
本文为CVPR 2023 Tutorial on Prompting in Vision 观后整理,详细视频和slides请访问:https://prompting-in-vision.github.io/
本文没有包括的Tutorial中的内容:
- Teaching language models to reason, by Denny Zhou [slides],主要介绍如何利用Prompt解释NLP大模型为何work。
- Prompting in visual generation, by Ziwei Liu [slides-b & video-b],主要介绍视觉生成领域的一些Prompt工作。
0. 前言
随着ChatGPT的爆火,Prompt这一概念也逐渐被大众知晓,各大企业重金招收Prompt工程师,并且供不应求,可以说“Prompt就是金钱”。Prompt的应用不仅仅局限于ChatGPT这类对话模型,在计算机视觉领域也有很多应用。比如具有多模态能力的GPT-4,爆火的文生图模型Stable Diffusion,甚至text-to-video。可以说,Prompt无论在NLP还是CV都有很高的热度。本篇根据最新的CVPR 2023 Tutorial,简单介绍NLP中的Prompt,并主要聚焦于Prompt在视觉领域的应用。
1. Prompting in NLP
1.2 Language Model and Prompt
首先,我们知道一个语言模型的训练,基本遵循下面的流程,模型接收一段文字作为输入,然后给出字典中每个word的预测概率,并输出概率最大的作为结果,类似完形填空的形式。这类模型在训练时一般会接受大量不同来源的数据,因此具有非常丰富的知识和能力。

想要让如此强大的模型发挥应有的性能,就要用模型熟悉的套路,即完形填空。比如要让模型回答一个问题,就要将问题转换成完形填空的形式,如下图的例子所示:

又比如说,想要模型实现英语翻译法语,就可以用下述的方式。值得注意的是,下面除了将输入转换成了完形填空的形式,还给模型提供了几个例子,这种方式称为 in-context learning,也是一种few-shot。
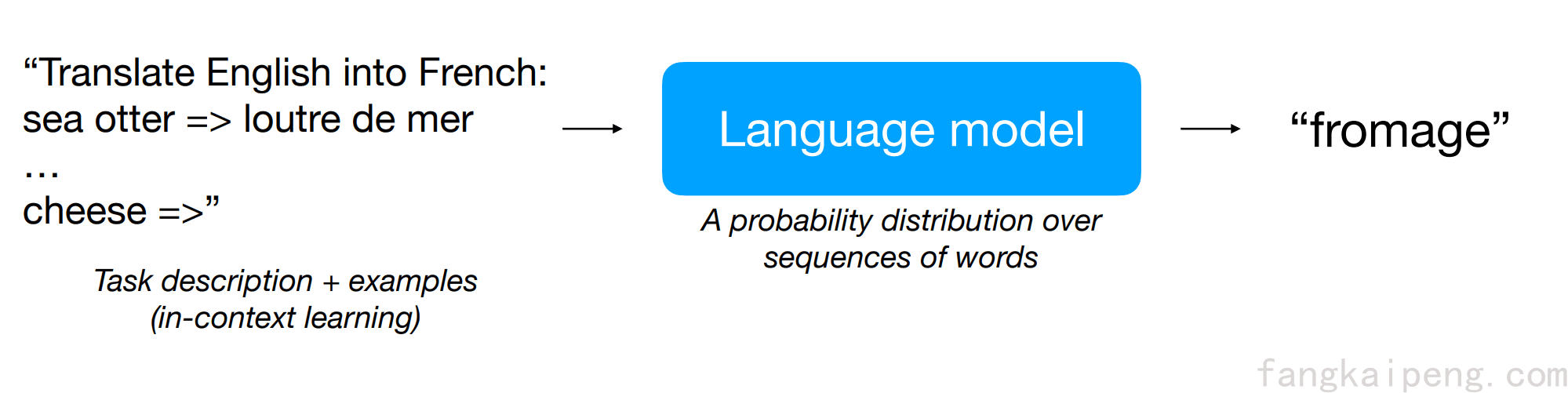
由此可见,强大的语言模型只需要构造合适的Prompt,无需二次训练,就能对任何开放性的问题都有很好的表现,由此可见Prompt的强大。但是,由此也引发了一个问题:如何构造一个完美的Prompt?或者说,如何避免不好的Prompt导致模型检索出错误的答案?
1.3 Hard Prompt
既然直接构造一个合适的Prompt比较困难,那么一种比较暴力的做法就是用一堆Prompt,然后选择一个最好的不就行了,即Mining-based prompt generation,这种方法的思路就是给定一个x和一个y,在一个超大的数据库中进行搜索,将最频繁出现的中间词作为prompt。
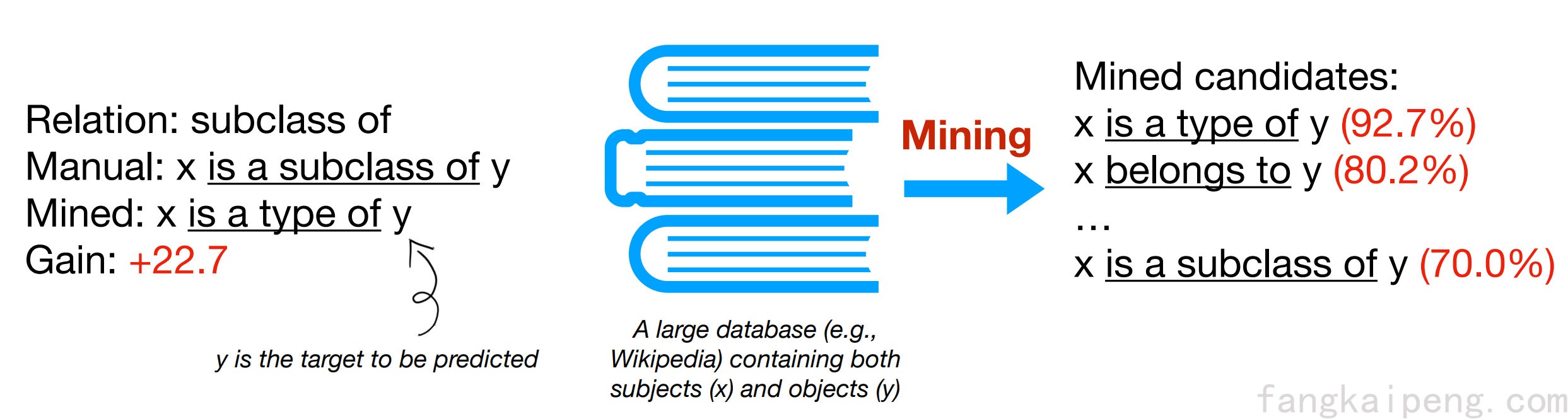
