CS231n第三节:优化器
本系列文章基于CS231n课程,记录自己的学习过程,所用视频资料为 2017年版CS231n,阅读材料为CS231n官网2022年春季课程相关材料
上一节介绍了图像识别任务的两个关键组成部分:
- 参数化的评估函数,通过赋予权值参数的方式将原始图片的像素映射成每个类别的得分
- 损失函数,用于衡量使用特定参数的评估函数的好坏,衡量标准是该评估函数在训练集中对真实样本值的预测能力。
因此,如果一组参数的预测结果和真标签值相符合,那么它的损失值就会很小。下面将介绍图像识别任务的最后一个关键组成部分,优化器。优化器用于寻找一组参数使得损失函数值最小化。
1. 损失函数可视化
损失函数通常会被定义在一个很高纬度的空间中(比如CIFAR-10数据集下的线性分类器,参数矩阵的大小为
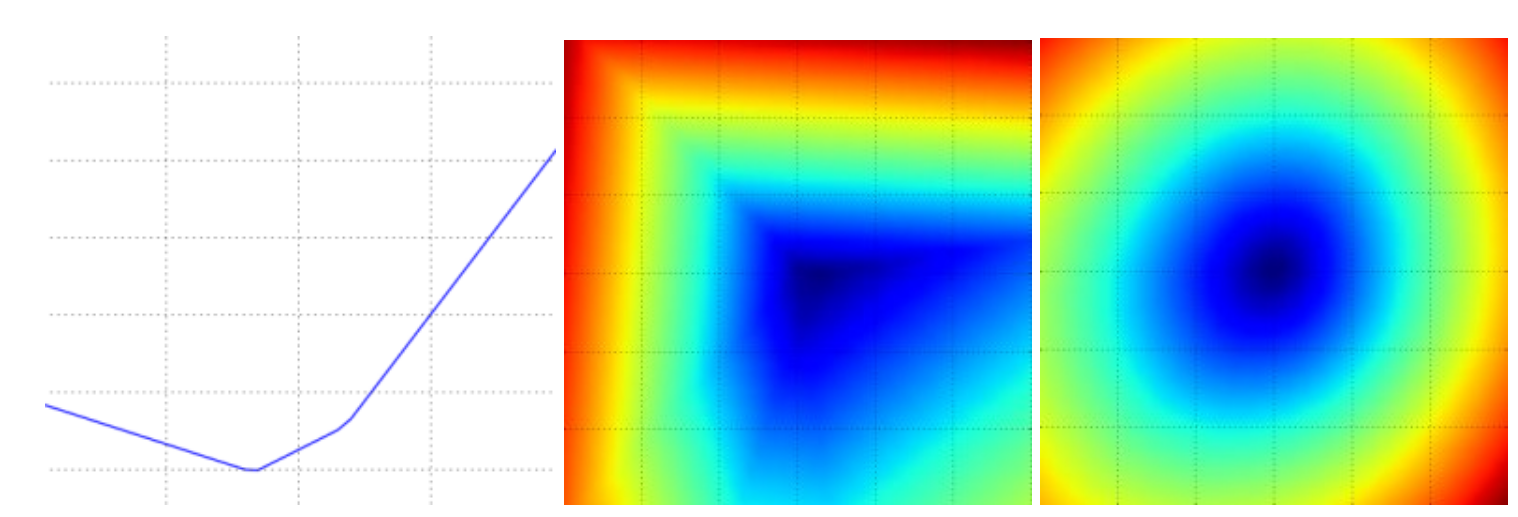
如下图所示是SVM损失函数的可视化结果,左图表示沿一个方向的可视化结果,y轴表示损失值的高低。中图和右图表示选择两个方向的可视化效果,颜色表示损失值的高低(蓝色表示损失值低,红色表示损失值高)。其中,中间的图表示对于一个样本的损失值可视化结果,右图表示对于100个样本取平均的可视化结果。从图中我们可以看出,损失函数是一个分段线性的结构,而右图之所以是圆滑的碗状是因为这是很多个分段线性结构取平均后的结果。
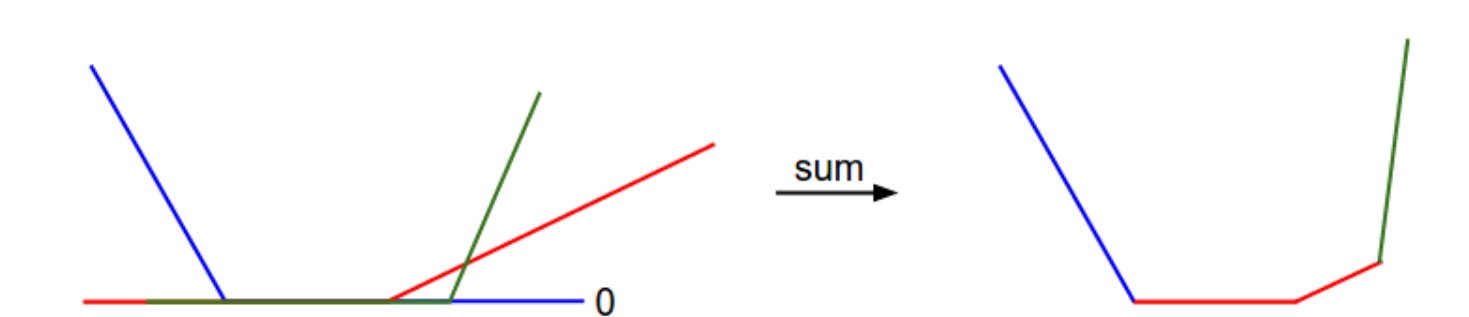
我们可以分析一下为什么损失函数是一个分段线性的结构,对于某个样本数据
即,损失值是多项之和,每一项的值都独立于特定的权重参数,或者是其线性函数(负数时函数值为0),如下图所示,就是对于单个权重的损失函数图像,x轴表示权值,y轴表示损失值,求和的效果就是一个分段的线性结构。而对于一个完整的SVM数据损失值(在CIFAR-10数据集上),就是一个30730维度的版本。
从损失函数的碗状图像可以猜到,SVM的损失图像是一个凸函数,凸函数的优化方法有很多。但是当我们将评价函数拓展到神经网络中后,其可视化图像就变成一个复杂,凹凸不平的形状了。
2. 优化器
再次说明,损失函数使得我们能够量化任意一组权值的质量。优化器的目标是找到一组权重,使得最小化损失函数值。虽然我们后面介绍优化器时使用的例子是一个凸优化问题(SVM损失函数),但需要注意的是,我们的最终目标是找到一个优化方法可以用于神经网络(神经网络中很难使用凸优化的技巧)。
2.1 随机搜索
由于验证某个参数是否足够优秀是很方便的一件事情,所以第一种很容易想到的策略就是我们随机生成一些权重,然后量化其好坏,保留最优的。代码如下:
# assume X_train is the data where each column is an example (e.g. 3073 x 50,000)
# assume Y_train are the labels (e.g. 1D array of 50,000)
# assume the function L evaluates the loss function
bestloss = float("inf") # Python assigns the highest possible float value
