1. 逻辑单元(神经元)
1.1 生物神经元
对于神经元的研究由来已久,1904年生物学家就已经知晓了神经元的组成结构。在人脑中有数以亿计的神经元,每个神经元最主要的部分就是树突和轴突,一个神经元通常有多个树突但是只有一个轴突。树突接收来自外界的电信号,电信号经过细胞体的处理后经由轴突发送出去。一个神经元通常有多个树突但是只有一个轴突,树突与其他神经元的轴突相连,神经元间通过这样的方式传递和处理信号,并控制着肌肉的收缩。神经元的结构如下图所示:
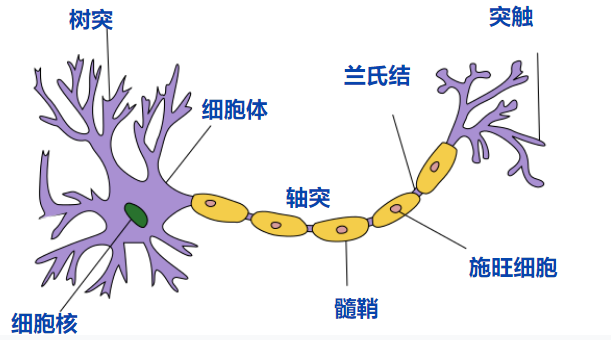
此外,生物神经元有如下的假定特点:
- 每个神经元都是一个 多输入单输出的信息处理单元;
- 神经元输入 分兴奋性输入和 抑制性输入两种类型;
- 神经元具有 空间整合特性和 阈值特性;
- 神经元输入与输出间有固定的 时滞,主要取决于突触延搁。
1.2 M-P模型
1943年,心理学家McCulloch和数学家Pitts参考了生物神经元的结构,发表了抽象的神经元模型M-P,神经元模型是一个包含输入,输出与计算功能的模型。输入可以类比为神经元的树突,而输出可以类比为神经元的轴突,计算则可以类比为细胞核。其结构如下图所示:

那么接下来我们可以开始类比理解了。我们将这个模型和生物神经元的特性列表来比较:

为了表述方便,我们给这个神经元一个编号
如果我们将输入表示成行向量
1.3 发展历程
1943年发布的MP模型,虽然简单,但已经建立了神经网络大厦的地基。但是,MP模型中,权重的值都是预先设置的,因此不能学习。
1949年心理学家Hebb提出了Hebb学习率,认为人脑神经细胞的突触(也就是连接)上的强度上可以变化的。于是计算科学家们开始考虑用调整权值的方法来让机器学习。这为后面的学习算法奠定了基础。
尽管神经元模型与Hebb学习律都已诞生,但限于当时的计算机能力,直到接近10年后,第一个真正意义的神经网络才诞生。
2. 单层感知机
1958年,计算科学家Rosenblatt提出了由两层神经元组成的神经网络。他给它起了一个名字–“感知器”(Perception)(有的文献翻译成“感知机”,下文统一用“感知器”来指代)。感知器是当时首个可以学习的人工神经网络。Rosenblatt现场演示了其学习识别简单图像的过程,在当时的社会引起了轰动。人们认为已经发现了智能的奥秘,许多学者和科研机构纷纷投入到神经网络的研究中。美国军方大力资助了神经网络的研究,并认为神经网络比“原子弹工程”更重要。这段时间直到1969年才结束,这个时期可以看作神经网络的第一次高潮。
