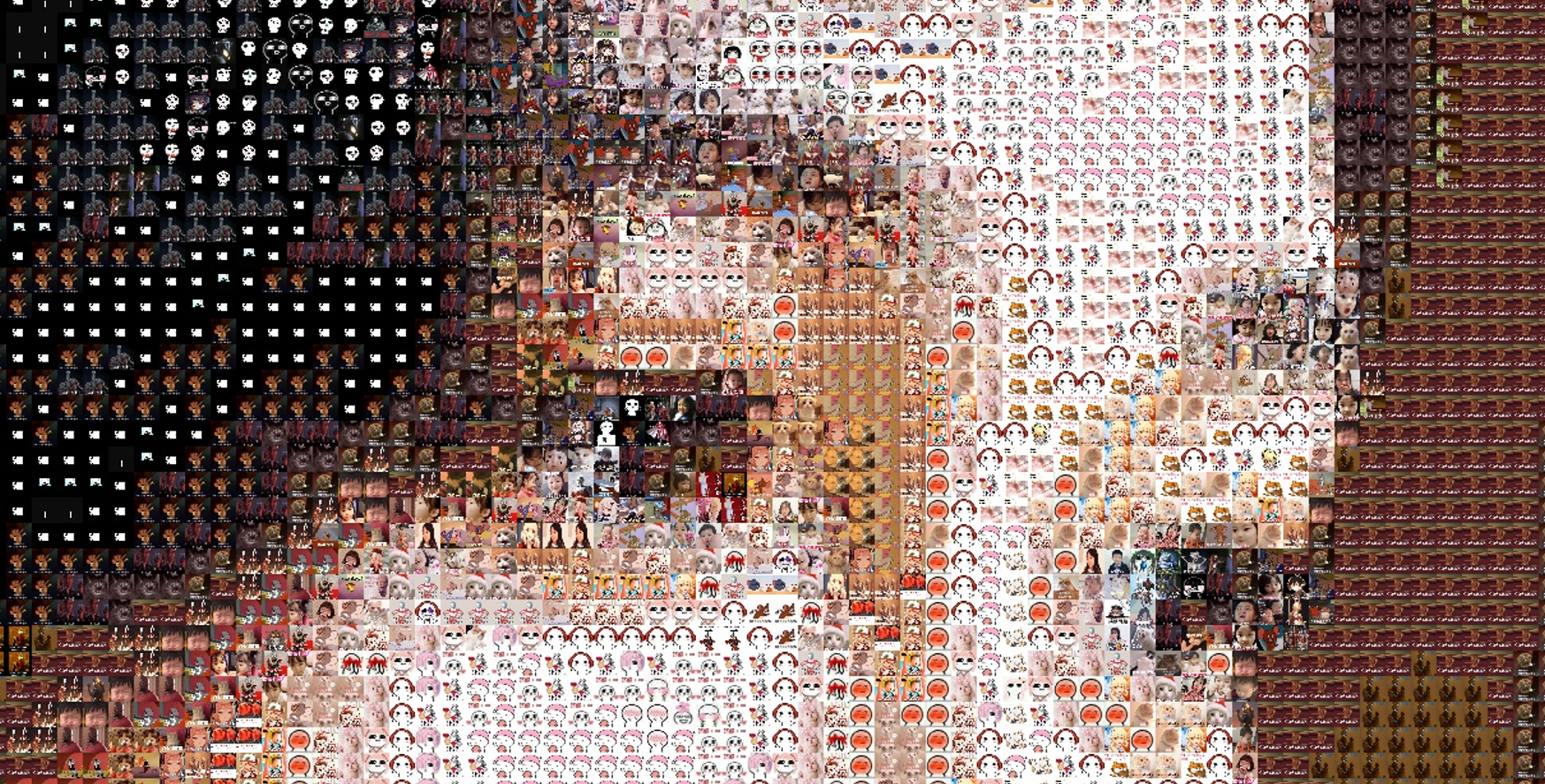一、前言
前段时间准备情人节礼物,想到了能不能用过去所有的照片作为像素点,合成为一张合照。但是,我也没有处理这方面问题的经验,于是上网查找,果然找到了一个相关的代码(原网址实在找不到了,就不贴了)。花了一晚上的时间研究学习,最终实现了合成照片的功能,并学习了很多以前没有接触过的Python库,加以记录。
二、基础知识
在讲解代码思路之前,先记录一下一些库的用法,以便以后的查阅。
2.1 argparse库
argparse是python的命令行解析的标准模块,内置于python,不需要安装。这个库可以让我们直接在命令行中就可以向程序中传入参数并让程序运行。它的基本使用流程如下:
import argparse # 导入包
parser = argparse.ArgumentParser() # 创建对象
parser.add_argument() # 添加参数
args = parser.parse_args() # 解析添加的参数
print(args) #获得传入的参数
2.1.1 argparse.ArgumentParser()方法
这个函数用于新建一个 ArgumentParser 对象,创建时可以给对象添加描述信息:
argparse.ArgumentParser(description="输入命令行参数的名称")
# 也可以简写成:
argparse.ArgumentParser("输入命令行参数的名称")
2.1.2 add_argument() 方法
此方法用于添加命令行参数,基础写法为:
parser = argparse.ArgumentParser() # 创建对象
parser.add_argument("i", type=int, help="位置参数")
parser.add_argument("-a",type=int, default=3, help="可选参数")
其中第一个参数表示添加的参数的名称,第二个表示参数类型,help为提示信息,default表示参数默认值,注意只有参数为可选参数时有效。
位置参数:在命令行中传入参数时候,位置参数得到的值与传入的参数的先后顺序有关,比如:
parser = argparse.ArgumentParser("测试")
parser.add_argument("x", type=int, help="位置参数")
parser.add_argument("y", type=int, help="位置参数")
args = parser.parse_args()
print("x = " + str(args.x))
print("y = " + str(args.y))
该代码存放在文件路径:Python/2.py 下,在命令行输入python Python/2.py 2 3,得到结果:
x = 2
y = 3
在命令行输入python Python/2.py 3 2,得到结果:
x = 3
y = 2
可以看出,对于位置参数x和y,由于先添加x参数,再添加y参数,所以在命令行中,也是对应得先将第一个值赋给x再将第二个值赋给y,且位置参数必须赋值,否则将会报错:
# 命令行输入:
python Python/2.py
# 输出:
usage: 测试 [-h] [--z Z] x y
测试: error: the following arguments are required: x, y
可选参数:如果参数很多,使用位置参数很容易出错,那么就可以用可选参数,可以指定改变哪个变量的值,也可以不进行赋值,使用默认值,和位置参数的区别就是名称前需要加--,如下所示:
parser = argparse.ArgumentParser("测试")
parser.add_argument("--z", type=int, default=3, help="可选参数")
args = parser.parse_args()
print("z = " + str(args.z))
