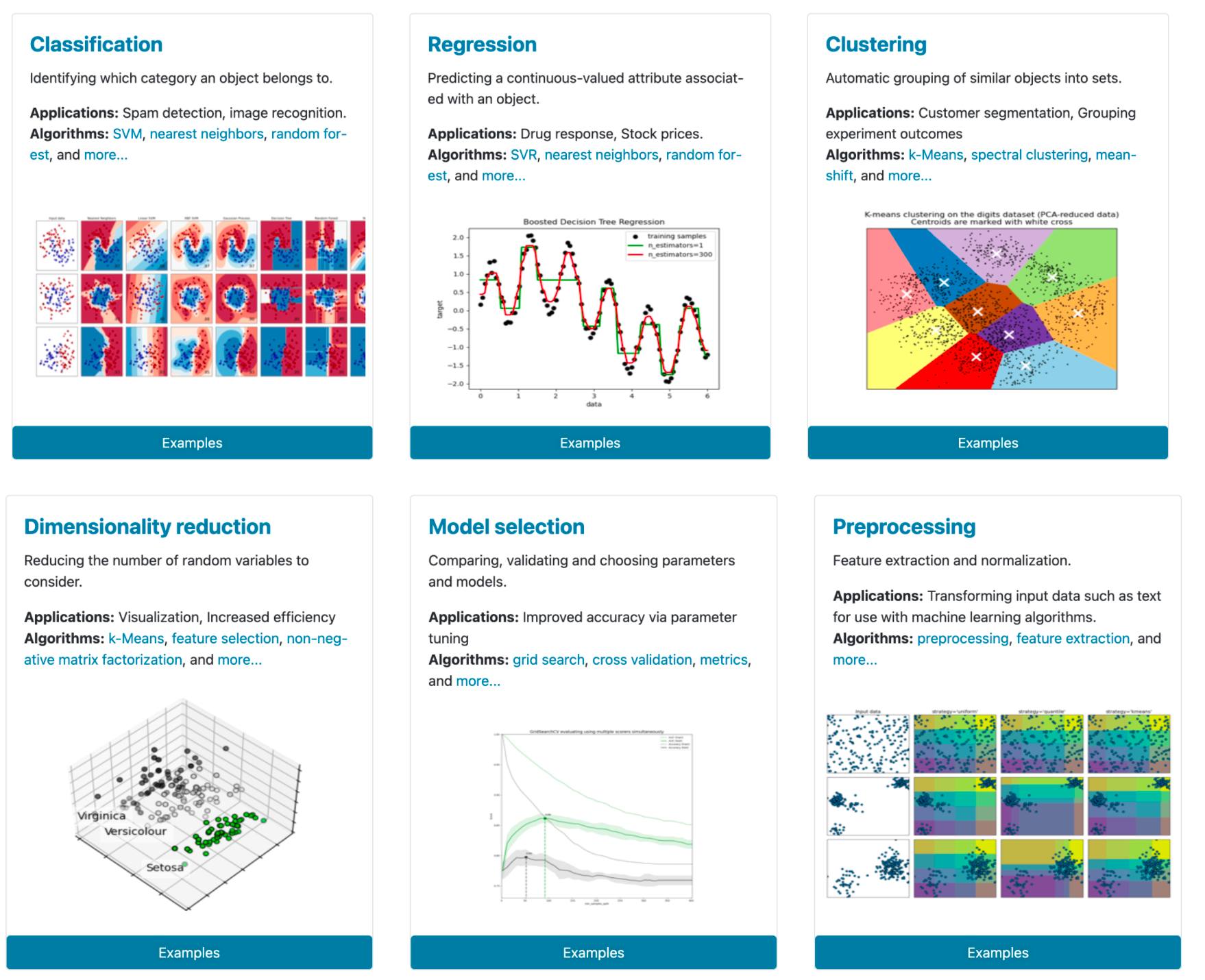
1. 概述
Scikit-learn是基于NumPy、 SciPy和 Matplotlib的开源Python机器学习包,它封装了一系列数据预处理、机器学习算法、模型选择等工具,是数据分析师首选的机器学习工具包。自2007年发布以来,scikit-learn已经成为Python重要的机器学习库了,scikit-learn简称sklearn,在 Sklearn 里面有六大任务模块:分别是分类、回归、聚类、降维、模型选择和预处理,此外还有一个数据引入模块。
2. sklearn的安装
Scikit-learn 所需的依赖项:
- Python (>= 3.5),
- NumPy (>= 1.11.0),
- SciPy (>= 0.17.0),
- joblib (>= 0.11).
