
本文为 CVPR 2022 Tutorial Deep Visual Similarity and Metric Learning 的个人笔记
1. Introduction
1.1 CV的宏图
在最开始,先介绍一下机器学习在CV领域的宏大目标是什么。机器学习的目标显然是为了解决某个任务,比较常见的有分类和回归两类。但这只能算是一个很小的目标,对于计算机视觉来说,使用某个模型来学习整个世界(特别是视觉上的世界)的特征(representation)算是一个比较大的目标。但这仍然不够宏大,因为我们还遗漏了不同物体之间的语义关联(semantic interdependence)。
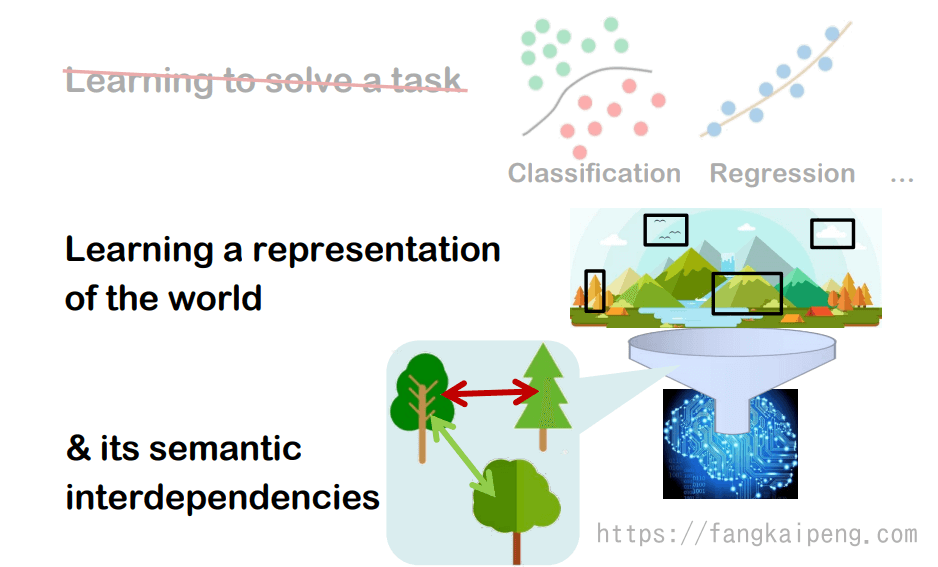
相关应用:
经过一段时间的发展,计算机视觉有很多方面的应用,比如基于最邻近方法的分类、密度估计、检索任务;聚类任务;数据可视化任务。
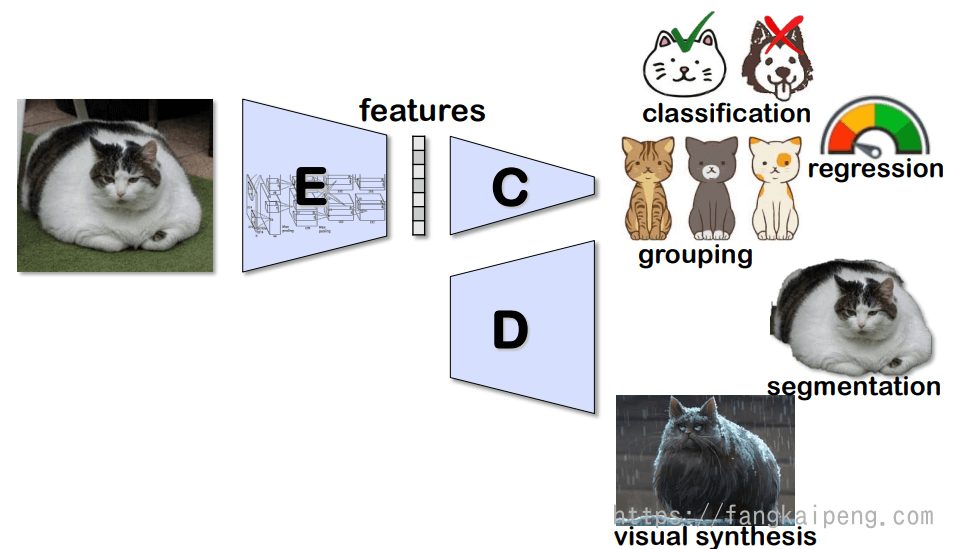
对于上述的这些应用,都需要将图片映射成特征(embedding aka features)才能进行。因为这些特征相比原始图片,具有更加丰富和紧凑的语义信息,除了将图片降维得到特征,来进行一系列的分类、回归、聚类的任务,也可以将特征重新升维,来实现分割和视觉生成的一些任务。
When you have difficulty in classification, do not look for ever more esoteric mathematical tricks, instead, find better features. –B.P.K Horn: Robot Vision, 1986
1.2 主要的挑战
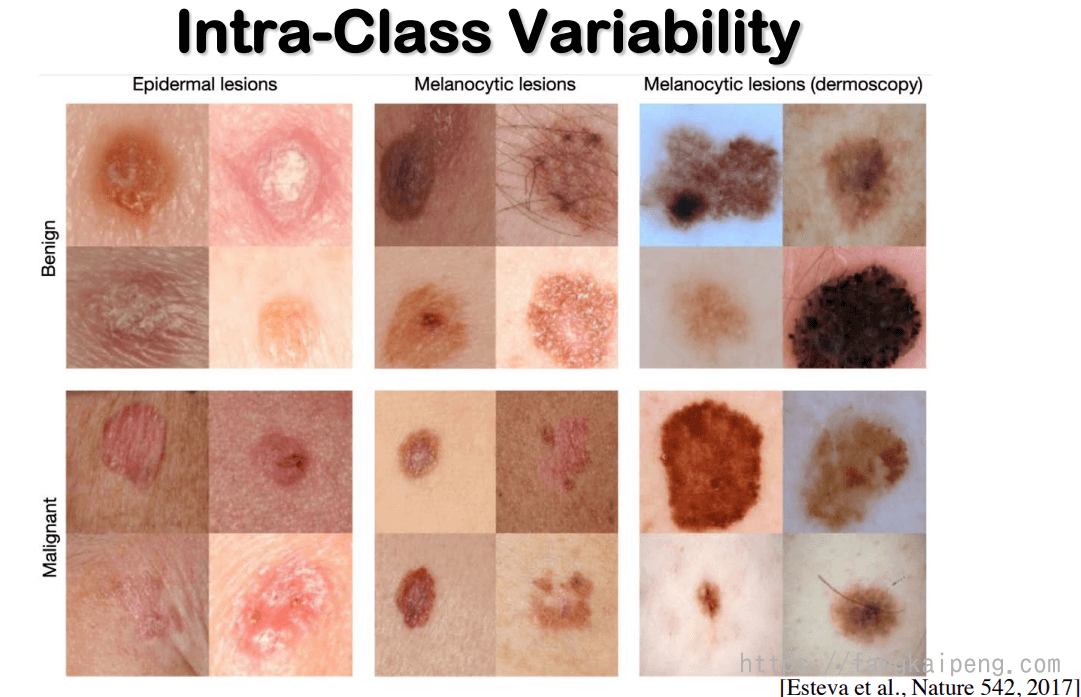
如何获得更好的特征是我们目前面临的主要挑战,因为现实世界中,同一类物体也有很多的变化,比如下图的两种不同皮肤病变,相同类间也有很多变化。
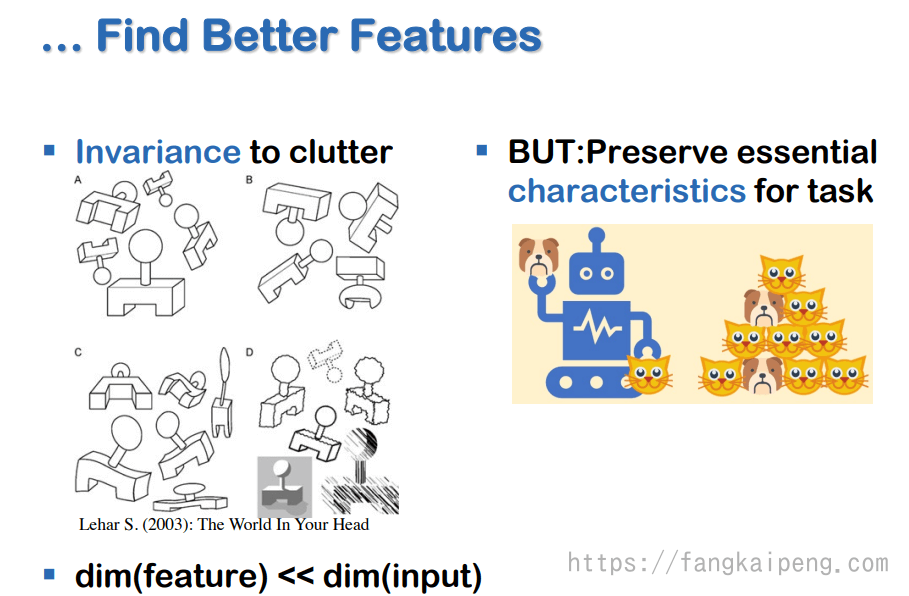
所以,我们既要对同类物体的杂乱变动保持不变形,这可以通过舍弃一些不必要的特征来实现。同时,也要保留必要的特征保证能够很好地完成任务。所以,如何很好的平衡特征的舍弃和保留,是十分具有挑战性的。此外,一般我们的特征维度都是远远小于图片大小的,这样具有正则化的效果,可以使得模型具有很好的泛化性能。
如下图是一个关于狼的分类器,输入一张狼的图片,分类器将原始像素映射到中间的隐式空间中(黄色向量),最终分类器可以很好地预测出它是狼。网络最后一层的输出特征具有很好的不变性(invariance),因为对于狼这一个物种图片的不同采样,最终都能得到相同的特征向量。该分类器是由可逆神经网络(INN)训练得到的,所以可以很方便地将这些中间特征重构成图片(如下图)。可以看到,随着网络越深,重构特征得到的图片更具有多样性,这就说明,随着网络的加深,将会舍弃掉一些细节特征,保留更加典型的特征。即越深的网络得到的特征,具有更好的不变性。

