CCS231n第一节:图像分类问题
本系列文章基于CS231n课程,记录自己的学习过程,参考视频资料为 2017年版CS231n,阅读材料为CS231n官网2022年春季课程相关材料,
本文主要介绍图片分类问题以及数据驱动的方法,同时介绍了一个简单的分类器KNN。
0 图片分类问题
图片分类问题就是辨认输入的图片类别的问题,且图片的类别属于事先给定的一个类别组中。尽管这看起来很简单,但这是计算机视觉的一个核心问题,且有很广泛的实际应用。并且,有很多的计算机视觉的问题最终会化简为图片分类问题。
举例来说,假设有一个图片分类模型,它对于输入的三通道的图片会预测其属于四个标签(label)的概率(四个标签为 cat, dog,hat,mug)。下图所示的图片是一张248像素宽度,400像素高度的图片,并且有RGB三通道,那么这张图片可以用
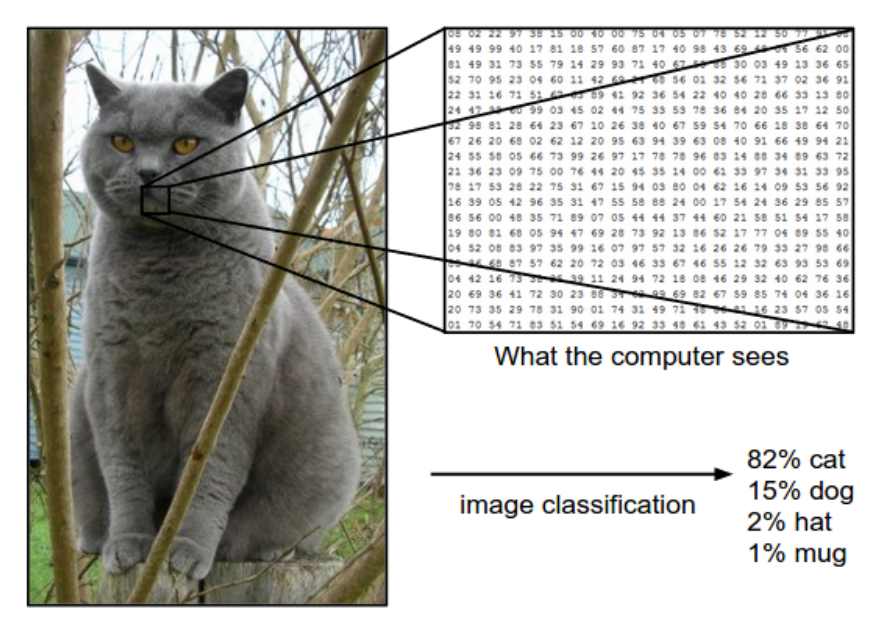
1 数据驱动方法
1.1 当前的挑战
虽然图片识别对于人来说是一件轻松的事情,但是对于计算机来说,由于接受的是一串数字,对于同一个物体,表示这个物体的数字可能会有很大的不同,所以使用算法来实现这一任务还是有很多挑战的,具体来说:
- 观察角度的变化 Viewpoint variation:一句诗可以很好概括,“不识庐山真面目,只缘身在此山中”。
- 尺度变换 Scale variation:图片大小比例的变化也会使得数据发生改变。
- 变形 Deformation:很多物体的外形不是一成不变的,比如众所周知,猫是液体。
- 遮挡 Occlusion:要被识别的物体可能被遮挡,只露出一部分。
- 光线条件 Illumination conditions:环境光线的变化对物体的图片也会有很大的影响。
- 背景干扰 Background clutter:如果物体和背景有很相似的颜色和纹路,那么就很难被识别。
- 物种变异 Intra-class variation:同一物种可能也有差异很大的形态。

1.2 数据驱动方法
那么我们如何设计算法去分辨不同的类别呢?我们不会去设计一个特定的算法来解决这样的问题,而是将大量带有标签的数据送给一个模型,让模型自己学习,这种方式就成为数据驱动方法,因为它依赖于一个带有标签的数据集合。
所以通常图片识别任务的流水线如下:
- 输入:输入
张图片,图片的总类别数量为 ,我们称这一部分的数据为训练集。 - 学习:使用模型在训练集中学习,提取每一个种类的特征。我们称之为 训练一个模型或者训练一个分类器。
- 评估:在最后,我们需要评估这个训练的模型好坏。这时需要一个之前从来都没使用过的新数据集(保证类别也在
类之中),然后在新的数据集上预测每张图片的种类,我们期望的是分类正确的图片越多越好。
2. 最近邻域分类器 NN
2.1 数据集和原理
首先我们来介绍一下最近邻域分类器,这是一个十分简单并且不常用于分类的算法,但是通过这个算法, 我们也可以大致了解解决图片分类问题的大致方法。本次使用的数据集是 CIFAR-10,这是一个有名的公开图片数据集,由60000张

