零、前言
很早就打算学python了,但后来各种事情太多就又耽搁了(主要是太会摸鱼了)。这学期开了python课,就打算继续开始学习,先快速学习一下python的基础语法,后续有机会还会学习python比较厉害的爬虫、数据分析、数据可视化等。感觉学习一门语言,及时的记录是很重要的,不仅可以加深印象也方便以后的查阅,本篇博客记录的是python中较为基础的语法、数据类型和一些常用的库。语言只是个工具,算法和编程思想才是灵魂,并且对于编程语言的学习实践是极为重要的,所以我选择了北理工的Python语言程序设计课程辅助学习,因为他们附带了一个oj可以用于练习,实属良心!那么就开始快乐的python之旅吧~
一、基本语法
1.1 输入输出
1.1.1 输入
input() 函数用于从控制台获取用户的输入,并以字符串的形式返回用户的输入,以换行标志一次输入的结束,括号内可以填写一个字符串,表示输入的提示信息,该字符串不会被当做输入读取。
<变量> = input(<提示信息字符串>)
Str = input("请输入")
1.1.2 输出
print()函数以字符串形式向控制台输出结果,括号内填写字符串或字符串变量。
-
eval()函数去掉参数最外侧的引号并执行余下语句。该语句基础用法是用于字符串向数字的转换,但还有更高级的用法。去掉最外侧的引号后如果不是字符串,Python在编译代码时会先去检查该语句是否代表某个变量或者Python中可执行的语句,如果是则会表示成此变量或运行相应的语句,如果不是将报错。
print(eval("1")) #输出1 print(eval('"1+2"')) #输出1+2 print(eval("1+2")) #输出3,去掉最外侧的引号后是一个加法算式,运算后输出结果 a = 3 print(eval("a")) #输出3,去掉最外侧引号后不是字符串,表示变量a,则输出a的值 - 槽和格式化
print("xxx{}".format(c)){}表示一个槽,槽内设置格式化输出的要求,然后在format中写出具体的变量名,详细介绍见 2.2.5字符串类型的格式化。
1.2 注释格式
- 单行注释:以
#开头,其后为注释内容 - 多行注释:以
'''开头和结尾,之间是注释内容,本质上是一个字符串,Python中没有进行任何操作的字符串在程序运行时会直接跳过,不会被处理。
1.3 分支结构
基本格式:
if <条件1> :
<语句块1>
elif <条件2> :
<语句块2>
...
else :
<语句块N>
# 简写
<语句块1> if <条件1> else <语句块2> #如果条件1符合则执行语句块1,否则执行语句块2
特殊的分支——异常:
- 报错语句分析:
当Python运行出错时会结束程序并给出如下错误信息。

-
异常处理
trytry : <语句块1> #执行语句块1并检测是否出错 except <异常类型>: <语句块2> #如果语句块1出现与异常类型相同的错误,执行语句块2 else : <语句块3> #未发生异常,执行语句块3 finally : <语句块4> #无论是否异常都执行语句块4

1.4 循环结构
range函数:
range(m,n,k) #从m开始产生一个小于n的序列,步长为k
range(1,6,2) = [1,3,5]
基本格式:
for <循环变量> in <遍历结构> :
<语句块>
#从遍历结构中逐一提取元素,放在循环变量中,并执行一次语句块,完整遍历所有元素后结束
#举例:
#遍历range函数
for i in range(1,6):
print(i,end = " ") #输出1 2 3 4 5
#遍历字符串
for c in "Python123":
print(c, end=",") #输出:P,y,t,h,o,n,1,2,3,
#遍历列表
for item in [123,"PY", 456] :
print(item, end=",") #输出123,PY,456,
while <条件> :
<语句块>
# 反复执行语句块,直到条件不满足时结束
循环控制保留字:
break:跳出并结束当前整个循环,执行循环后的语句。continue:结束当次循环,继续执行后续次数循环。
循环的扩展:
当循环没有被break语句退出时,执行else语句块,else语句块作为”正常”完成循环的奖励,这里else的用法与异常处理中else用法相似。
for <变量> in <遍历结构> :
<语句块1>
else :
<语句块2>
while <条件> :
<语句块1>
else :
<语句块2>
1.5 库引用和import关键字
Python之所以强大不仅仅因为其上手简单,语法通俗,更因为它有庞大的库。库引用是扩充Python程序功能的方式,使用import关键字完成。
格式:
import<库名> ,引用后要使用库中的某个函数则采用 <库名>.<函数名>(<函数参数>) 的格式。
其他用法:
可以使用from <库名> import * 引用某个库,这种方法引用库后可以直接使用函数,无需使用 <库名>.<函数名> 的方式。
高级用法:
import <库名> as <库别名> 可以给库起别名,便于代码的书写,使用函数的格式为:<库别名>.<函数名>(<函数参数>)。
1.6 函数的定义和调用
1.6.1 定义格式:
def <函数名>(<参数(0个或多个)>) :
<函数体>
return <返回值>
def fact(n) : #计算n!
s = 1
for i in range(1, n+1):
s *= i
return s
1.6.2 特殊的参数类型
- 可选参数类型
函数定义时可以为某些参数指定默认值,构成可选参数,调用函数时可选参数类型可以填写也可以不填写。
def fact(n, m=1) : #m为可选参数类型,计算n!/m的值 s = 1 for i in range(1, n+1): s *= i return s//m - 可变参数类型
函数定义时可以设计可变数量参数,既不确定参数总数量,类似C++中的指针。
def fact(n, *b) : #*b为可变参数,计算n!乘上一些数后的值 s = 1 for i in range(1, n+1): s *= i for item in b: s *= item return s
1.6.3 函数的返回值
函数可以返回0个或多个结果,return 用于返回值,可以返回任意多个值,return 在函数中不是必须的。
举例:
def fact(n, m=1) :
s = 1
for i in range(1, n+1):
s *= i
return s//m, n, m
a,b,c = fact(10,5)#可以用这种方式接收返回值,按照位置一一对应
1.6.4 局部变量和全局变量
规则一:局部变量和全局变量是不同变量:
- 局部变量是函数内部的占位符,与全局变量可能重名但不同
- 函数运算结束后,局部变量被释放
- 可以使用global保留字在函数内部使用全局变量
规则二:局部变量为组合数据类型且未创建,等同于全局变量
ls = ["F","f"]
def func(a) :
ls.append(a)
return
func("C")
print(ls) #输出['F', 'f', 'C']
ls = ["F","f"]
def func(a) :
ls = []
ls.append(a)
return
func("C")
print(ls) #输出['F', 'f']
1.6.5 lambda函数
定义方式:
<函数名> = lambda <参数>: <表达式>
#等价于:
def <函数名>(<参数>) :
<函数体>
return <返回值>
举例:
f = lambda x, y : x + y
f(10, 15) = 25
f = lambda : "lambda函数"
print(f()) # 输出lambda函数
二、基本数据类型
2.1 数字类型
2.1.1 整数类型
Python中的整数不同于C++等语言,它没有取值范围限制,与数学中整数的概念一致。
四种进制表示形式:
- 十进制:1010, 99, -217
- 二进制,以0b或0B开头:0b010, -0B101
- 八进制,以0o或0O开头:0o123, -0O456
- 十六进制,以0x或0X开头:0x9a, -0X89
2.1.2 浮点数类型
与数学中实数的概念一致,但是浮点数取值范围和小数精度都存在限制,取值范围数量级约 $-10^{307}到10^{308}$,精度数量级$10^{-16}$,且浮点数间运算存在不确定尾数,如Python中 0.1 + 0.2 = 0.30000000000000004,可以使用round() 进行四舍五入,具体函数操作后面有专门描述。
科学计数法:
浮点数可以采用科学计数法表示,使用字母e或E作为幂的符号,以10为基数,格式为<a>e<b> ,表示 $a*10^b$ ,比如 4.3e-3 = 0.0043,9.6E5 = 960000.0
2.1.3 复数类型
与数学中复数的概念一致,定义 $j = \sqrt {-1}$ ,-a+bj被称为复数,其中,a是实部,b是虚部。
z = 1.23e-4+5.6e+89j
z.real() #获得实部
z.imag() #获得虚部
2.1.4 数值运算操作符



