CS231n第四节:反向传播
本系列文章基于CS231n课程,记录自己的学习过程,所用视频资料为 2017年版CS231n,阅读材料为CS231n官网2022年春季课程相关材料
本文将介绍反向传播,一种递归应用链式法则的求解梯度的方法。理解这一过程的精妙之处对于设计、构建和调试神经网络十分重要。
1.背景介绍
本文解决的主要问题就是对函数进行求偏导,具体来说就是给出一些函数
2. 链式求导法则
对于简单的函数求偏导是十分轻松的,比如下面的偏导计算:
对哪个变量求偏导就是将其看成自变量,其他的看成常数即可。但是对于一个复合函数如果比较复杂就很难直接求得关于某个变量的偏导数。比如这样一个例子:
# set some inputs
x = -2; y = 5; z = -4
# perform the forward pass
q = x + y # q becomes 3
f = q * z # f becomes -12
# perform the backward pass (backpropagation) in reverse order:
# first backprop through f = q * z
dfdz = q # df/dz = q, so gradient on z becomes 3
dfdq = z # df/dq = z, so gradient on q becomes -4
dqdx = 1.0
dqdy = 1.0
# now backprop through q = x + y
dfdx = dfdq * dqdx # The multiplication here is the chain rule!
dfdy = dfdq * dqdy
上述过程可以用计算图可视化展示出来:

图中绿色的数字表示前向传播计算输出。红色的数字表示反向传播,从右往左逐一计算每个变量关于
其中先计算 * 节点下,然后计算 + 节点下。
然后计算 + 节点处进行计算,首先计算局部导数 -4 (即从前一节点计算得来的梯度,这里就是+节点下所记录的梯度)相乘得到结果,记录在 x 下。其余节点的计算过程相似。
涉及的两个概念:
- Local gradient 局部梯度: 即某个节点的输出关于其输入的梯度。
- Upstream gradient 上游梯度:即最终结果关于当前节点的输出的梯度。
3. 反向传播的直观理解
上文的计算图实际上就可视化展示了反向传播的一个过程,可以发现,反向传播就是一个局部进行的过程。每一个节点(或者称为门gate)得到一些输入,然后会自动地计算出他们的输出,这些输出或许又会成为其他节点的输入,同时他们可以很轻松地计算出他们的局部梯度,即他们的输出关于输入的偏导数。所有的节点执行这些操作无需知晓整个过程的细节,只需要关注自身。当 输出 和 局部梯度 计算完成后,就可以进行反向传播了。递归地应用链式法则,反向传播使得节点可以得到最终输出关于该节点输入变量的偏导数,只需要将局部梯度和上游梯度(即最终输出关于该节点输出的偏导数)相乘即可。
换一个角度理解这一过程,假设有一个加法门(之所以称为门是因为节点接受一个输入给出一个输出,就好像经过一道门一样,其实就是运算图上的一个节点)收到输入
我们继续进行反向传播,将上游梯度和局部梯度相乘,得到最终结果关于加法门的输入的梯度,由于局部梯度为1,所以得到的结果仍然为-4,这说明,如果
由此可见,反向传播可以看成门之间的通信,其通信媒介就是梯度,通信内容就是门的输出对最终结果的影响(正相关还是负相关,以及影响的力度)。
4. 常见运算对梯度的影响
在神经网络中比较常见的运算有加法、乘法和max,这些运算与梯度有什么关系呢,以下面的例子来说明:
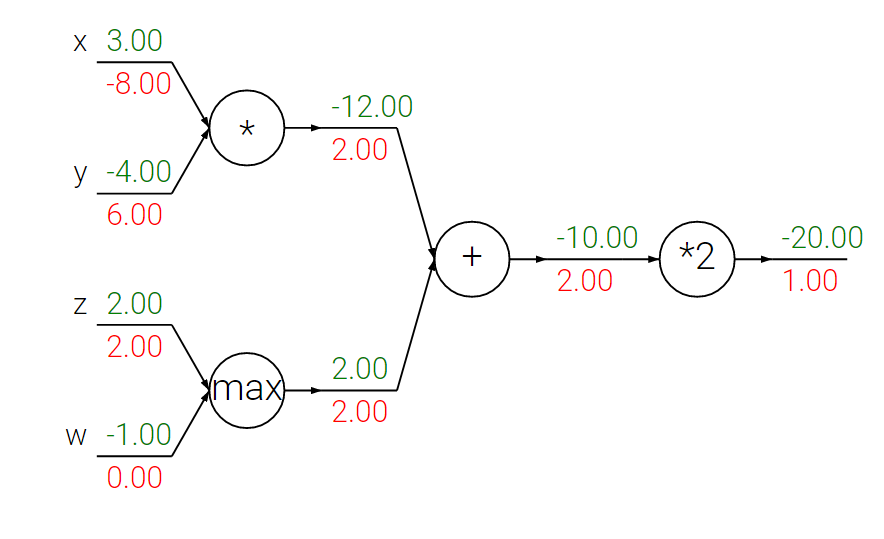
从图中我们可以发现,在反向传播的过程中,每个运算实际是将输出处的梯度以一定的规律分配给输入端:
-
加法:
将输出端的梯度等价地分配给输入端,并且与输入端的数值大小无关。其原因是,加法运算的局部梯度为1,所以所有输入端的梯度就是将输出端的梯度和1相乘,自然是相等的。
-
max操作:
max操作就像一个路由器,将梯度路由给值较大的输入,例如上图中的
z的值大于w,所以将max门的输出端的梯度2.00分配给z下方,而w下方就为0,这也和max函数的性质相关。 -
乘法:
乘法运算对梯度的分配稍微复杂一点,它是将输出端的梯度和另外一个输入的值相乘作为当前输入的梯度,例如
x的梯度就是y = -4和 输出端的梯度2相乘得到的结果,可以看成一个梯度的交换器。值得注意的是,当输入的值一个非常大,而另外一个非常小的时候,乘法会将一个很大的梯度分配给小的输入,而将一个很小的梯度分配给大的输入。这就说明,输入值的量级会影响到梯度的大小。这就是为什么需要进行归一化的原因,如果输入数据量级差异太大,就会导致梯度相差很大。还有一个值得注意的点在于,如果在预处理的时候将输入全部都增大的1000倍,那么梯度也会增大1000倍,那么学习率就需要相应地变小来抵消。

好!!!!
谢谢~
计算图我这边无法展示,文章有点看不懂
+1
图片没上传,本地也弄丢了,没办法了
写得太好啦 就是第一个图加载不出来耶