for num in range(1000):
W = np.random.randn(10, 3073) * 0.0001 # generate random parameters
loss = L(X_train, Y_train, W) # get the loss over the entire training set
if loss < bestloss: # keep track of the best solution
bestloss = loss
bestW = W
print 'in attempt %d the loss was %f, best %f' % (num, loss, bestloss)
# prints:
# in attempt 0 the loss was 9.401632, best 9.401632
# in attempt 1 the loss was 8.959668, best 8.959668
# in attempt 2 the loss was 9.044034, best 8.959668
# in attempt 3 the loss was 9.278948, best 8.959668
# in attempt 4 the loss was 8.857370, best 8.857370
# in attempt 5 the loss was 8.943151, best 8.857370
# in attempt 6 the loss was 8.605604, best 8.605604
# ... (trunctated: continues for 1000 lines)
从代码的输出结果可以看到,有一些随机的权重
# Assume X_test is [3073 x 10000], Y_test [10000 x 1]
scores = Wbest.dot(Xte_cols) # 10 x 10000, the class scores for all test examples
# find the index with max score in each column (the predicted class)
Yte_predict = np.argmax(scores, axis = 0)
# and calculate accuracy (fraction of predictions that are correct)
np.mean(Yte_predict == Yte)
# returns 0.1555
得到其准确率为15.5%,随机猜测图片属于哪种类别的准确率为10%,可以发现这种无脑随机的搜索方法比胡乱猜测是要好的。
虽然这是一种很愚蠢的优化策略,但其中也有一个重要的思想:迭代寻优。直接寻找一个最优解是基本不可能的一件事情,但是如果我们首先随机选取一个初始值,然后逐步地去优化,使得权重每次都稍微进步一点,这样最终就会逼近最优解。随机搜索就像是一个人蒙住双眼在一个山地中,企图走到山谷最低处。
2.2 随机局部搜索
此外,我们可以在局部采用随机搜索的方式,具体来说就是我们从一个随机的
W = np.random.randn(10, 3073) * 0.001 # generate random starting W
bestloss = float("inf")
for i in range(1000):
step_size = 0.0001
Wtry = W + np.random.randn(10, 3073) * step_size
loss = L(Xtr_cols, Ytr, Wtry)
if loss < bestloss:
W = Wtry
bestloss = loss
print 'iter %d loss is %f' % (i, bestloss)
使用这种方法在测试集上的准确率为21.4%,这有所改进,但是对于性能的浪费是巨大的。
2.3 跟随梯度
上一种方法中,我们使用随机搜索的方法去寻找可能的优化方向,但是其实我们有很好的方法去寻找最优的前进方向,我们可以直接计算出当前最优的方向。即计算出一个向量,保证在数学上朝着这个方向是当前下降最快的。这一向量称作损失函数的梯度。类比下山,跟随梯度下降的方法就类似我们通过感受我们脚下地势的斜率,然后朝着下降最快的方向前进一样。对于一个一维的函数,梯度就是其斜率,而对于一个多维的函数,梯度是一个向量,每一维度就是对应属性在多维函数中的偏导数。
3. 计算梯度
有两种计算梯度的方法:
- 数值梯度:比较慢,且是一个近似值,但是比较简单
- 解析梯度:快速精确但是由于需要推导分析,所以容易出错
3.1 使用有限差分计算梯度
对于一个一维的函数,梯度计算公式为:
使用这个公式,我们就可以用有限差分的方法计算梯度了,具体的方法就是选取一个微小的
其中 f 表示需要计算梯度的函数, x 表示输入的向量。
def eval_numerical_gradient(f, x):
"""
a naive implementation of numerical gradient of f at x
- f should be a function that takes a single argument
- x is the point (numpy array) to evaluate the gradient at
"""
fx = f(x) # evaluate function value at original point
grad = np.zeros(x.shape)
h = 0.00001
# iterate over all indexes in x
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
# evaluate function at x+h
ix = it.multi_index
old_value = x[ix]
x[ix] = old_value + h # increment by h
fxh = f(x) # evalute f(x + h)
x[ix] = old_value # restore to previous value (very important!)
