今天Physical Intelligence (PI) 又发表了一篇新工作,作为研发通用机器人模型的全球顶级独角兽公司,这也是PI第一次将关注点放在如何利用人类数据来训练机器人模型。作为Human Data的忠实拥趸,自然是非常激动的。整个工作还是非常具有PI的风格,实验很扎实,写作也非常丝滑,也带来了很多有趣的Insight。接下来我将对论文抽丝剥茧,带大家看看PI能给我们带来什么有趣的思考?
论文标题:Emergence of Human to Robot Transfer in Vision-Language-Action Models
01. 核心动机:回归第一性原理与“Simple is Scalable”的暴力美学
长期以来,机器人学习面临的最大痛点莫过于数据的匮乏。相比于互联网上唾手可得的万亿级文本和图像,高质量的机器人操作数据(Robot Data)显得极其昂贵且稀缺 。自然地,我们把目光投向了人类——毕竟,包含人类操作行为的视频数据是海量的 。然而,过去利用人类视频(Human Video)来训练机器人一直面临着巨大的 Domain Gap:形态不同(灵巧手 vs 平行夹爪)、视角不同、运动学差异巨大 。为了跨越这道鸿沟,学界尝试了各种复杂的“补丁”:从手动设计的重定向(Retargeting)算法,到复杂的中间表征对齐 。
在PI的这篇论文中,我们看到了一种回归 第一性原理(First Principles) 的深刻思考:具身智能的本质应当是对物理世界交互逻辑的理解,而非对特定肢体运动学的机械模仿。正如不同口音的人说着同一种语言,人类与机器人的操作在物理本质上是同构的。如果模型真正理解了‘收拾餐桌’这一任务背后的物理因果,那么执行者是碳基的人手还是硅基的夹爪,本质上只是 ‘方言’ 的区别,而非无法沟通的 ‘语言’ 隔阂。基于此,PI下注了一个极具 ‘Simple is Scalable’ 精神的假设:
如果VLA模型的预训练数据足够多样化,那么模型是否会自动涌现出理解人类数据的能力,而无需任何显式的对齐设计?
这是一个非常大胆且性感的假设。这意味着我们终于可以告别复杂的Retargeting算法和繁琐的手工特征映射。通往通用具身智能的最优解,或许就藏在最朴素的 Scaling Law 之中——大道至简,重剑无锋。
02. 演进之路:人类数据利用的“三重境界”
在深入PI的方法之前,我们需要厘清学术界在利用人类数据上的演进脉络。这并非全新话题,但如何“用好”这一数据源,学界经历了三个阶段的探索,而PI的突破正是建立在对这些路径的“破局”之上:
- 视觉表征的“预热”(Visual Representations):最早期的尝试,如 R3M [1] 和 VIP [2]。核心逻辑是利用大规模人类视频“只练眼,不练手”,训练通用的视觉编码器。但这导致模型只学到了特征,下游动作生成仍需从零学习策略。
- 寻找“动作”的代理(Proxy Tasks):为了提取与动作相关的信息,研究者引入了中间任务,如预测关键点轨迹 (Track2Act [3]) 、功能可见性 (Affordance [4])、奖励函数 (Reward Modeling [5])、隐式动作表征 (Latent Actions [6]) 。虽然比纯视觉更进一步,但这并非直接的控制信号,中间存在巨大的转化损耗。
- 联合训练与显式对齐(Unified Policies with Explicit Alignment):这是目前最主流的方向 [7] [8]。利用VR/手部追踪提取3D姿态进行联合训练。但痛点在于,由于缺乏数据规模,为了让模型收敛,研究者不得不依赖 显式对齐(运动学重定向、视觉风格迁移或隐变量对齐)。这些人工先验(Manual Engineering)虽然短期有效,却限制了模型的大规模扩展。
PI的破局点:基于