在命令行中输入python Python/2.py --z 5,得到:
z = 5
在命令行中输入python Python/2.py,得到:
z = 3
所以,可选参数不是必须赋值的。
对于help参数,可以使用 -h 进行查看参数的描述信息,使用如下代码:
parser = argparse.ArgumentParser("测试")
parser.add_argument("x", type=int, help="位置参数")
parser.add_argument("y", type=int, help="位置参数")
parser.add_argument("--z", type=int, default=3, help="可选参数")
args = parser.parse_args()
在命令行输入python Python/2.py -h,得到:
usage: 测试 [-h] [--z Z] x y
positional arguments:
x 位置参数
y 位置参数
optional arguments:
-h, --help show this help message and exit
--z Z 可选参数
参考资料
2.2 tqdm库
tqdm模块是python进度条库, 主要分为两种运行模式:
- 基于迭代对象运行: tqdm(iterator)
- 手动进行更新
这里只介绍基于迭代器的运行模式:
import time
from tqdm import tqdm, trange
#trange(i)是tqdm(range(i))的一种简单写法
for i in trange(100):
time.sleep(0.05)
运行效果:
100%|██████████| 100/100 [00:06<00:00, 16.04it/s]
import time
from tqdm import tqdm, trange
for i in tqdm(range(100), desc='Processing'):
time.sleep(0.05)
运行效果:
Processing: 100%|██████████| 100/100 [00:06<00:00, 16.05it/s]
import time
from tqdm import tqdm, trange
dic = ['a', 'b', 'c', 'd', 'e']
pbar = tqdm(dic)
for i in pbar:
pbar.set_description('Processing '+i)
time.sleep(0.2)
运行效果:
Processing e: 100%|██████████| 5/5 [00:01<00:00, 4.69it/s]
参考资料:
2.3 itertools.product 用法
itertools模块实现一系列 iterator ,这些迭代器受到APL,Haskell和SML的启发。为了适用于Python,它们都被重新写过。itertools模块标准化了一个快速、高效利用内存的核心工具集,这些工具本身或组合都很有用。它们一起形成了“迭代器代数”,这使得在纯Python中有可能创建简洁又高效的专用工具。(来源)
我们这里只介绍其中的product方法,此方法的作用就是求笛卡尔积,其实相当于嵌套的for循环,但是会比嵌套的for循环快。
for i in product("ABC", "DEF", repeat=1):
print(i)
运行结果:
('A', 'D')
('A', 'E')
('A', 'F')
('B', 'D')
('B', 'E')
('B', 'F')
('C', 'D')
('C', 'E')
('C', 'F')
其中repeat表示重复几次,默认repeat=1,运行下面的代码:
for i in product("AB", "DE", repeat=2):
print(i)
得到:
('A', 'D', 'A', 'D')