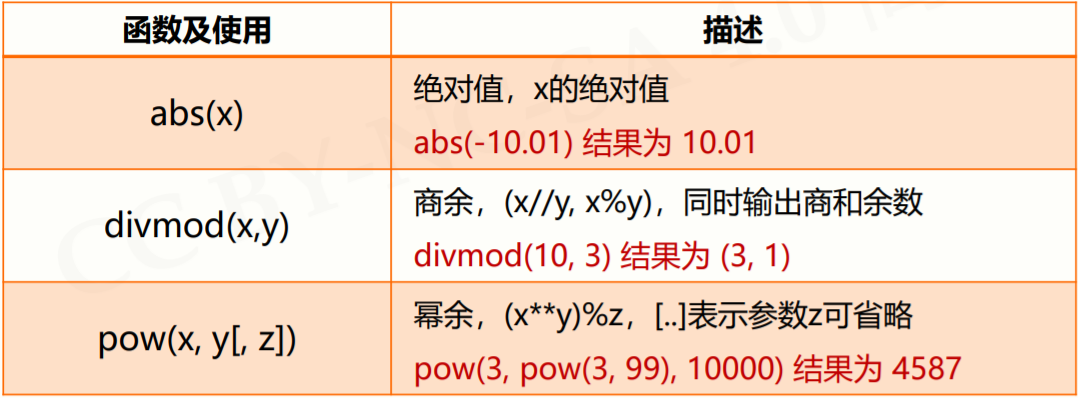
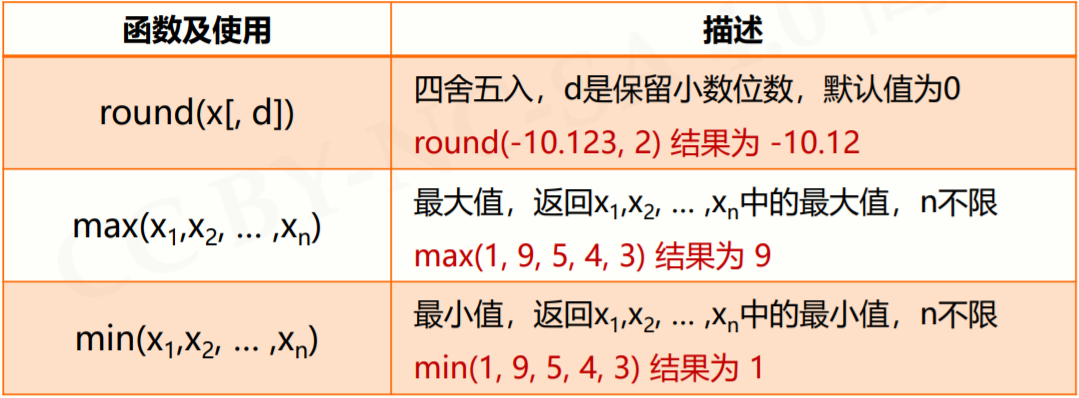
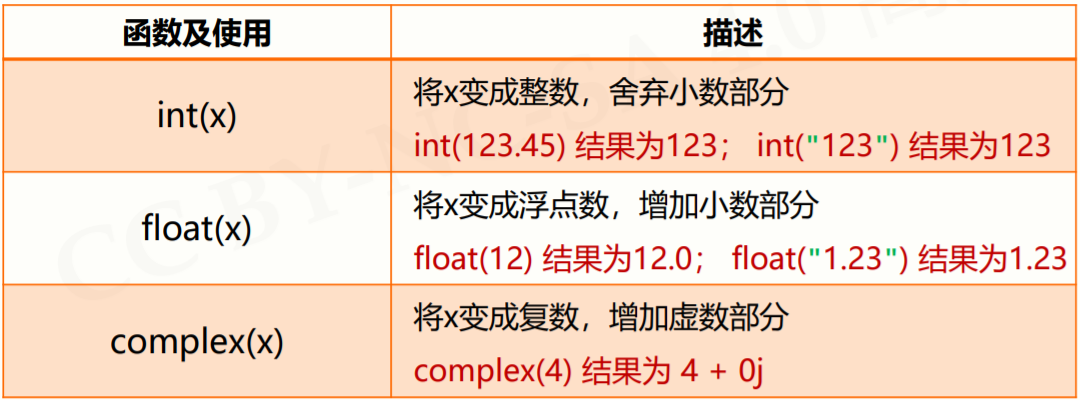
2.1.5 数值运算函数
2.2 字符串类型
2.2.1 字符串类型的表示
两种表示方法:
- 由一对单引号或双引号表示,仅表示单行字符串
'1234' "12345" - 由一对三单引号或三双引号表示,可表示多行字符串
s = '''qw1234 2134123'''
Python之所以设置那么多种表示方法,是为了避免字符串中包含 (‘) 或者 (”) ,使得字符串无法正确表示的情况。
字符串的序号:
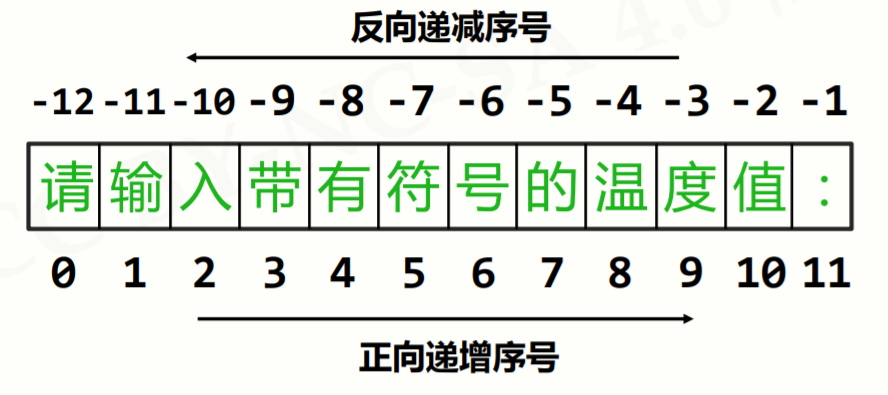
切片操作:
<字符串>[M: N: K]类似range函数,M表示开始序号,N表示结尾序号且不包括下标为N的字符,K表示步长,即每隔几个字符取一次。M省略表示从开头开始,N省略表示从结尾开始,K省略表示步长为1,如果[ ]内只有一个数字则表示索引,即取以数字为下标的那一个字符。
示例:
"1234"[2] = "3"
"1234"[-1] = "4"
"1234"[1:3] = "23"
"01234"[:3] = "012"
"01234"[3:] = "34"
"0123456789"[2:9:2] = "2468"
特殊字符:
转义符 \ 表达特定字符的本意,如:
print("这里有个双引号(\")") #输出 这里有个双引号(")
一些与转义符的特殊组合:
\b回退
\n换行(光标移动到下行首)
\r 回车(光标移动到本行首)
2.2.2 字符串操作符