注:论文只引用了少量代表性工作,还有很多有趣的工作详见论文原文或自行搜索
03. 方法设计:Simple is Better
PI 的核心方法论可以概括为:将人类视为一种特殊的、具有高度自由度的机器人实体(Embodiment)。 他们没有选择设计复杂的域适应损失函数,而是通过在传感器配置和动作空间上进行极其克制的“软对齐”,让模型在海量数据中自动通过 Scaling Law 抹平差异。
A. 数据采集:模拟机器人的视角
为了在输入端最大程度地减小 Domain Gap,PI 并没有直接使用互联网上的第三人称被动视频,而是构建了一套“模拟机器人视角”的采集系统 。
- 头戴式视角(Ego-view):采集员佩戴头戴式、高分辨率相机(iPhone夹在头上),模拟机器人的 Ego-centric 视角 。
- 手腕式视角(Wrist-view):这是本文极其精妙的一个设计。考虑到现代机械臂操作高度依赖手腕相机(Wrist Camera)来处理遮挡和精细操作,PI 让采集员在双手手腕上也佩戴了摄像头 。这不仅增加了视角的丰富度,更重要的是在物理层面强行对齐了人类与机器人的传感器布局 。后续消融实验也证明,这种“传感器层面的模拟对于某些精细任务(如整理梳妆台)至关重要 。
B. 动作空间的“软对齐”
为了让模型能像理解机器人数据一样理解人类视频,PI 设计了一套标准化的处理流程,将人类的动作“翻译”为通用的控制信号:
- 视觉估算(CV Pipeline): 首先,必须从原始 RGB 视频中提取出精确的空间信息。PI 使用视觉 SLAM 技术重建头戴式相机的 6D 运动轨迹(相对于世界坐标系)。同时,利用 3D 关键点检测算法,在头部相机坐标系下重建双手的 17 个 3D 关键点 。
- 构建“共有”动作空间(Shared Action Space): 为了对齐机器人末端执行器(End-effector),PI 并没有使用整只手的姿态,而是选取了掌心、中指和无名指的关键点来定义一个“虚拟末端执行器”的坐标系 。 基于此,系统计算出该虚拟末端相对于当前帧的相对位姿变化(Relative Transformations)。这与机器人数据中定义的动作空间(相对于当前状态的 6-DoF 变化量)完全一致 。
- 差异处理:大胆放弃 Gripper: 虽然手臂轨迹对齐了,但末端开合不仅难以对齐,而且从视频中估算人类手指的“开合度”噪声极大且极其困难 。 因此,PI 采取了“抓大放小”的策略:在人类数据上,模型只学习 6-DoF 的手臂轨迹,而完全忽略抓取(Gripper)动作。抓取动作的学习完全依赖于混合数据中的机器人数据 。这种策略巧妙地规避了错误标签的干扰。
C. 训练配方:Co-training
模型架构基于
微调时的配方非常简单暴力:50% 人类数据(用于泛化任务) + 50% 机器人数据(最接近的邻居任务)。 没有任何额外的Domain Adaptation Loss。
04. 实验剖析:Scaling Law 的胜利
这是整篇论文最精彩、也最扎实的部分。作者没有停留在“刷榜”上,而是像做手术一样解剖了 Transfer 发生的每一个环节。
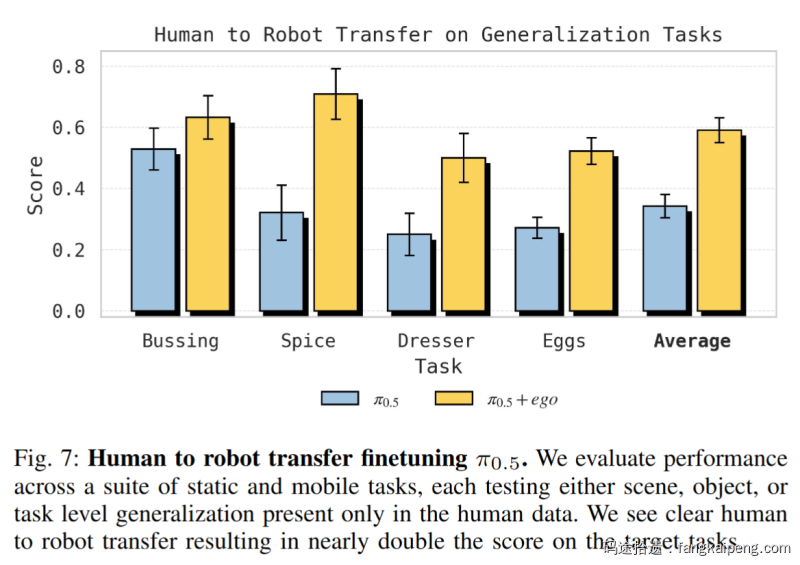
实验1:Zero-shot 泛化能力的跃升
首先是验证核心假设:人类数据到底能不能让机器人学会它从未见过的东西?作者构建了一个极其刁钻的 "Human to robot transfer benchmark",包含三个维度的外推:
- 新场景(Scene):机器人只在训练过的Airbnb里工作,人类数据教它在从未见过的陌生厨房(Spice)和卧室(Dresser)里干活 。
- 新物体(Object):机器人只收拾过旧餐具,人类数据教它收拾未见过的厨房工具(Bussing).
