多样性和质量对于增强模型的泛化能力是非常重要的,然而这一系列的数据操纵方法有一个重要的问题:缺乏对泛化的无约束风险 (unbound risk of generalization) 的理论保证。
3.1.1 Data augmentation
传统的数据增强包括:旋转,翻转,增加噪音,改变颜色…
在DG领域也有一些数据增强的手段:
-
Domain randomization:通过随机改变图片中物体的数量,视角,位置,纹理,环境等,实现真实环境的模拟。
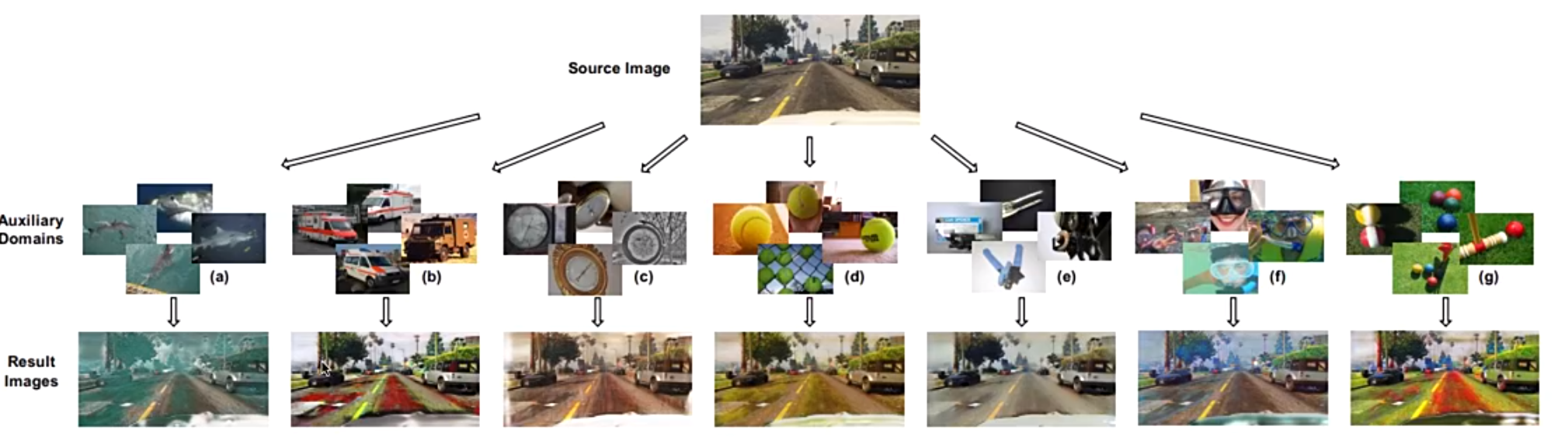
- Adversarial data augmentation:对抗性数据增强的目的是用对抗的方式来指导数据增强以优化泛化能力,通常通过增强数据的多样性同时保证其可靠性的方式。比如,朝着梯度的反方向来增强数据,使得训练更加困难,以此提高模型泛化能力。然而,这种对抗的方式往往会使得训练更加难以进行。
3.1.2 Data generation
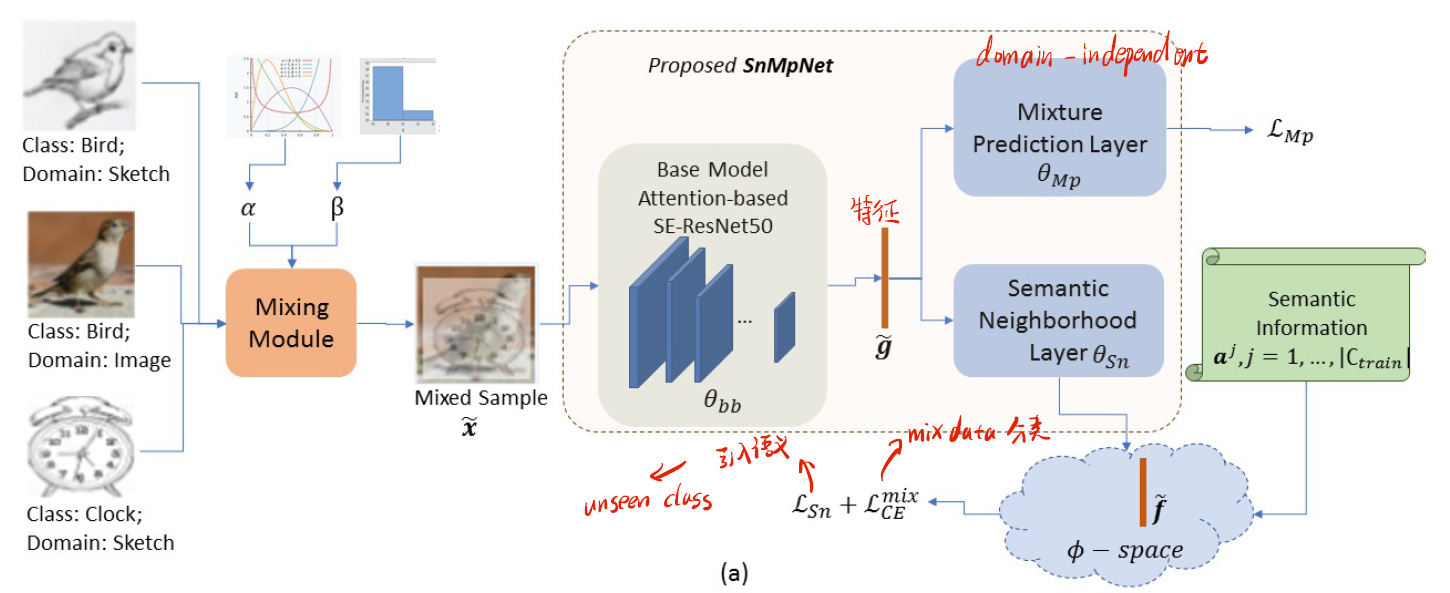
这种方法更加直观,就是去直接生成新的数据,比如通过VAE,GAN,Mixup的方式来进行。比如下图就是将不同类和不同域的图片按照比例进行混合,实现新数据的生成。
3.2 Representation Learning
表征学习的目标可以用下式概括:
$\min _{f, g} \mathbb{E}_{\mathbf{x}, y} \ell(f(g(\mathbf{x})), y)+\lambda \ell_{\mathrm{reg}}$
其中,$g()$ 表示表征函数(提取图片特征),$f()$ 为分类器,$\ell_{\mathrm{reg}}$ 为正则项。
与数据操作相比,表征学习一般都有理论支持。基于核的方法在传统方法中被广泛使用,而基于深度学习的方法在最近几年发挥了主导作用。虽然领域对抗训练在领域适应中经常取得更好的性能,但在DG中,我们没有看到这些对抗方法的明显改进。我们认为这可能是因为DA这个任务相对容易。对于显式分布对齐,越来越多的工作倾向于匹配联合分布,而不仅仅是匹配margin或条件分布。因此,进行动态的分布匹配是可行的。disentanglement和IRM方法都有很好的泛化动机,同时可以开发出更有效的训练策略。但是,仅仅学习领域不变的特征是不够的,还应该考虑表示的平滑性。
3.2.1 Domain-invariant representation
该方法基于理论:如果特征在不同域中都具有不变性,那么这个特征就具有泛化和迁移到其他域的能力。对于域泛化,目标是将特定特征空间中多个源领域之间的表征差异减少到领域不变,这样学到的模型就可以对未见过的领域有一个可泛化的能力。
- Kernel-based methods:类似SVM的思想,通过核函数将特征映射到一个新的空间中,使其具有某种特性(比如跨域不变)。