Tips:Scikit-learn绘图功能,需要Matplotlib(>= 1.5.1)。一些scikit-learn示例可能需要一个或多个额外依赖项:scikit-image(>= 0.12.3)、panda(>= 0.18.0)
如果电脑环境中已有合适的 numpy 和 scipy版本,安装 scikit-learn 最简单的方法是使用 pip
pip install -U scikit-learn
如果没有任何合适的依赖项,强烈建议使用 conda 安装。
conda install scikit-learn
当然也可以使用anaconda的交互界面进行安装。
升级 scikit-learn:
conda update scikit-learn
卸载 scikit-learn:
conda remove scikit-learn
3. 数据引入
sklearn的datasets中提供一些训练数据,我们可以使用这些数据来进行分类或者回归等等。其中包含以下几种获取数据的方式:
- 获取小数据集(本地加载):
datasets.load_xxx( ) - 获取大数据集(在线下载):
datasets.fetch_xxx( ) - 本地生成数据集(本地构造):
datasets.make_xxx( )
| 数据集 | 介绍 |
|---|---|
| load_iris( ) | 鸢尾花数据集:3类、4个特征、150个样本 |
| load_boston( ) | 波斯顿房价数据集:13个特征、506个样本 |
| load_digits( ) | 手写数字集:10类、64个特征、1797个样本 |
| load_breast_cancer( ) | 乳腺癌数据集:2类、30个特征、569个样本 |
| load_diabets( ) | 糖尿病数据集:10个特征、442个样本 |
| load_wine( ) | 红酒数据集:3类、13个特征、178个样本 |
| load_files( ) | 加载自定义的文本分类数据集 |
| load_linnerud( ) | 体能训练数据集:3个特征、20个样本 |
| load_sample_image( ) | 加载单个图像样本,只有'china'和'flower'两张图片 |
| load_svmlight_file( ) | 加载svmlight格式的数据 |
| make_blobs( ) | 生成多类单标签数据集 |
| make_biclusters( ) | 生成双聚类数据集 |
| make_checkerboard( ) | 生成棋盘结构数组,进行双聚类 |
| make_circles( ) | 生成二维二元分类数据集 |
| make_classification( ) | 生成多类单标签数据集 |
| make_friedman1( ) | 生成采用了多项式和正弦变换的数据集 |
| make_gaussian_quantiles( ) | 生成高斯分布数据集 |
| make_hastie_10_2( ) | 生成10维度的二元分类数据集 |
| make_low_rank_matrix( ) | 生成具有钟形奇异值的低阶矩阵 |
| make_moons( ) | 生成二维二元分类数据集 |
| make_multilabel_classification( ) | 生成多类多标签数据集 |
| make_regression( ) | 生成回归任务的数据集 |
| make_s_curve( ) | 生成S型曲线数据集 |
| make_sparse_coded_signal( ) | 生成信号作为字典元素的稀疏组合 |
| make_sparse_spd_matrix( ) | 生成稀疏堆成的正定矩阵 |
| make_sparse_uncorrelated( ) | 使用稀疏的不相关设计生成随机回归问题 |
| make_spd_matrix( ) | 生成随机堆成的正定矩阵 |
| make_swiss_roll( ) | 生成瑞士卷曲线数据集 |
from sklearn import datasets
import matplotlib.pyplot as plt
# 鸢尾花数据演示
iris = datasets.load_iris()
features = iris.data
target = iris.target
print(features.shape,target.shape)
print(iris.feature_names)
# 手写数字图片演示
digits = datasets.load_digits()
print(digits.data.shape)
plt.gray()
plt.imshow(digits.images[2])
plt.show()
# 生成圆形数据
x, y = datasets.make_circles(n_samples=15000, shuffle=True, noise=0.03)
plt.scatter(x[:, 0], x[:, 1], c=y, s=7)
plt.show()