1.3 Metric Learning 度量学习
现在,我们再来考虑一个二分类任务:如下图左,有一堆人脸图片,训练一个分类器区分男性和女性。这是一个很简单的分类任务,可以很好地使用神经网络将每张图片都投影到一个高维空间中,然后再轻松地将其区分开来(如下图右所示)。
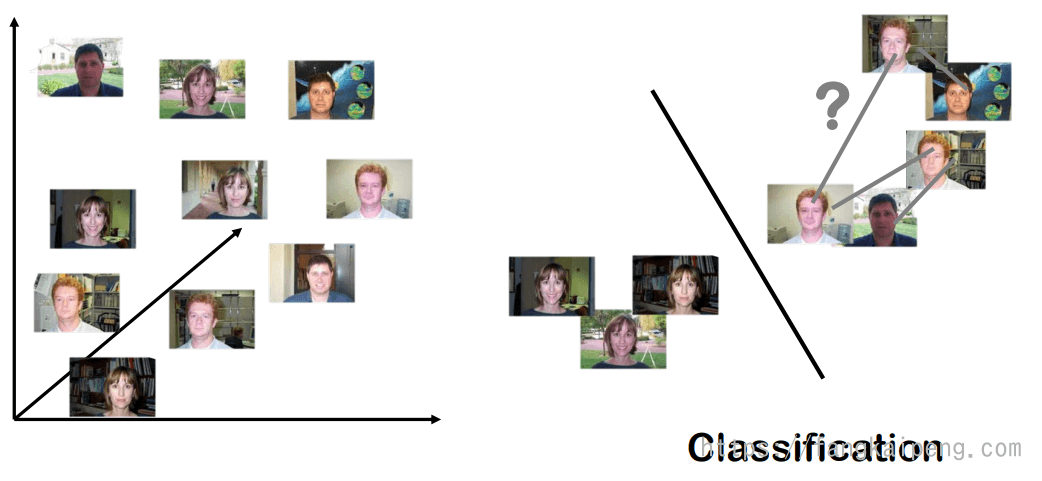
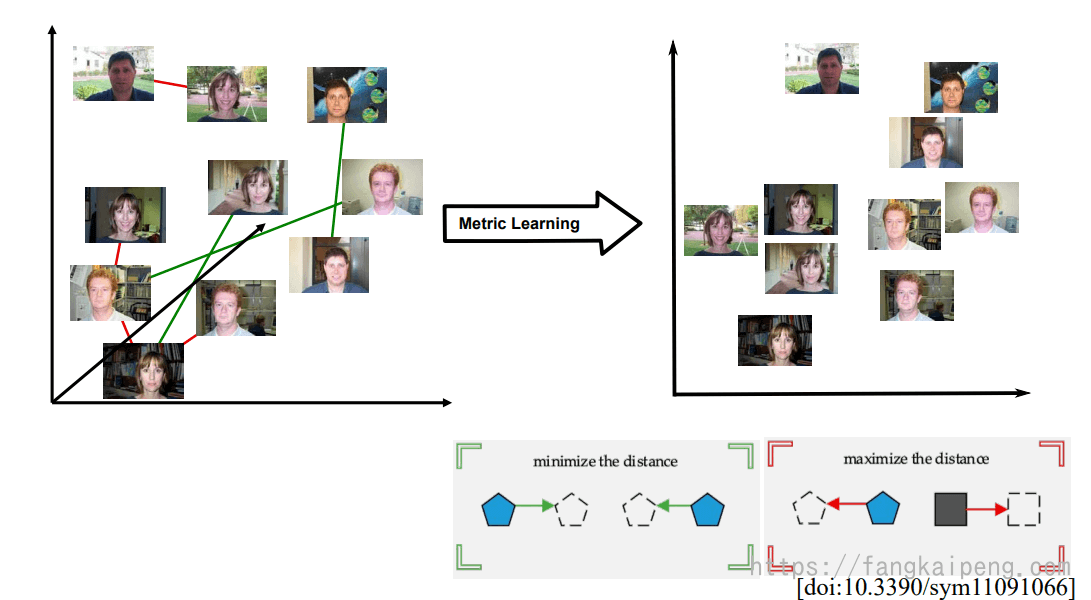
但是,对于上图右边的空间中,虽然能够很好地区分男性和女性,但如果我们想得到更加丰富和细粒度的结构呢?比如我们可以看到上面的男性图片中,有几张图片为同一个人的不同角度,那么我们能否也将同类之间的语义信息保留下来呢。这就是Metric learning(度量学习)所关注的内容。假设,我们给定了一些正约束和一些负约束来定义图片之间的相似性,那么我们所希望的就是减小相似图片之间的距离,增加不同图片之间的距离,其效果如下图右所示。可以看到,经过metric learning后,男性和女性之间的距离被拉开,同时,同一个人之间的距离被拉近,同一性别中不同人的距离也相对来说被拉开。
当然,对于相似度,也存在很多不同的衡量标准,比如颜色,视角,类别,通常来说,类别是比较典型的衡量标准。

