1. 激活函数
1.1 原因
由于单层的感知机模型的表达能力很差,只能表示线性模型,连最简单的 XOR 函数模型都无法表示,所以出现了多层感知机模型,加入了隐藏层,最简单的多层感知机模型有三层,分别为输入层、隐藏层、输出层,其中隐藏层的元素个数和层数是超参数(即自定义的),如下图所示:

其中
1.2 Sigmoid激活函数
将输入映射到 (0, 1), 一个平滑的版本
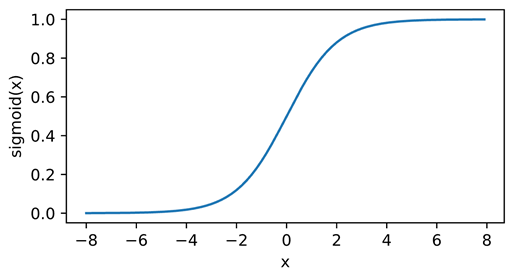
1.3 Tanh 激活函数
将输入投影到 (-1,1) 之间。
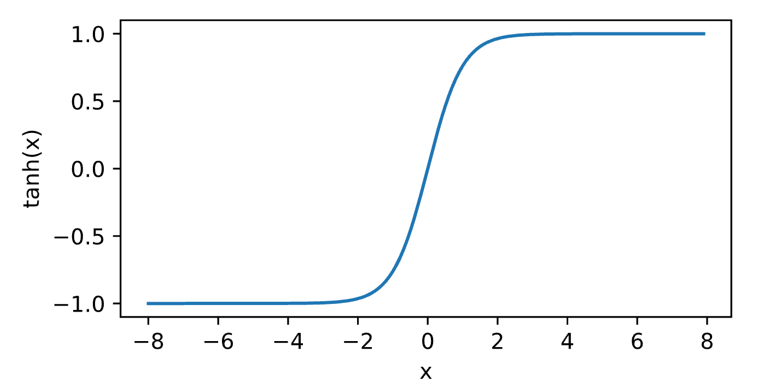
1.4 ReLU激活函数
ReLU:rectified linear unit, 线性修正单元,把小于0的部分砍掉使得变成一个非线性的函数,相比前两个激活函数,不用做指数运算,速度快。
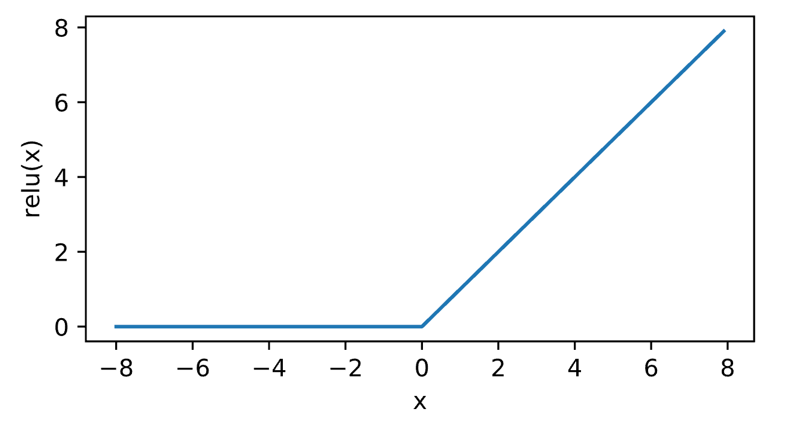
1.5 感知机模型实现
基于PyTorch实现模型,训练采用d2l包
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X@W1 + b1) # 这里“@”代表矩阵乘法
return (H@W2 + b2)
loss = nn.CrossEntropyLoss(reduction='none')
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
其中,网络模型定义也可以用PyTorch的高级API实现:
net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256), nn.ReLU(), nn.Linear(256,10))
2. 数据集划分
2.1 训练误差和泛化误差
- 训练误差:出自于训练数据
- 泛化误差:出自于新数据
比如说,使用历年考试真题准备将来的考试,在历年考试真题取得好成绩(训练误差)并不能保证未来考试成绩好(泛化误差),我们训练模型的目的是希望训练好的模型泛化误差越低越好。
2.2 验证数据集和测试数据集
下图是机器学习实操的7个步骤:

