前言:本文为学习 PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】时记录的 Jupyter 笔记,部分截图来自视频中的课件。
神经网络的骨架 nn.Module
import torch.nn as nn
import torch
class Model(nn.Module):
def __init__(self):
super().__init__()
def forward(self,input):
output = input + 1
return output
model = Model()
x = torch.tensor(1.0)
model(x)
tensor(2.)
上面演示了神经网络的创建和使用,可以发现直接使用 "对象名()" 的方式就能调用这个网络,具体原理应该是通过继承的Module中的 __call__ 实现的。
卷积操作
在torch.nn.functional 和 torch.nn 中都有与卷积相关的类,两者差别不大,命名为conv1d、conv2d、conv3d,分别表示对不同维度的数据进行卷积操作,以torch.nn.functional.conv2d为例:

卷积操作举例如下:
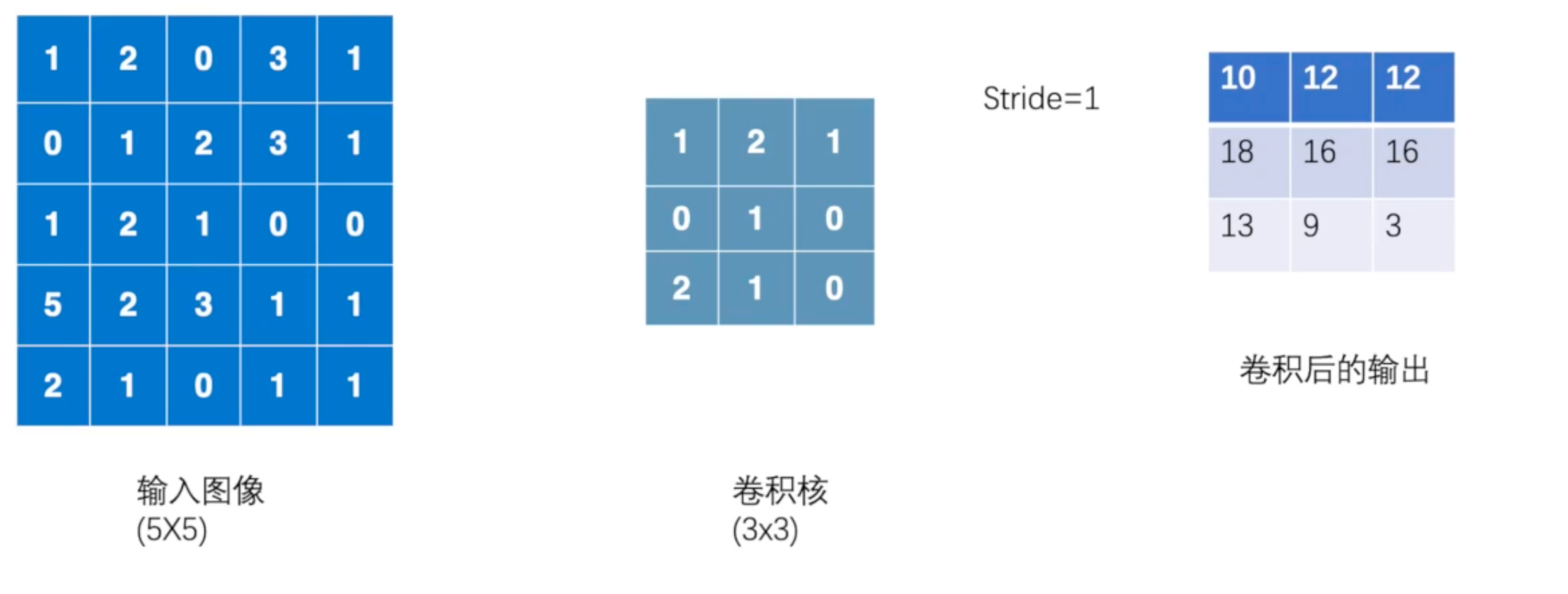
下面用代码模拟一下上图的卷积操作:
import torch
import torch.nn.functional as F
x = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
kernal = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
x = torch.reshape(x,[1,1,5,5])
kernal = torch.reshape(kernal,[1,1,3,3])
out = F.conv2d(x, kernal, stride=1)
