前言:本文为学习 PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】时记录的 Jupyter 笔记,部分截图来自视频中的课件。
搭建模型流程
import torchvision
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10/", train=True, transform=torchvision.transforms.ToTensor(), download=False)
test_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10/", train=False, transform=torchvision.transforms.ToTensor(), download=False)
# length
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集长度为:{} \n验证数据集的长度为:{}".format(train_data_size, test_data_size))
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
训练数据集长度为:50000
验证数据集的长度为:10000
# 搭建神经网络
class Modle(nn.Module):
def __init__(self):
super(Modle,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2), # 输入channel 输出channel 卷积核大小 步长 padding填充
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 验证模型是否出错
x = torch.randn((64,3,32,32)) # 随机一个输入
model = Modle()
y = model(x)
y[0]
tensor([-0.2466, 0.0369, -0.0336, 0.0940, -0.0035, -0.1510, -0.0465, -0.1413,
0.0610, 0.1415], grad_fn=<SelectBackward0>)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 0.001
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
# 设置训练网络的参数
total_train_step = 0
total_test_step = 0
epoch = 5
# 添加tensorboard
writer = SummaryWriter("./logs_train_CIFAR10")
# 开始训练
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# model.train() 网络中有特殊层的时候需要加上,具体看文档,但加上不会出错
for data in train_dataloader:
imgs, targets = data
outputs = model(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 200 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
# model.eval() 网络中有特殊层的时候需要加上,具体看文档,但加上不会出错
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 取消梯度跟踪,进行测试 重要!!!
for dataata in test_dataloader:
imgs, targets = data
outputs = model(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accurcy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accurcy
print("第{}次训练 整体测试上的loss:{}".format(total_test_step + 1,total_test_loss))
print("第{}次训练 整体测试上的准确率:{}".format(total_test_step + 1,total_accuracy/test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 保存每一次训练的模型
torch.save(model, "model_{}.path".format(total_train_step))
print("------训练完毕-------")
writer.close()
-------第 1 轮训练开始-------
训练次数:200,Loss:1.5930722951889038
训练次数:400,Loss:1.5104329586029053
训练次数:600,Loss:1.6171875
第1次训练 整体测试上的loss:289.1482034921646
第1次训练 整体测试上的准确率:0.12559999525547028
-------第 2 轮训练开始-------
训练次数:800,Loss:1.3620392084121704
训练次数:1000,Loss:1.4055718183517456
训练次数:1200,Loss:1.405728816986084
训练次数:1400,Loss:1.5098960399627686
第2次训练 整体测试上的loss:287.84552359580994
第2次训练 整体测试上的准确率:0.12559999525547028
-------第 3 轮训练开始-------
训练次数:1600,Loss:1.453757882118225
训练次数:1800,Loss:1.753093957901001
训练次数:2000,Loss:1.7896429300308228
训练次数:2200,Loss:1.3330057859420776
第3次训练 整体测试上的loss:286.49878656864166
第3次训练 整体测试上的准确率:0.10989999771118164
-------第 4 轮训练开始-------
训练次数:2400,Loss:1.55629563331604
训练次数:2600,Loss:1.5665236711502075
训练次数:2800,Loss:1.4883909225463867
训练次数:3000,Loss:1.3436790704727173
第4次训练 整体测试上的loss:284.92055308818817
第4次训练 整体测试上的准确率:0.10989999771118164
-------第 5 轮训练开始-------
训练次数:3200,Loss:1.3288989067077637
训练次数:3400,Loss:1.4521342515945435
训练次数:3600,Loss:1.6048355102539062
训练次数:3800,Loss:1.3855892419815063
第5次训练 整体测试上的loss:283.1985069513321
第5次训练 整体测试上的准确率:0.12559999525547028
------训练完毕-------
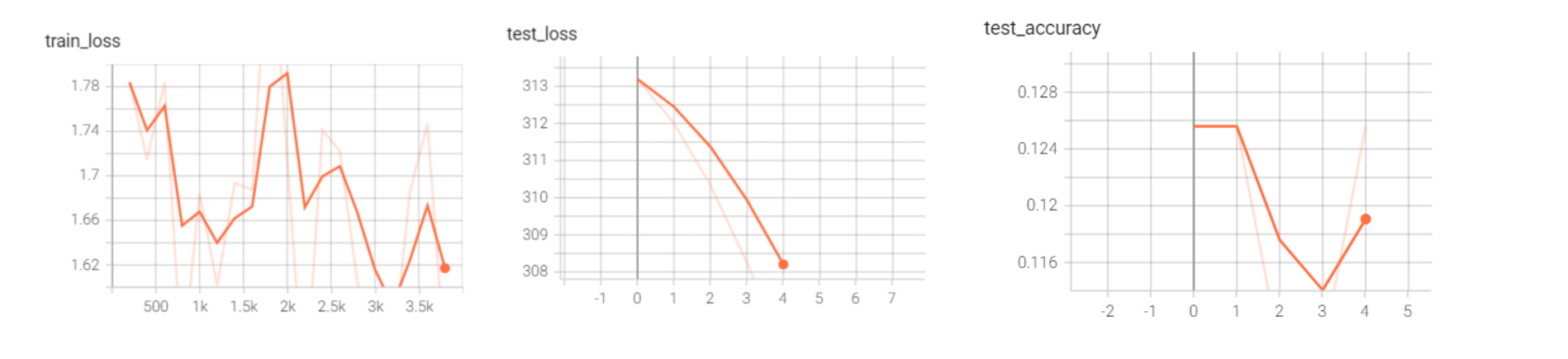
可以看到效果并不是很好,仅作为演示
GPU训练模型
用之前搭建好的模型,演示如何使用GPU训练
主要就是在:网络模型、数据(输入、标签)、损失函数上设置 .cuda() 模式即可
实测比CPU快10倍左右。
此外还有一种写法就是用 .to(device)
Device = torch.device("CPU")
Device = torch.device("duta")
Device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
import torchvision
import torch.nn as nn
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10/", train=True, transform=torchvision.transforms.ToTensor(), download=False)
test_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10/", train=False, transform=torchvision.transforms.ToTensor(), download=False)
# length
train_data_size = len(train_data)
test_data_size = len(test_data)
# 利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
class Modle(nn.Module):
def __init__(self):
super(Modle,self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2), # 输入channel 输出channel 卷积核大小 步长 padding填充
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
model = Modle()
model = model.cuda() # 设置在GPU中训练
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda() # 设置GPU模式
# 优化器
learning_rate = 0.001
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
# 设置训练网络的参数
total_train_step = 0
total_test_step = 0
epoch = 5
# 添加tensorboard
#writer = SummaryWriter("./logs_train_CIFAR10")
# 开始训练
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i+1))
# model.train() 网络中有特殊层的时候需要加上,具体看文档,但加上不会出错
for data in train_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = model(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 200 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
#writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
# model.eval() 网络中有特殊层的时候需要加上,具体看文档,但加上不会出错
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 取消梯度跟踪,进行测试 重要!!!
for dataata in test_dataloader:
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = model(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accurcy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accurcy
print("第{}次训练 整体测试上的loss:{}".format(total_test_step + 1,total_test_loss))
print("第{}次训练 整体测试上的准确率:{}".format(total_test_step + 1,total_accuracy/test_data_size))
# writer.add_scalar("test_loss", total_test_loss, total_test_step)
# writer.add_scalar("test_loss", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 保存每一次训练的模型
torch.save(model, "model_{}.path".format(total_train_step))
print("------训练完毕-------")
# writer.close()