- 新任务(Task):机器人只会“放鸡蛋”,人类数据教它按颜色“分类鸡蛋” 。
结果令人印象深刻:引入人类数据联合微调(
- Spice 任务:成功率从 32% 飙升至 71%。
- Dresser 任务:从 25% 提升至 50%。
- Sort Eggs 任务:准确率达到 78%,而基线模型完全不懂分类逻辑,只会随机乱放。
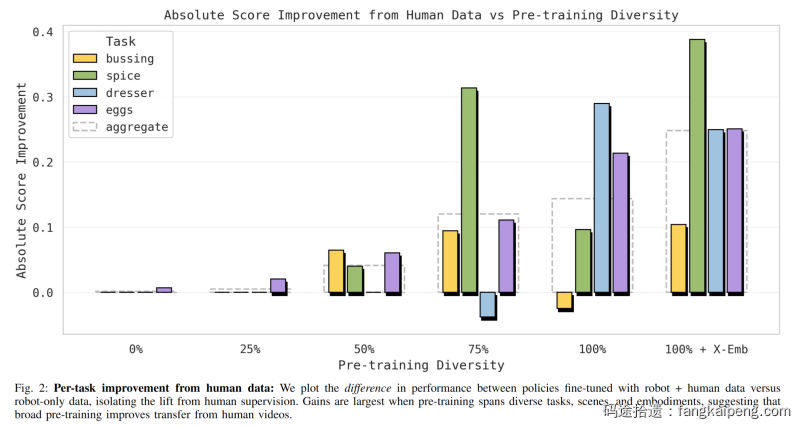
实验2:核心Insight——泛化是预训练多样性的函数
这是论文最核心的图表(Figure 2)。作者对比了在不同预训练多样性(0% 到 100% 以及包含更多实体的 X-Emb)下,微调阶段加入人类数据带来的提升。
- 低多样性(0-25%):加入人类数据几乎没用,甚至有负迁移。这时候模型太“弱”,分不清人和机器人。
- 高多样性(>75%):Transfer效果爆发式增长。
潜空间对齐(Latent Alignment):作者还通过 t-SNE 可视化了视觉 Token 的分布。
- 初期:人类数据和机器人数据的 Feature 是分离的两个团 。
- 后期:随着预训练增强,两者自动重叠在了一起 。这证明了 Human-to-Robot Transfer 是一个涌现属性——模型在见过足够多的机器人形态后,自动学会了把“人手”归类为一种特殊的“末端执行器”。
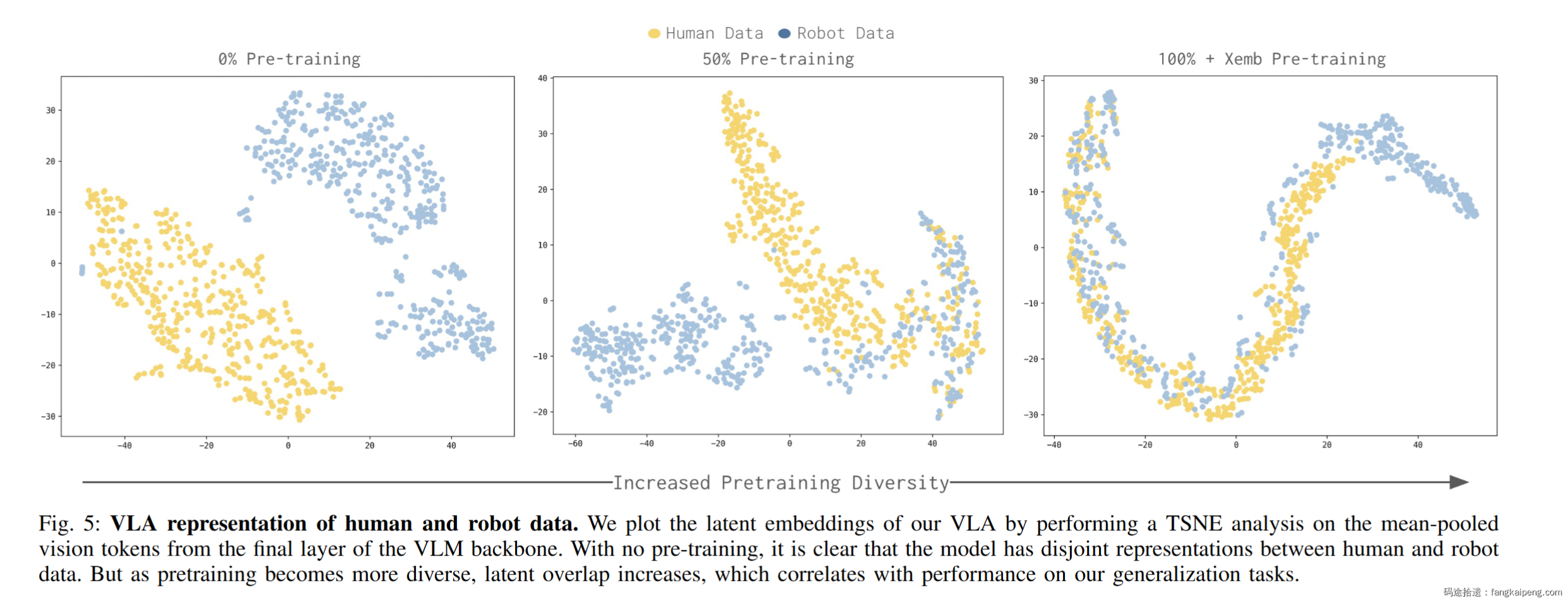
这揭示了一个深刻的结论:Human-to-Robot Transfer是一个涌现属性。 只有当VLA在足够多样的机器人数据上见过足够多的世面后,它才能自动在潜空间(Latent Space)里把“人手”和“夹爪”对齐。
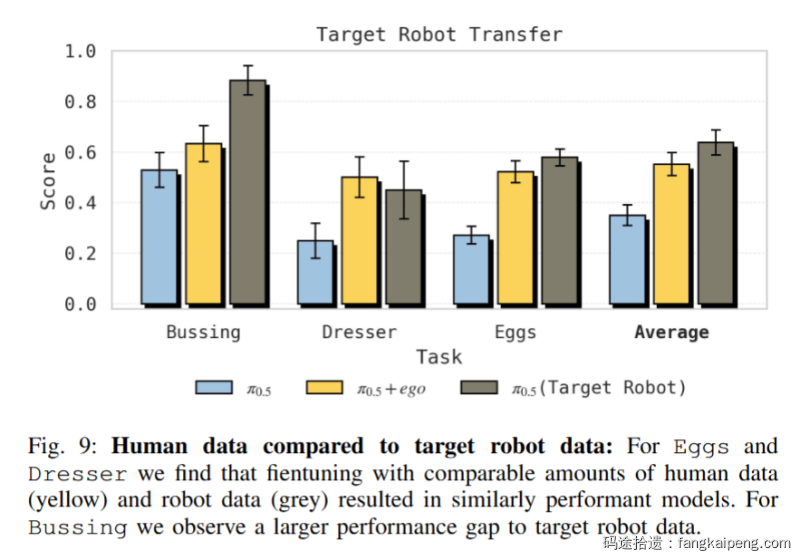
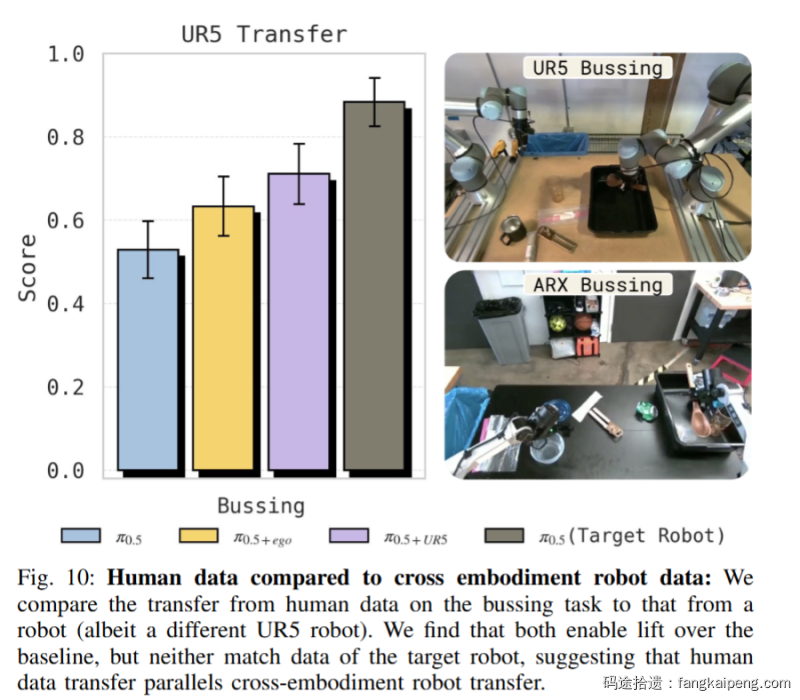
实验3:人类数据
对比目标机器人真值(Target Robot Data,Upper Bound):
- 在 Sort Eggs 和 Dresser 任务上,人类数据的微调效果几乎等同于使用目标机器人(Target Robot)自己的数据 。这非常惊人,意味着我们可以用廉价的人类数据替代昂贵的机器人数据。
