前言:本文为学习 PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】时记录的 Jupyter 笔记,部分截图来自视频中的课件。
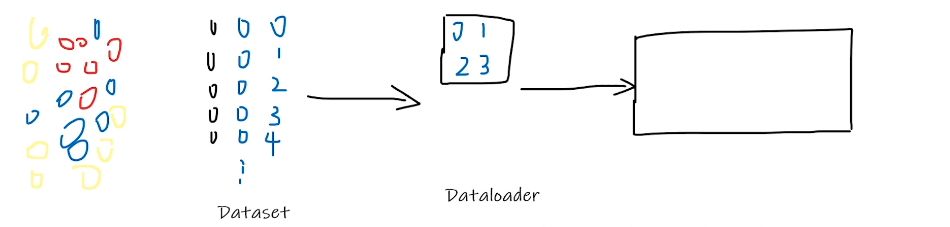
数据:一堆杂乱是数据,是个垃圾堆
Dataset:提供一种方式去获取数据及其 label ,即在垃圾堆里寻宝,如何获取每个数据及其label,告诉我们总共有多少个数据。
Dataloader: 为网络提供不同的数据形式。
from torch.utils.data import Dataset
help(Dataset)
Help on class Dataset in module torch.utils.data.dataset:
class Dataset(typing.Generic)
| An abstract class representing a :class:`Dataset`.
|
| All datasets that represent a map from keys to data samples should subclass
| it. All subclasses should overwrite :meth:`__getitem__`, supporting fetching a
| data sample for a given key. Subclasses could also optionally overwrite
| :meth:`__len__`, which is expected to return the size of the dataset by many
| :class:`~torch.utils.data.Sampler` implementations and the default options
| of :class:`~torch.utils.data.DataLoader`.
|
| .. note::
| :class:`~torch.utils.data.DataLoader` by default constructs a index
| sampler that yields integral indices. To make it work with a map-style
| dataset with non-integral indices/keys, a custom sampler must be provided.
|
| Method resolution order:
| Dataset
| typing.Generic
| builtins.object
|
| Methods defined here:
|
| __add__(self, other: 'Dataset[T_co]') -> 'ConcatDataset[T_co]'
|
| __getitem__(self, index) -> +T_co
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| __orig_bases__ = (typing.Generic[+T_co],)
|
| __parameters__ = (+T_co,)
|
| ----------------------------------------------------------------------
| Class methods inherited from typing.Generic:
|
| __class_getitem__(params) from builtins.type
|
| __init_subclass__(*args, **kwargs) from builtins.type
| This method is called when a class is subclassed.
|
| The default implementation does nothing. It may be
| overridden to extend subclasses.
从上面的帮助文档可以看出,Dataset是一个抽象类,继承Dataset类后必须重写__getitem__方法,其他可选重写的方法有len等。
__gettiem__方法用于通过下标(idx)获取一个样本数据
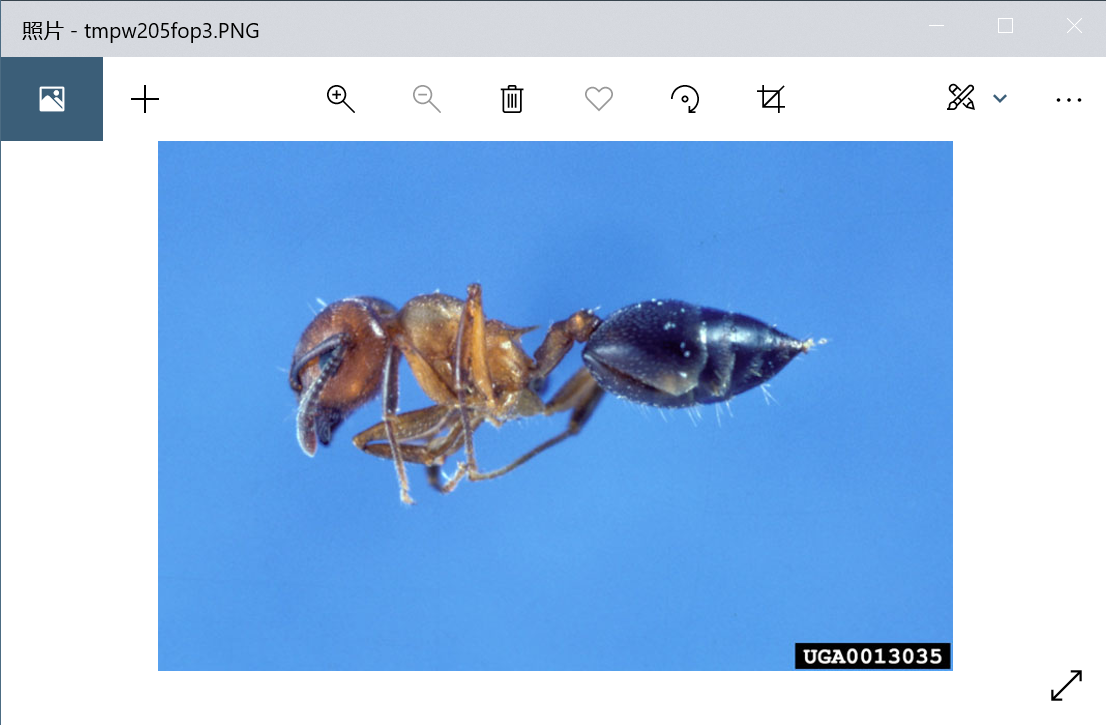
这里采用的是蜜蜂蚂蚁数据集为例,数据集下载链接: https://pan.baidu.com/s/1jZoTmoFzaTLWh4lKBHVbEA 密码: 5suq
# 载入图片数据
from PIL import Image
img_path = "D:/work/StudyCode/jupyter/dataset_for_pytorch_dataloading/train/ants/0013035.jpg"
img = Image.open(img_path)
img.show()
主要用到os库的两个方法:
os.listdir(filepath):遍历 filepath 下的所有文件,将文件名以列表的形式返回os.path.join(a,b):将路径a和b拼接起来,此函数的好处是可以根据不同的操作系统的路径分隔符自动拼接路径
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)