2.1 模型结构
感知机模型其实就是M-P神经元模型的组合,对于单层感知机模型,它只包含一个输入层和一个输出层,输入层的神经元提供输入数据,不进行计算,输出层的神经元接受输入层的数据并进行计算得到模型的输出结果。如下图所示的就是一个输入层包含三个神经元,输出层包含两个神经元的单层感知机模型。

以输出层的神经元
2.2 几何意义
在有些地方,感知机模型的表达式为
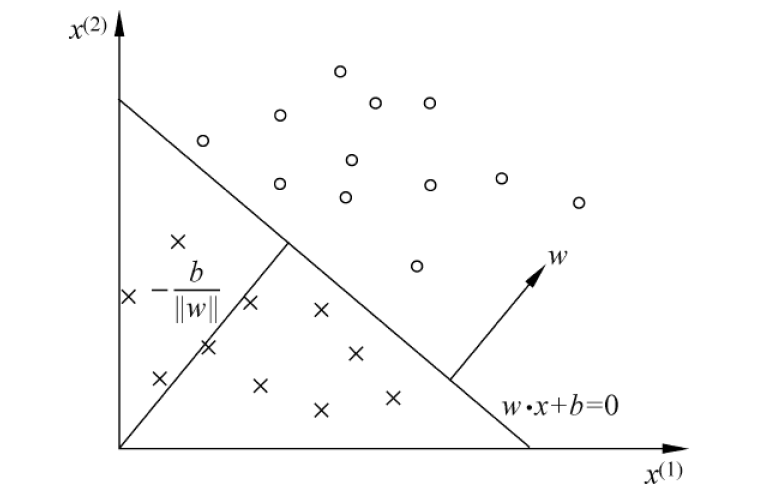
2.3 学习策略
假设训练数据集是线性可分的,感知机学习的目标是求得一个能够将训练集正实 例点和负实例点完全正确分开的分离超平面。为了找出这样的超平面,即确定感知机模型参数
对于某个误分类点
那么对于误分类点到超平面的距离为:
这样,假设超平面
不考虑
这里的
在模型训练时,首先随机选取一个
然后使用梯度更新参数:
式子中
2.4 局限性
感知器只能做简单的线性分类任务。但是当时的人们热情太过于高涨,并没有人清醒的认识到这点。于是,当人工智能领域的巨擘Minsky指出这点时,事态就发生了变化。Minsky在1969年出版了一本叫《Perceptron》的书,里面用详细的数学证明了感知器的弱点,尤其是感知器对XOR(异或)这样的简单分类任务都无法解决。Minsky认为,如果将计算层增加到两层,计算量则过大,而且没有有效的学习算法。所以,他认为研究更深层的网络是没有价值的。由于Minsky的巨大影响力以及书中呈现的悲观态度,让很多学者和实验室纷纷放弃了神经网络的研究。神经网络的研究陷入了冰河期。这个时期又被称为“AI winter”。接近10年以后,对于两层神经网络的研究才带来神经网络的复苏。
3. 多层感知机
Minsky说过单层神经网络无法解决异或问题。但是当增加一个计算层以后,两层神经网络不仅可以解决异或问题,而且具有非常好的非线性分类效果。不过两层神经网络的计算是一个问题,没有一个较好的解法。1986年,Rumelhar和Hinton等人提出了反向传播(Backpropagation,BP)算法,解决了两层神经网络所需要的复杂计算量问题,从而带动了业界使用两层神经网络研究的热潮。这时候的Hinton还很年轻,30年以后,正是他重新定义了神经网络,带来了神经网络复苏的又一春。