- 但在 Bussing 任务上,人类数据还是弱于目标机器人数据(25% vs 65%),说明对于某些任务,Domain Gap 依然很难完全跨越 。
对比跨机器人迁移(Cross-Embodiment):
- 作者尝试用 UR5 机器人的数据来教 ARX 机器人(Target)。结果发现,人类数据的迁移效果与 UR5 -> ARX 的迁移效果非常相似 。
- 这进一步支持了 PI 的观点:在强大的基座模型面前,人类无非就是一种长得比较奇怪、自由度比较高的机器人罢了 。
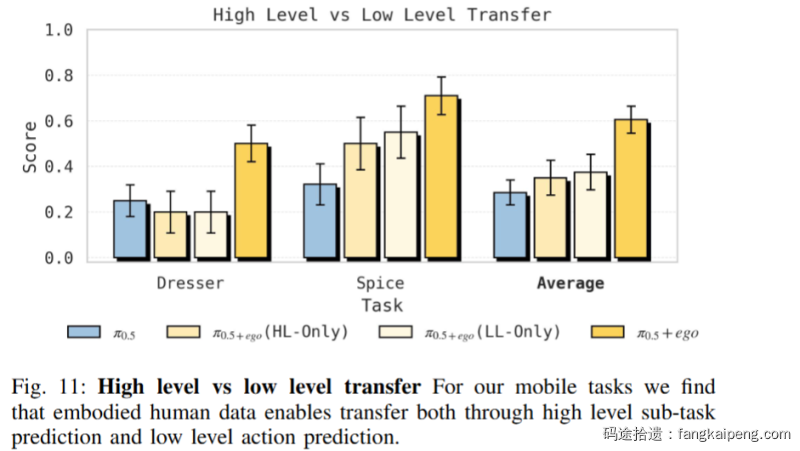
实验 4:迁移发生的层级
迁移到底是发生在“脑子”(高层语义)还是“手”(低层动作)?作者设计了精巧的消融实验,分别只用人类数据训练 High-Level (HL) 或 Low-Level (LL) 策略 。
-
结果:只有 HL + LL 同时联合训练 才能达到最佳效果 。
-
失效模式:
- 仅 HL:低层策略听不懂指令。比如 HL 说“去拿项链”,LL 却把项链扔进了错误的盒子里 。
- 仅 LL:高层策略由于没见过新物体,会发出错误的指令(如一直重复喊“拿起瓶子”,哪怕瓶子已经被拿起来了)。 这证明了人类数据不仅教会了机器人“做什么”(语义规划),也教会了它“怎么做”(动作执行)。
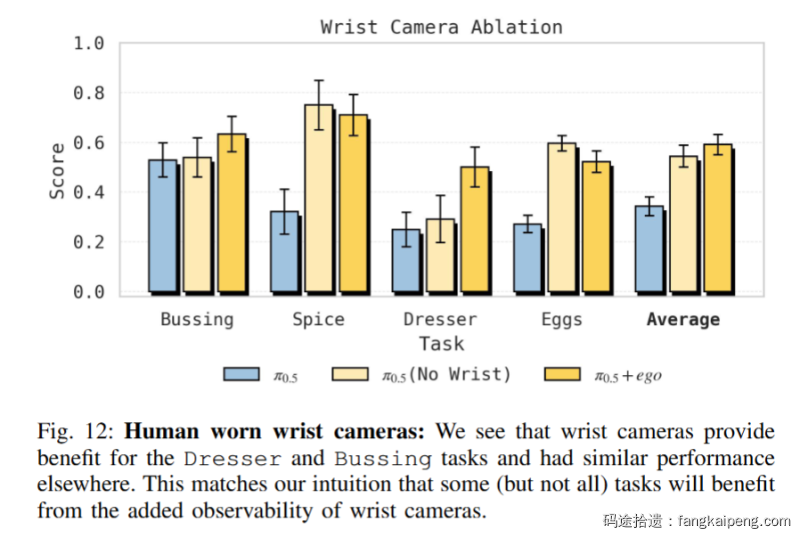
实验 5:传感器配置的重要性(The "Hardware")
还记得那个看似多余的“手腕相机”吗?消融实验证明它是必不可少的。
- 移除手腕相机后:在 Dresser(整理梳妆台)和 Bussing(收拾餐桌)这两个任务上,性能显著下降 。
- 原因:这些任务涉及严重的遮挡或精细操作,头戴视角的盲区太大。如果人类数据缺乏这一视角,模型就无法学会处理遮挡下的动作 。
- 结论:在采集人类数据时,物理层面的传感器模拟(Sensor Simulation)是实现高效迁移的关键一环 。
05. 总结与展望:当“人”成为一种通用的“具身”