此外还有Paraphrasing-based prompt generation,这种方法主要将现有的Prompt(比如手工构造的),将其转述成一组其他候选prompts,然后选择一个在目标任务上达到最好效果的。一般的做法有:将提示符翻译成另一种语言,然后再翻译回来(这不是常见的毕设去重方法吗hhhh);或者使用同义或近义短语来替换等。

以上这些由具体单词构成的Prompt都属于Hard Prompt,也可以称为离散的Prompt,虽然具有很好的可解释性,但其缺点也很明显:Prompt的搜索空间局限于现有的单词库。
1.4 Soft Prompt
有hard就有soft,也就是与离散对应的连续prompt,即使用一组可学习的参数作为Prompt,然后使用下游任务相关的Loss进行梯度传播,在冻结语言模型的情况下更新Prompt,如下图所示。
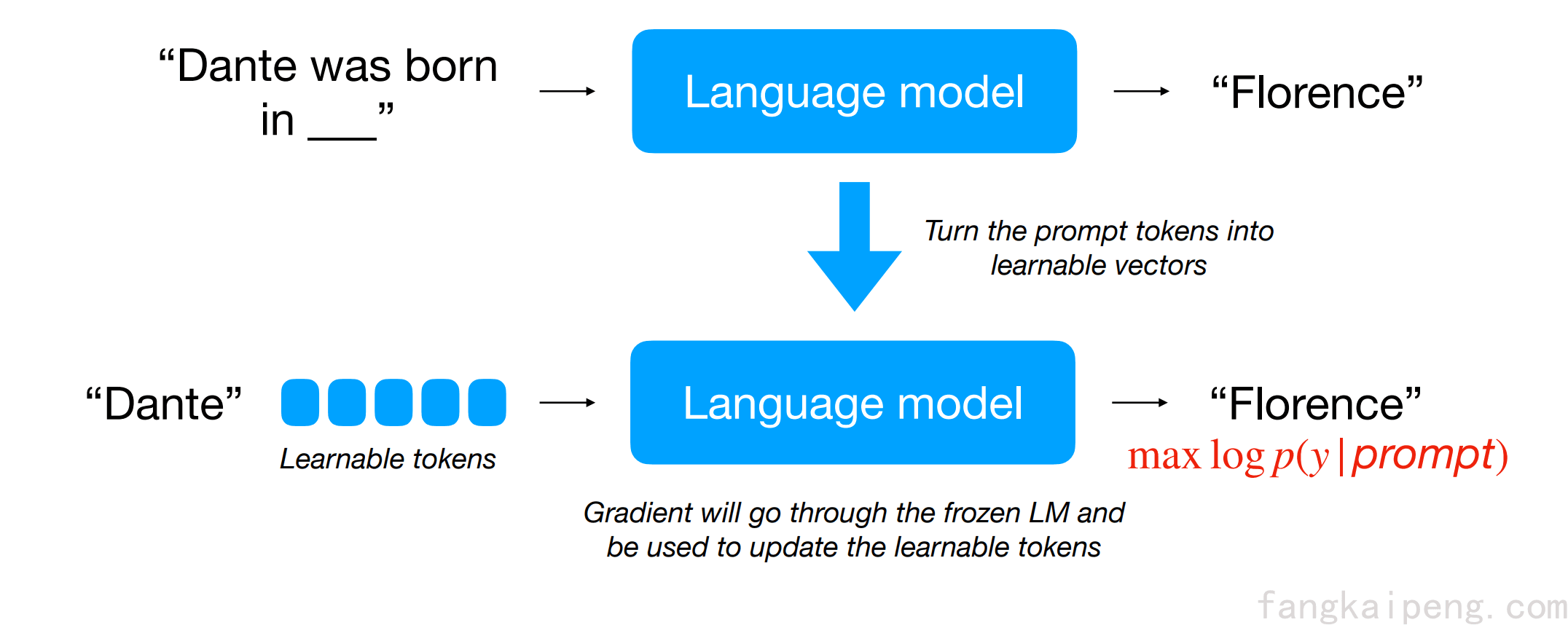
相比于传统的Fine-Tuning模型的方式,这种获得Soft Prompt的方式也被称为Prompt Tuning,其优点在于,不改动模型本身,只需要训练和存储少量的task-specific/user-specific的prompt即可。
下面是一些关于Soft Prompt的研究和结论:
-
Can handle low-data regimes,即实现了few-shot learning
Li and Liang. Prefix-Tuning: Optimizing Continuous Prompts for Generation. 2021
-
Is domain-generalizable
Lester et al. The Power of Scale for Parameter-Efficient Prompt Tuning. 2021

-
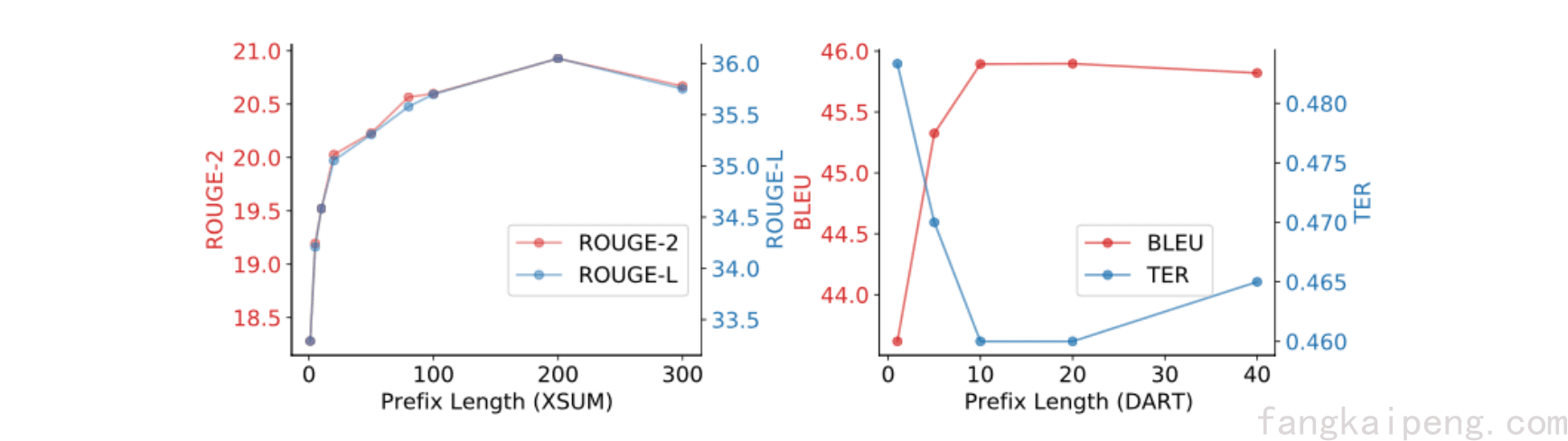
Longer prompt works better but should not be too long
Li and Liang. Prefix-Tuning: Optimizing Continuous Prompts for Generation. 2021.
-
Initialization matters a lot (word embeddings >> random) 这样不就还是需要一部分的hand craft,开始无限套娃了?
Li and Liang. Prefix-Tuning: Optimizing Continuous Prompts for Generation. 2021.
-
可解释性?有,但不多。

2. Prompting in CV
2.1 Overview
目前已经有很多CV相关的任务使用了Prompt技术,部分代表性文章如下,不详细展开:
Alayrac et al. Flamingo: a Visual Language Model for Few-Shot Learning. 2022.
Li et al. Otter: A Multi-Modal Model with In-Context Instruction Tuning. 2023.
Kirillov et al. Segment Anything. 2023.