现在我们的训练集中就有了50000张图片,每个类别5000张,对于测试集10000张图片中的每一张图片,我们要做的是将其与训练集中的每一张图片进行比较,然后将这种图片与训练集中最相似的图片归为一类,上图右就是部分分类后的结果,可以发现,存在很多的误分类,原因在于虽然图片的种类不同,但是两种图片的颜色图案等非常类似,就容易被归为一类。
那么在最近邻域算法中,我们衡量两张图片是否相近的标准是什么呢?一种最简单的标准就是 L1距离,假设我们将两张图片分别表示为两个向量
一个简单的计算流程演示:
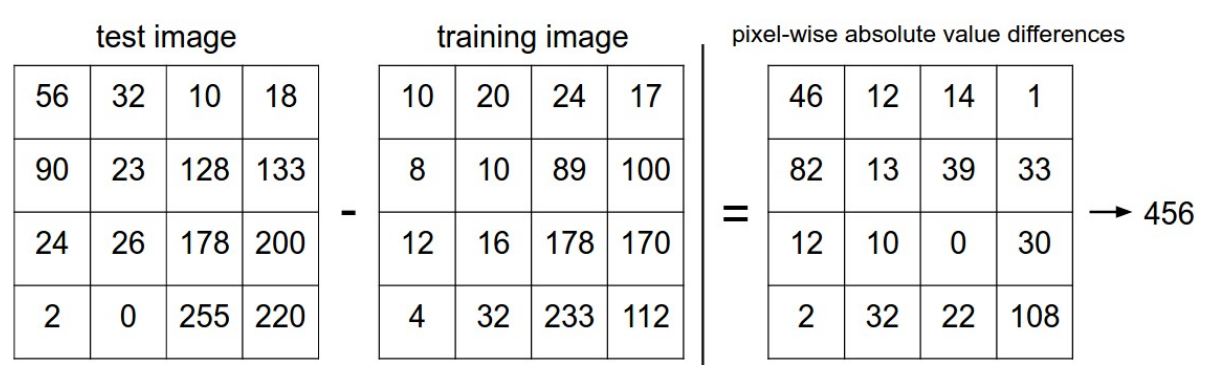
对于两种图片的衡量标准还有 L2 距离,定义如下:
2.2 代码实现
首先我们需要处理 CIFAR-10 数据集,将其以四个数组的形式表示,分别为 训练集数据、训练集标签、测试集数据、测试集标签,下面的代码中 Xtr 表示训练集数据,Ytr 表示训练集标签,得到数据后将其拉成一条向量,便于计算。
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/')
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072
下面是训练和评估模型的流程:
nn = NearestNeighbor() # create a Nearest Neighbor classifier class
nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels
Yte_predict = nn.predict(Xte_rows) # predict labels on the test images
print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )
其中,NearestNeighor 类的定义如下:
import numpy as np
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in range(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred
如果要是用 L2 距离,则只需要将距离计算公式改写为 distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))。
L1和L2距离比较: 在某一维度上,如果两个点相距较远,则L2距离比L1距离更大,若两个点相距很近,则反之,这是由于平方导致的。所以L2距离对距离差异的容忍度更差。
2.3 K-邻近邻域算法(KNN)
可以注意到,前面的最近邻域算法只关注和预测图片最相近的一张训练集中的图片,不同于最近邻域算法,KNN算法会关注与预测图片最相近的

2.4 超参数选择
所有需要我们自行选择的,而不是由算法自学习得到的参数都是超参数,比如 KNN 中
下面是选择超参数
# assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
# recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
# find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
# here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
# keep track of what works on the validation set
validation_accuracies.append((k, acc))
像 CIFAR-10 这样的数据集比较大,可以很好地划分出验证集,但是当训练集很小的时候,就不容易划分出一个验证集了,那么我们可以使用交叉验证的方法。不同于直接从训练集中拿出一部分作为验证集,交叉验证通过将训练集均分为几部分,然后每次迭代地从中选取一部分作为验证集。举例来说,假设进行5折交叉验证,即将训练集平均划分为5份,对于某个待验证的超参数,我们迭代使用其中的1份作为验证集,4份作为测试集,一共进行5次准确率的计算,将5次的结果取平均作为这个超参数的准确率。如下如所示就是一个5折交叉验证的结果,横轴为
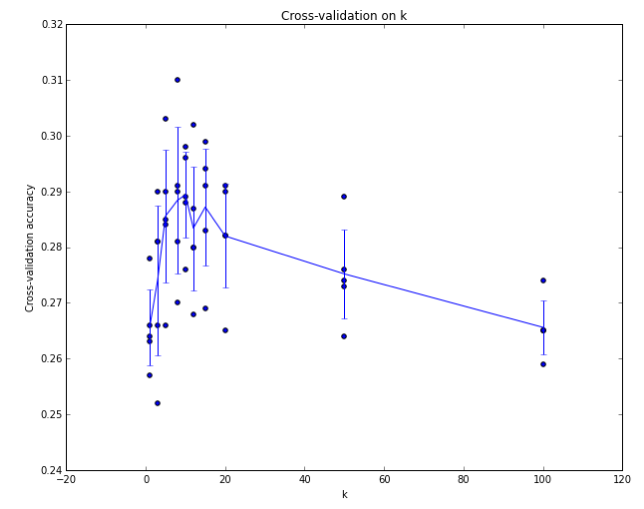
不过通常来说,在实践中我们会尽力避免使用交叉验证,因为使用交叉验证会造成很多的计算,造成性能浪费。一般我们会选择训练集的 50%-90%作为训练集,剩下作为验证集,具体的划分和选择由训练集大小以及需要验证的超参数数量决定。
2.5 KNN优缺点
KNN算法的最大优点就是实现和理解起来很简单,并且分类器无需训练时间,只需要将训练集存储下来,然后在预测的时候将待预测的图片与训练集中的图片进行比较。但这就导致了,KNN的预测时间与训练集的大小正相关,且预测时间很长。这是很不好的,我们希望的是,一个模型的训练时间可以比较长,但是训练结束后,预测的时间要尽量短,这样在实际应用中才比较方便。KNN模型有时候可能是一个好的选择,尤其是在数据维度很小的情况下,但是它也有很致命的问题。前面介绍了图片识别问题的挑战,受图片的大小、背景、光线等因素,同样一个物体可能在像素表示上大相径庭。如下图的例子,四张图片都是同一个人脸,但是每个位置的像素值完全不同,这也导致采用像素点间距离之和作为判别标准的KNN模型变得十分不准确。换一个角度,除了对于同一个物体可能会分辨错误,对于不同的物体KNN也可能将其归为一类,因为KNN认为这些图片在像素上是十分相近的,但是在语义上,这些图片可能完全不同。


您好,请问可以分享一下完整的代码吗?小白连下载好的数据集怎么使用都不会。
时间太久了 找不到啦 抱歉~
可以交流一下吗?
太棒了,光看课有点迷糊,看这个博客让我的思路更加清晰,对学习帮助很大,希望多多更新
谢谢
你好,请问一下你这个是静态网站吗,hexo + github搭建的?我也想搭建一个自己的博客,在纠结搞静态还是动态,求大佬给点指点
阿里云+WordPress+Argon主题
好的,谢谢
你好,博主,请问你搭建这个网站用的服务器配置是啥样的呢?
阿里云1核1G内存
写得太好了,省了很多整理的时间,谢谢您!!
本科的时候在看学长整理的各种复习,读研了被分到cv了,又来看了哈哈哈
感恩博主