读完这篇 Paper,最大的感受并非是单纯的技术震撼,而是一种范式转移(Paradigm Shift)的快感。
PI 用最扎实的实验告诉我们:Deep Learning 的暴力美学在机器人领域依然奏效,但前提是你必须对物理本质有足够的尊重。
过去,我们把人类数据看作一种需要被“翻译”的外语(Retargeting);现在,PI 证明了只要模型见过足够多的世面(Pre-training Diversity),人类数据不过是另一种“方言”。这篇工作最大的贡献,在于它打破了 Human Data 和 Robot Data 的边界,将“人类”重新定义为一种无需特殊对待的、具有极高灵巧度的 Robot Embodiment。
面向未来的几个核心思考:
- 从“主动采集”到“被动挖掘”的最后一公里: 本文虽然利用了人类数据,但这依然是经过精心设计的“情景式(Episodic)”数据——采集员必须佩戴特制的手腕相机。实验 5 证明了这些手腕视角对于解决遮挡至关重要。 那么,如何利用 YouTube 上那万亿级、非结构化、且没有手腕视角的“被动视频”? 这将是下一个圣杯。也许未来的模型能通过“脑补”手腕视角,或者通过更大规模的 Video Generative Model 来填补这一缺失的信息。
- 通用机器人(Generalist)的新定义: 以前我们认为的通用机器人是指“能做很多任务”的机器人。PI 这篇工作暗示了新的定义:真正的通用机器人,是指“能从任何具身数据中学习”的机器人。 无论是狗的奔跑、人的烹饪,还是机械臂的焊接,在物理智能(Physical Intelligence)的底层逻辑上,或许都是相通的。
- Scaling Law 的下一个战场: 如果在 75% 的数据多样性下就能涌现出对齐能力,那么在 1000% 的多样性下会发生什么?是否会出现 Zero-shot 的形态适应?是否机器人看一眼人类的动作视频,就能直接在完全不同的身体结构上复现其意图?