Bar et al. Visual Prompting via Image Inpainting. 2022
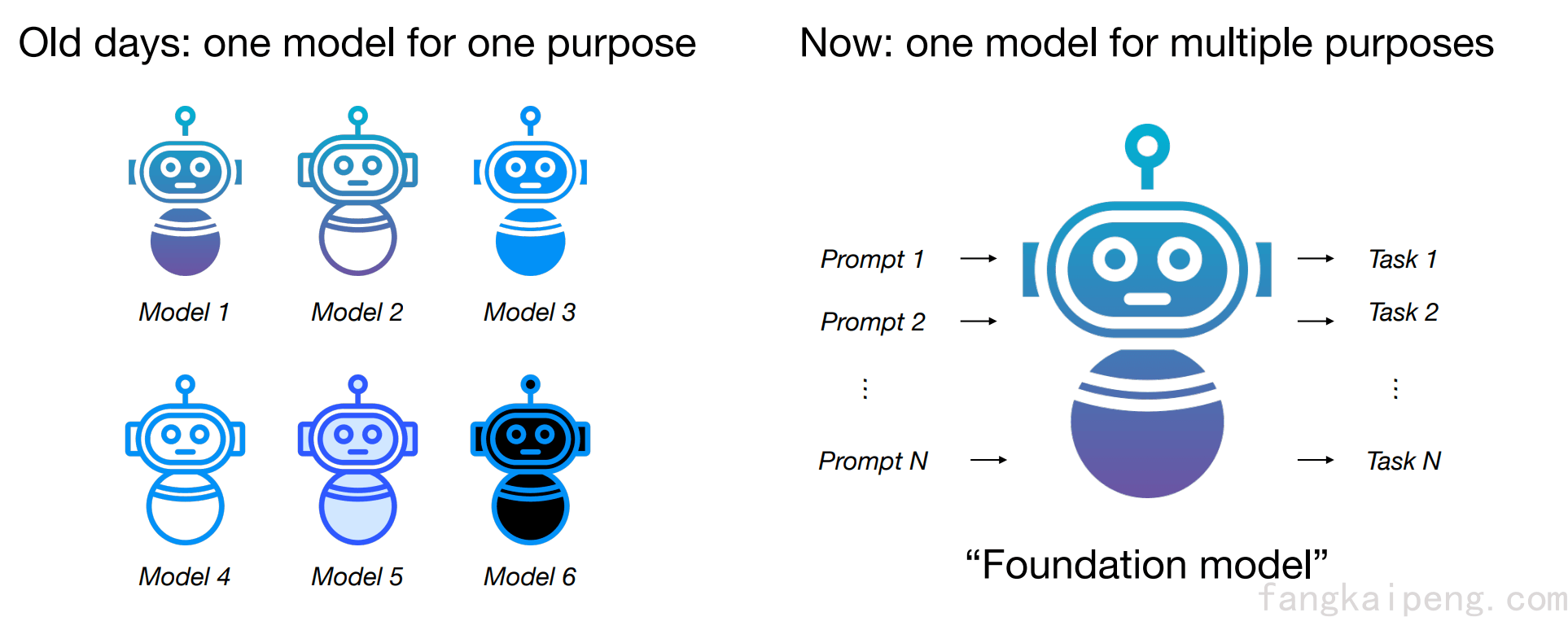
总的来说,相比于过去传统的做法,Prompt可以说是一种新的训练范式。传统的计算机视觉模型一般是一个模型对应一个下游任务。而现在,通过Prompt实现了大一统,即使用大量的数据训练一个大型的基础视觉模型,然后通过不同的Prompt来实现不同的任务。这样的好处是大大降低了存储和训练的开销。
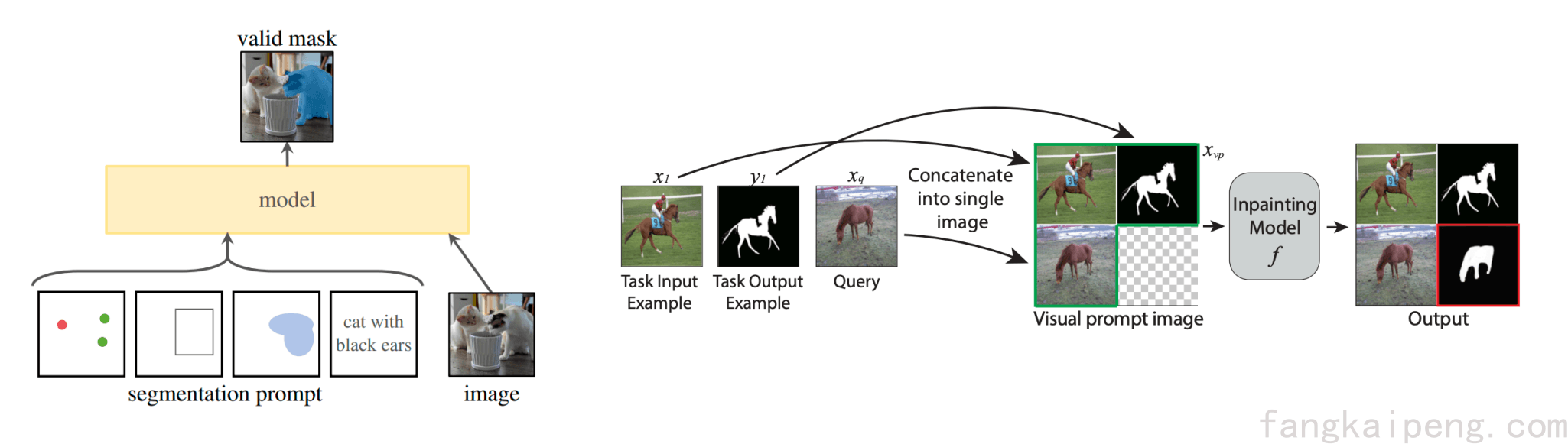
作用于视觉模型的Prompt被统称为Visual Prompt,和NLP不同的是,Visual Prompt有着很多的形式,比如点图,Bounding Box,Mask图,输入输出样例图等,如下图所示,后面也会逐一介绍。
2.2 Prompt in MultiModal
2.2.1 Hard Prompt
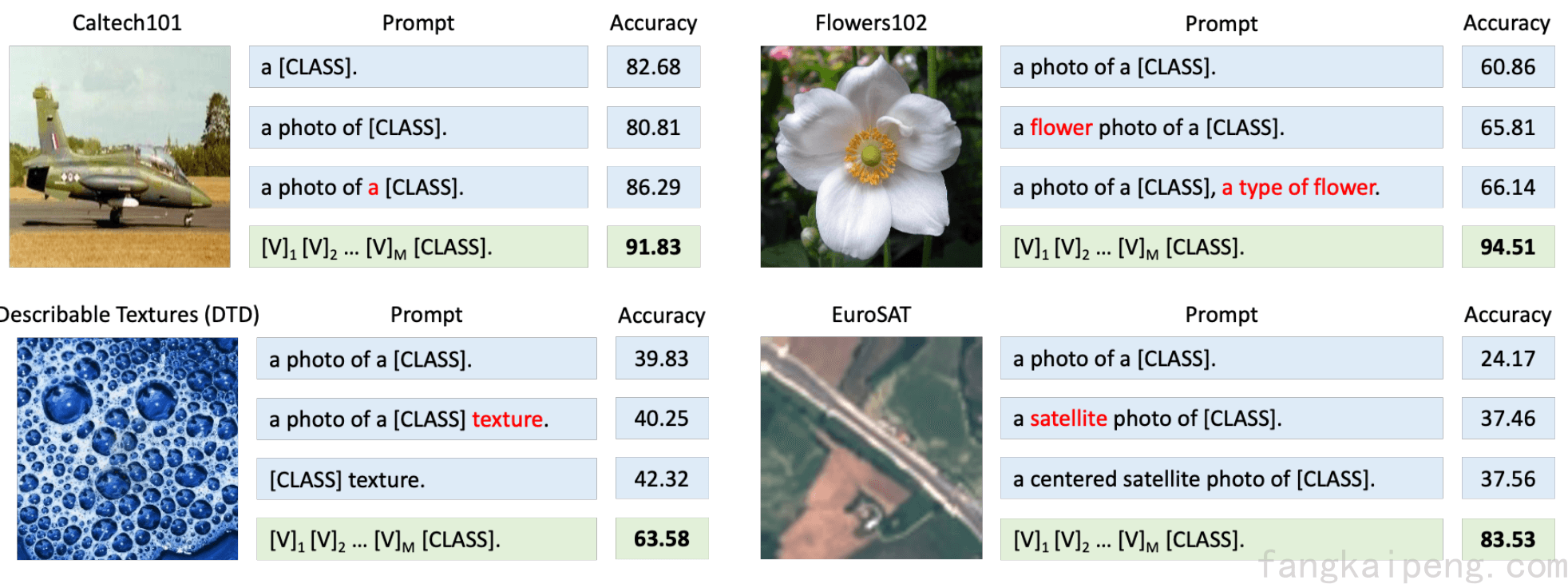
Prompt技术是在NLP领域兴起的,然后逐渐用到了多模态模型的Text端,最终以各种不同的形式出现在CV领域。其中,利用Prompt的最有名的多模态模型就是OpenAI的CLIP了,它使用了400M的图文对进行训练,训练的方式是图文配对,即最大化图片和对应的文本之间的相似度,消耗了250-600GPU跑了18天,在当时算是一个很大的模型了。训练完成后,为了实现分类的功能,作者构造了一个Prompt,如下图所示,a photo of a {object} ,使用Encoder提取embedding后,比较图文的相似度,取相似度最大的Prompt对应的类别作为分类结果。所以,这里的Prompt也实现了将一个模型陌生的任务转换成它熟悉的形式。并且,在论文中可知,CLIP具有很强的Zero-Shot能力,能在很多的数据集上展现很好的性能。