总结一下,Metric Learning的目的是:学习每个数据之间的语义联系,实现这一目的的一种思路是,学习一种映射,使得我们将不同数据的语义关系,映射成一种度量(Metric)的距离,如下图,可以通过学习一种映射,将
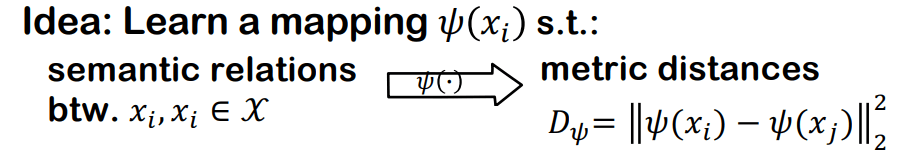
对于我们定义的度量 Metric ,还需要满足一些数学公理(非负、等价、对称、次加性):
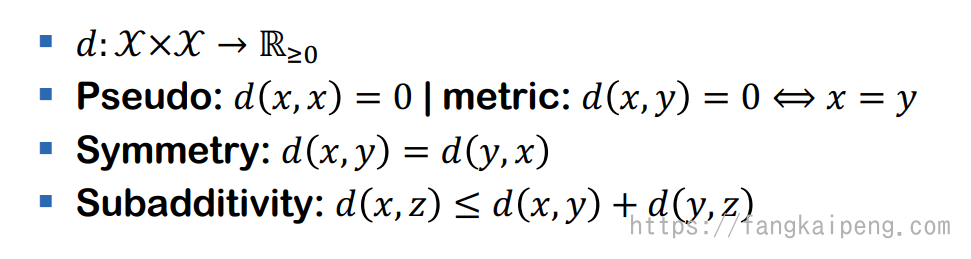
以下是Metric Learning目前的一些研究方向:

1.4 线性度量学习
可以使用马氏距离作为我们的度量,实际上就是对原始数据进行了一个线性变换。但是这样的方法有两个挑战:
是半正定矩阵,计算复杂度为 的秩要求小于 ,以及 的正则化是一个NP-hard的问题
可选的解决方案:不适用半正定矩阵,使用双线性映射
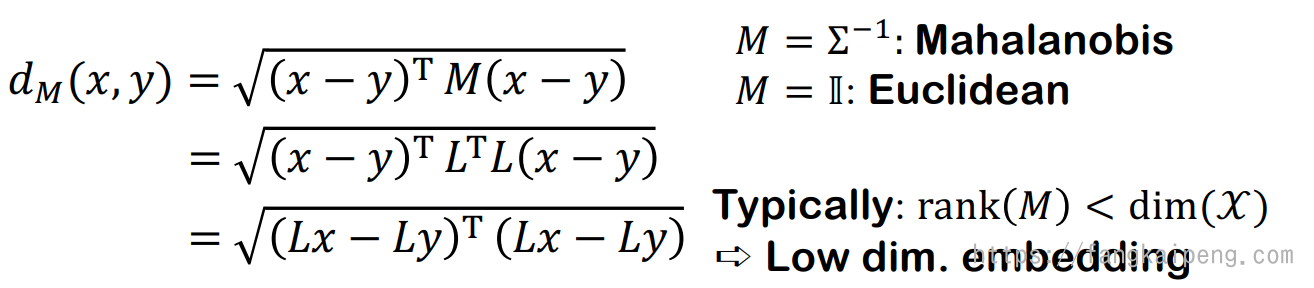
线性的方式具有很好的凸性和鲁棒性,不容易过拟合。那么,如果要表示一个非线性的结构或特征,目前的第一种方法就是使用核函数,将数据映射到一个高维空间中,类似SVM的做法。但是,这种做法需要
1.5 DMP 深度度量学习
线性度量学习有很多的限制和不足,那么很自然的就能想到,我们可以先自定义一个度量空间(比如下图的以L2距离为衡量标准的空间),然后用一个神经网络提取数据的特征,并映射到这个度量空间中。这就是 Deep Metric Learning 深度度量学习。

简单来说,DMP的大致流程如下:
-
选择一个参数化的embedding space(某个神经网络)
-
为这个空间选择一个距离度量标准
,比如L2距离: -
收集数据
,同时进行相似性判断(similarity judgements): 
-
优化embedding space的参数
,使得特征空间可以完美符合之前定义的相似性判断标准,即 ,损失值+正则项。

损失函数/目标函数:
-
Ranking-based
-
Contrastive w/ margin
-
Multi-similarity loss
-
-
Proxy-based(基于代理的,与某个代理比较)
-
ProxyNCA
-
-
Classification-based

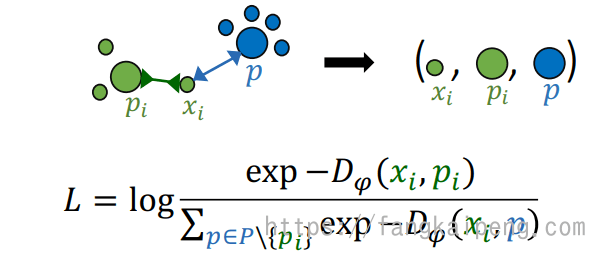
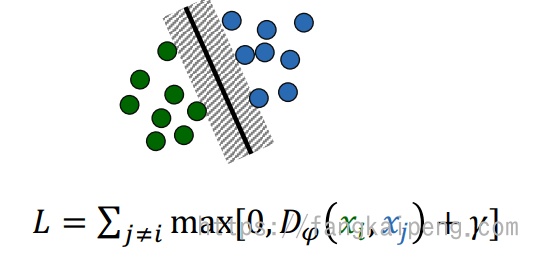
数据采样问题:
如果我们需要衡量三者(Anchor、Positive、Negative)的关系作为Loss,那么数据中一共有
- Local (mini-batch) vs. global mining
- (Semi-)Hard-negatives
- Hardness-aware
- Easy positives
- Adversarial negative synth.
集成学习:是的,度量学习也可以使用集成学习的方法,将多个embedding结合起来一起学习。
泛化: 之前我们都是假设数据来自同一个分布的,那么如果测试数据来自不同的分布呢?