- Domain adversarial learning:使用对抗攻击的方式进行学习,比如使用discriminator去对域进行分类,使用generator去进行对抗攻击,干扰discriminator的分类,以此实现让discriminator学习不变的特征。
- Explicit feature alignment:这类方法比较直接,通过将源域的特征进行对齐,实现跨域不变,通常的做法是进行feature distribution alignment 或者 feature normalization。
- Invariant risk minimization:这类方法区别于feature alignmen显式地对齐特征,它主要是去学习一个分类器,使得同一类样本无论在什么域中的分类结果都是一致的。
3.2.2 Feature disentanglement
一般来说,基于Disentanglement的DG方法将特征解耦为一定的组合/子特征,其中一个特征是跨域不变的特征,另一个是特定领域才有的特征,可以用公式表示成,其中$g_{c}(\mathbf{x})$ 表示跨域不变特征,$g_{s}(\mathbf{x})$ 表示特定领域才有的特征:
$\min _{g_{c}, g_{s}, f} \mathbb{E}_{\mathbf{x}, y} \ell\left(f\left(g_{c}(\mathbf{x})\right), y\right)+\lambda \ell_{\mathrm{reg}}+\mu \ell_{\mathrm{recon}}\left(\left[g_{c}(\mathbf{x}), g_{s}(\mathbf{x})\right], \mathbf{x}\right)$
主要方法包括:
- Multi-component analysis:分别使用不同的网络参数或结构来学习跨域不变和特定领域的特征。
- Generative modeling: 从数据生成过程的角度对特征进行解耦。这类方法试图分别从domain-level, sample-level, and label-level分别制定样本的生成机制。
- Causality-inspired methods:因果关系是对统计学(联合分布)以外的变量关系的更精细描述。因果关系给出了系统在干预下的行为信息,所以它自然适合于迁移学习任务,因为领域迁移可以被看作是一种干预。特别是,在因果考虑下,所需的表征是标签的真正原因(如物体形状),因此,预测不会受到相关但语义上不相关的特征(如背景、颜色、风格)的干预影响。
3.3 Learning Strategy
- Meta-Learning:将不同的源域拆分成不同的任务,然后使用功能Meta-Learning来学习一般化的信息。
- Ensemble learning:集成学习通常结合多个模型,如分类器或专家,以增强模型的能力。对于领域泛化,集合学习通过使用特定的网络架构设计和训练策略来利用多个源领域之间的关系,以提高泛化能力。他们假设任何样本都可以被看作是多个源域的综合样本,所以整体预测结果可以被看作是多域网络的叠加。