# compute the partial derivative
grad[ix] = (fxh - fx) / h # the slope
it.iternext() # step to next dimension
return grad
在代码中通过微小的改变 h ,我们可以逐一计算出每一维度的梯度,最终返回梯度向量 grad 。
实际应用中需要注意的问题:
在梯度的数学公式中,
使用上文的梯度计算公式,我们可以计算任意一点在任意一个函数中的梯度,于是我们可以使用该函数来计算在CIFAR-10中某些随机点关于损失函数的梯度。代码如下:
# to use the generic code above we want a function that takes a single argument
# (the weights in our case) so we close over X_train and Y_train
def CIFAR10_loss_fun(W):
return L(X_train, Y_train, W)
W = np.random.rand(10, 3073) * 0.001 # random weight vector
df = eval_numerical_gradient(CIFAR10_loss_fun, W) # get the gradient
梯度告诉了我们当前点在损失函数中下降最快的方向,使用我们可以使用这一信息来更新参数:
loss_original = CIFAR10_loss_fun(W) # the original loss
print 'original loss: %f' % (loss_original, )
# lets see the effect of multiple step sizes
for step_size_log in [-10, -9, -8, -7, -6, -5,-4,-3,-2,-1]:
step_size = 10 ** step_size_log
W_new = W - step_size * df # new position in the weight space
loss_new = CIFAR10_loss_fun(W_new)
print 'for step size %f new loss: %f' % (step_size, loss_new)
# prints:
# original loss: 2.200718
# for step size 1.000000e-10 new loss: 2.200652
# for step size 1.000000e-09 new loss: 2.200057
# for step size 1.000000e-08 new loss: 2.194116
# for step size 1.000000e-07 new loss: 2.135493
# for step size 1.000000e-06 new loss: 1.647802
# for step size 1.000000e-05 new loss: 2.844355
# for step size 1.000000e-04 new loss: 25.558142
# for step size 1.000000e-03 new loss: 254.086573
# for step size 1.000000e-02 new loss: 2539.370888
# for step size 1.000000e-01 new loss: 25392.214036
梯度告诉了我们下降最快的方向,但是没有告诉我们需要朝这个方向前进多少,上文代码中 step_size 表示的就是一次更新所前进的步长,也称之为学习率。如果 step_size 太小,那么每次进步的幅度就太小,而如果太大,从代码的输出结果也可以看出,损失值不降反增,这就是前进过头了。
效率问题: 使用有限差分的数值梯度有一个问题就是对于每个参数每次迭代都需要计算一次梯度,如果参数非常多那么训练效率就会非常低,很显然我们需要一种更好的策略。
3.2 用微积分来计算梯度
数值梯度使用有限差近似非常易于计算,但缺点是它是近似值(因为我们必须选择较小的
使用单个数据点的SVM损失函数为例:
我们可以给出
即所有超出安全间隔的种类的个数乘上输入的
观察可以发现真实标签对应的权重和其他权重的梯度是不同的,其本质就是求偏导, 在损失函数的求和中每一项都包含
4. 梯度下降法
现在,我们可以计算损失函数的梯度,重复评估梯度然后执行参数更新的过程称为梯度下降。原始版本的梯度下降如下所示:
# Vanilla Gradient Descent
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - step_size * weights_grad # perform parameter update
这个简单的循环是所有神经网络的核心,虽然还有很多其他优化的方法,但是梯度下降是目前最常用的方法。后面的课程中,随着神经网络的介绍,会在上述的循环中增加一些东西,但是跟随梯度变化的想法一直保持。
小批量梯度下降(mini-batch gradient descent):
当梯度下降应用在大尺度的任务中时,训练集可能有上百万个样本,因此计算损失函数同时计算出梯度并更新的操作需要针对整个训练集,这是十分浪费并且有时候是无法实现的(如果内存太小就会存不下所有样本)。一个常用的方法是将训练集随机划分为多个小批次,每次只对这一个批次的样本进行计算损失值以及梯度,然后用这个梯度进行更新参数,代码如下:
# Vanilla Minibatch Gradient Descent
while True:
data_batch = sample_training_data(data, 256) # sample 256 examples
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += - step_size * weights_grad # perform parameter update
这样的做法之所以可行是因为,训练集中的样本之间是有一定的关联性的。通过评估小批度样本的梯度以执行更频繁的参数更新,可以在实践中实现更快的收敛速度。有一种极端情况就是,一个小批度只包含一个样本,这种方法称为随机梯度下降法Stochastic Gradient Descent (SGD),或者有时候也称为在线梯度下降法。值得注意的是,很多情况下虽然人们使用SGD这个词,但实际他们指代的是小批量梯度下降(mini-batch gradient descent)。每个批度的大小也是个超参数,但一般不会去进行交叉验证,这通常取决于内存的大小,或者将其设置成 2 的幂,这是由于使用2的幂会加快计算机矢量处理的速度。