1.6 总结

2. DML的目标函数
Deep Metric Learning的目标是学习一个映射关系,将输入数据映射到另外一个空间中,在这个空间中可以反映在

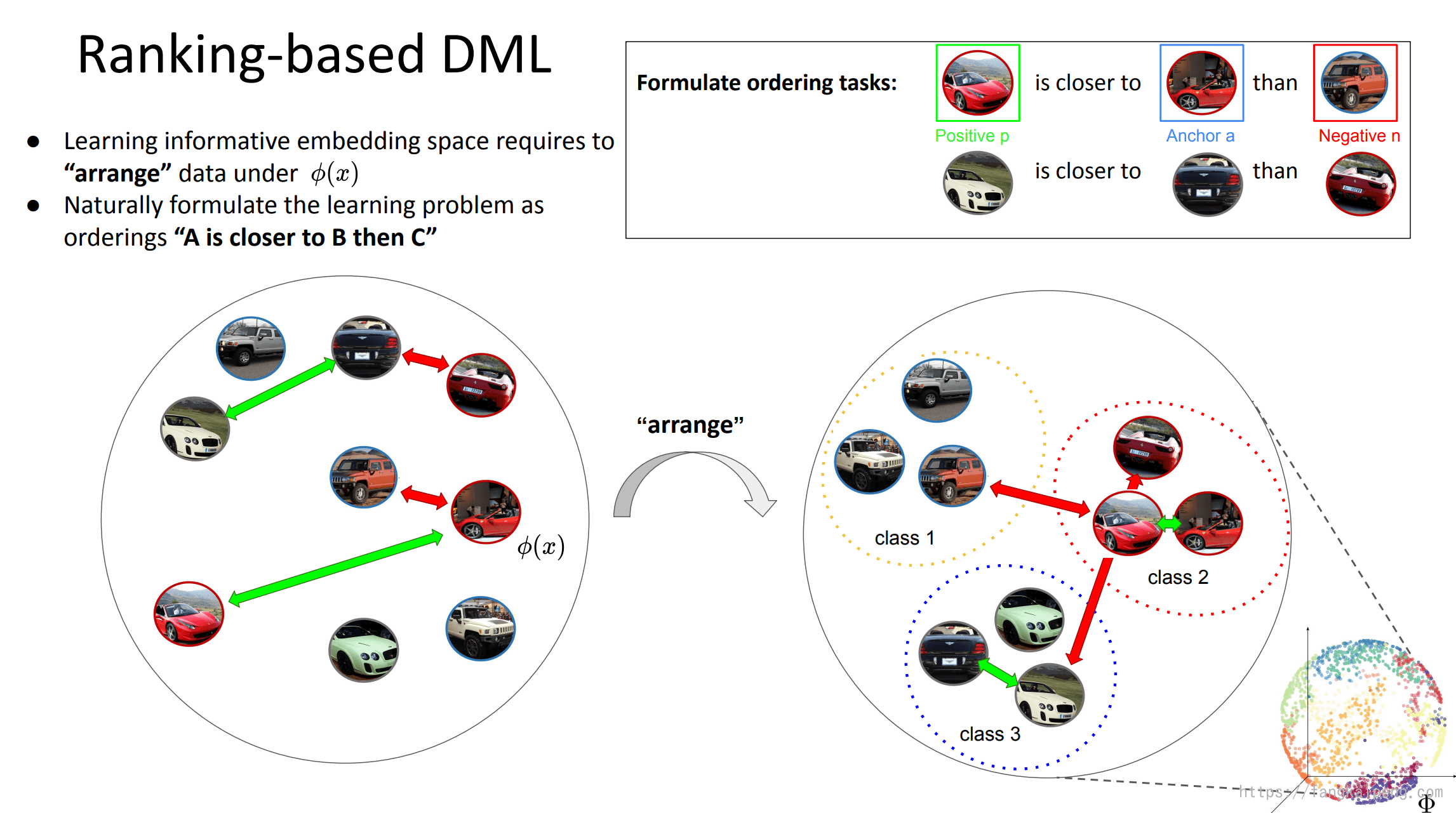
2.1 Ranking-based DML
学习一个特征空间,以此来调整数据之间的位置关系,一种最自然的做法就是将问题公式化为:“A 比 C 更靠近 B”,也就出现了 triple loss 三元组损失。它的基本思想是:对于设定的三元组(Anchor, Positive, Negative) (Anchor和Positive为同类的不同样本,Anchor与Negative为异类样本),Triplet loss试图学习到一个特征空间,使得在该空间中相同类别的基准样本(Anchor)与 正样本(Positive)距离更近,不同类别的 Anchor 与负样本(Negative)距离更远。
最常见的三元组损失
前一半表示基准样本和正样本之间的距离,后一半表示基准样本和负样本之间的距离,当基准和正样本越近,和负样本越远时,loss越小。
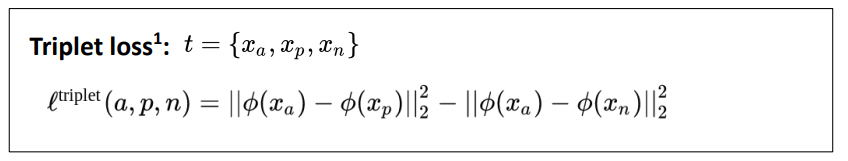
加入margin后的三元组损失:
加入margin有两个好处,首先可以使得模型不会“偷懒”,因为原来的三元组损失函数,会使得模型可能将正负样本都朝着基准样本靠近,这样距离都为0,loss也很小,但是不能达到区分的效果。其二,使用margin可以使得当负样本和基准的距离大于margin后就不在优化,让模型去更加关注那些距离小于margin的负样本,以此达到更好的效果。