然而后续的实验发现,由于CLIP太大了,所以难以进行微调(Fine-Tuning)。同时人工构造的Prompt只要有一些细微的变化就会对性能产生很大的影响。如下图,左上角的图片只多加了一个a就获得了6点的提升。因此,Prompt Engineer也是比较困难的。
2.2.2 Soft Prompt
由于人工的Prompt有上述的那些问题,因此有很多研究者开始研究如何使用Soft Prompt来提升模型的性能,比较具有代表性的就是CoOp和CoCoOp这两篇工作了。CoOp首次将Soft Prompt引入CLIP为代表的CV模型,实现了高效的少样本学习,相比Linear Probe有显著的提升。
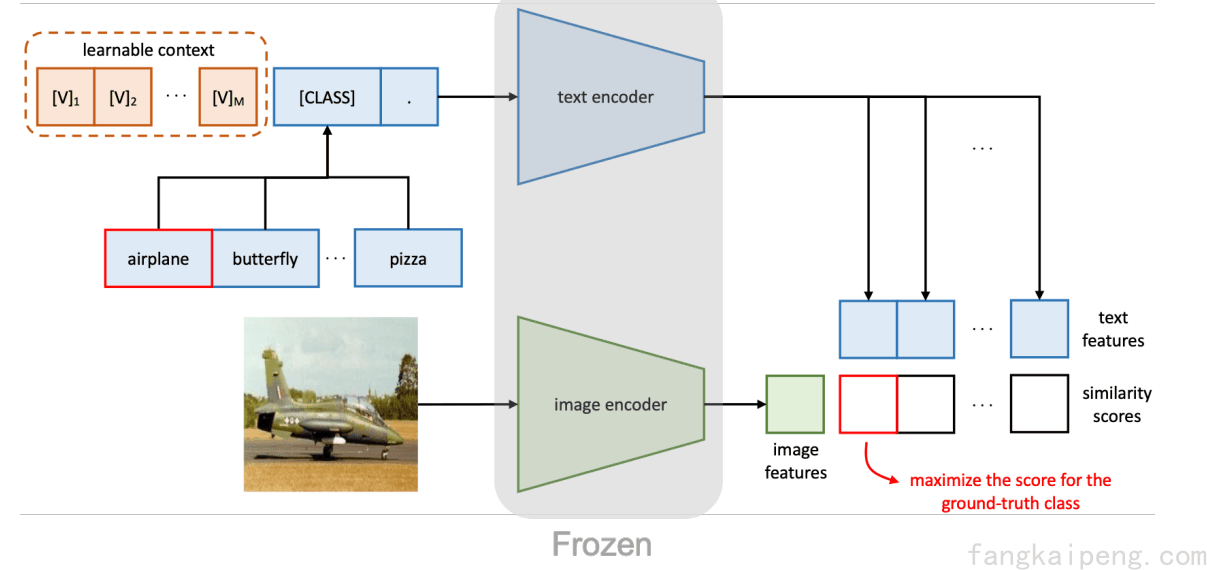
CV和NLP中的Soft Prompt有着很大的不同,如下图所示。

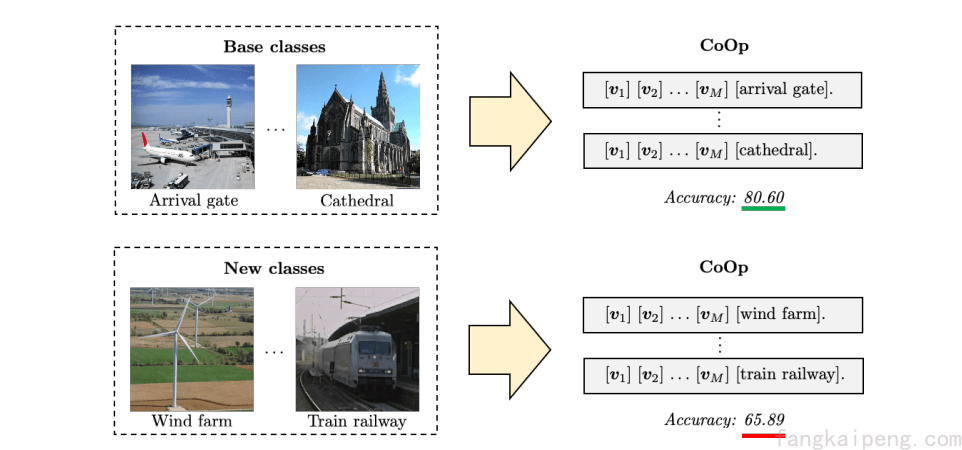
虽然CoOp使用少量的样本就能大幅提升模型性能,但它也会造成模型的过拟合,也就是说模型对这些训练过的类别具有很好的表现,但是对新的类别就会有很大的性能下降,如下图所示。
那么一个好的Prompt应该如何获得呢?受到如下图所示的文本Prompt启发,一个好的Prompt应该对一张图片有一些具体的特定描述。

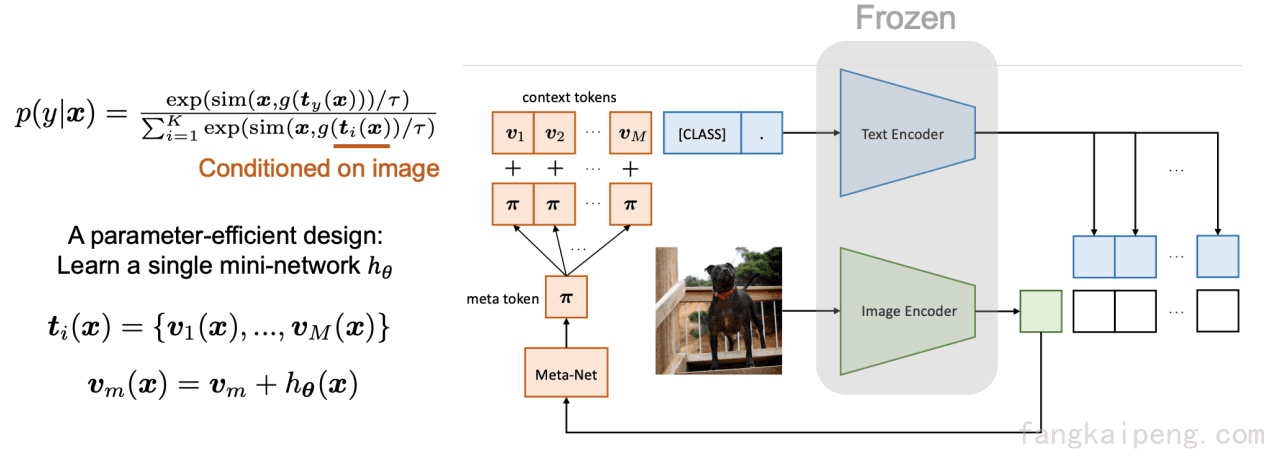
因此,就提出了CoOp的升级版,CoCoOp,即在原来的基础上,提取图片的一些视觉信息,将其加到原来的Soft Prompt上。通过这样的方式,提升了模型的泛化能力。
2.3 Visual Prompt
2.3.1 Introduction
上面介绍的这些Prompt都作用于多模态模型的Text Encoder,这些Prompt的作用是在不改变模型参数的情况下,引导语言模型的行为以实现想要的输出。这些Prompt不算Visual Prompt,Visual Prompt一般直接作用于视觉模型上,具有视觉上的一些特征,其作用是在不改变模型参数的前提下帮助模型预测预期的答案。这种利用Prompt来修改输入空间来迁移模型的方式具有以下的优点:
- 输入一般具有较好的可解释性,并且终端用户可以对输入进行干预,在不获取模型参数的情况下改变模型输出。