- Gradient operation-based DG:利用梯度信息做文章,来学习更一般的特征。
- Distributionally robust optimization-based DG:分布鲁棒优化(DRO)的目标是在最坏的分布情况下学习一个模型,希望它能很好地泛化到测试数据中,这与DG有类似的目标。
- Self-supervised learning-based DG:使用自监督学习范式,可以利用大量未标注的数据参与到训练中。
对于学习策略,有一种趋势是许多工作将元学习用于DG,需要设计更好的优化策略来利用不同领域的丰富信息。除了深度网络,还有一些工作将随机森林用于DG。
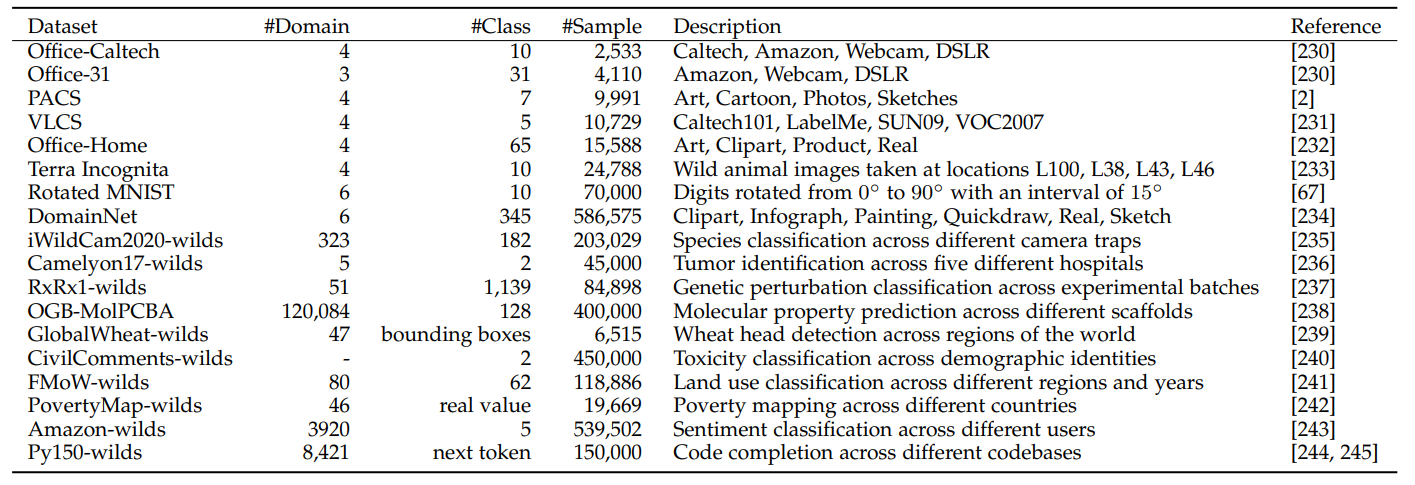
4. 数据集
5. 未来挑战
5.1 Continuous domain generalization
在真实场景中,模型遇到的数据多样性是持续增加的。在这种情况下,进行连续的领域泛化是非常重要的,它可以有效地更新DG模型以克服灾难性的遗忘并适应新的数据。虽然有一些领域适应方法专注于连续学习,但只有很少的关于DG的连续学习的工作。
5.2 Domain generalization to novel categories
现有的DG算法通常假设不同领域的标签空间是相同的。一个更实用和普遍的设置是支持在新类别上的泛化,即领域和类别泛化。
5.3 Interpretable domain generalization
基于DG的方法将一个特征分解为领域不变的/共享的和特定领域的部分,这为DG提供了一些可解释性。对于其他类别的方法,仍然缺乏对DG模型中学习特征的语义或特征的深入理解。例如,如何将该方法的结果与输入特征空间联系起来。因果关系可能是理解领域泛化网络并提供解释的一个有前途的工具。
5.4 Large-scale pre-training/self-learning and DG
近年来,我们见证了大规模预训练/自我学习的快速发展,如BERT[263]、GPT-3[264]和Wav2vec[265]。在大规模数据集上进行预训练,然后根据下游任务对模型进行微调,可以提高其性能,其中预训练有利于学习一般的表征。因此,如何设计有用和高效的DG方法来帮助大规模预训练/自学是值得研究的。
5.5 Test-time Generalization
虽然DG专注于训练阶段,但我们也可以要求在推理阶段进行Test-time Generalization。这进一步连接DG和DA,因为我们也可以使用推理阶段的无标签数据进行适应。与传统的DG相比,这种方式将允许推理有更大的灵活性,而它需要更少的计算和更高的效率,因为推理端设备的资源往往有限。
5.6 Performance evaluation for DG
最近的工作指出,在几个数据集上,一些DG方法的性能几乎与基线(即ERM)相同。这可能是由于现在使用的评估方案不恰当,或者领域差距不大造成的。在更现实的情况下,如人的识别,存在明显的领域差距,DG的改进是巨大的。