('A', 'D', 'A', 'E')
('A', 'D', 'B', 'D')
('A', 'D', 'B', 'E')
('A', 'E', 'A', 'D')
('A', 'E', 'A', 'E')
('A', 'E', 'B', 'D')
('A', 'E', 'B', 'E')
('B', 'D', 'A', 'D')
('B', 'D', 'A', 'E')
('B', 'D', 'B', 'D')
('B', 'D', 'B', 'E')
('B', 'E', 'A', 'D')
('B', 'E', 'A', 'E')
('B', 'E', 'B', 'D')
('B', 'E', 'B', 'E')
如果要当做嵌套的for循环使用,可以如下:
for i, j, k in product([1,2], [3,4], [5,6], repeat=1):
# 对i j k进行操作...比如输出
print("i = {}, j = {}, k = {}".format(i, j, k))
输出结果:
i = 1, j = 3, k = 5
i = 1, j = 3, k = 6
i = 1, j = 4, k = 5
i = 1, j = 4, k = 6
i = 2, j = 3, k = 5
i = 2, j = 3, k = 6
i = 2, j = 4, k = 5
i = 2, j = 4, k = 6
2.4 numpy的一些操作
2.4.1 axis参数的理解
- Axis就是数组层级
- 设axis= i ,则numpy沿着第 i 个下标变化的方向进行操作
axis=0,表示指向的是数组的第一层,axis=i表示指向的是数组的第i层,也可以理解成维度。在很多函数中,都可以指定axis参数,这表示接下来的运算是沿着axis这一层进行的,比如:
a = np.array(
[[1,2,3,4],
[5,6,7,8],
[9,9,9,9]])
print(np.sum(a, axis=0))
print(np.sum(a, axis=1))
结果为:
[15 17 19 21]
[10 26 36]
可见,当axis=0时,其实可以看成新建了一个array,并将a[i] = a[0][i]+a[1][i]+a[2][i]
而当axis=1时,其实可以看成新建了一个array,并将a[i] = a[i][0]+a[i][1]+a[i][2]
同理可得,假设有一个四维数组,其大小为3 * 4 * 2 * 6
那么如果执行np.sum(a, axis = 2),那么就可以看成新建一个array,大小为3 * 4 * 6,其中a[i][j][k] = a[i][j][0][k]+a[i][j][1][k]。
参考资料:Numpy:对Axis的理解
2.4.2 argmax函数
argmax用于返回传入数组的最大数的索引,如:
import numpy as np
a = np.array([3, 1, 2, 4, 6, 1])
print(np.argmax(a))
输出为4,即最大数6的下标。
argmax函数也有参数axis,默认为0,可以类比sum,就是将加法换成了取max操作。
2.4.3 numpy.linalg.norm函数
numpy.linalg.norm 函数用来计算矩阵的范数,可以输入一个 vector,也可以输入一个matrix,基本用法如下:
x_norm=np.linalg.norm(x, ord=None, axis=None, keepdims=False)
- x: 表示矩阵(也可以是一维)
-
ord:范数类型
| 参数 | 说明 | 计算方法 |
|---|---|---|
| 默认 | 二范数: |
|
| ord=2 | 二范数: |
同上 |
| ord=1 | 一范数: |
|
| ord=np.inf | 无穷范数: |
|
>>> x = np.array([3, 4])
>>> np.linalg.norm(x)
5.