# 生成瑞士卷型数据
X, t = datasets.make_swiss_roll(n_samples=2000, noise=0.1)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=t, cmap=plt.cm.Spectral,edgecolors='black')
plt.show()
# 展示示例图片
img = datasets.load_sample_image('flower.jpg')
print(img.shape)
plt.imshow(img)
plt.show()
4. 数据预处理
sklearn.preprocessing
| 函数 | 功能 |
|---|---|
| preprocessing.scale( ) | 标准化 |
| preprocessing.MinMaxScaler( ) | 最大最小值标准化 |
| preprocessing.StandardScaler( ) | 数据标准化 |
| preprocessing.MaxAbsScaler( ) | 绝对值最大标准化 |
| preprocessing.RobustScaler( ) | 带离群值数据集标准化 |
| preprocessing.QuantileTransformer( ) | 使用分位数信息变换特征 |
| preprocessing.PowerTransformer( ) | 使用幂变换执行到正态分布的映射 |
| preprocessing.Normalizer( ) | 正则化 |
| preprocessing.OrdinalEncoder( ) | 将分类特征转换为分类数值 |
| preprocessing.LabelEncoder( ) | 将分类特征转换为分类数值 |
| preprocessing.MultiLabelBinarizer( ) | 多标签二值化 |
| preprocessing.OneHotEncoder( ) | 独热编码 |
| preprocessing.KBinsDiscretizer( ) | 将连续数据离散化 |
| preprocessing.FunctionTransformer( ) | 自定义特征处理函数 |
| preprocessing.Binarizer( ) | 特征二值化 |
| preprocessing.PolynomialFeatures( ) | 创建多项式特征 |
| preprocessing.Imputer( ) | 弥补缺失值 |
import numpy as np
from sklearn import preprocessing
#标准化:将数据转换为均值为0,方差为1的数据,即标注正态分布的数据
x = np.array([[1,-1,2],[2,0,0],[0,1,-1]])
x_scale = preprocessing.scale(x)
print(x_scale.mean(axis=0),x_scale.std(axis=0))
std_scale = preprocessing.StandardScaler().fit(x)
x_std = std_scale.transform(x)
print(x_std.mean(axis=0),x_std.std(axis=0))
#将数据缩放至给定范围(0-1)
mm_scale = preprocessing.MinMaxScaler()
x_mm = mm_scale.fit_transform(x)
print(x_mm.mean(axis=0),x_mm.std(axis=0))
#正则化
nor_scale = preprocessing.Normalizer()
x_nor = nor_scale.fit_transform(x)
print(x_nor.mean(axis=0),x_nor.std(axis=0))
# 将分类特征或数据标签转换位独热编码
ohe = preprocessing.OneHotEncoder()
x1 = ([["大象"],["猴子"],["老虎"],["老鼠"]])
x_ohe = ohe.fit(x1).transform([["老虎"]]).toarray()
print(x_ohe)
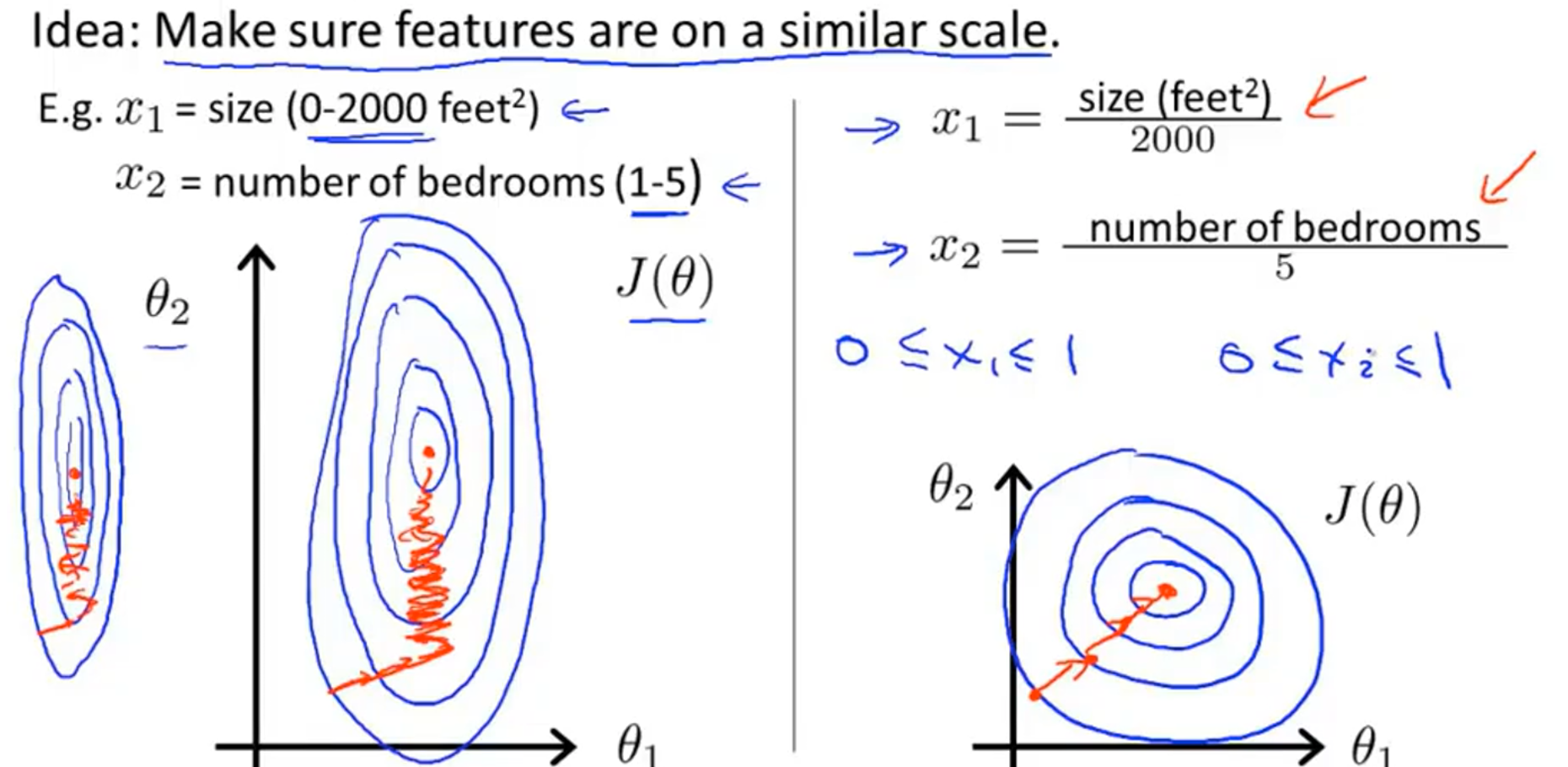
特征放缩的意义:
5. 模型选择
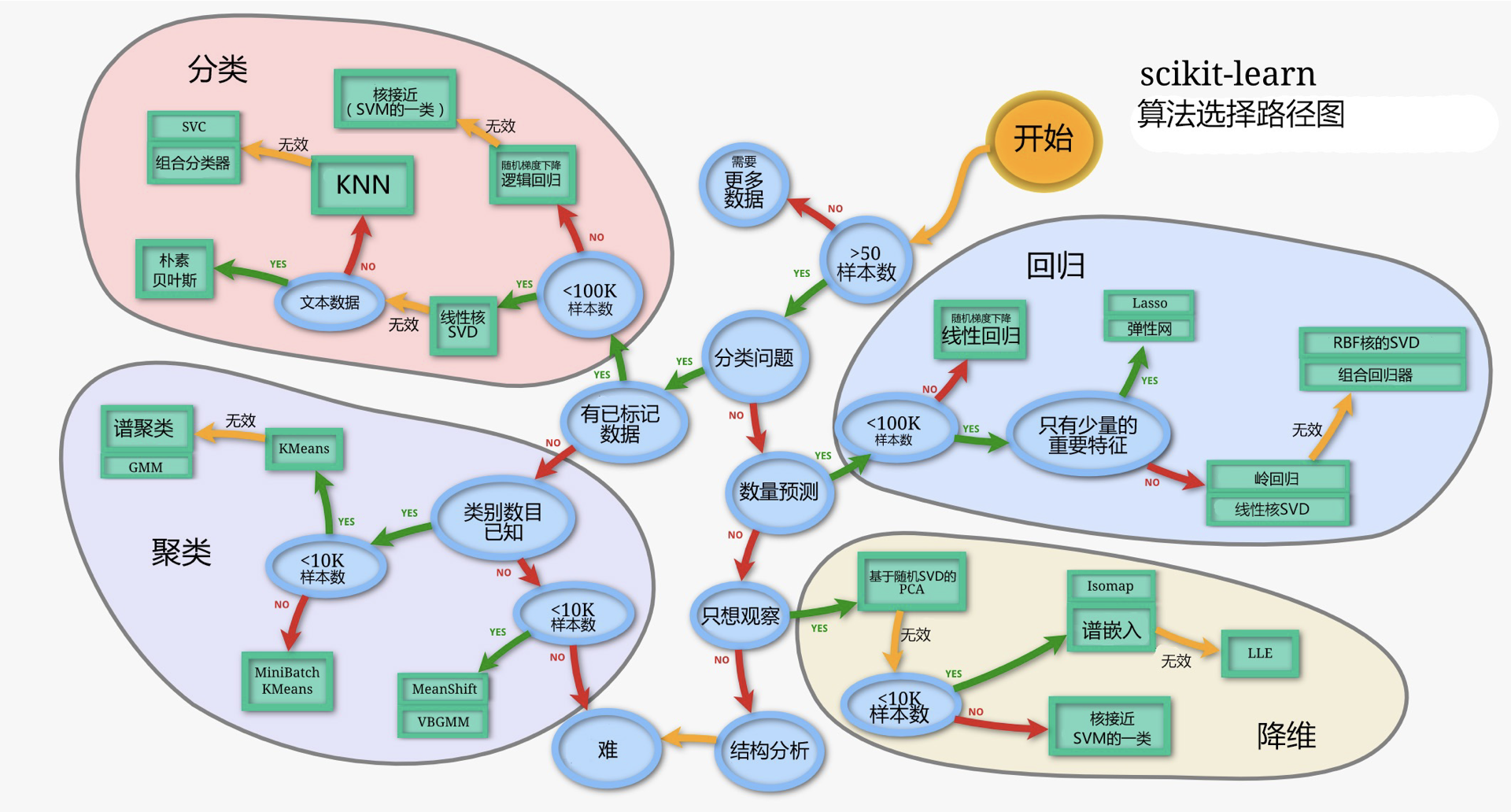
5.1 算法的选择
对于分类、回归、聚类、降维算法的选择,可以参照下图中的算法选择路径图:
从图中可以看到,按照是否为分类问题划分成了两大块,其中分类和聚类属于分类的问题(虽然聚类没有给定类别),回归和降维属于非分类的问题。同时,四类算法也可以按照数据是否有标签划分为监督学习(分类、回归)和无监督学习(聚类、降维)。
5.2 数据划分
5.2.1 训练误差和泛化误差
- 训练误差:出自于训练数据
- 泛化误差:出自于新数据