- 具有较好的集成性,模型可以在推理阶段就实现一个新的任务,而无需重新训练。
下面的流程图就很好的展示了prompt的优点,其中SAM就是通过训练。
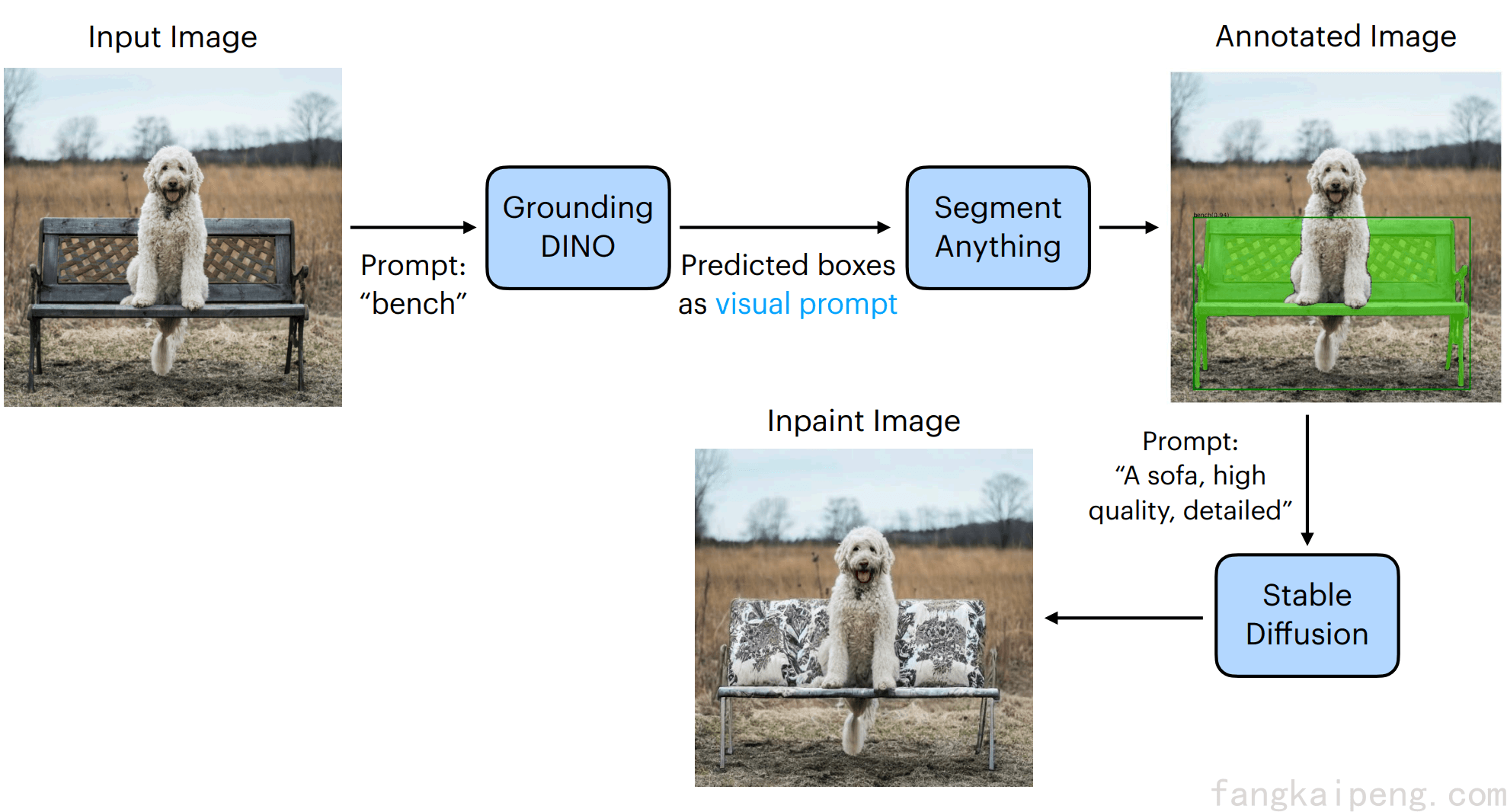
2.3.2 Promptable vision foundation models
I. Visual Prompting via Image Inpainting
那么我们该通过什么样的方式才能获得一个可以在Inference的时候使用Visual Prompt的模型呢?下面这篇工作给出了一个答案:
Visual Prompting via Image Inpainting, 2022.
这篇工作使用Image Inpainting(图像修复)作为目标函数训练了一个模型,使其可以依靠Visual Prompt完成各种不同的任务。具体来说,模型通过训练具有了图像修复的能力,在推理阶段,准备一个目标任务的输入输出样例,以及实际的输入,一共三张图片,将其拼接起来,实际的输入留空让模型来填充完整。由于模型具有图片填充的能力,所以就仿照样例,根据输入填充输出。因此,理论上这样的模型可以实现各种各样的视觉任务。这种给出一个样例,让模型仿照着输出的方式也称为 in-context learning。

II. Segment Anything (SAM)
这是一个Google团队的工作,正如其名,可以实现一切物体的分割,并且可以根据用户的交互实现不同细粒度和对不同物体的分割。
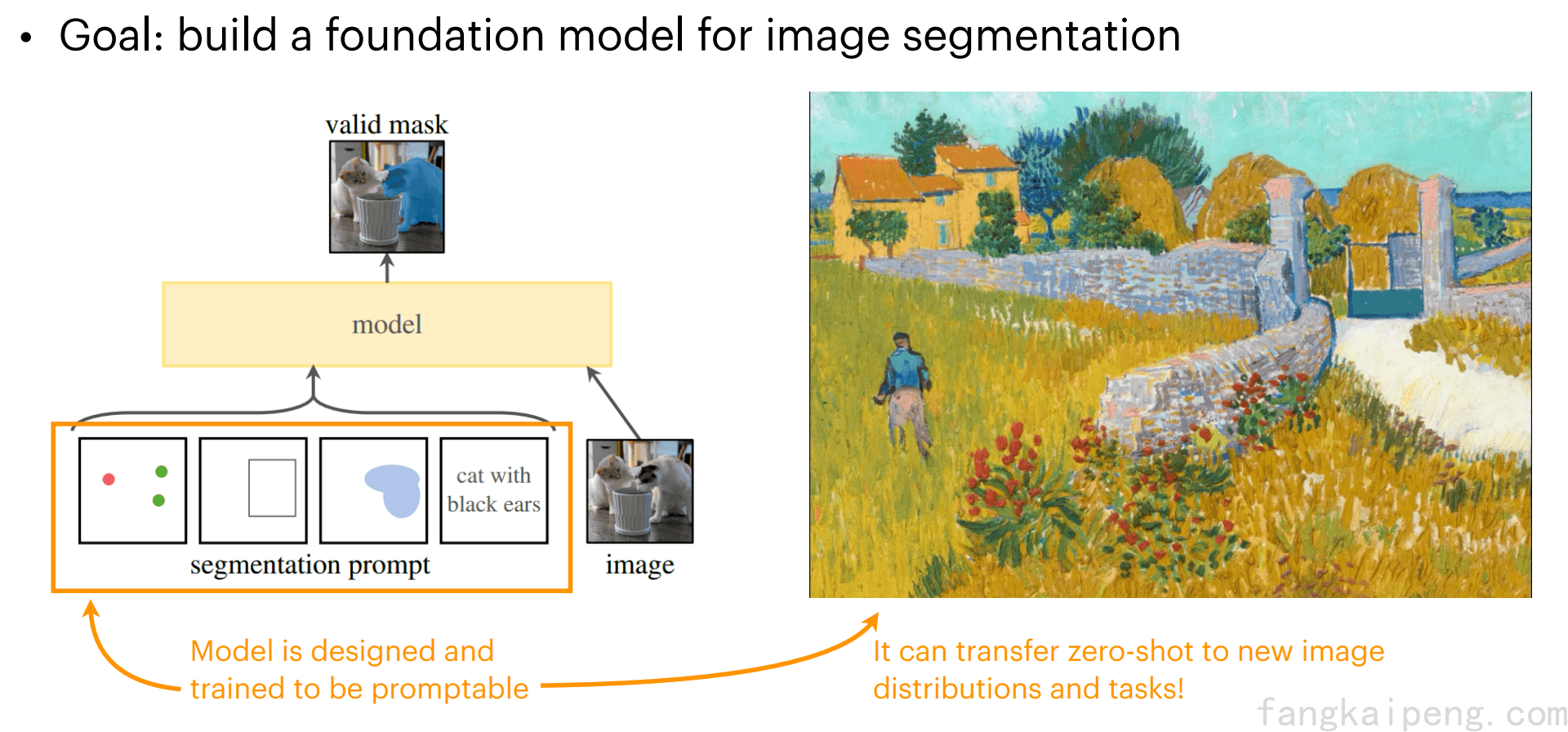
这篇工作主要有三个重点:
-
设计怎样的任务能实现zero-shot generalization?
文中使用了Promptable segmentation task,即重复利用prompt来指导模型的输出,其中prompt的形式有point,bounding box,mask,text,这些都可以用来描述要被分割的目标物体,模型将会对prompt所指向的物体进行分割。
-
要实现上述效果,模型的结构如何设计?