Margin loss:
它除了有固定的margin

Lifted Structures Feature Embedding Loss
上述的Loss中,batch中的每个样本只会被使用一次,如下图右下角图示,而Lifted Structures Feature Embedding Loss则一次直接考虑整个batch中所有可能的关系,所以每个样本会多次被使用到,如下图左上角公式所示。Loss包含的是 anchor 和所有负样本的距离以及正样本和所有负样本直接的距离。
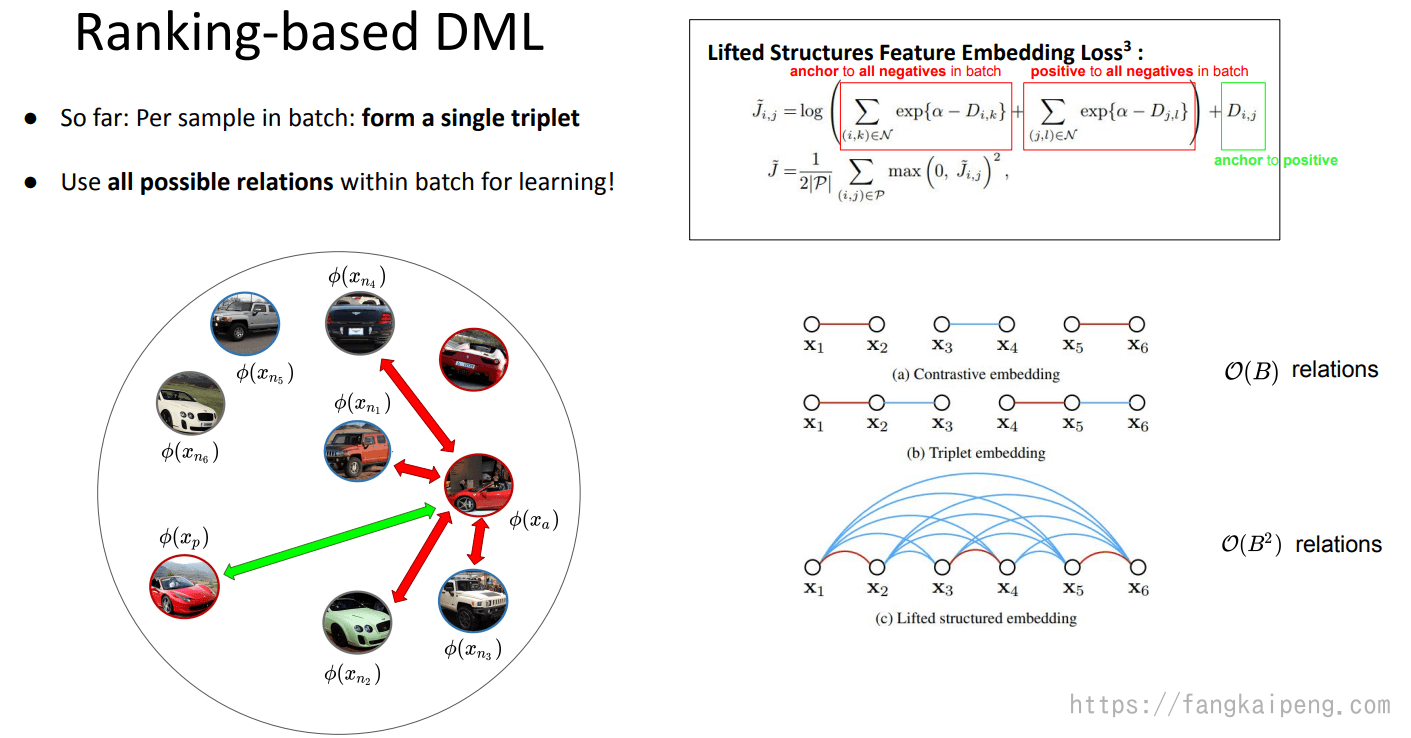
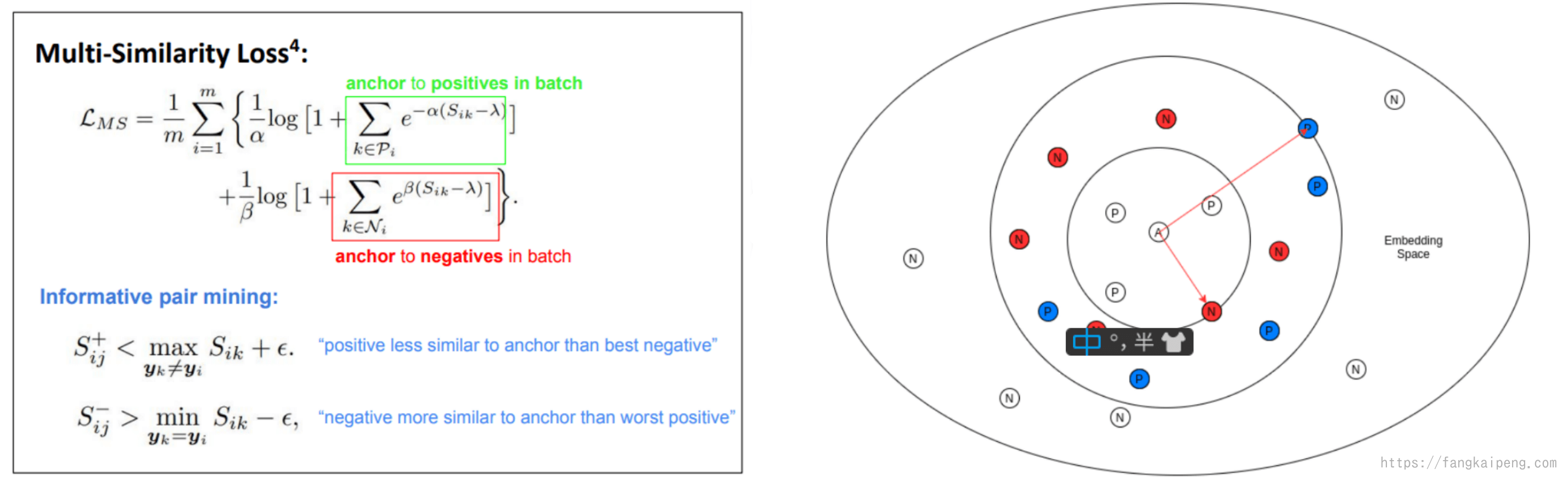
Multi-Similarity Loss
这个loss和前面的Lifted Structures Feature Embedding Loss很像,也是考虑整个batch中的所有数据,就是表达式不太一样,其中
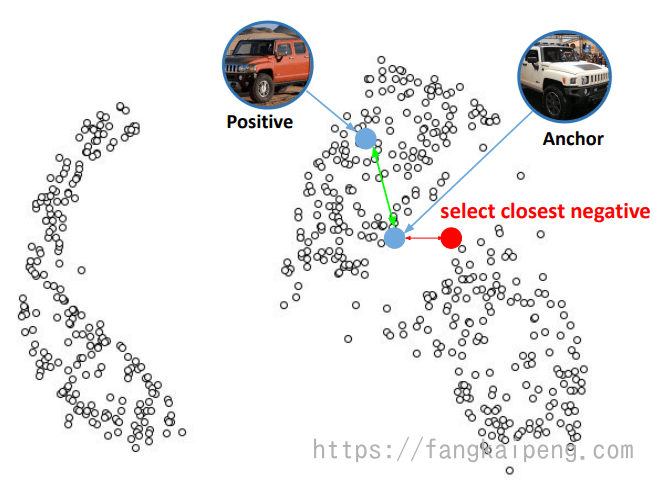
Negative Sampling 负样本的采样
如果考虑整个batch全部的负样本,那么复杂度为
第一种:困难负样本发掘:
即,使用所有负样本中最接近anchor的样本,也就是最容易被弄混的。这种采样方式容易造成不稳定的现象,Hard negative样本通常离anchor的距离较小,这时如果有噪声,那么这种采样方式就很容易受到噪声的影响,从而造成训练时的模型坍塌,困难负样本的梯度方差较大。