>>> np.linalg.norm(x, ord=2)
5.
>>> np.linalg.norm(x, ord=1)
7.
>>> np.linalg.norm(x, ord=np.inf)
4
- axis表示在哪一维度上进行范数的计算。
- keepdims表示是否保持维度不变,特殊需求时才会使用。
参考资料:
2.5 golb库
glob模块可以使用Unix shell风格的通配符匹配符合特定格式的文件和文件夹,跟windows的文件搜索功能差不多。glob模块并非调用一个子shell实现搜索功能,而是在内部调用了os.listdir()和fnmatch.fnmatch()。glob模块共包含以下3个函数:
- glob(pathname, recursive=False)
- iglob(pathname, recursive=False)
- escape(pathname)
这里我们只介绍 glob函数,此函数的第一个参数pathname为需要匹配的字符串。第二个参数代表递归调用,与特殊通配符“**”一同使用,默认为False。该函数返回一个符合条件的路径的字符串列表,如果使用的是Windows系统,路径上的“\”符号会自动加上转义符号变为“\”(方便使用)。
glob模块支持的通配符:
| 通配符 | 功能 |
|---|---|
| * | 匹配0或多个字符 |
| ** | 匹配所有文件、目录、子目录和子目录里的文件(3.5版本新增) |
| ? | 匹配1个字符,与正则表达式里的?不同 |
| [exp] | 匹配指定范围内的字符,如:[1-9]匹配1至9范围内的字符 |
| [!exp] | 匹配不在指定范围内的字符 |
参考资料:[Python模块学习] glob模块
三、实现思路
选取图片库中的图片将它们拼接成一张图片,主要就是三个步骤:读取图片、选取图片、拼接并输出图片。
- 读取图片:
这一步骤很简单,先用glob库获取文件夹内所有图片的路径,然后用OpenCV库逐一读取即可。
-
选取图片:
- 这一步是实现整个代码的核心。拼接图片的本质就是将图片库中的某张图片替换目标图片的某一小块区域,然后组成一张大的图片,那么如何衡量选取哪张图片放在目标图片的哪个位置呢?主要就取决于图片的RGB颜色。
-
所有我们先对图片库中的图片进行预处理,计算出图片的平均RGB颜色,即将所有像素的RGB分别相加,最后除以整张图片的像素个数,得到该图片的平均R、平均G和拼接B的值,用这个值来代表这张图片的颜色状况。
- 假如一张图片库中的图片占用目标图片中
20*20像素的面积,则我们将整个目标图片分割成20*20的区域,然后遍历每个区域,分别计算每个区域的平均RGB颜色。 - 对于遍历过程中的某个区域,我们计算出该区域的平均RGB颜色后,与图片库的RGB颜色进行相减(使用numpy进行矩阵运算),得到一个
n*3的矩阵,其中n表示图片库中图片的数量,3表示3个代表RGB颜色的数,然后把每个RGB当做一个3维向量,计算该向量的长度(使用numpy.linalg.norm函数),向量长度最小的就是最优的图片(使用argmin函数)
-