- 向后退一步的思考:从“动作克隆”到纯粹的“观察学习” 从第一性原理出发,PI 目前的方法仍依赖 CV 算法显式估计 Keypoints ,这在光照复杂或遮挡严重的 In-the-wild 视频中极易成为瓶颈。反观人类,我们无需计算关节坐标,仅凭纯视频观察即可习得技能。未来的 Policy 是否可以跳过“姿态估计”这一中间商,直接从像素中提取智能?比如借助 世界模型(World Models) 预测物理演变?或者是利用 视觉奖励(Visual Reward) 进行 RL 探索?还是其他还没出现的范式?目前没有非常好的想法,但个人觉得是一个很好的出发点。
结语:
机器人通用模型的黎明,或许并不在于我们造出了多么完美的机械身体,而在于我们终于学会了如何让硅基的大脑读懂碳基的经验。PI 迈出了坚实的一步,通过 "Simple is Scalable" 的哲学,让我们确信:在通往 AGI 的路上,Scale is all you need, provided you scale the right thing.
参考文献:
[1] R3m: A universal visual representation for robot manipulation
[2] Vip: Towards universal visual reward and representation via value-implicit pre-training
[3] Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation
[4] Affordances from human videos as a versatile representation for robotics
[5] Learning generalizable robotic reward functions from in-the-wild human videos
[6] Latent action pretraining from videos
[7] Egomimic: Scaling imitation learning via egocentric video
[8] Egobridge: Domain adaptation for generalizable imitation from egocentric human data