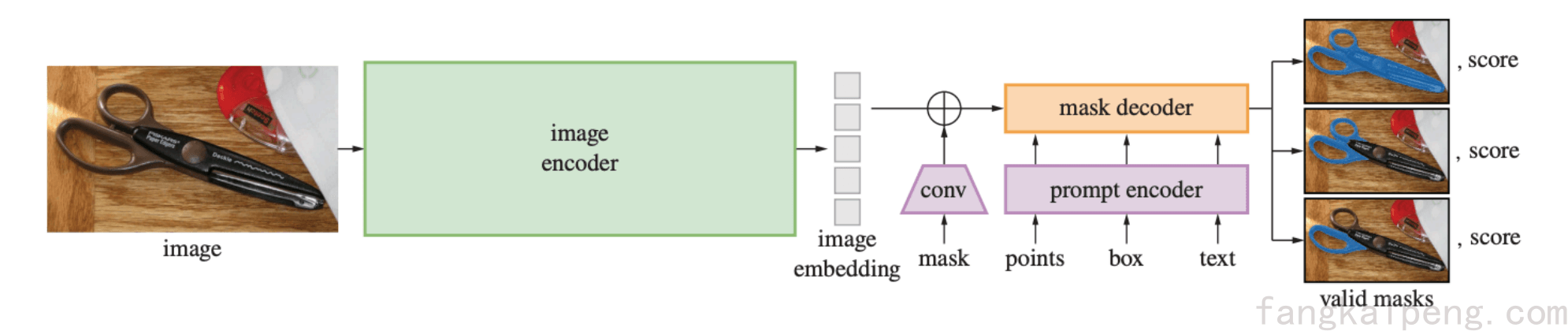
模型由三部分组成,一个比较大的image encoder用来提取image embedding,这里是一个ViT。一个轻量的prompt encoder和mask encoder实现毫秒级的处理一个prompt。prompt encoder将输入的prompt转换到和image embedding同一空间中,然后进入mask decoder产生对应的mask。值得注意的是,为了消除歧义,mask decoder将会输出三种细粒度的mask,取score最高的计算loss,即实现了Ambiguity-aware。
-
为了训练上述的模型,Google团队创建了一个新的分割数据集,包含11M图片和1.1B的mask,同时采用人工标注和机器标注完成。
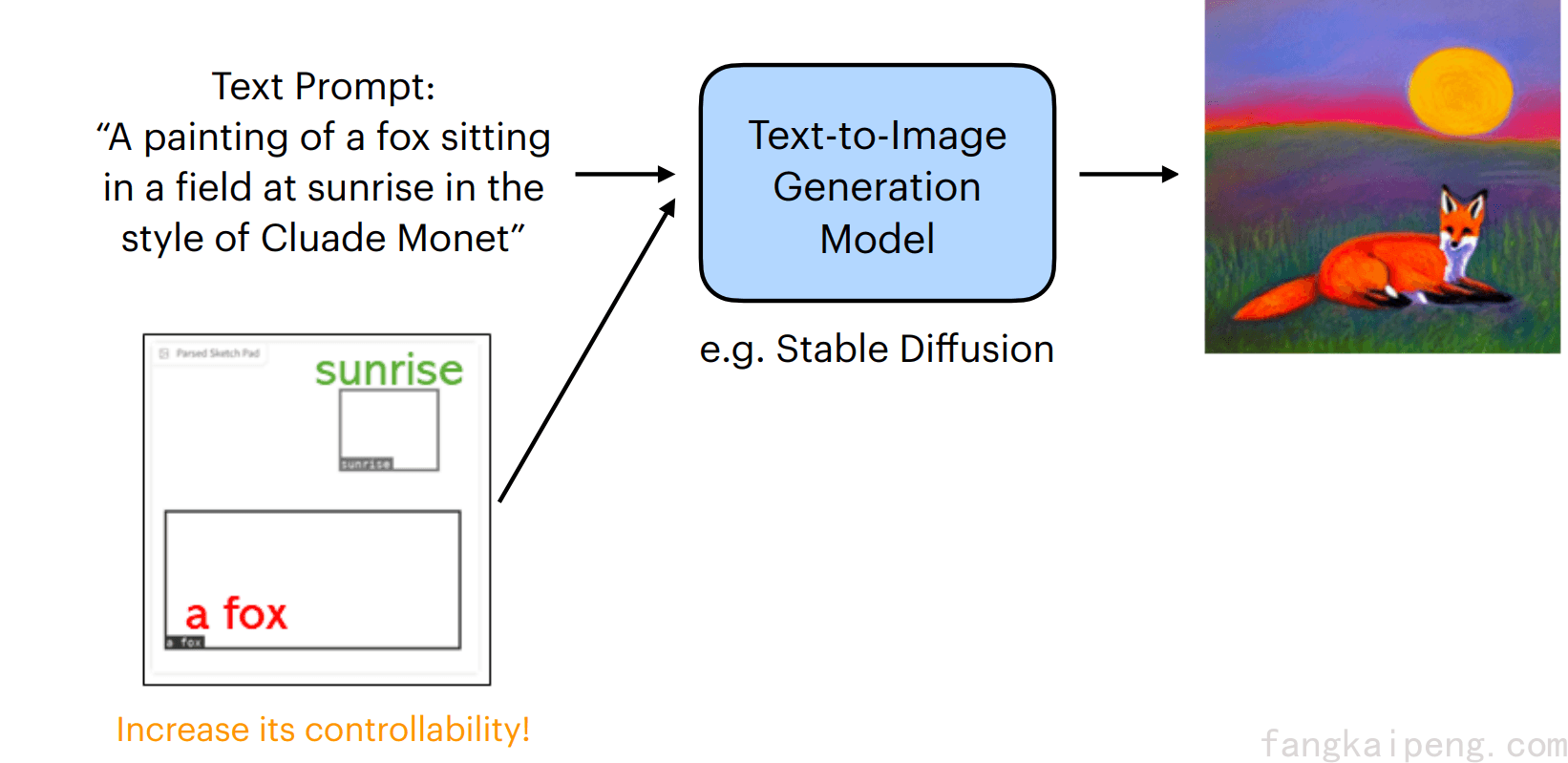
III. GLIGEN
下面介绍一个图像生成模型,叫做GLIGEN,区别于其他的生成模型,例如Stable Difussion使用text作为prompt,GLEGEN可以同时使用图像作为prompt来指导模型生成期望的图像,如下图。
2.3.3 Visual prompt learning
上述介绍的prompt虽然都属于visual prompt,但也类似hard prompt,即人为选择的。与之对应的,也有一些通过训练微调得到的连续的prompt,下面逐一介绍:
I. Prompt Learning in Pixel Space
即像素形式的prompt,这种思想其实和Adversarial reprogramming(对抗重编程)很像。传统对抗样本目的是使模型分类错误,对抗重编程则是使模型执行特定任务(攻击者设定),且该任务可以未被训练过。常用的方法也是在输入图片上覆盖或者围绕一些像素,来改变输入数据的分布,使得模型的预测结果也发生相应的改变。
Adversarial Reprogramming of Neural Networks, 2018.