out
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
神经网络中的卷积层


具体每个参数的作用,这里有个可视化的介绍:https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
池化操作


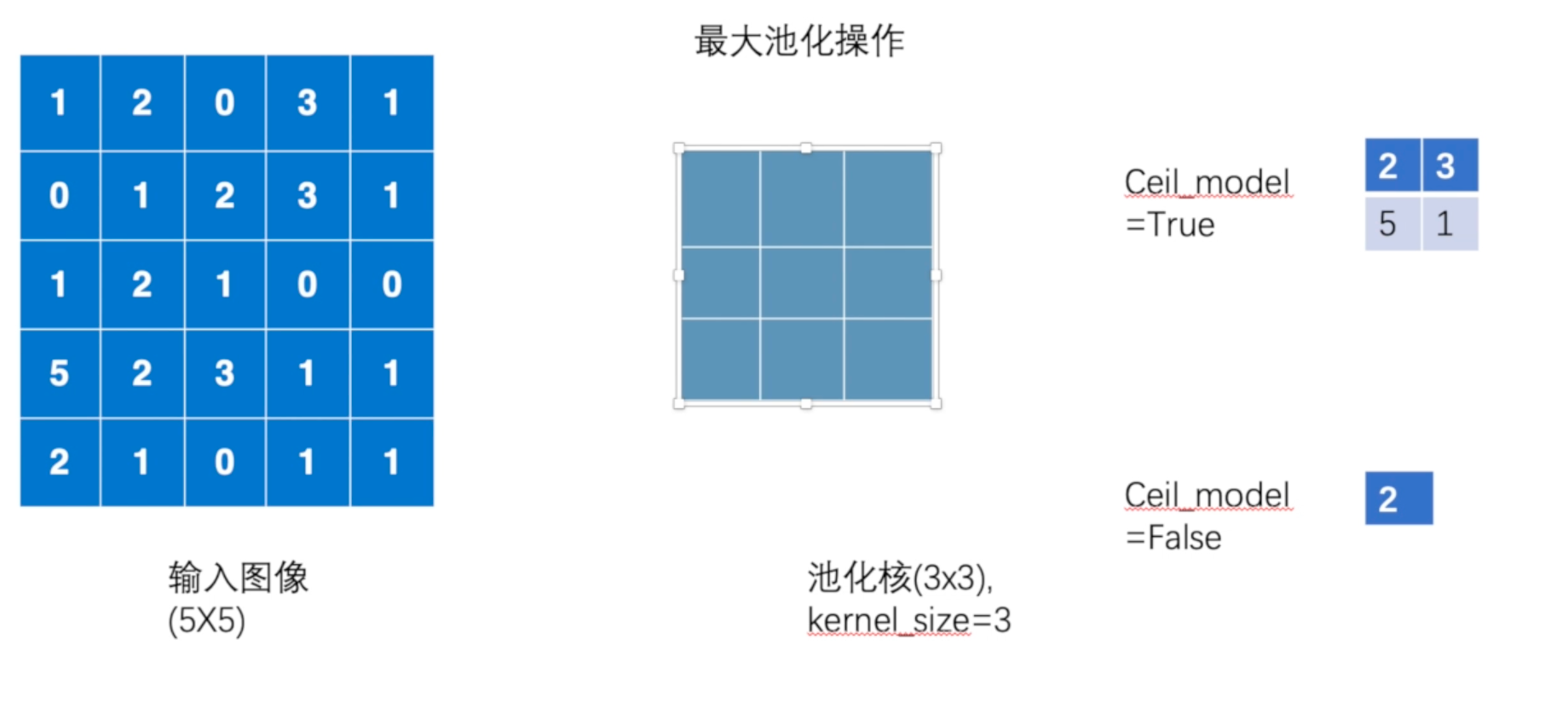
from torch.nn import MaxPool2d
x2 = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]],dtype = torch.float32) # 池化操作需要浮点数
x2 = torch.reshape(x2,[-1,1,5,5])
class Model2(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self,input):
output =self.maxpool1(input)
return output
test = Model2()
out = test(x2)
out
C:\Users\86176\anaconda3\envs\pytorch-gpu\lib\site-packages\torch\nn\functional.py:780: UserWarning: Note that order of the arguments: ceil_mode and return_indices will changeto match the args list in nn.MaxPool2d in a future release.
warnings.warn("Note that order of the arguments: ceil_mode and return_indices will change"
tensor([[[[2., 3.],
[5., 1.]]]])