2.2.3 字符串处理函数
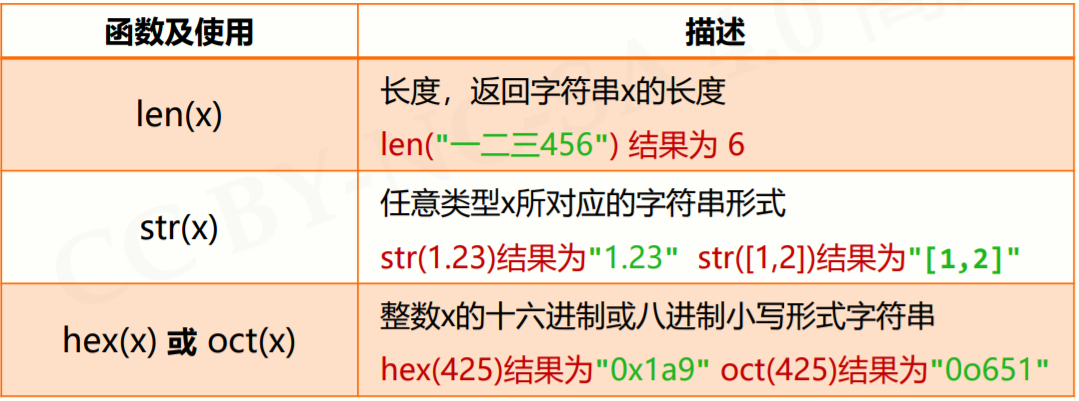
Python的字符串使用Unicode编码,这是一种覆盖几乎所有字符的编码方式 ,从0到1114111 (0x10FFFF)空间,每个编码对应一个字符,Python字符串中每个字符都是Unicode编码字符。

2.2.4 字符串处理方法
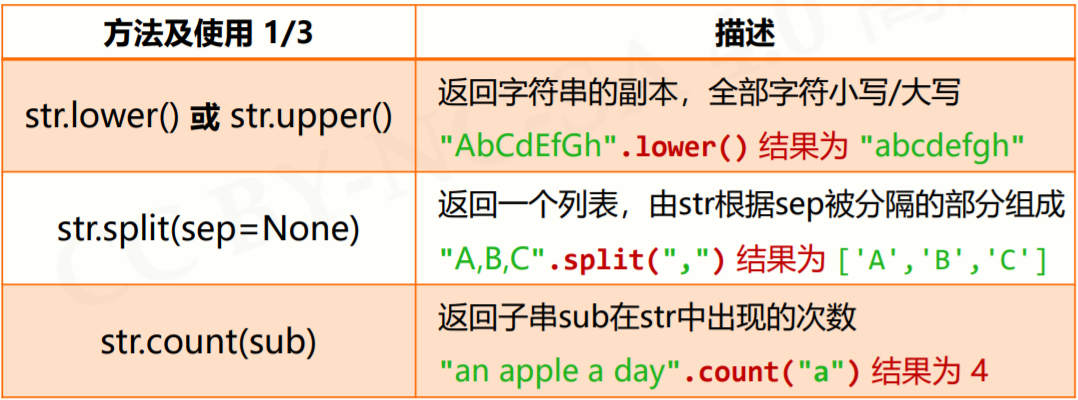
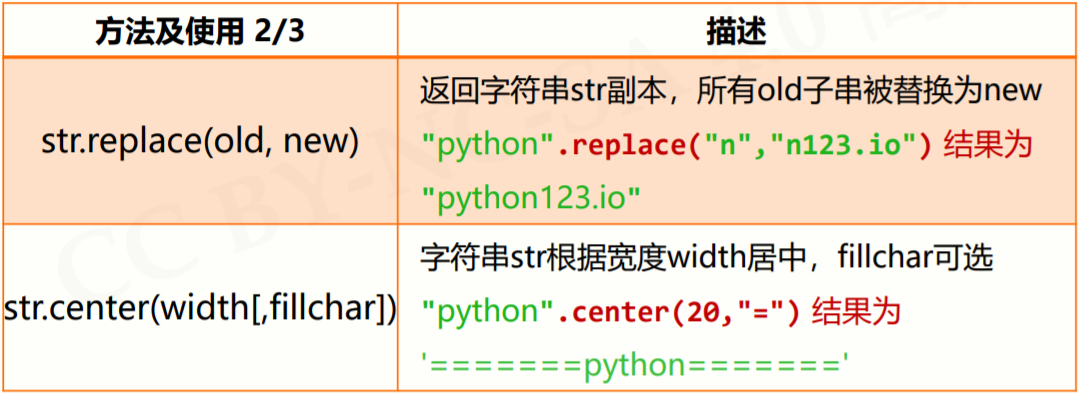