比如说,使用历年考试真题准备将来的考试,在历年考试真题取得好成绩(训练误差)并不能保证未来考试成绩好(泛化误差),我们训练模型的目的是希望训练好的模型泛化误差越低越好。
5.2.2 验证数据集和测试数据集
下图是机器学习实操的7个步骤:

- 验证数据集(Validation Dataset):用于评估模型的数据集,不应与训练数据混在一起
- 测试数据集(Test Dataset):只可以使用一次数据集
- 训练数据集(Training Dataset):用于训练模型的数据集
那么为什么要分为那么多种数据集呢,首先我们知道训练模型的目的是使得模型的泛化能力越来越强,在训练集上,我们不断进行前向转播和反向传播更新参数使得在训练误差越来越小,但是这并不能代表这个模型泛化能力很强,因为它只是在拟合一个给定的数据集(就好比做数学题用背答案的办法,正确率很高,但并不代表你学到了东西),那么如何评判这个模型泛化能力强呢?就用到了测试数据集,测试数据集就像是期末考试,在模型最终训练完成后才会使用一次,在最终评估之前不能使用这个数据集(好比在考试前不能泄题一样)。判断模型泛化能力强弱的途径有了,但是我们知道在神经网络中有很多超参数也会对模型泛化能力造成影响,那么如何判断不同参数对模型的影响呢,毕竟测试集只能用一次,而参数调整需要很多次,而且也不能使用训练数据集,这样只会拟合训练数据集,无法证明其泛化能力提升,于是我们又划分出了一个数据集,验证数据集,我们的模型训练好之后用验证集来看看模型的表现如何,同时通过调整超参数,让模型处于最好的状态。用一个比喻来说:
- 训练集相当于上课学知识
- 验证集相当于课后的的练习题,用来纠正和强化学到的知识
- 测试集相当于期末考试,用来最终评估学习效果
5.2.3 sklearn中划分数据集
我们可以使用交叉验证或其他划分数据集的方法对数据集多次划分,以得出模型平均的性能而不是偶然结果。sklearn 有很多划分数据集的方法,它们都在model_selection 里面,常用的有
-
K折交叉验证:
-
- KFold 普通K折交叉验证
- StratifiedKFold(保证每一类的比例相等)
-
留一法:
-
- LeaveOneOut (留一)
- LeavePOut (留P验证,当P = 1 时变成留一法)
-
随机划分法:
-
- ShuffleSplit (随机打乱后划分数据集)
- StratifiedShuffleSplit (随机打乱后,返回分层划分,每个划分类的比例与样本原始比例一致)
以上方法除了留一法都有几个同样的参数:
- n_splits:设置划分次数
- random_state:设置随机种子
以上的划分方法各有各的优点,留一法、K折交叉验证充分利用了数据,但开销比随机划分要高,随机划分方法可以较好的控制训练集与测试集的比例,(通过设置train_size参数)详细可查看官方文档。
# 简单划分数据
from sklearn.model_selection import train_test_split
from sklearn import datasets
import pandas as pd
X,y = datasets.load_iris(return_X_y=True)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)
# K折交叉验证
from sklearn.model_selection import KFold
import numpy as np
X = np.random.randint(1,10,20)
kf = KFold(n_splits=5)
for train,test in kf.split(X):
print(train,'\n',test)
# 留一法划分数据
from sklearn.model_selection import LeaveOneOut
import numpy as np
X = np.random.randint(1,10,5)
kf = LeaveOneOut()
for train,test in kf.split(X):
print(train,'\n',test)
使用划分后的数据集进行训练:
# 使用逻辑回归训练鸢尾花数据集
from sklearn.datasets import load_iris
dataSet = load_iris()
data = dataSet['data'] # 数据
label = dataSet['target'] # 数据对应的标签
feature = dataSet['feature_names'] # 特征的名称
target = dataSet['target_names'] # 标签的名称
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import ShuffleSplit
from sklearn.metrics import classification_report
from sklearn.metrics import roc_auc_score