- 验证数据集(Validation Dataset):用于评估模型的数据集,不应与训练数据混在一起
- 测试数据集(Test Dataset):只可以使用一次数据集
- 训练数据集(Training Dataset):用于训练模型的数据集
那么为什么要分为那么多种数据集呢,首先我们知道训练模型的目的是使得模型的泛化能力越来越强,在训练集上,我们不断进行前向转播和反向传播更新参数使得在训练误差越来越小,但是这并不能代表这个模型泛化能力很强,因为它只是在拟合一个给定的数据集(就好比做数学题用背答案的办法,正确率很高,但并不代表你学到了东西),那么如何评判这个模型泛化能力强呢?就用到了测试数据集,测试数据集就像是期末考试,在模型最终训练完成后才会使用一次,在最终评估之前不能使用这个数据集(好比在考试前不能泄题一样)。判断模型泛化能力强弱的途径有了,但是我们知道在神经网络中有很多超参数也会对模型泛化能力造成影响,那么如何判断不同参数对模型的影响呢,毕竟测试集只能用一次,而参数调整需要很多次,而且也不能使用训练数据集,这样只会拟合训练数据集,无法证明其泛化能力提升,于是我们又划分出了一个数据集,验证数据集,我们的模型训练好之后用验证集来看看模型的表现如何,同时通过调整超参数,让模型处于最好的状态。用一个比喻来说:
- 训练集相当于上课学知识
- 验证集相当于课后的的练习题,用来纠正和强化学到的知识
- 测试集相当于期末考试,用来最终评估学习效果
2.3 K 折交叉验证
在没有足够的数据时非常有用,算法如下:
-
将训练数据划分为 K 个部分
-
For i = 1,…,K
- 使用第 i 部分作为验证集,其余部分用于训练
-
报告 K 个部分在验证时的平均错误
常见 K 值选择:5 – 10
3. 过拟合和欠拟合
3.1 模型复杂度
模型复杂度:可适应不同数据分布的能力,低容量模型难以适应训练集(欠拟合),高容量模型可以记忆训练集(过拟合)

估计模型复杂度:很难比较不同算法之间的复杂度,但是对于同一类的算法,主要影响因素为:参数个数和每个参数采用的值(值的取值范围大则复杂度高)
3.2 VC维度
统计学习理论的中心主题,核心思想:对于分类模型,VC维度等于这个数据集的大小,无论我们如何分配标签,都存在一个模型来完美地对它进行分类
比如说2维感知机的VC维为3,表示对于3个点,他都可以将其区分,但是如果有4个点就不能区分了,如下图,最右边的就需要一个二维的曲线才能分隔:

具有 N 个参数的感知机:VC维是 N+1,一些多层感知机的VC维是
4. 正则化
4.1 正则化背景
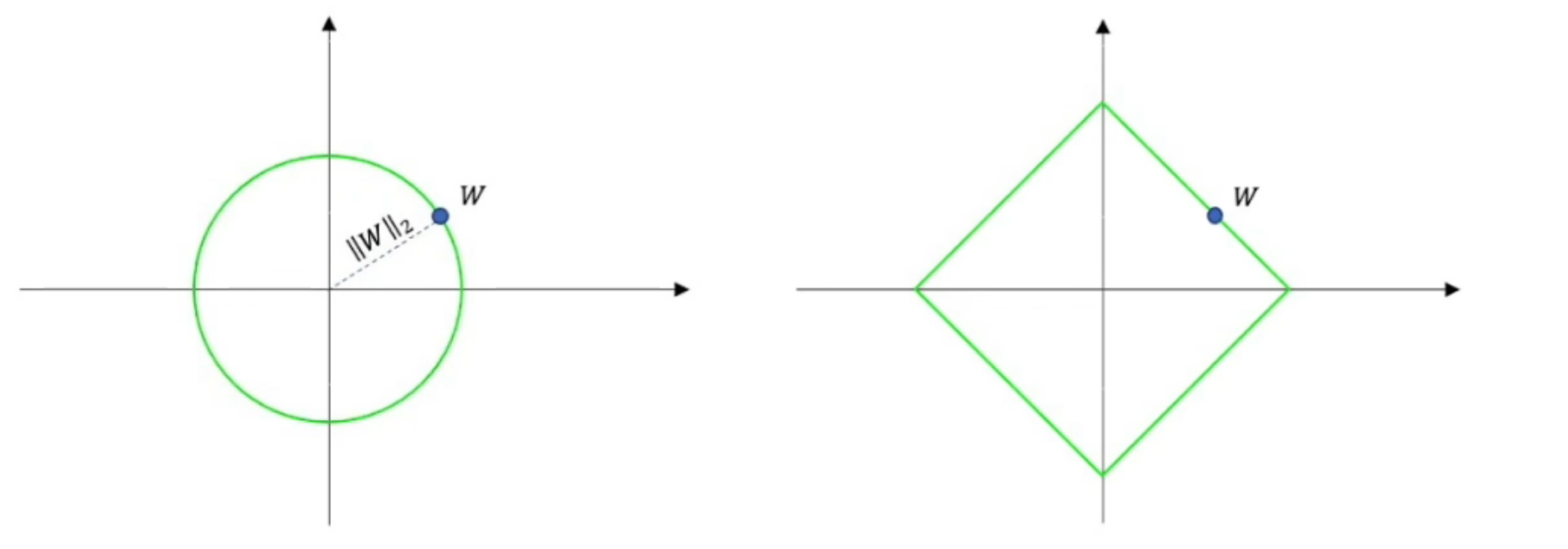
正则化定义: 凡是能减少模型泛化误差而不是训练误差的方法都成为正则化,常见的L1、L2、Dropout等都属于正则化,这里只讲针对神经网络中权值参数 $w$ 的正则化,即L1、L2正则化。L1和L2正则化用到的是L1和L2范数,其实就是对高维空间距离的一个定义,公式表达如下:
- L1范数:
,如下图右。 - L2范数:
,如下图左。
关于正则化涉及拉格朗日对偶问题,数学基础有点差,先战略性跳过,机缘合适再填坑。
4.2 平方正则化
硬约束:
通过限制参数值范围来降低模型复杂性,即:
软约束:
对于每一个 θ,我们都可以找到 λ 将硬约束版本重写为
图解正则项对最优解的影响
如下图所示,绿色的圈表示