可以看到和图片中的结果相同,那么最大池化有什么作用呢?
保留输入的特征同时减小数据量(数据降维),使得训练更快。
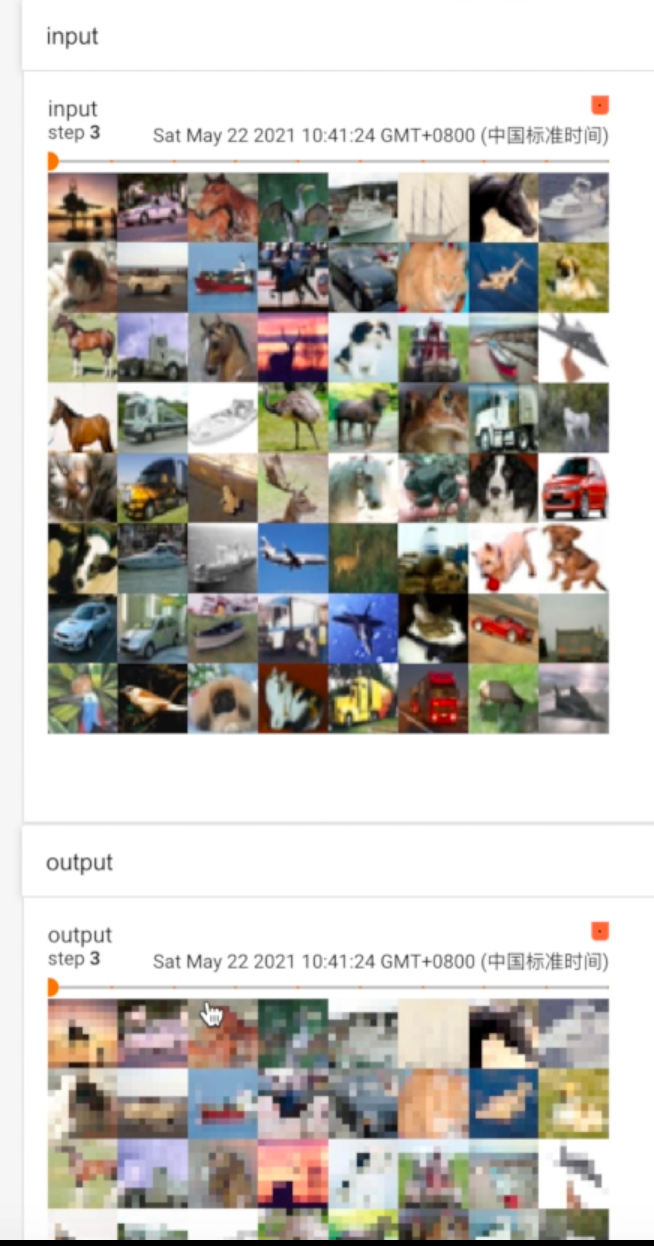
在tensorboard输出池化后的图形,可以发现,有一种类似马赛克的效果。
非线性激活
常用的非线性激活函数有 ReLu Sigmoid等,用于给神经网络增加非线性,使得网络有更好的表达能力。
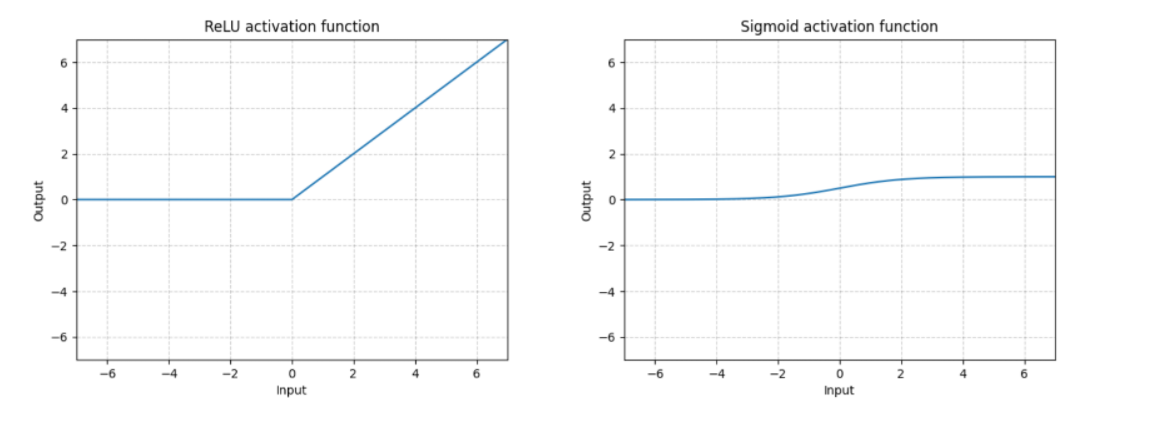
线性变换

用于将数据从一个维度通过线性变换成另外一个维度,类似ANN中的前向传播
损失函数与反向传播
损失函数用于计算输出和目标之间的差距,为神经网络的参数更新提供一定的依据(反向传播)
可以在这里看PyTorch支持的损失函数:
https://pytorch.org/docs/stable/nn.html#loss-functions
在损失函数中需要重点关注的就是输入输出数据要求的维度大小。
import torch
from torch.nn import L1Loss, MSELoss, CrossEntropyLoss
inputs = torch.tensor([1,2,3], dtype=torch.float32)
outputs = torch.tensor([1,2,5], dtype = torch.float32)
inputs = torch.reshape(inputs, (1,1,1,3))
outputs = torch.reshape(outputs, (1,1,1,3))
loss = L1Loss(reduction='sum')
loss2 = MSELoss()
loss3 = CrossEntropyLoss()
result = loss(inputs, outputs)
result2 = loss2(inputs, outputs)
result3 = loss3(inputs, outputs)
print("loss1 = %lf loss2 = %lf loss3 = %lf" %(result, result2, result3))
loss1 = 2.000000 loss2 = 1.333333 loss3 = -0.000000
下面根据上述介绍的函数建立一个神经网络模型,以下图模型为例(CIFAR10-quick model):
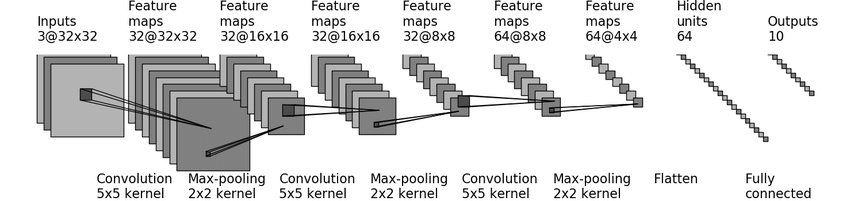
# 在网络中应用
import torchvision
from torch.utils.data import DataLoader
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear, Module
dataset = torchvision.datasets.CIFAR10("./dataset_CIFAR10/", train = False, transform=torchvision.transforms.ToTensor(),download=False)
dataloader = DataLoader(dataset, batch_size=1)
class Model(Module):
def __init__(self):
super(Model, self).__init__()
self.model = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self, x):
x = self.model(x)
return x
# 查看第一批数据的输出结果
iterator = iter(dataloader)
model = Model()
imgs, targets = iterator.next()
imgs.requires_grad = True
outputs = model(imgs)
result_loss = loss3(outputs, targets)
print("outputs = ", outputs)
print("label = %d" %targets.item())
print("loss = %lf" %result_loss.item())
result_loss.backward()
# 反向传播后得到输入数据imgs某一维度的梯度:
print(imgs.grad[0][0][0])
outputs = tensor([[ 0.0962, -0.1525, 0.0624, -0.0246, -0.1077, 0.0627, 0.0115, -0.0504,
0.0796, -0.0587]], grad_fn=<AddmmBackward0>)
label = 3
loss = 2.322197
tensor([-9.1752e-05, 1.9347e-04, -3.4172e-04, 6.5890e-04, -2.8083e-04,
-3.6005e-04, 7.4641e-05, 2.9763e-04, -6.5787e-04, -8.7575e-05,
6.1196e-04, 2.6139e-04, -1.9589e-04, 8.2434e-04, -3.5418e-04,
1.8183e-05, 1.3080e-03, -1.7294e-04, 4.4629e-04, -1.2231e-04,
-1.6606e-04, 7.2360e-05, 3.0993e-04, -9.2893e-04, 6.6193e-05,
-1.6203e-04, -2.1413e-05, 1.7245e-04, 8.3499e-05, 1.4657e-04,
-9.5108e-06, 4.2742e-04])
优化器
上面得到了损失函数,并用损失函数进行梯度下降得到了每个参数对应的梯度,下一步就是使用优化器对神经网络的参数进行更新了。
pytorch支持的优化器可以在:https://pytorch.org/docs/stable/optim.html 中查看。
model2 = Model()
optim = torch.optim.Adam(model2.parameters(), lr=0.005) # 设置模型中需要更新的参数和学习率
imgs.requires_grad = False
for epoch in range(4):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = model2(imgs)
result_loss = loss3(outputs, targets)
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss = running_loss + result_loss
print("epoch%d loss = %lf" %(epoch, running_loss))
epoch0 loss = 337001.468750
epoch1 loss = 2112099.500000
epoch2 loss = 3675678.000000
epoch3 loss = 715378.125000
注:可以发现loss下降一段后又逐渐增大了,这可能是学习率过高的原因。
现有模型的使用
pytorch中也提供了一些已经训练好的模型可以使用并且修改,以VGG16模型为例做分类问题,模型结构如下:
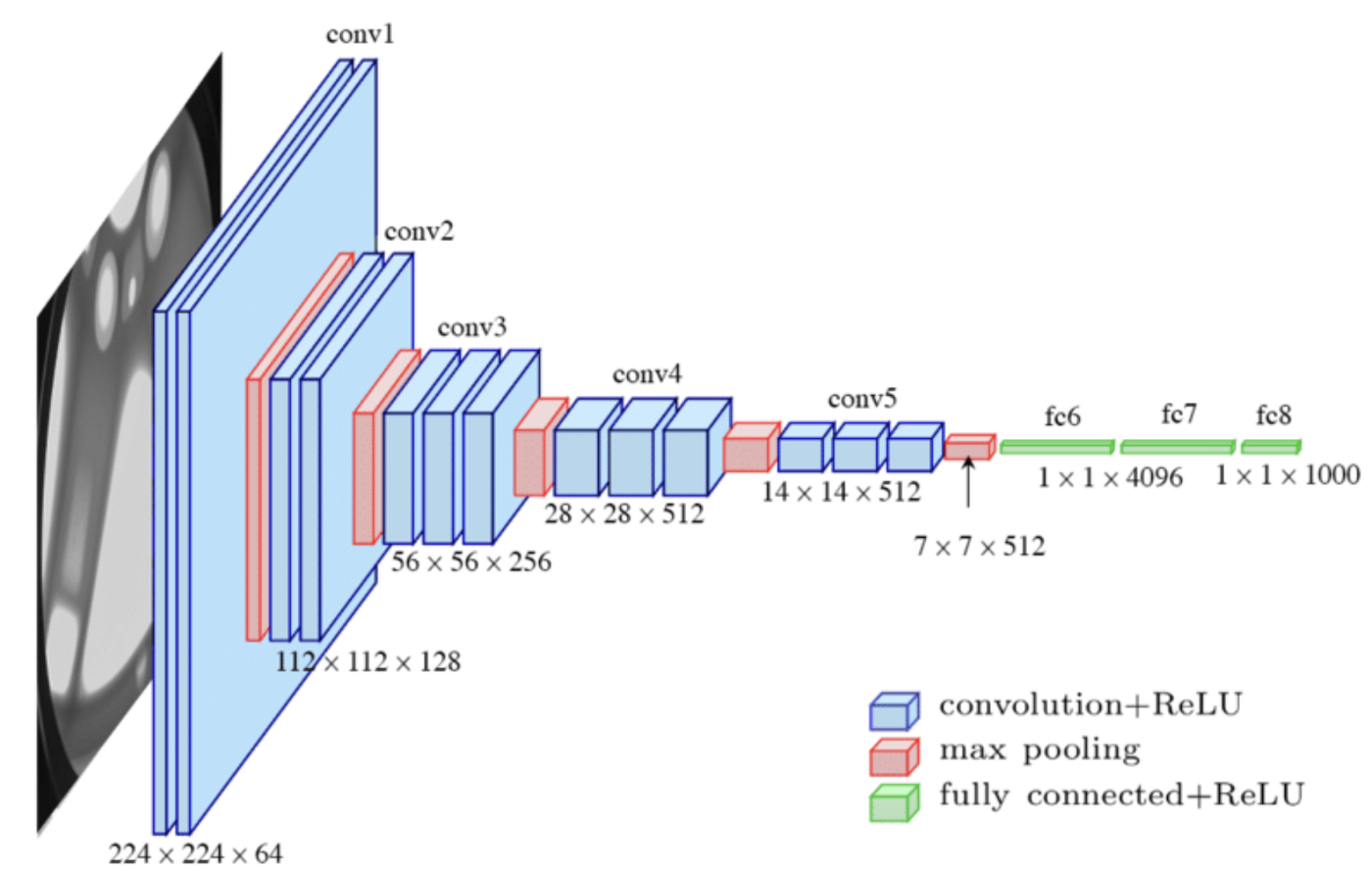
在pytorch中,使用方法如下:
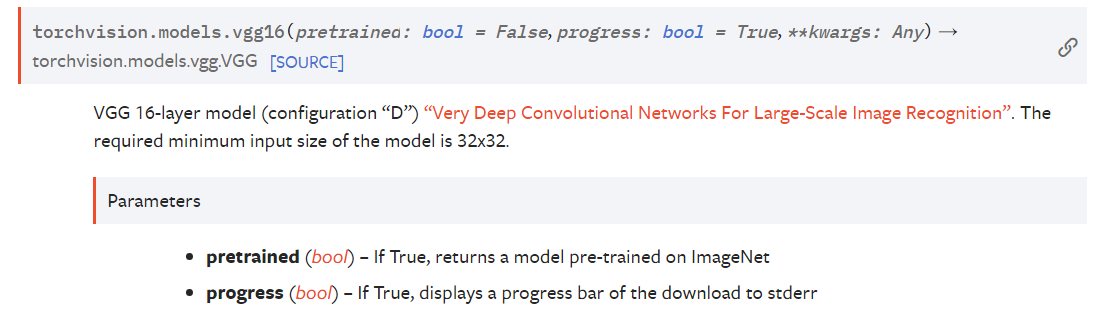
import torchvision
# vgg16在ImageNet中训练完成,但是由于ImageNet数据集过大(100多G),所以不下载使用
vgg16_false = torchvision.models.vgg16(pretrained=False) # 未进行训练,只有网络结构
vgg16_true = torchvision.models.vgg16(pretrained=True) # 训练好的模型,包括参数和结构,会在网络上下载网络参数
print(vgg16_true)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
从上面的vgg16的参数中可以看到,它输出的维度out_features = 1000,所以它可以进行1000分类的任务,如果我们想将这个模型用在CIFAR10中,有两种途径:
- 把 out_features 改成10
- 在输出层下再加入一层,使得输出变成10
from torch import nn
dataset = torchvision.datasets.CIFAR10("./dataset_CIFAR10/", train = False, transform=torchvision.transforms.ToTensor(),download=False)
# 增加一层使得输出变为10
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000,10))
vgg16_true
# 修改最后一层的输出
vgg16_false.classifier[6] = nn.Linear(4096,10)
vgg16_false
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
)
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
网络模型的保存和读取
# 保存方法1
vgg16 = torchvision.models.vgg16(pretrained=False)
torch.save(vgg16, "vgg16_method_false.pth")
# 加载模型方法1
model_load = torch.load("vgg16_method_false.pth")
# 保持方法2--模型参数(官方推荐,空间小)
torch.save(vgg16.state_dict(), "vgg16_mothod_dict.pth")
# 加载模型方式2
model_load_dict = torch.load("vgg16_mothod_dict.pth") # 导入字典参数
vgg16_load_dict = torchvision.models.vgg16(pretrained=False) # 新建模型结构
vgg16_load_dict.load_state_dict(model_load_dict) # 从字典中导入参数
<All keys matched successfully>