ss = ShuffleSplit(n_splits = 1,test_size= 0.2) # 按比例拆分数据,80%用作训练
for tr,te in ss.split(data,label):
xr = data[tr] # 训练数据
xe = data[te] # 测试数据
yr = label[tr]
ye = label[te]
clf = LogisticRegression(solver = 'lbfgs',multi_class = 'multinomial')
clf.fit(xr,yr)
predict = clf.predict(xe)
print(classification_report(ye, predict))
5.3 模型超参数搜索
5.3.1 GridSearchCV解释
在机器学习模型中,需要人工选择的参数称为超参数。比如随机森林中决策树的个数,人工神经网络模型中隐藏层层数和每层的节点个数,正则项中常数大小等等,他们都需要事先指定。超参数选择不恰当,就会出现欠拟合或者过拟合的问题。而在选择超参数的时候,有两个途径,一个是凭经验微调,另一个就是选择不同大小的参数,带入模型中,挑选表现最好的参数。微调的一种方法是手工调制超参数,直到找到一个好的超参数组合,这么做的话会非常冗长,你也可能没有时间探索多种组合,所以可以使用Scikit-Learn的GridSearchCV来做这项搜索工作。
GridSearchCV的名字其实可以拆分为两部分,GridSearch和CV,即网格搜索和交叉验证。这两个名字都非常好理解。网格搜索,搜索的是参数,即在指定的参数范围内,按步长依次调整参数,利用调整的参数训练学习器,从所有的参数中找到在验证集上精度最高的参数,这其实是一个训练和比较的过程。GridSearchCV可以保证在指定的参数范围内找到精度最高的参数,但是这也是网格搜索的缺陷所在,他要求遍历所有可能参数的组合,在面对大数据集和多参数的情况下,非常耗时。
5.3.2 参数说明
estimator:所使用分类器
param_grid:值为字典或者列表,即需要最优化的参数的取值
scoring:准确度评价标准,默认为None,根据所选模型不同,评价准则不同
cv:交叉验证参数,默认None(三折交叉验证,即fold数量为3),也可以是训练/测试数据的生成器
refit:默认为True,即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集
iid:默认为True,即默认个个样本fold概率分布一直,误差估计为所有样本的和,而非各个fold的平均
verbose:日志冗长度,int:
若冗长度为0,不输出训练过程;
若冗长度为1,偶尔输出(一般设置为1);
若冗长度>1,对每个子模型都输出
n_jobs:并行数,一般设置为-1
pre_dispatch:总共分发的并行任务数,当n_jobs大于1时,数据将在每个运行点进行复制,可能会导致OOM(内存溢出)。通过设置pre_dispatch参数,可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
5.3.3 常用方法及属性
grid.fit():运行网格搜索
grid.score():运行网格搜索后模型得分
best_estimator_:最好的参数模型
best_params_:描述已取得最佳结果的参数的组合
best_score_:提供优化过程期间观察到的最好评分
cv_results_:每次交叉验证后的验证集和训练集的准确率结果
5.3.4 示例
from sklearn.model_selection import GridSearchCV,KFold,train_test_split
from sklearn.metrics import make_scorer , accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_breast_cancer
# load data
data = load_breast_cancer()
X,y = data['data'] , data['target']
X_train,X_test,y_train,y_test = train_test_split(
X,y,train_size=0.8 , random_state=0
)
regressor = DecisionTreeClassifier(random_state=0) # 决策树模型
parameters = {'max_depth':range(1,6)} # 参数列表
scorin_fnc = make_scorer(accuracy_score) # 评估函数采用准确率
kflod = KFold(n_splits=10) # 交叉验证 10折
grid = GridSearchCV(regressor,parameters,scoring=scorin_fnc,cv=kflod)
grid = grid.fit(X_train,y_train)
reg = grid.best_estimator_