2.2.5 字符串类型的格式化
format() 方法:
此方法用于字符串的格式化,格式为:<模板字符串>.format(<逗号分隔的参数>)
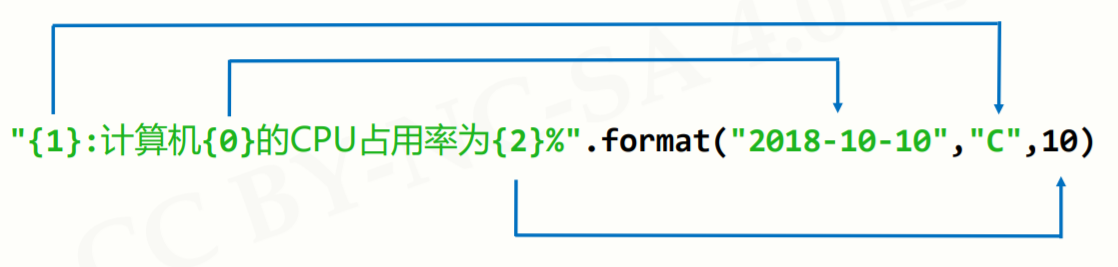
槽的概念:
在字符串中使用{ }作为一个槽,表示此处挖了一个空待填,槽中可以设置相应的字符串模板,槽中需要填写的字符串在后面的.fotmat()中给出,如下图所示:

槽中还可以指定字符串对应的顺序:
格式化控制标记:
前面说过槽中可以设置字符串格式化模板,具体格式如下:

举例:
"{0:=^20}".format("PYTHON") = '=======PYTHON======='
"{0:*>20}".format("BIT") = '*****************BIT'
"{:10}".format("BIT") = 'BIT '
"{0:,.2f}".format(12345.6789) = '12,345.68'
"{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(425) = '110101001,Ʃ,425,651,1a9,1A9'
"{0:e},{0:E},{0:f},{0:%}".format(3.14) = '3.140000e+00,3.140000E+00,3.140000,314.000000%'
2.3 集合类型
2.3.1 集合类型的定义
集合是多个元素的无序组合 ,类似c++中点set,数据去重,但是无序。
- 集合类型与数学中的集合概念一致
- 集合元素之间无序,每个元素唯一,不存在相同元素
- 集合元素不可更改,不能是可变数据类型(如果可以修改则不能保证元素之间不相同)
-
集合用大括号 {} 表示,元素间用逗号分隔 ,建立集合类型用
{}或set(),建立空集合类型,必须使用set()
例子:
A = {"python", 123, ("python",123)} #使用{}建立集合,()表示一个元组
#{123, 'python', ('python', 123)}
B = set("pypy123") #使用set()建立集合,字符串会被拆分成几个字符
#{'1', 'p', '2', '3', 'y'}
C = {"python", 123, "python",123} #自动去重
#{'python', 123}
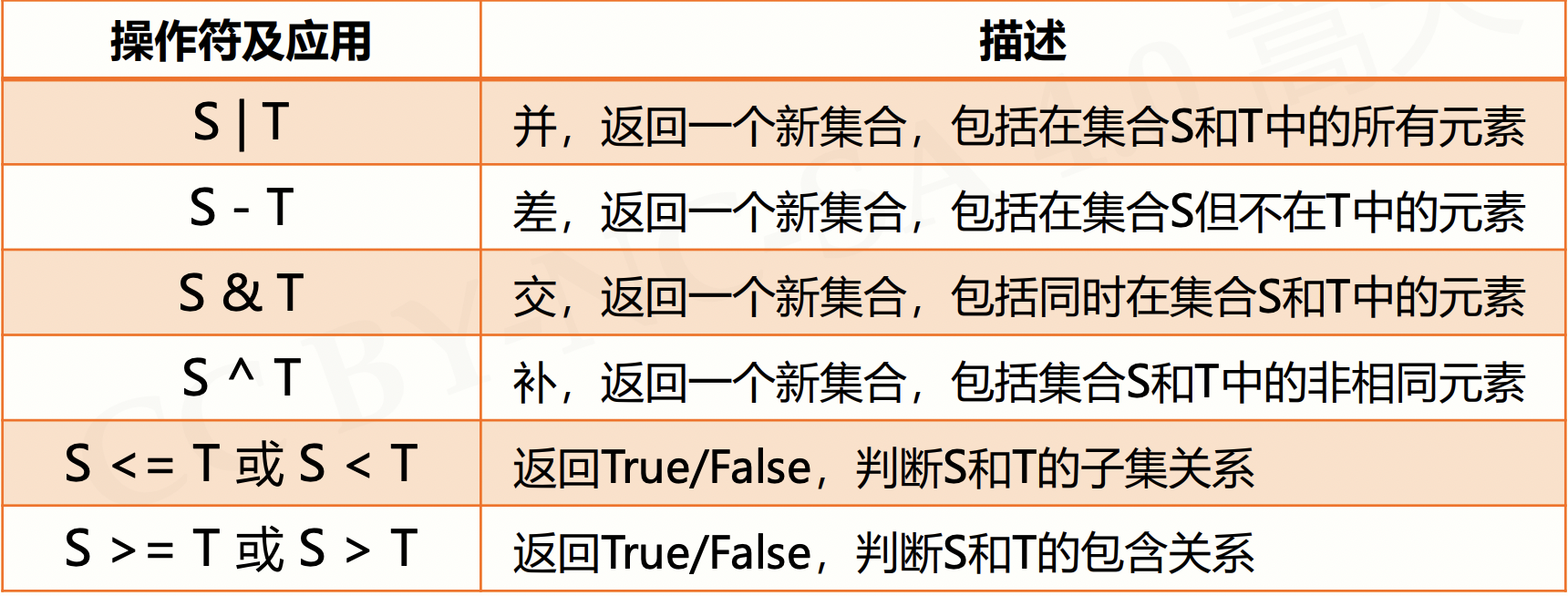
2.3.2 集合操作符
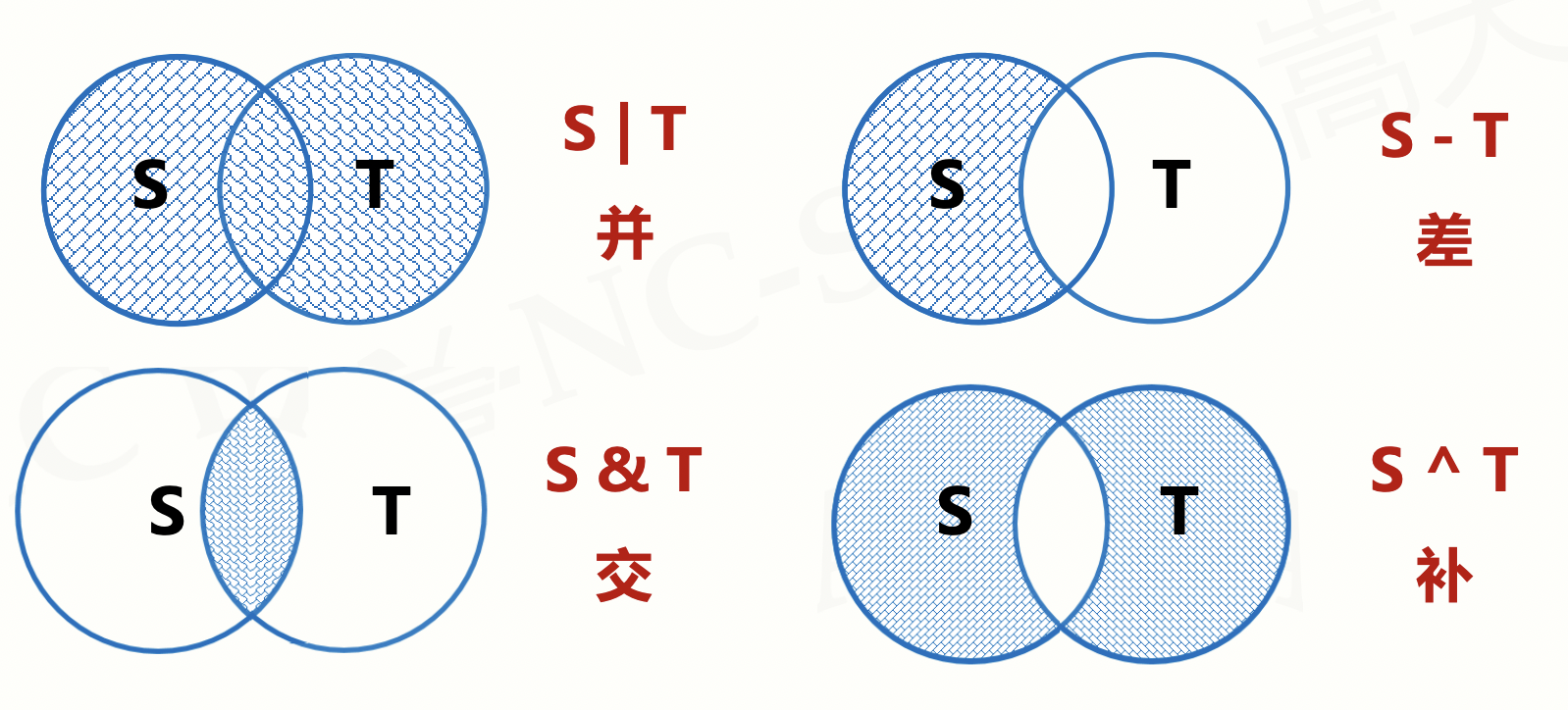
一共有四种基本操作,对应符号如图所示。

2.3.3 集合处理方法


2.3.4 应用
根据集合的特点,可以用于数据去重(将某个列表用set()转化成集合类型即可),以及通过集合操作符进行包含关系的比较。
2.4 序列类型
2.4.1 序列定义
序列是具有先后关系的一组元素 。
- 序列是一维元素向量,元素类型可以不同。
- 类似数学元素序列:$ s_0, s_1, … , s_{n-1} $。
- 元素间由序号引导,通过下标访问序列的特定元素。
- 序列类型是一个基类类型,包括字符串、列表、元组都属于序列类型,他们有各自的特点和处理函数。
- 序列类型的序号定义可以见上文字符串类型,两者是相同的。
2.4.2 序列处理函数
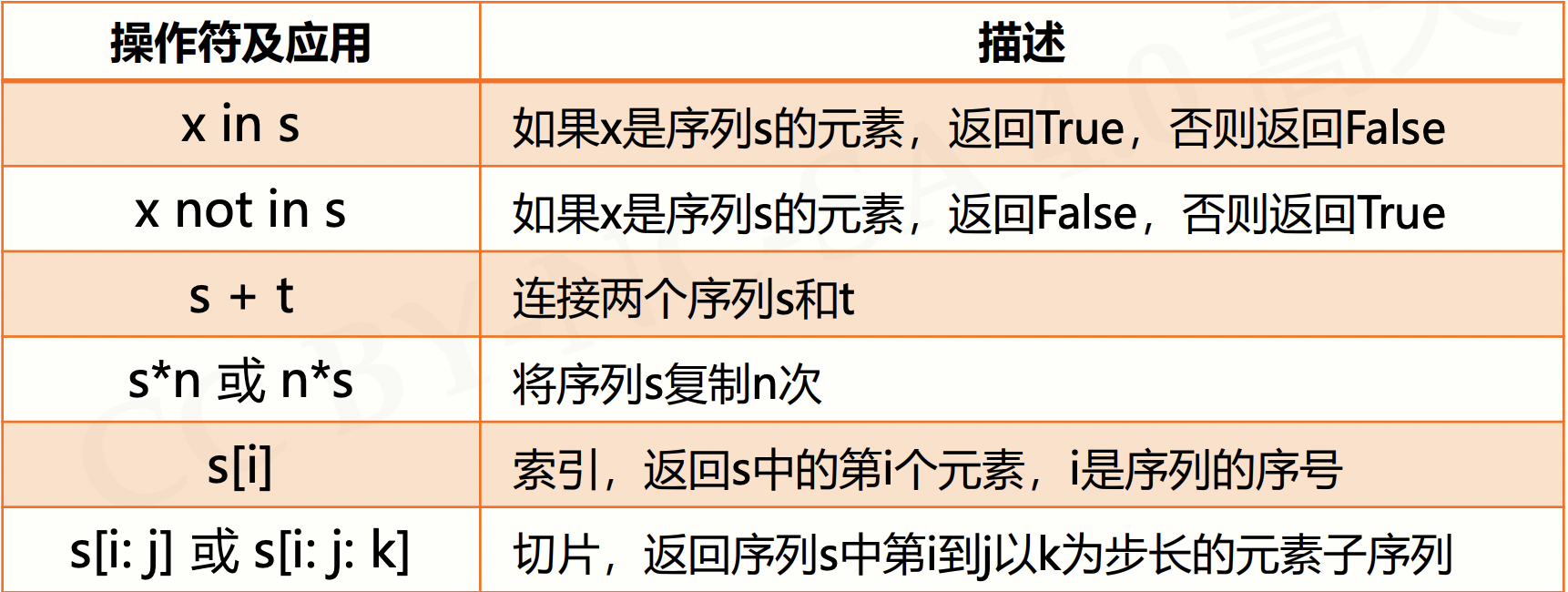
2.4.3 序列通用函数和方法

2.5 元组类型
元组是序列类型的一种扩展 。
- 使用小括号 () 或 tuple() 创建,元素间用逗号
,分隔 ,可以使用或不使用小括号。 - 元组之间是有序的(注意是元组之间前后顺序,并不是按照大小关系排序),因此元组中可以有重复元素,且元组不能修改。
- 元组继承了序列类型的全部通用操作,元组因为创建后不能修改,因此没有特殊操作,使用或不使用小括号。
creature = "cat","dog","tiger","human"
creature('cat', 'dog', 'tiger', 'human')
color = (0x001100, "blue", creature)
color(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
2.6 列表类型
2.6.1 列表定义
列表是序列类型的一种扩展,十分常用
- 列表是一种序列类型,创建后可以随意被修改 。
- 使用方括号 [] 或list() 创建,元素间用逗号 , 分隔 。
- 列表中各元素类型可以不同,且无长度限制。
ls = ["cat","dog","tiger", 1024] #创建列表ls
lt = ls #注意如果使用=进行赋值是不会创建新的列表的,赋值仅传递引用
2.6.2 列表的函数与方法


2.6 字典类型
2.6.1 字典类型的定义
字典类型是“映射”的体现,定义和用法类似C++中的unorder_map
- 键值对:键是数据索引的扩展
- 字典是键值对的集合,键值对之间无序
- 采用大括号{}和dict()创建,键值对用冒号: 表示,
{<键1>:<值1>, <键2>:<值2>, … , <键n>:<值n>} - 使用
[]进行索引和增加映射。
2.6.2 操作函数和方法


三、文件和数据格式化
3.1 文件的类型
文件是数据的抽象和集合,是存储在辅助存储器上的数据序列,是数据存储的一种形式,有两种展现形态:文本文件和二进制文件。
文本文件:
- 由单一特定编码组成的文件,如UTF-8编码
- 由于存在编码,也被看成是存储着的长字符串
- 适用于例如:.txt文件、.py文件等
二进制文件:
- 直接由比特0和1组成,没有统一字符编码
- 一般存在二进制0和1的组织结构,即文件格式
- 适用于例如:.png文件、.avi文件等
3.2 文件的打开和关闭
3.2.1 文件的打开
格式: <变量名> = open(<文件名>, <打开模式>)
- 变量名:又称作文件句柄,标识文件变量。
- 文件名:文件路径和名称,如果和代码是同目录则可以省略路径。注意文件路径要用
/或\\表示分层,如:”D:/PYE/f.txt”,”D:\PYE\f.txt”。 - 打开模式:

3.2.2 文件的关闭
格式:<变量名>.close()
3.3 文件内容的读取


3.4 数据的文件写入


注意:
fo = open("output.txt","w+")
ls = ["中国","法国","美国"]
fo.writelines(ls)
fo.seek(0) # 如果不加这一行则会没有输出,因为此时指针指向文件末尾,需要指回开头。
for line in fo:
print(line)
fo.close()
四、Turtle库
Turtle绘图体系于1969年诞生,主要用于程序设计入门,是Python语言的标准库之一,入门级的图形绘制函数库。之所以称为Turtle库,是因为此库中有一只假象的海龟(Turtle),全部的函数都是围绕这个海龟进行的。海龟一开始在窗体正中心,在画布上游走的轨迹形成了绘制的图形,可以通过函数改变海龟的行进路线,海龟的颜色和宽度等。
4.1 绘图窗体
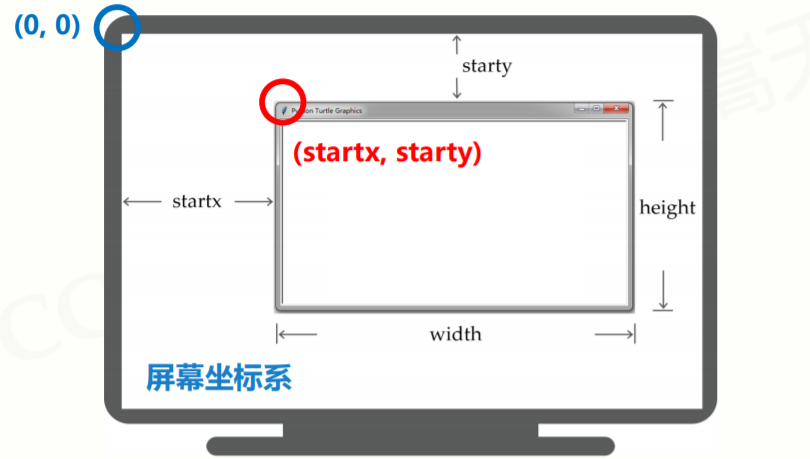
Turtle绘图体系的最小单位是像素,绘图窗体指程序运行时弹出的窗口,所有绘图的结果都在窗口内显示,可以用turtle.setup() 设置绘图窗体。
turtle.setup(width,height,startx,starty)
'''
前两个参数设置窗口大小,后两个窗口设置窗口相对于屏幕左上角的位置,后两个参数可以不写,setup函数不是必须使用的。
'''
4.2 空间坐标体系
4.2.1 绝对坐标
以屏幕中心为原点建立一个直角坐标系,相关函数有 turtle.goto(x,y) 表示控制海龟从当前位置沿直线移动到坐标为(x,y)的位置。
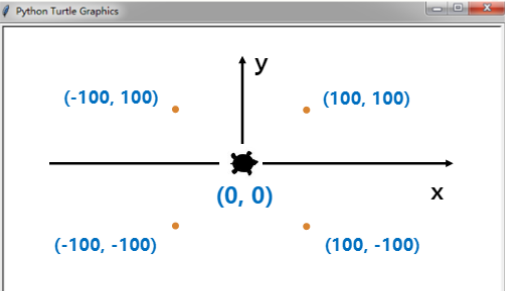
4.2.2 相对坐标(海龟坐标)
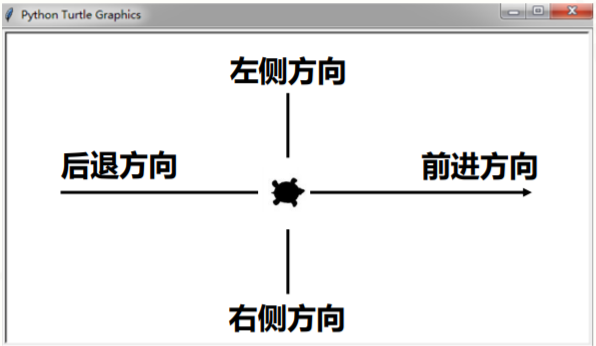
以海龟面朝的方向为基准,分为前后左右四个方向,相关函数入下:
turtle.circle(r,angle) #以距海龟右侧r的点为圆心,走一段角度为angle的弧
turtle.bk(d) #后退d
trutle.fd(d) #前进d
4.3 角度坐标体系
4.3.1 绝对角度
逆时针为正,顺时针为负,相关函数turtle.seth(angle) ,用于改变海龟面朝方向。
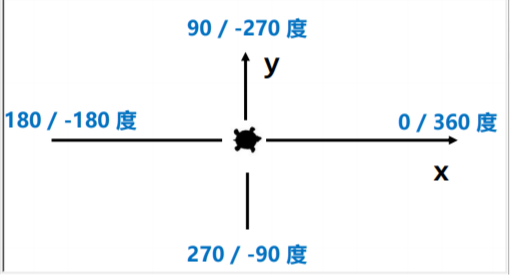
4.3.2 相对角度(海龟角度)
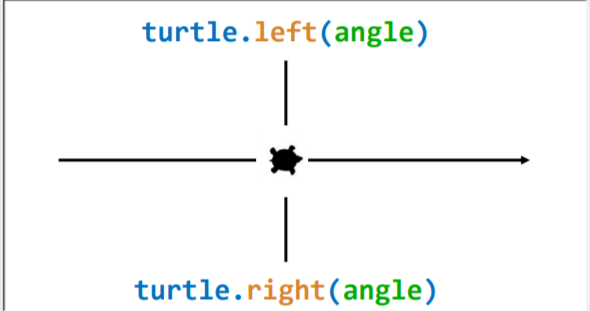
以海龟的朝向为基准分为左右,函数如图所示,分别表示向左和向右转angle度。
4.4 RGB色彩体系
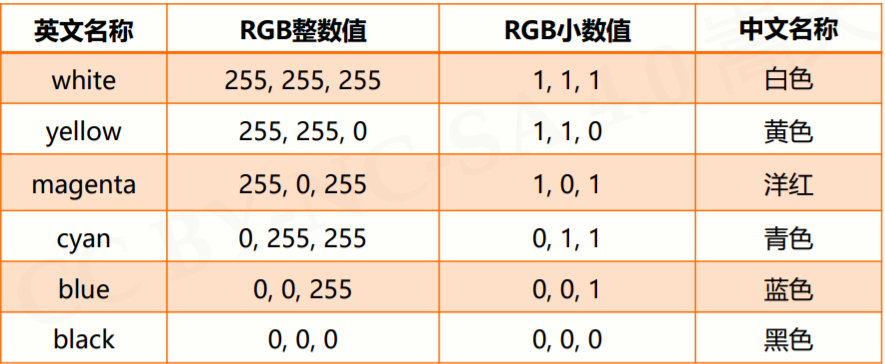
RGB指红蓝绿三个通道的颜色组合,可以覆盖视力所能感知的所有颜色,RGB每色取值范围0-255整数或0-1小数,Turtle库默认使用小数值表示RGB颜色,可以用turtle.colormode(mode),改变颜色表示模式,mode = 255表示整数模式,mode = 1.0 表示小数模式,常见的颜色如下所示:
4.5 画笔控制函数
turtle.penup() #别名 turtle.pu() 抬起画笔,海龟在飞行
turtle.pendown() #别名 turtle.pd() 落下画笔,海龟在爬行
turtle.pensize(width) #别名 turtle.width(width) 画笔宽度,海龟的腰围
turtle.pencolor(color) #color为颜色字符串或r,g,b值画笔颜色,海龟在涂装
'''
pencolor的参数可以有三种形式:
颜色字符串 :turtle.pencolor("purple")
RGB的小数值:turtle.pencolor(0.63, 0.13, 0.94)
RGB的元组值:turtle.pencolor((0.63,0.13,0.94))
'''
4.6 运动控制函数
# 别名 turtle.fd(d)向前行进,海龟走直线 d: 行进距离,可以为负数
turtle.forward(d)
#根据半径r绘制extent角度的弧形
#r: 默认圆心在海龟左侧r距离的位置,extent: 绘制角度,默认是360度整圆
turtle.circle(r, extent=None)
4.7 方向控制函数
turtle.setheading(angle) #别名 turtle.seth(angle) 改变行进方向(绝对方向)
turtle.left(angle) #海龟向左转,角度为相对角度
turtle.right(angle) #海龟向右转
4.8 字符绘制函数
turtle.write(arg,move=false,align='left',font=('arial',8,'normal'))
'''
arg:信息,将写入Turtle绘画屏幕。
move(可选):真/假。在默认情况下,move为false。如果move为true,则笔将移动到右下角。
align(可选):字符串对齐方式,“左(left)”、“中(center)”或“右(right)”之一。
font(可选):三个字体(fontname、fontsize、fonttype)。
'''
五、其他库库
5.1 Time库
time库是Python中处理时间的标准库,有以下几个功能:
- 计算机时间的表达
- 提供获取系统时间并格式化输出功能
- 提供系统级精确计时功能,用于程序性能分析
5.1.1 时间获取
time.time() #获取当前时间戳,即计算机内部时间值,浮点数
time.ctime() #获取当前时间并以易读方式表示,返回字符串
time.gmtime() #获取当前时间,表示为计算机可处理的时间格式
print(time.time()) #输出1627206277.5320847
print(time.ctime()) #输出 Sun Jul 25 17:43:40 2021
print(time.gmtime()) #输出 time.struct_time(tm_year=2021, tm_mon=7, tm_mday=25, tm_hour=9, tm_min=44, tm_sec=8, tm_wday=6, tm_yday=206, tm_isdst=0)
5.1.2 时间格式化
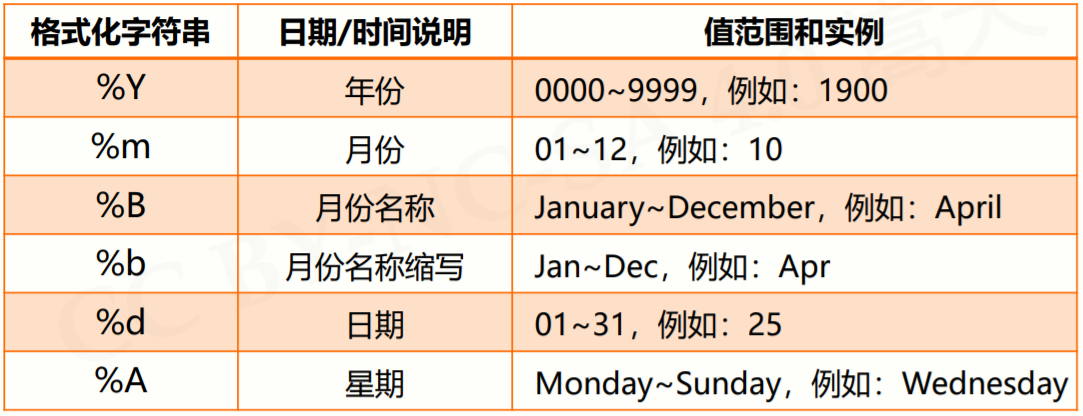
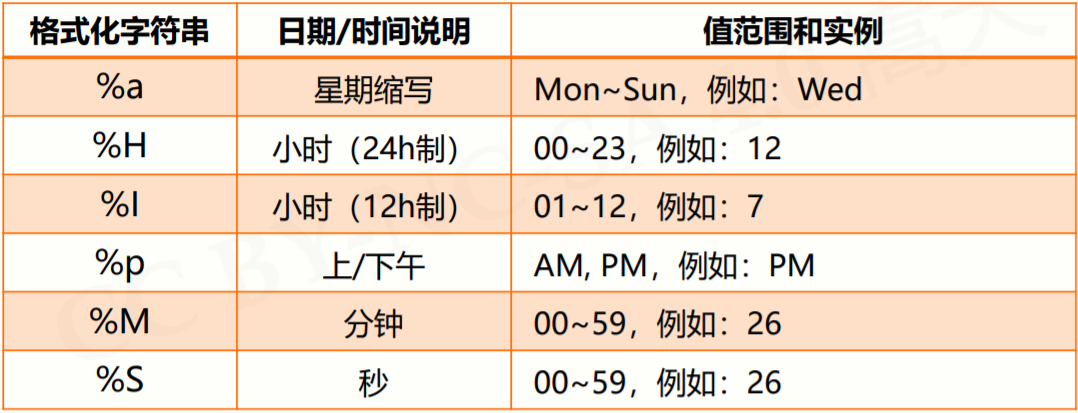
time.strftime(tpl, ts) 方法用于时间的格式化,格式化方式类似于字符串格式化,需要提供一个模板,其中 tpl 是格式化模板字符串,用来定义输出效果 ts是计算机内部时间类型变量。
格式化控制符:
# 例:
t = time.gmtime()
s = time.strftime("%Y-%m-%d %H:%M:%S", t)
print(s)
# 输出 2021-07-25 09:49:36
5.2 Random库
random库是Python的标准库之一,用于产生伪随机数,即采用梅森旋转算法生成随机序列。对于一个特定的随机数种子,经过梅森旋转算法将会生成一个固定的随机序列,即一个随机数种子决定一个随机序列。
5.2.1 基本随机数函数
random.seed(a = None) # 初始化随机数种子,默认为当前系统时间
random.random() #产生一个 [0.0,1.0) 之间的随机小数。
5.2.2 扩展随机数函数
randint(a, b) #生成一个[a, b]之间的整数
randrange(m, n[, k]) #生成一个[m, n)之间以k为步长的随机整数
getrandbits(k) #生成一个k比特长的随机整数
uniform(a, b) #生成一个[a, b]之间的随机小数
choice(seq) #从序列seq中随机选择一个元素
shuffle(seq) #将序列seq中元素随机排列,返回打乱后的序列
5.3 PyInstaller库
5.3.1 安装
PyInstaller库用于将.py源代码转换成无需源代码的可执行文件,是第三方库,需要自行安装,安装方法:
在命令行中输入pip install pyinstaller 回车即可,安装过程:
安装成功:

安装失败报错的可能解决方案:1. 使用管理员模式运行终端 。2. 如果开着梯子,关闭梯子后重试。
5.3.2 使用
pyinstaller -F <文件名.py> #将<文件名.py>打包生成一个可执行文件,生成位置为同一文件夹下
pyinstaller –i <图标名.ico> –F <文件名.py> #将<文件名.py>打包生成一个可执行文件,使用<图标名.ico>作为可执行文件的图标
其他一些参数:
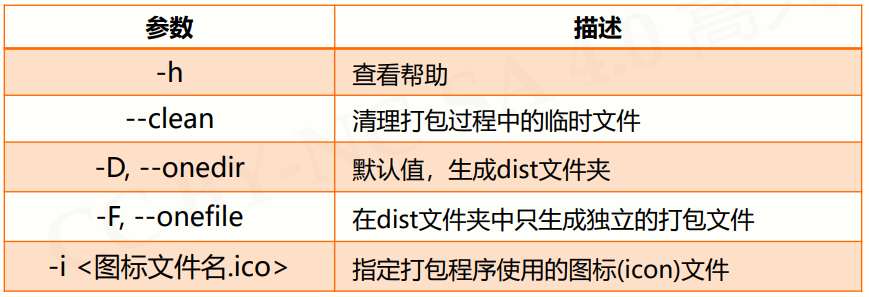
5.4 jieba库
5.4.1 概述
jieba是优秀的中文分词第三方库
- 中文文本需要通过分词获得单个的词语
- jieba是优秀的中文分词第三方库,需要额外安装
- jieba库提供三种分词模式,最简单只需掌握一个函数
jieba分词的原理:
- jieba分词依靠中文词库,利用一个中文词库,确定中文字符之间的关联概率。
- 中文字符间概率大的组成词组,形成分词结果。
- 除了分词,用户还可以添加自定义的词组
5.4.2 三种模式和函数
- 精确模式:把文本精确的切分开,不存在冗余单词。
- 全模式:把文本中所有可能的词语都扫描出来,有冗余。
- 搜索引擎模式:在精确模式基础上,对长词再次切分