拼接输出:图片的本质就是一堆的RGB数字,直接用从图片库选取的图片替换目标图片对应的区域,然后用OpenCV库输出即可。
四、代码
import cv2 # 计算机视觉相关包
import glob # 文件管理包
import argparse # 命令行包
import numpy as np
from tqdm import tqdm # 进度条工具库
from itertools import product # 迭代器工具
# 图片文件
def parseArgs():
parser = argparse.ArgumentParser('拼接马赛克图片')
parser.add_argument("--targetpath", type=str, default='template/3.jpg', help="目标图像路径") # 插入命令行可选参数,分别为参数名称、类型、缺省值、提示信息
parser.add_argument("--outputpath", type=str, default='output.jpg', help="输出图像路径")
parser.add_argument("--sourcepath", type=str, default='sourceimages', help="原图像路径")
parser.add_argument("--blocksize", type=int, default=20, help="每张图片占像素的大小")
args = parser.parse_args() # 获取命令行对象
return args
# 读取所有原图片并计算对应颜色的平均值
def readSourceImages(sourcepath, blocksize):
print("开始读取图像")
# 获取合法图像
sourceimages = []
# 平均颜色列表
avgcolors = []
for path in tqdm(glob.glob('{}/*.jpg'.format(sourcepath))): # glob.glob匹配文件名
image = cv2.imread(path, cv2.IMREAD_COLOR)
'''
cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道,可用1作为实参替代
cv2.IMREAD_GRAYSCALE:读入灰度图片,可用0作为实参替代
cv2.IMREAD_UNCHANGED:顾名思义,读入完整图片,包括alpha通道,可用-1作为实参替代
PS:alpha通道,又称A通道,是一个8位的灰度通道,该通道用256级灰度来记录图像中的透明度复信息,定义透明、不透明和半透明区域,其中黑表示全透明,白表示不透明,灰表示半透明
'''
if image.shape[-1] != 3: # 读取image数组最后一维的长度,不为3说明包含Alpha通道,为了图片格式统一,舍去
continue
image = cv2.resize(image, (blocksize, blocksize)) # 缩小图片大小