print('best score:%f'%grid.best_score_)
#print('best parameters:%d' %grid.best_params_)
print(grid.best_params_)
print('test score : %f'%reg.score(X_test,y_test))
6. 两大核心API
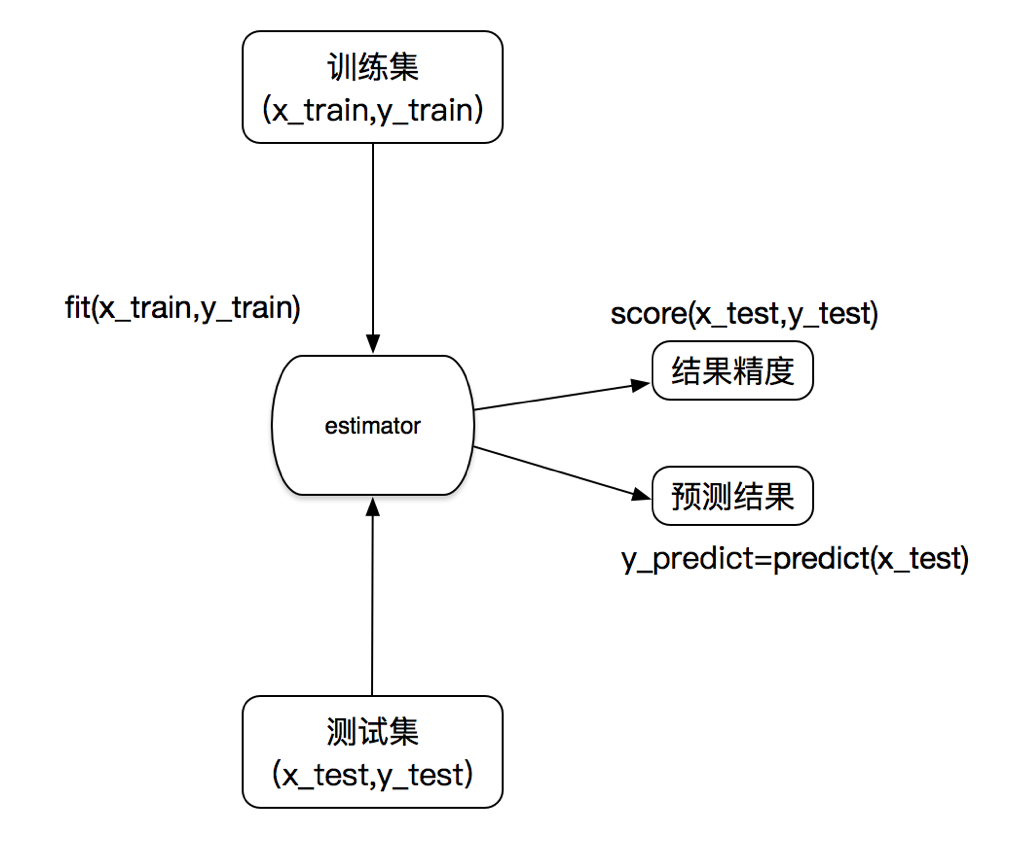
6.1 估计器
估计器(Estimator)其实就是模型,它用于对数据的预测或回归。基本上估计器都会有以下几个方法:
- fit(x,y) :传入数据以及标签即可训练模型,训练的时间和参数设置,数据集大小以及数据本身的特点有关
- score(x,y)用于对模型的正确率进行评分(范围0-1)。但由于对在不同的问题下,评判模型优劣的的标准不限于简单的正确率,可能还包括召回率或者是查准率等其他的指标,特别是对于类别失衡的样本,准确率并不能很好的评估模型的优劣,因此在对模型进行评估时,不要轻易的被score的得分蒙蔽。
- predict(x)用于对数据的预测,它接受输入,并输出预测标签,输出的格式为numpy数组。我们通常使用这个方法返回测试的结果,再将这个结果用于评估模型。
使用估计器的工作流:
6.2 转化器
转化器(Transformer)用于对数据的处理,例如标准化、降维以及特征选择等等。同与估计器的使用方法类似:
- fit(x,y) :该方法接受输入和标签,计算出数据变换的方式。
- transform(x) :根据已经计算出的变换方式,返回对输入数据x变换后的结果(不改变x)
- fit_transform(x,y) :该方法在计算出数据变换方式之后对输入x就地转换。
以上仅仅是简单的概括sklearn的函数的一些特点。sklearn绝大部分的函数的基本用法大概如此。但是不同的估计器会有自己不同的属性,例如随机森林会有Feature_importance来对衡量特征的重要性,而逻辑回归有coef_存放回归系数intercept_则存放截距等等。并且对于机器学习来说模型的好坏不仅取决于你选择的是哪种模型,很大程度上与你超参的设置有关。因此使用sklearn的时候一定要去看看官方文档,以便对超参进行调整。
6.3 举例
import matplotlib.pyplot as plt
# Import datasets, classifiers and performance metrics
from sklearn import datasets, svm, metrics
from sklearn.model_selection import train_test_split
digits = datasets.load_digits()
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, label in zip(axes, digits.images, digits.target):
ax.set_axis_off()
ax.imshow(image, interpolation="nearest")
ax.set_title("Training: %i" % label)
# flatten the images
n_samples = len(digits.images)
data = digits.images.reshape((n_samples, -1))
print(type(digits.images[0]))
# Split data into 50% train and 50% test subsets
X_train, X_test, y_train, y_test = train_test_split(
data, digits.target, test_size=0.5, shuffle=False
)
# Create a classifier: a support vector classifier
clf = svm.SVC(gamma=0.001)
# Learn the digits on the train subset
clf.fit(X_train, y_train)
# Predict the value of the digit on the test subset
predicted = clf.predict(X_test)
print(
f"Classification report for classifier {clf}:\n"
f"{metrics.classification_report(y_test, predicted)}\n"
)
disp = metrics.ConfusionMatrixDisplay.from_predictions(y_test, predicted)
disp.figure_.suptitle("Confusion Matrix")
print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()