第二种: Distance-weighted sampling
根据距离均匀的筛选样本,及带权值的筛选,为避免选择到噪声样本,再对筛选进行裁剪。

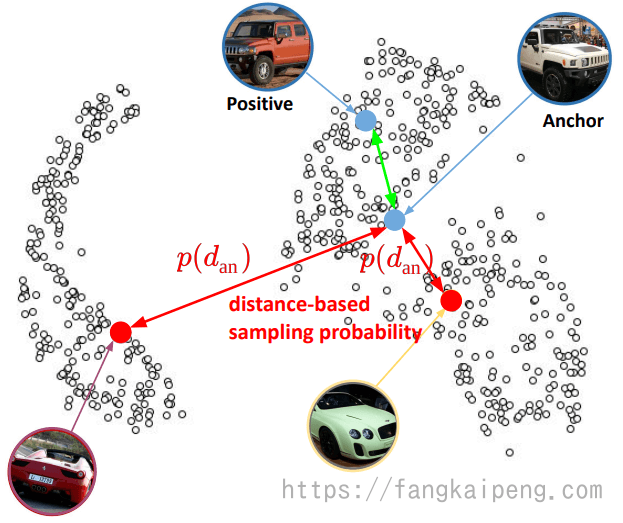
下图显示了不同方法采样负样本,距离的方差,可以看到提出的距离加权的采样提供了较大距离范围的样本:

Distance-weighted sampling是基于距离的采样方法已经是在大的梯度差异与稳定的训练过程之间的较好折中。然而,这种采样方法是静态的。在最开始的时候可能混合着不同难度的样本集对于模型训练有效,但随着模型的优化,需要样本集里有更多的困难负样本.我们希望采样方法可以根据模型的训练状态来进行调整,这样可以采样出具有任何困难度混合的样本集,并且可以通过学习一种策略来调整
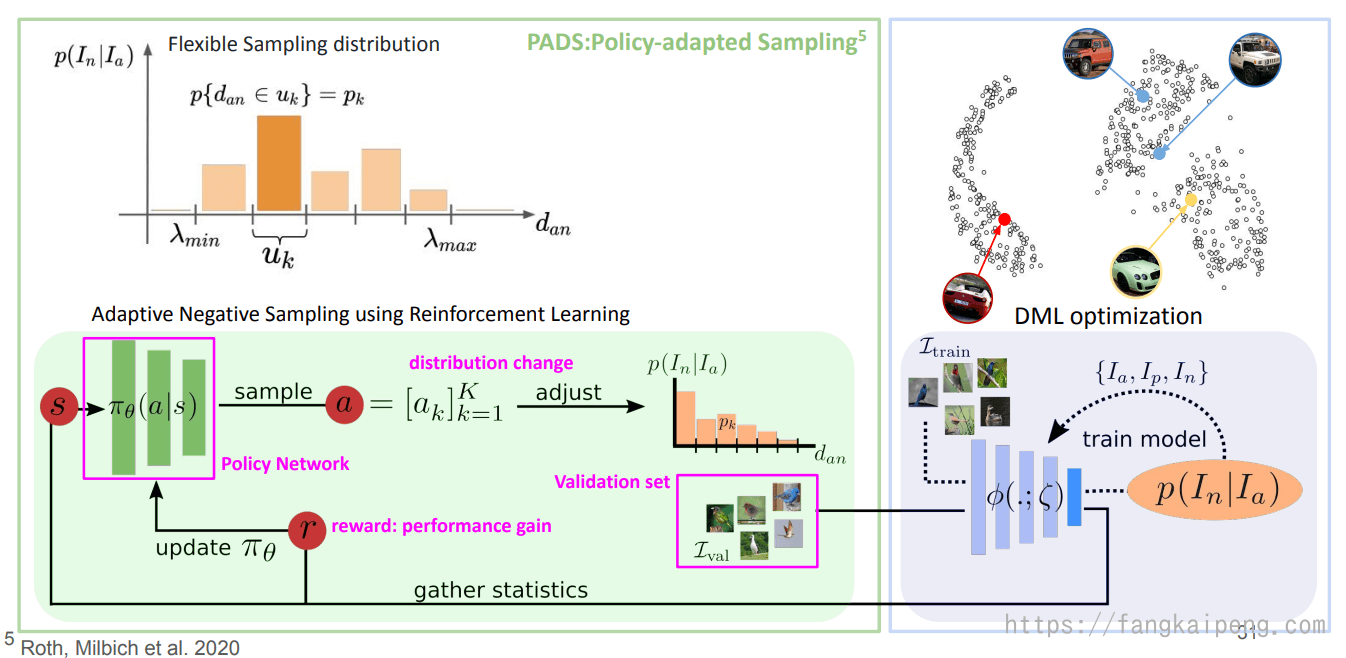
第三种:PADS
这种方法采用了强化学习,根据训练进度动态调整负样本的采样分布,以此来有效控制哪些样本用来学习映射后的向量空间。随着该向量空间的变化,
2.2 Classification-based DML
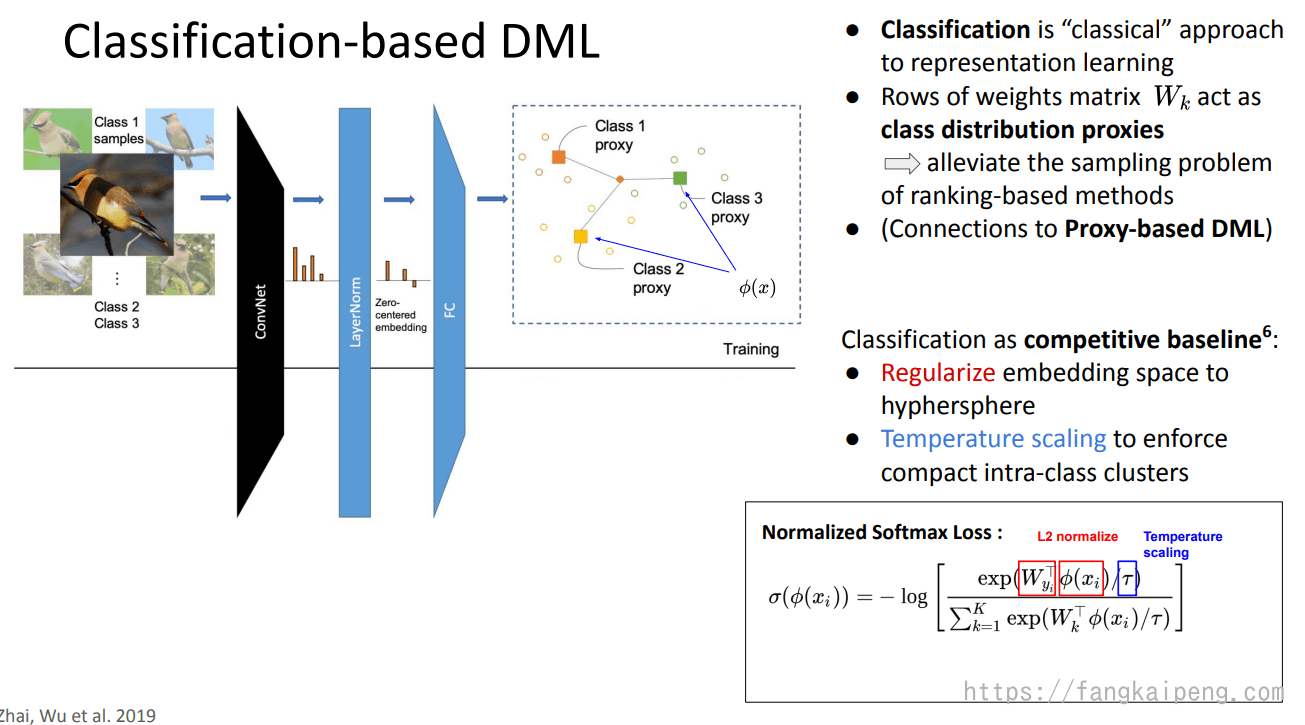
DML的目标是得到一个映射空间,使得类内紧凑,类间远离,自然而然我们就可以想到使用分类的方式来处理这个问题。分类也是一个经典的特征学习的问题。一般而言,对于分类问题,我们会先经过卷积操作提取图像特征,然后使用FC将特征映射到一个高维空间中,从而实现分类。显然可得,FC层中的权重矩阵
分类问题最常用的就是softmax loss了,但是这不能直接用于DML问题中,需要进行两个小的改变:
- 将embedding space 正则化成一个超球体。
- 借助温度系数,使得类内聚拢得更加紧凑。
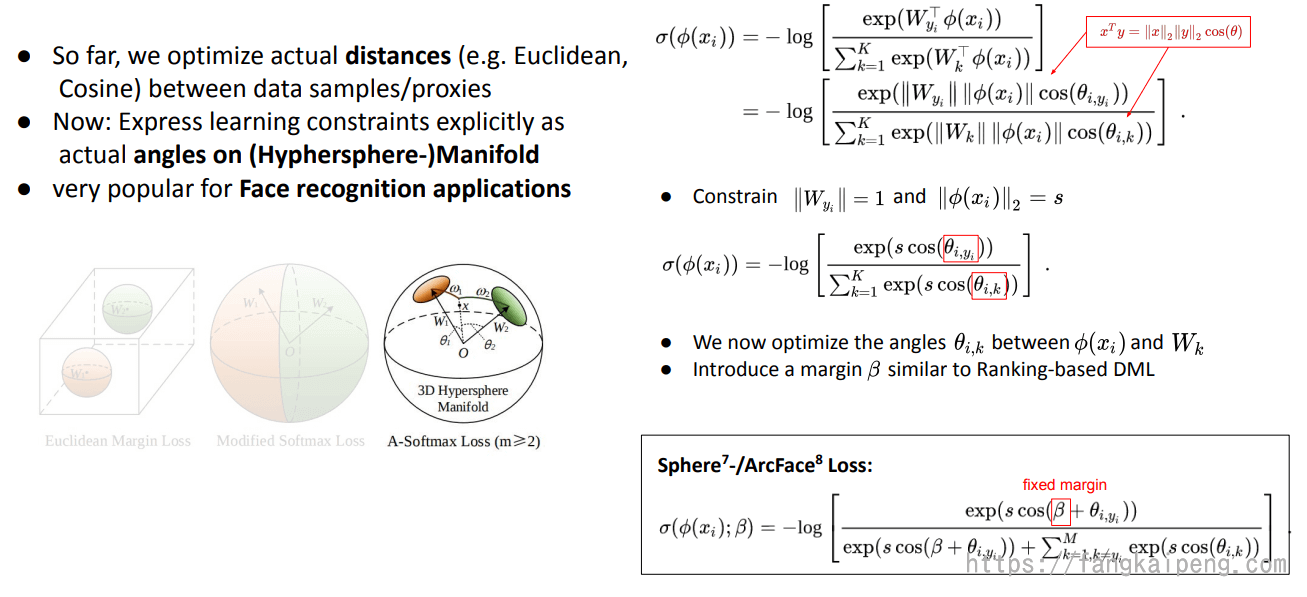
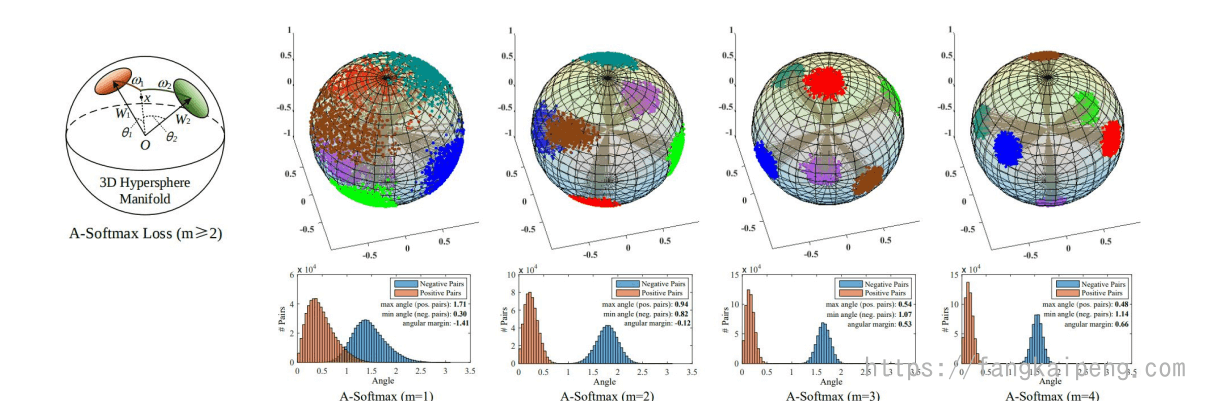
还有一种对softmax的改进称为 A-softmax,首先将向量内积写成模长乘加减的形式,然后引入限制条件(如下图所示),这样就能使得预测仅取决于W和x之间的角度θ。为什么要添加|w|=1的约束呢? 作者做了两方面的解释,一个是softmax loss学习到的特征,本来就依据角度有很强的区分度,另一方面,人脸是一个比较规整的流形,将其特征映射到超平面表面,也可以解释。
2.3 Ensemble-based DML
集成学习是一种很常见的提升模型整体性能的办法,其用于DML的思路也很简单。最原始的方法如下,就是独立训练K个不同的模型,并且使用相同的损失函数。一般认为,汇集多个不同的embedding会增加模型的鲁棒性。
BIER-借助 gradient boosting
但是上图的方法比较耗费时间和计算资源,所以就有了下图的方法,即多个模型共用一个Encoder,这样的好处是可以缓解计算资源的耗费,同时每个模型可以使用到更加强大的特征表示。然而,原始的DML集成学习方法使用相同的loss,导致学习到的feature有很多的关联性,集成后对性能提升帮助不大。所以,BIER提出了一种新的集成办法,如下图右所示。首先,借鉴online gradient boosting,根据前一个learner的预测情况,对样本进行重新加权,使得正确分类的样本权重第,错误分类的样本权重高,这样就使得每个learner和前一个都不同了。
同时,还提出了Adversarial Decorrelation,进一步增加每个learner的多样性,对任意两个learner,使用一个回归器来最大化他们的相似度,以此提高多样性。