3.1 模型结构
两层神经网络除了包含一个输入层,一个输出层以外,还增加了一个隐藏层。此时,隐藏层和输出层都是计算层。现在,我们的权值矩阵增加到了两个,我们用上标来区分不同层次之间的变量,如

参考单层感知机模型,可以同样可以用矩阵运算,得到
当然图中的模型只是多层感知机的一个例子,你可以任意增加层数和每层的神经元个数,“自由”把握在设计者的手中。
3.2 BP反向传播
在设计好模型后,随机给一个初始参数,然后应用前向传播从左向右逐层计算得到模型的输出。那么如何自动地更新参数训练模型呢,类比单层感知机模型,同样需要一个损失函数以及梯度下降的方法。在多层感知机中,我们使用均方误差作为损失函数,公式为:
不过这不是真正的均方误差函数,而是为了后面的求导方便进行了一定的微调,真正的均方误差公式为:
不过这只是倍数上的差别,多模型训练没有影响。所以,我们的优化目标就是使得上面的损失函数尽可能地小,通过更新每一层的权值参数。使用的方法就是反向传播,其原理就是从输出层开始逐层向左利用链式法则计算每一层权重的梯度并更新。以下面的模型为例:
假设我们的输入为分别为1和0,并且权重参数如图所示,我们先用前向传播计算出预测值为 0.8,假设真实值为1,应用损失函数公式计算得到误差为0.012。
Tips:下列涉及的所有数值计算都是进行过四舍五入的,非精确值。
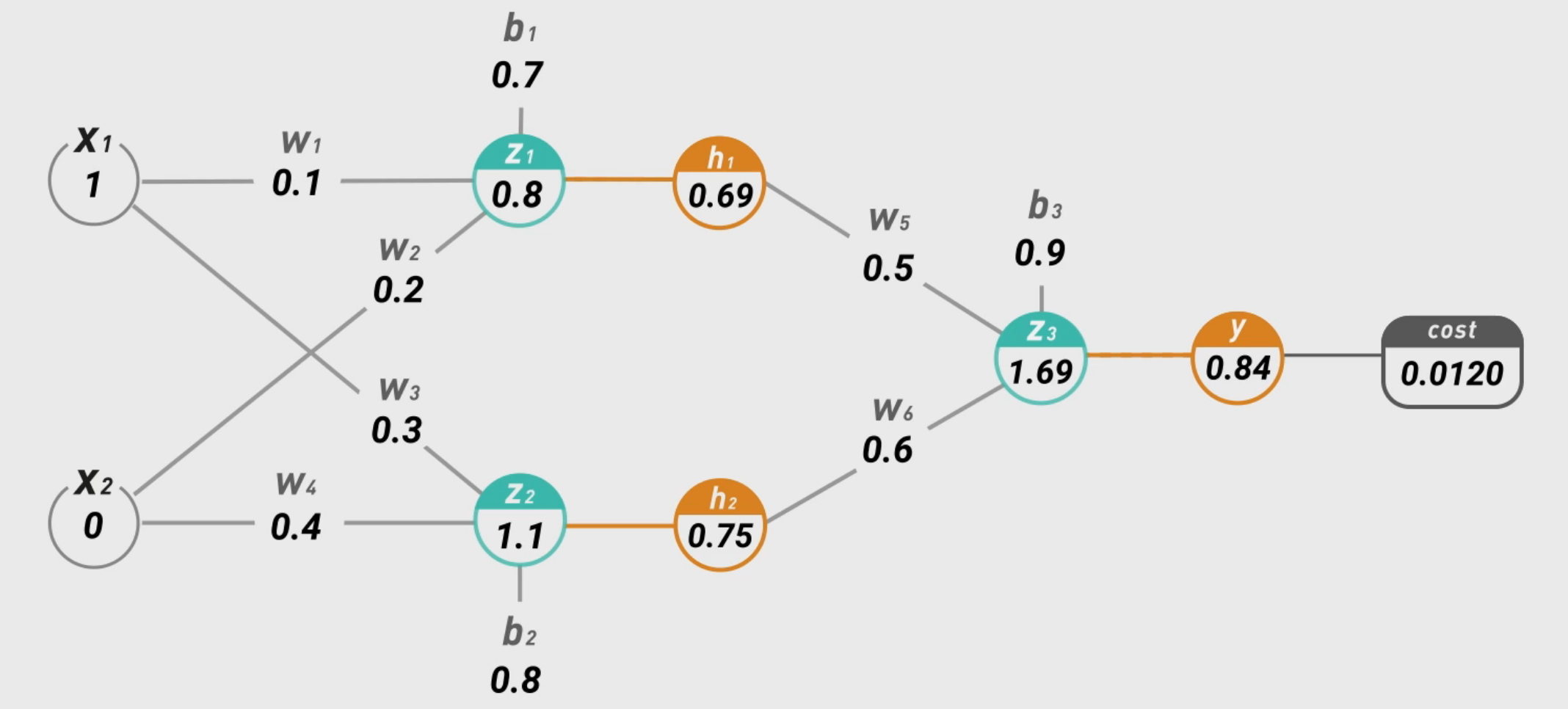
然后我们用计算出来的误差
逐项求解,
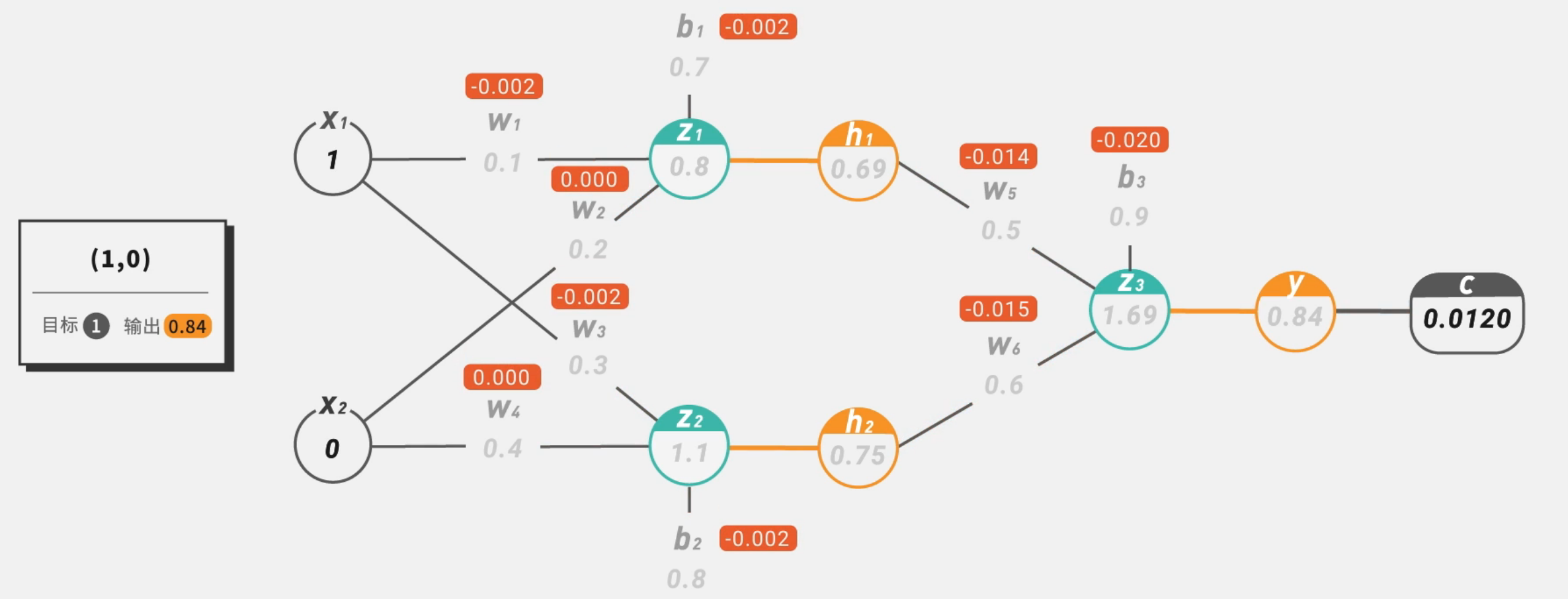
同理对于后面的参数都可以用链式求导的方式求出梯度:
求完所有的梯度后,我们就可以用和单层感知机一样的方式更新参数了。不过优化问题只是训练中的一个部分。机器学习问题之所以称为学习问题,而不是优化问题,就是因为它不仅要求数据在训练集上求得一个较小的误差,在测试集上也要表现好。因为模型最终是要部署到没有见过训练数据的真实场景。提升模型在测试集上的预测效果的主题叫做泛化(generalization),相关方法被称作正则化(regularization)。神经网络中常用的泛化技术有权重衰减等。
3.3 影响
两层神经网络在多个地方的应用说明了其效用与价值。10年前困扰神经网络界的异或问题被轻松解决。神经网络在这个时候,已经可以发力于语音识别,图像识别,自动驾驶等多个领域。 但是神经网络仍然存在若干的问题:尽管使用了BP算法,一次神经网络的训练仍然耗时太久,而且困扰训练优化的一个问题就是局部最优解问题,这使得神经网络的优化较为困难。同时,隐藏层的节点数需要调参,这使得使用不太方便,工程和研究人员对此多有抱怨。90年代中期,由Vapnik等人发明的SVM(Support Vector Machines,支持向量机)算法诞生,很快就在若干个方面体现出了对比神经网络的优势:无需调参;高效;全局最优解。基于以上种种理由,SVM迅速打败了神经网络算法成为主流。神经网络的研究再次陷入了冰河期。当时,只要你的论文中包含神经网络相关的字眼,非常容易被会议和期刊拒收,研究界那时对神经网络的不待见可想而知。
4. 深度学习
在被人摒弃的10年中,有几个学者仍然在坚持研究。这其中的棋手就是加拿大多伦多大学的Geoffery Hinton教授。2006年,Hinton在《Science》和相关期刊上发表了论文,首次提出了“深度信念网络”的概念。与传统的训练方式不同,“深度信念网络”有一个“预训练”(pre-training)的过程,这可以方便的让神经网络中的权值找到一个接近最优解的值,之后再使用“微调”(fine-tuning)技术来对整个网络进行优化训练。这两个技术的运用大幅度减少了训练多层神经网络的时间。他给多层神经网络相关的学习方法赋予了一个新名词–“深度学习”。很快,深度学习在语音识别领域暂露头角。接着,2012年,深度学习技术又在图像识别领域大展拳脚。Hinton与他的学生在ImageNet竞赛中,用多层的卷积神经网络成功地对包含一千类别的一百万张图片进行了训练,取得了分类错误率15%的好成绩,这个成绩比第二名高了近11个百分点,充分证明了多层神经网络识别效果的优越性。在这之后,关于深度神经网络的研究与应用不断涌现。
参考文献及相关资源:
一文弄懂神经网络中的反向传播法——BackPropagation
统计学习方法-李航著
机器学习-周志华著
机器学习-吴恩达