avgcolor = np.sum(np.sum(image, axis=0), axis=0) / (blocksize * blocksize) # 计算图片平均RGB值
sourceimages.append(image)
avgcolors.append(avgcolor)
print("结束读取图像")
return sourceimages, np.array(avgcolors)
def main(args):
targetimage = cv2.imread(args.targetpath) # 获取目标图像
outputimage = np.zeros(targetimage.shape, np.uint8) # 建立一个和目标图像一样大的空图
sourceimages, avgcolors = readSourceImages(args.sourcepath, args.blocksize) # 获取原图片
print("开始制作")
for i, j in tqdm(product(range(int(targetimage.shape[1]/args.blocksize)), range(int(targetimage.shape[0]/args.blocksize)))): # 遍历
block = targetimage[i * args.blocksize: (i + 1) * args.blocksize, j * args.blocksize : (j + 1) * args.blocksize, : ]
avgcolor = np.sum(np.sum(block, axis=0), axis=0) / (args.blocksize * args.blocksize) # 目标图像某个区块的平均颜色值 1*3
distances = np.linalg.norm(avgcolors - avgcolor, axis=1) # axis=1, 等价于求RGB向量的长度,可以用于代表这个向量的特征值
idx = np.argmin(distances) # 找到特征值最小的,就是最接近的,替换即可
outputimage[i*args.blocksize : (i+1) * args.blocksize, j * args.blocksize : (j+1) * args.blocksize, :] = sourceimages[idx]
cv2.imwrite(args.outputpath, outputimage)
cv2.imshow('result', outputimage)
print("制作完成")
main(parseArgs())
可以直接从github下载:传送门
五、效果展示
原图 5722×3820:

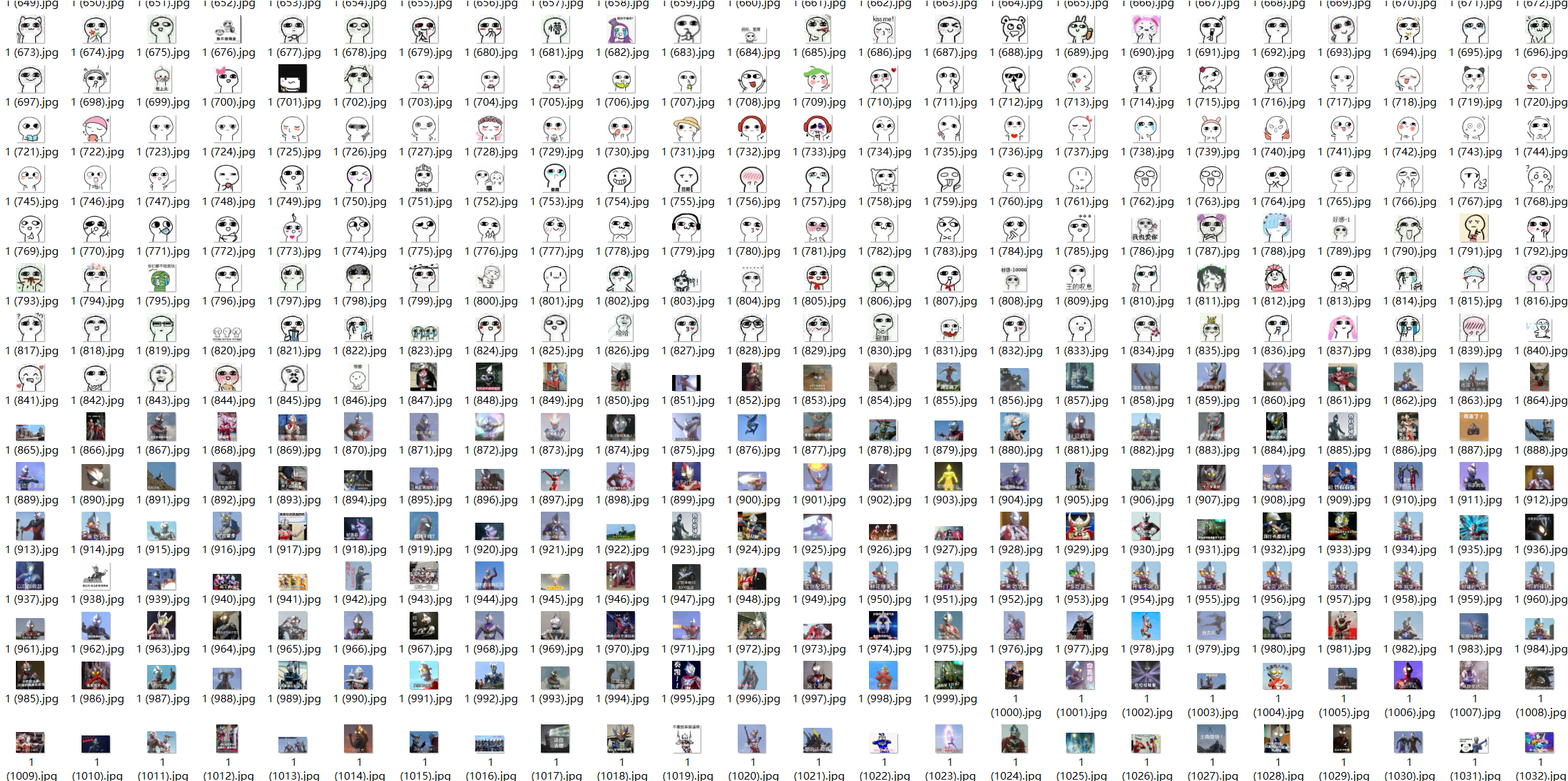
使用的图片库:
素材来自github上的表情包库:ChineseBQB
注意需要将图片都转为JPG格式,可以使用格式工厂批量处理。一共选取约2000张图片,部分图片如下:
输出效果

密恐高能预警!!!
放大的细节: