一、神经网络的代价函数
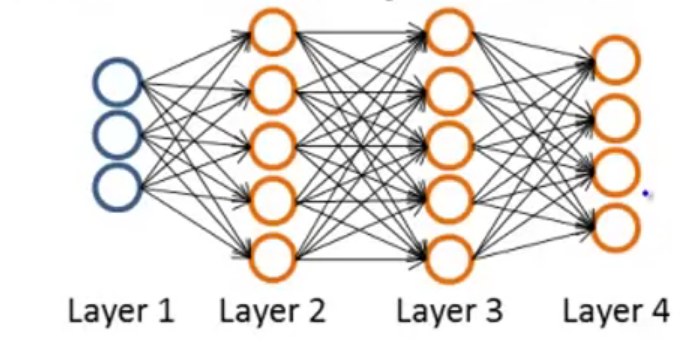
符号定义:
- 假设我们有训练集:
表示训练集中第 个数据的第 个属性值 - 设
表示神经网络的总层数,对于上图来说, - 设
表示第 层的神经元个数(不包括偏置单元),对于上图, - 对于一个
类的分类问题,神经网络模型的输出层就有 个单元,即 ,用一个列向量 表示输出的结果。
在Logistic回归中,代价函数为
所以对于神经网络,它的代价函数为:
一些说明:关于公式中的
二、反向传播算法(BP)
2.1 算法介绍
反向传播算法(Backpropagation Algorithm),又称为误差逆传播算法,使用这个算法,使得神经网络模型可以自主地计算出合适的模型参数
我们已知代价函数
2.2 前向传播
在模型最初的时候,要先进行一次前向传播(Forward propagation),以此获得每个节点的原始激活值。
假设我们只有一个训练样本
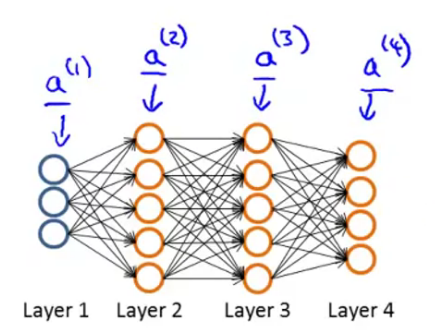
2.3 反向传播
在BP算法中我们首先要计算
由于 Sigmoid 函数有个很好的性质:
于是我们得到算法流程:
假设我们有训练集
-
先令所有的
,这里的 其实就是大写的 , 用于计算代价函数的偏导数 -
For
to 将
赋值成 使用前向传播从左向右逐层计算所有的
使用
计算 从右往左逐步计算
,或者写成向量化 -
最终我们可以得到:
,且
三、MATLAB编程实现
3.1 矩阵向量化
回忆前面的Logistic回归的实现方法,我们利用了一个MATLAB中内置的优化算法 fminunc 来实现自动计算梯度,函数参数如下:
function [jVal, gradient] = costFunction(theta)
optTheta = fminunc(@costFunction, initialTheta, options)
其中 @costFunction 是我们所实现的损失函数的指针,损失函数的输入为 jVa;l 以及梯度值gradient ,initialTheta 为初始的 options 为函数的可选项,这里用不到,返回的 optTheta 是进行梯度下降后的 gradient 都是一个一维的列向量,而在神经网络中,这些参数都是一个个矩阵,所以我们首先需要进行矩阵的展开。
假设我们有一个三层的神经网络模型,其中第一层神经元个数
在MATLAB中可以用 (:) 的方法将一个矩阵展开成一个向量,具体可以见:机器学习:MATLAB语法 2.2 操作数据
于是我们可以:
thetaVec = [Theta1(:); Theta2(:); Theta3(:)];
Dvec = [D1(:); D2(:); D3(:)];
分别将 thetaVec 中,并将 Dvec 中。
同时我们可以使用:
Theta1 = reshape(thetaVec(1:110), 10, 11);
Theta2 = reshape(thetaVec(111:220), 10, 11);
Theta3 = reshape(thetaVec(221:231), 1, 11);
将 thetaVec 中恢复回来,
那么整体的流程就变成下面这样了:
-
得到初始化后的参数值
-
将参数展开得到
initialTheta -
运行函数
fminunc(@costFunction, initialTheta, options)进行梯度下降对于
function [jVal, gradientVec] = costFunction(thetaVec):- 从
thetaVec中使用reshape提取出 - 使用前向传播和反向传播算法计算
和 - 将
展开成向量存入 gradientVec
- 从
3.2 梯度检验
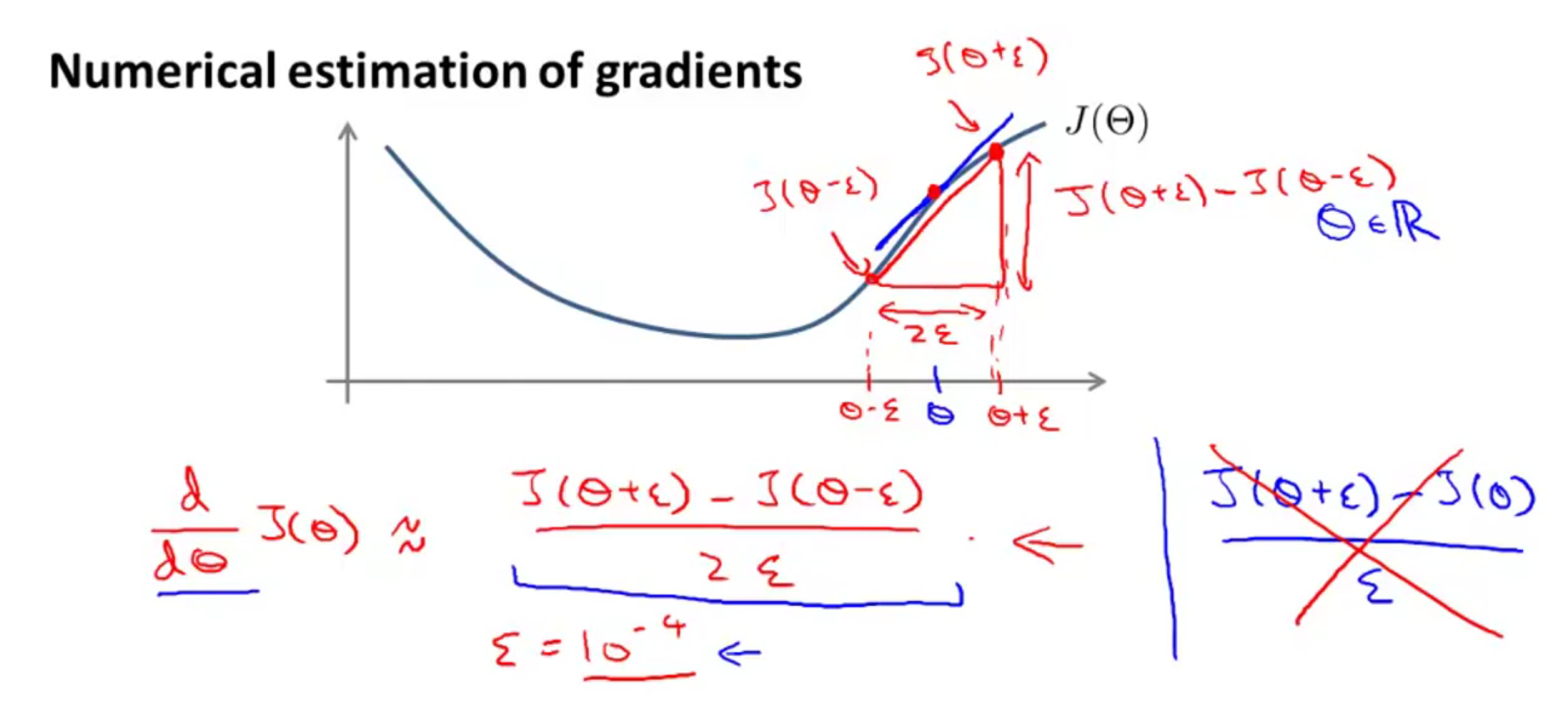
有时候可能由于一些玄学问题导致梯度计算错误,但是你却很难发现,这里介绍了一种检测方法:
如上图所示,假设我们的
由于神经网络的

对应的代码如下:
epsilon = 1e-4;
for i = 1:n,
thetaPlus = theta;
thetaPlus(i) += epsilon;
thetaMinus = theta;
thetaMinus(i) -= epsilon;
gradApprox(i) = (J(thetaPlus) - J(thetaMinus))/(2*epsilon)
end;
然后将计算得到的 gradApprox 与反向传播得到的梯度值 gradientVec 逐一比较,如果误差不大则说明没错。
需要注意的是,梯度检测步骤只在模型训练开始前进行一次,开始训练模型后就不用检测了,不然会很慢。
3.3 随机初始化
在线性回归中我们可以将参数初始为0,但是在神经网络中不行,因为如果初始化为0,则最后无论如何进行,最终的参数都是相同的,所以我们需要用一种更加科学的方式进行参数初始化,代码如下:
If the dimensions of Theta1 is 10x11, Theta2 is 10x11 and Theta3 is 1x11.
Theta1 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta2 = rand(10,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
Theta3 = rand(1,11) * (2 * INIT_EPSILON) - INIT_EPSILON;
其中 INIT_EPSILON 为自己设置的值。
3.4 其他注意点
- 神经网络的输入层和输出层神经元个数取决于数据的属性个数以及分类个数
- 一般来说,神经网络设置为三层,如果大于三层,则中间的隐藏层的神经元个数都一样多,如果不考虑计算复杂度的问题,神经元个数越多越好,一般比输入的特征数目稍大一点。
3.6 总结流程
- 随机初始化参数
- 实现前向传播算法,对于所有的
计算得到 - 实现代价函数
- 实现反向传播算法,计算偏导数
- 进行梯度检验(只在一开的时候进行一次)
- 使用梯度下降或者其他高级的优化算法来更新参数以最小化代价函数

评论