参数更新法则

从参数更新的公式可以看出,和不加入正则项的区别就在于
4.5 丢弃法dropout
动机
在神经网络中,神经元是相互依赖的,他们对彼此的影响相当大,相对于他们的输入还不够独立。一些神经元具有比其他神经元更重要的预测能力的情况,我们会过度依赖于个别的神经元的输出。这些影响必须避免,权重必须具有一定的分布,以防止过拟合。某些神经元的协同适应和高预测能力可以通过不同的正则化方法进行调节。其中最常用的是Dropout,用输入噪声训练相当于 Tikhonov 正则化,而Dropout是将噪音注入内部隐藏层。
无偏差地加入噪音
对
可以发现,添加扰动后,每个元素的期望是没有发生变化的。在神经网络中,通常将丢弃法作用在隐藏全连接层的输出上。需要注意的是,对于所有的正则项,都只在训练中使用,因为他们影响模型参数的更新(在 PyTorch中可以用 torch.eval() 和 torch.train() 来激活和失活正则项)。
5. 数值稳定性
5.1 梯度爆炸和梯度消失
由于神经网络中需要进行很多次的求梯度的过程,这就可能导致两个数值稳定性的问题:梯度爆炸和梯度消失
对于梯度爆炸,可能会造成下面的问题:
-
梯度值超出范围:特别是使用 16 位浮点,其数值范围:[6e-5 , 6e4]
-
对学习率(LR)敏感,可能需要在训练期间大幅改变 LR:
- 不够小的 LR -> 更大的权重 -> 更大的梯度
- 太小的 LR -> 模型训练没有进展
对于梯度消失,比如使用 sigmoid函数作为激活函数,它的图像和梯度的图形如下图,可以发现,当函数值到达6以及-6的时候,梯度就会变得非常接近于0 了,加上在神经网络中梯度可能会被乘上百次,梯度就会更趋近于0了,这就是梯度消失。
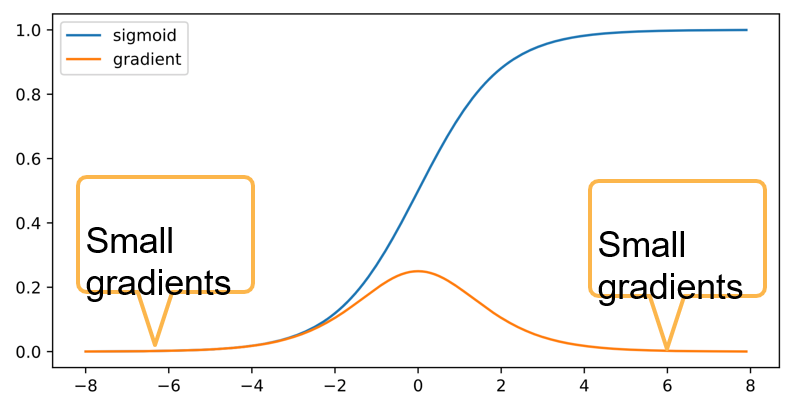
梯度消失可能会有以下问题:
- 度值趋近为0的渐变,对16位浮点尤为严重
- 训练没有进展,无论如何选择学习率(LR)
- 对于底层训练基本无效,因为越到深处,梯度就会越小,越接近0,这就导致深层网络和浅层网络没有区别了。

哈哈,我也是看d2l~沐神的视频确实是无敌(~ ̄▽ ̄)~
确实无敌~
这个是根据啥资料整理的啊|´・ω・)ノ
回复的有点晚了,应该是李沐的动手学深度学习,b站有,有些也是我自己网上找的
奥奥谢谢佬