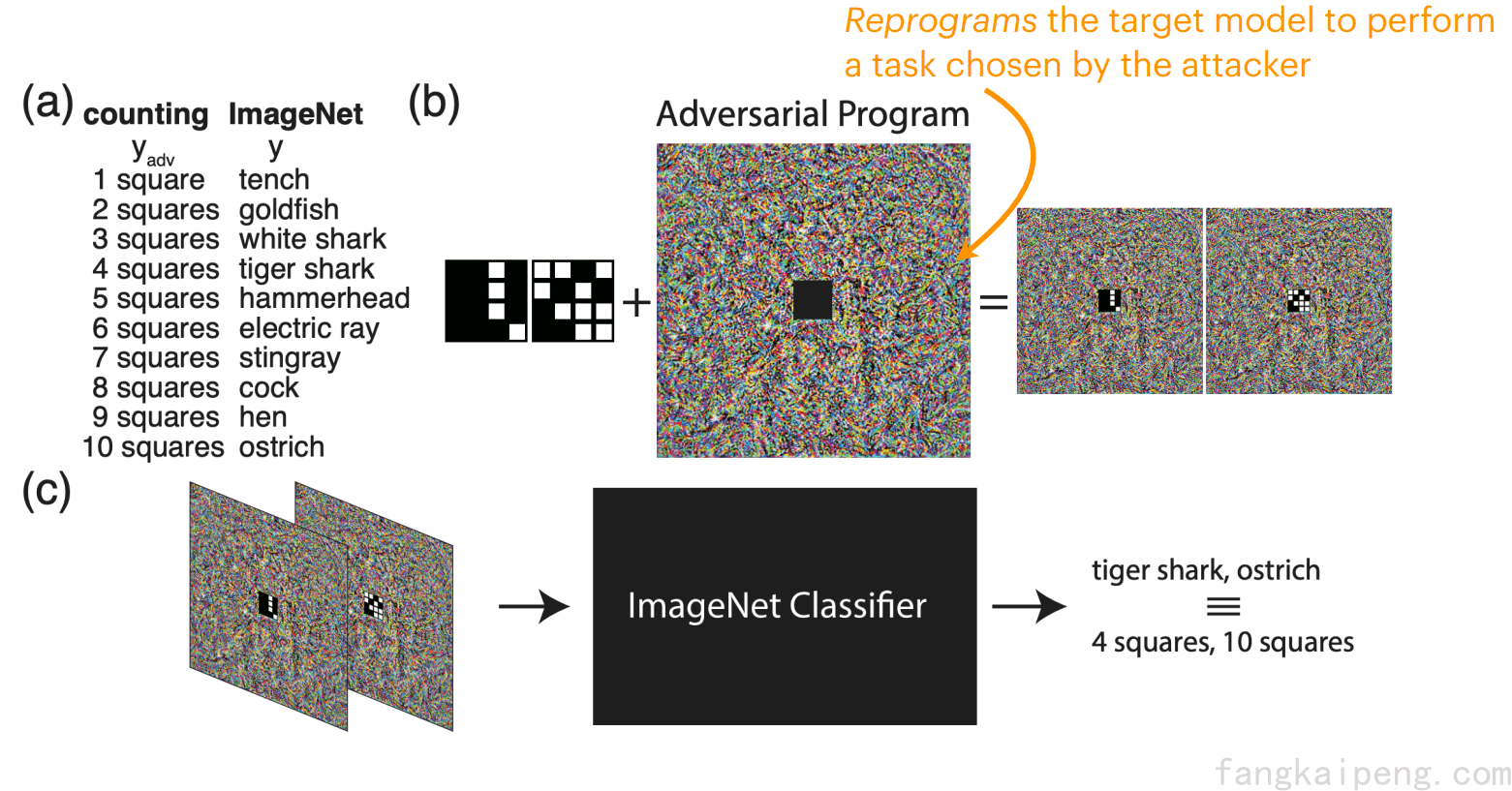
如下图,在a中,我们将imagenet任务的输出标签映射到对抗任务的标签,这里我们给定的对抗任务是计算小图像中的格子数量,所以对抗任务的标签为1~10;在b中,将对抗任务的小图像嵌入到对抗程序的中间,从而得到对抗图像。在c中,当把对抗图像输入分类器时,分类器此时会输出标签tiger shark,ostrich等,不过由于有hf函数的存在,他们会被映射到对应的4,10等。经过这一套流程,我们对一个在imagenet上训练的分类模型进行了对抗重编程攻击,使它的任务变为数格子。
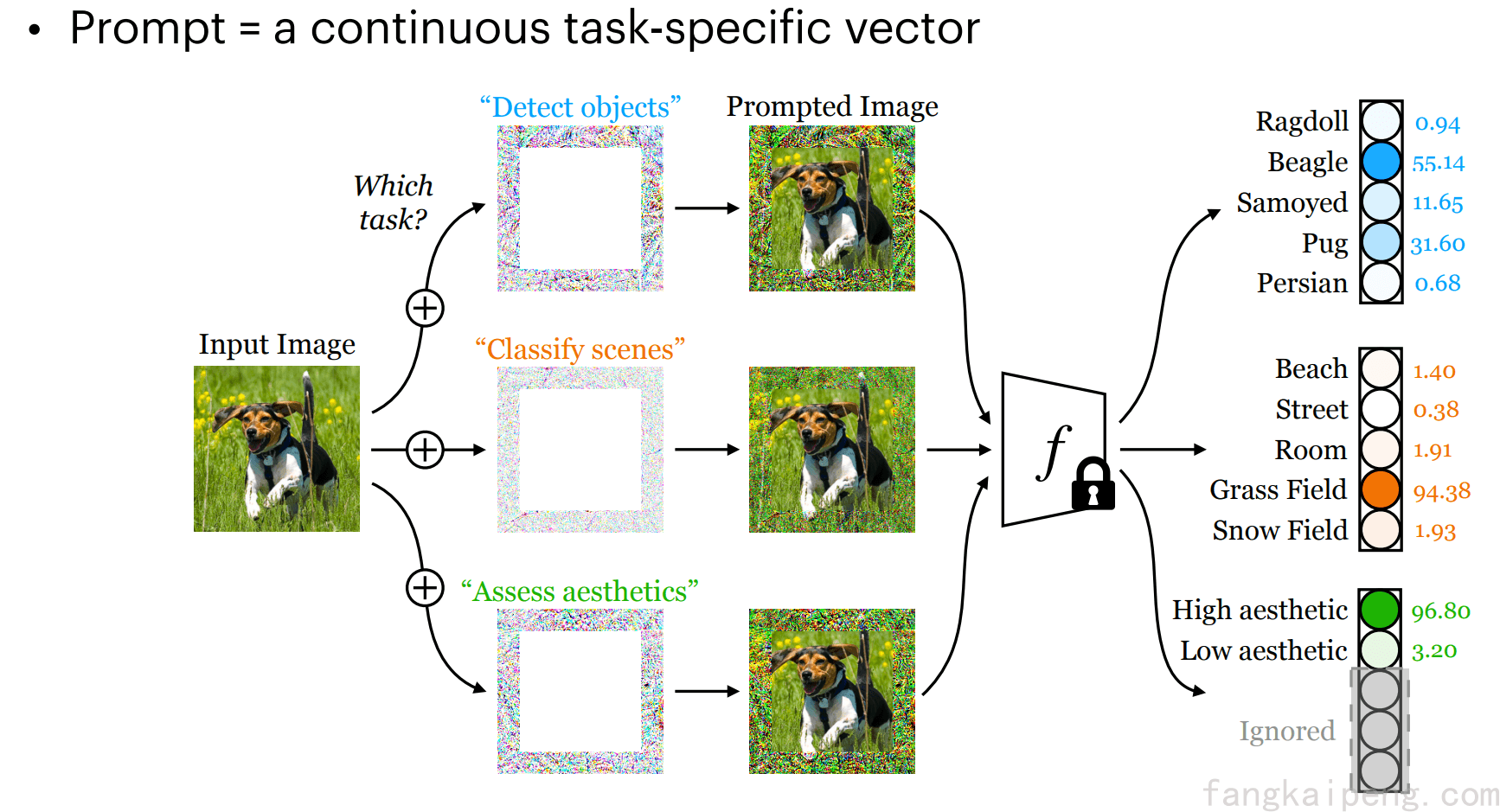
Exploring Visual Prompts for Adapting Large-Scale Models, 2022.