7. 具体模型
7.1 降维
sklearn.decomposition
| 函数 | 功能 |
|---|---|
| decomposition.PCA( ) | 主成分分析 |
| decomposition.KernelPCA( ) | 核主成分分析 |
| decomposition.IncrementalPCA( ) | 增量主成分分析 |
| decomposition.MiniBatchSparsePCA( ) | 小批量稀疏主成分分析 |
| decomposition.SparsePCA( ) | 稀疏主成分分析 |
| decomposition.FactorAnalysis( ) | 因子分析 |
| decomposition.TruncatedSVD( ) | 截断的奇异值分解 |
| decomposition.FastICA( ) | 独立成分分析的快速算法 |
| decomposition.DictionaryLearning( ) | 字典学习 |
| decomposition.MiniBatchDictonaryLearning( ) | 小批量字典学习 |
| decomposition.dict_learning( ) | 字典学习用于矩阵分解 |
| decomposition.dict_learning_online( ) | 在线字典学习用于矩阵分解 |
| decomposition.LatentDirichletAllocation( ) | 在线变分贝叶斯算法的隐含迪利克雷分布 |
| decomposition.NMF( ) | 非负矩阵分解 |
| decomposition.SparseCoder( ) | 稀疏编码 |
7.2 分类
7.2.1 决策树
tree.DecisionTreeClassifier( )
from sklearn.datasets import load_iris
from sklearn import tree
x,y = load_iris(return_X_y=True)
clf = tree.DecisionTreeClassifier()
clf = clf.fit(x,y)
tree.plot_tree(clf)
7.2.2 集成学习
| 函数 | 功能 |
|---|---|
| ensemble.BaggingClassifier() | 装袋法集成学习 |
| ensemble.AdaBoostClassifier( ) | 提升法集成学习 |
| ensemble.RandomForestClassifier( ) | 随机森林分类 |
| ensemble.ExtraTreesClassifier( ) | 极限随机树分类 |
| ensemble.RandomTreesEmbedding( ) | 嵌入式完全随机树 |
| ensemble.GradientBoostingClassifier( ) | 梯度提升树 |
| ensemble.VotingClassifier( ) | 投票分类法 |
7.2.3 线性模型
| 函数 | 功能 |
|---|---|
| linear_model.LogisticRegression( ) | 逻辑回归 |
| linear_model.Perceptron( ) | 线性模型感知机 |
| linear_model.SGDClassifier( ) | 具有SGD训练的线性分类器 |
| linear_model.PassiveAggressiveClassifier( ) | 增量学习分类器 |
7.2.4 支持向量机SVM
| 函数 | 功能 |
|---|---|
| svm.SVC( ) | 支持向量机分类 |
| svm.NuSVC( ) | Nu支持向量分类 |
| svm.LinearSVC( ) | 线性支持向量分类 |
7.2.5 KNN算法
| 函数 | 功能 |
|---|---|
| neighbors.NearestNeighbors( ) | 无监督学习临近搜索 |
| neighbors.NearestCentroid( ) | 最近质心分类器 |
| neighbors.KNeighborsClassifier() | K近邻分类器 |
| neighbors.KDTree( ) | KD树搜索最近邻 |
| neighbors.KNeighborsTransformer( ) | 数据转换为K个最近邻点的加权图 |
7.2.6 判别分析
| 函数 | 功能 |
|---|---|
| discriminant_analysis.LinearDiscriminantAnalysis( ) | 线性判别分析 |
| discriminant_analysis.QuadraticDiscriminantAnalysis( ) | 二次判别分析 |
7.2.7 高斯过程分类
| 函数 | 功能 |
|---|---|
| gaussian_process.GaussianProcessClassifier( ) | 高斯过程分类 |