借鉴对抗重编程的思路,我们也可以在输入的周围增加一圈像素来表示不同的任务,并通过训练更新这些像素,如下图所示。除了增加一圈像素外,论文中还是用了小像素点覆盖图片的形式作为prompt。
这篇论文的方法很简单,并且性能也不是很好,基本没有刷新SOTA,甚至连Linear Probing都比不过,如下图所示,性能表现不好,但是我觉得它好的地方在于对这种形式的prompt有比较完整的探索分析。

作者分别探究了Prompt和数据集之间的关系,不同形式prompt对性能的影响,以及CLIP在使用visual prompt的情况下,text prompt的选择对性能的影响。
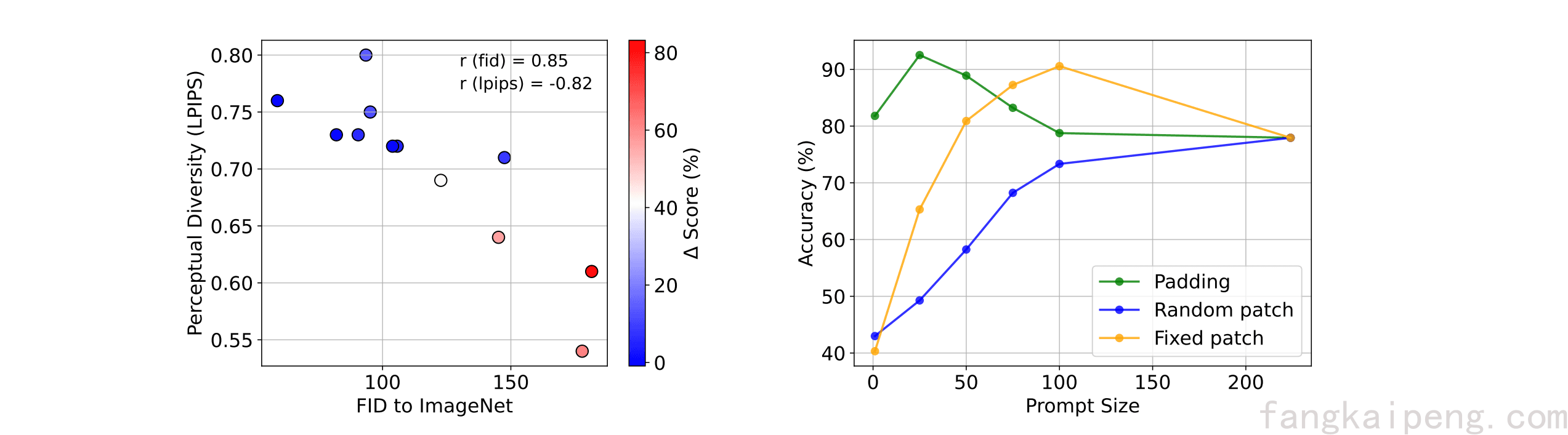
- 首先分析下图左,作者分别探究了数据集整体的shift和数据集内部的差异对性能的影响。作者使用CLIP在ImageNet上进行了微调。先看横坐标,表示其他数据集和ImageNet的差异(FID越大差异越大),可以发现,差异越大,即Out-Of-Distribution越明显,模型的性能提升越高。然后看纵坐标,表示模型内部差异度,可以发现,差异越小,模型性能越好。这说明了两个结论:prompt可以将模型不熟悉的数据转换成模型训练时所熟悉的数据;单一的prompt难以代表复杂的整体。
- 下图右分析了不同prompt形式对性能的影响,可以发现随机位置的表现不好,固定位置的两种方式表现较好。Fixed Patch先升后降,个人感觉是prompt过多导致过拟合,以及破坏了图像原本的信息。
-
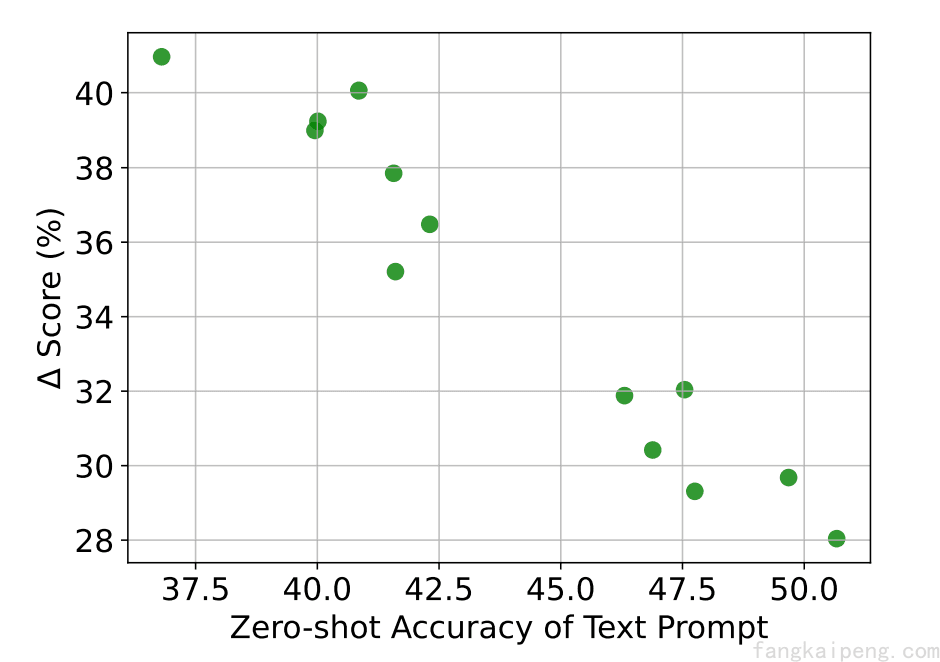
还有一个实验,作者选取不同的text prompt以实现不同的zero-shot CLIP性能(没有使用Visual Prompt,横坐标所示),然后在此基础上使用Visual Prompt,观察提升的性能,发现在使用Visual Prompt后,Text Prompt的选择对性能影响不大,这也是Visual Prompt所带来的一个优势。
II. Prompt Learning in Embedding Space
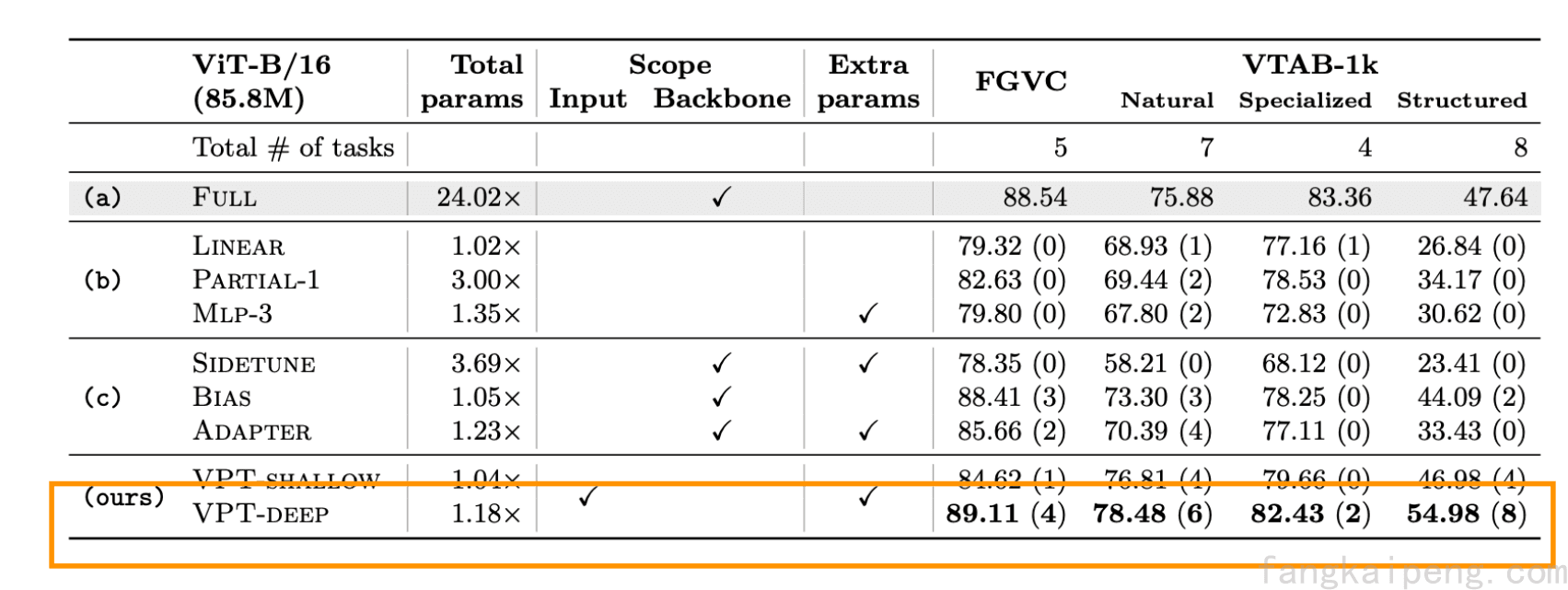
Visual Prompt Tuning, 2022.
如图所示,也是看起来比较简单的一个工作,就是在ViT的输入之前增加几条参数作为prompt。

值得注意的是,这种方式可以超越Fine-Tuning!
3. Key takeaways