7.2.8 朴素贝叶斯
| 函数 | 功能 |
|---|---|
| naive_bayes.GaussianNB( ) | 朴素贝叶斯 |
| naive_bayes.MultinomialNB( ) | 多项式朴素贝叶斯 |
| naive_bayes.BernoulliNB( ) | 伯努利朴素贝叶斯 |
7.3 回归
7.3.1 树形模型
| 函数 | 功能 |
|---|---|
| tree.DecisionTreeRegress( ) | 回归决策树 |
| tree.ExtraTreeRegressor( ) | 极限回归树 |
7.3.2 集成学习
| 函数 | 功能 |
|---|---|
| ensemble.GradientBoostingRegressor( ) | 梯度提升法回归 |
| ensemble.AdaBoostRegressor( ) | 提升法回归 |
| ensemble.BaggingRegressor( ) | 装袋法回归 |
| ensemble.ExtraTreeRegressor( ) | 极限树回归 |
| ensemble.RandomForestRegressor( ) | 随机森林回归 |
7.3.3 线性模型
| 函数 | 功能 |
|---|---|
| linear_model.LinearRegression( ) | 线性回归 |
| linear_model.Ridge( ) | 岭回归 |
| linear_model.Lasso( ) | 经L1训练后的正则化器 |
| linear_model.ElasticNet( ) | 弹性网络 |
| linear_model.MultiTaskLasso( ) | 多任务Lasso |
| linear_model.MultiTaskElasticNet( ) | 多任务弹性网络 |
| linear_model.Lars( ) | 最小角回归 |
| linear_model.OrthogonalMatchingPursuit( ) | 正交匹配追踪模型 |
| linear_model.BayesianRidge( ) | 贝叶斯岭回归 |
| linear_model.ARDRegression( ) | 贝叶斯ADA回归 |
| linear_model.SGDRegressor( ) | 随机梯度下降回归 |
| linear_model.PassiveAggressiveRegressor( ) | 增量学习回归 |
| linear_model.HuberRegression( ) | Huber回归 |
7.3.4 支持向量机
| 函数 | 功能 |
|---|---|
| svm.SVR( ) | 支持向量机回归 |
| svm.NuSVR( ) | Nu支持向量回归 |
| svm.LinearSVR( ) | 线性支持向量回归 |
7.3.5 KNN算法
| 函数 | 功能 |
|---|---|
| neighbors.KNeighborsRegressor( ) | K近邻回归 |
| neighbors.RadiusNeighborsRegressor( ) | 基于半径的近邻回归 |
7.3.6 其他
| 函数 | 功能 |
|---|---|
| kernel_ridge.KernelRidge( ) | 内核岭回归 |
| gaussian_process.GaussianProcessRegressor( ) | 高斯过程回归 |
| cross_decomposition.PLSRegression( ) | 偏最小二乘回归 |
7.4 聚类
| cluster.DBSCAN( ) | 基于密度的聚类 |
|---|---|
| cluster.GaussianMixtureModel( ) | 高斯混合模型 |
| cluster.AffinityPropagation( ) | 吸引力传播聚类 |
| cluster.AgglomerativeClustering( ) | 层次聚类 |
| cluster.Birch( ) | 利用层次方法的平衡迭代聚类 |
| cluster.KMeans( ) | K均值聚类 |
| cluster.MiniBatchKMeans( ) | 小批量K均值聚类 |
| cluster.MeanShift( ) | 平均移位聚类 |
| cluster.OPTICS( ) | 基于点排序来识别聚类结构 |
| cluster.SpectralClustering( ) | 谱聚类 |
| cluster.Biclustering( ) | 双聚类 |
| cluster.ward_tree( ) | 集群病房树 |
本文参考资料:
https://scikit-learn.org/stable/index.html
https://zhuanlan.zhihu.com/p/393113910
https://blog.csdn.net/algorithmpro/article/details/103045824