分治法
还有一种基于集成学习的DML方法,借鉴了分治法(Divide & Conquer strategy)的思想(第一次看到DL中应用传统算法的思想,也很巧妙!)。如下图所示,具体是这样的:
主要分为两步骤,拆分训练和合并结果。
首先将图片输入一个CNN和FC层,得到一个D维的向量, 即映射到了一个D维的embedding space,然后再这个D维空间中进行K-means,将数据分为K个簇,同时将FC层拆成K个learner,每个learner输出一个D/K维的向量,即将原来的embedding space拆成了K个子空间,这K个子空间分别和一个簇对应。接下来就是对这K个learner进行交替训练,每次训练会从对应的簇中取出一个batch的数据,然后用这个子空间中定义的loss进行DML训练,反向传播的时候只会更新CNN的参数和这个子空间对应的learner。文中还提到,由于训练后embedding space会改变,所以经过T个epochs后,会重新进行一次 K-means(利用整个embedding space)。
K个learner都收敛后,将这K个embedding space进行合并,然后将其在整个数据集中进行一次 fine-tune,这就是整个算法流程。

还有一种利用分治的做法如下图所示,区别是按照分层的方式划分。文中指出,当前DML面临的主要挑战是,数据集中有大量的隐藏因素可能会影响图片之间的相似度,而类别只是其中的一个。同时,数据中也可能会存在一些偶然的特征(accidental traits),比如一些噪音,或者照片的噪点。这就导致了训练时容易出现两个问题:
- 无法解释所有的隐藏因素,而只关注那些比较重要的,比如类别,这就导致泛化能力很差。
- 有时候神经网络会走捷径,关注那些偶然的特征,这就容易导致过拟合。
于是,受分治思想启发,提出如下的pipline,将网络每次训练后都切分成两个子空间,直到一定限度。切分时,同时将空间和数据集一起切割,数据集按照k-means进行聚类。
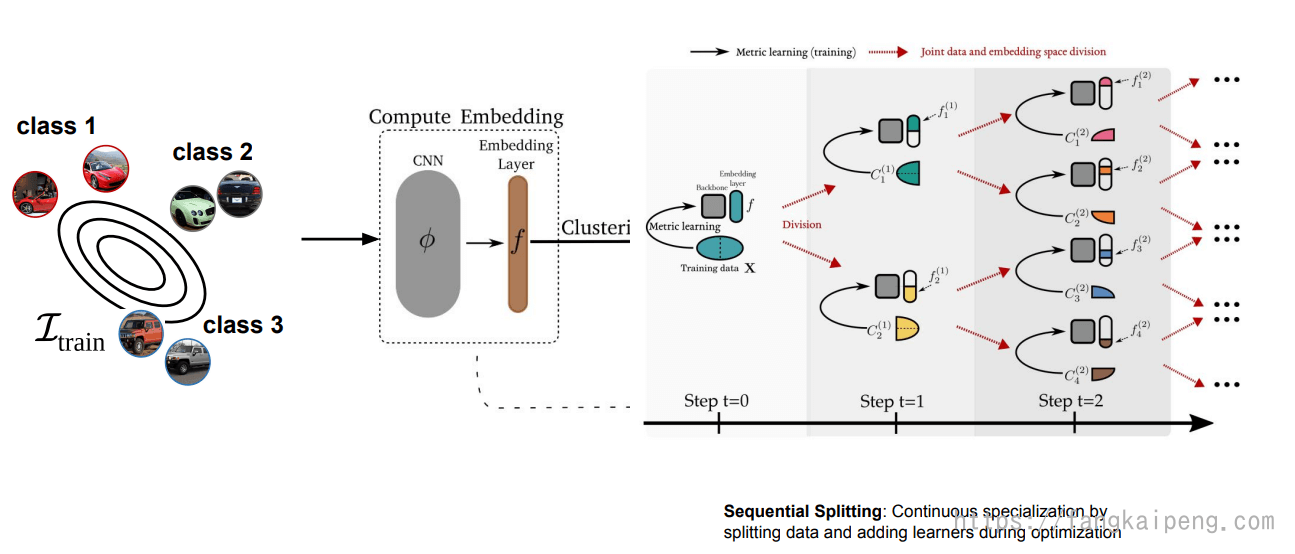
挖掘类间特征
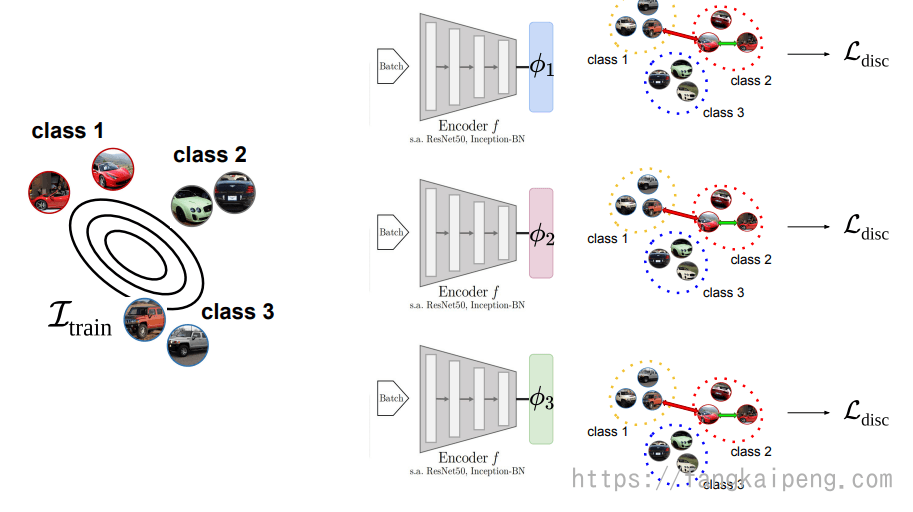
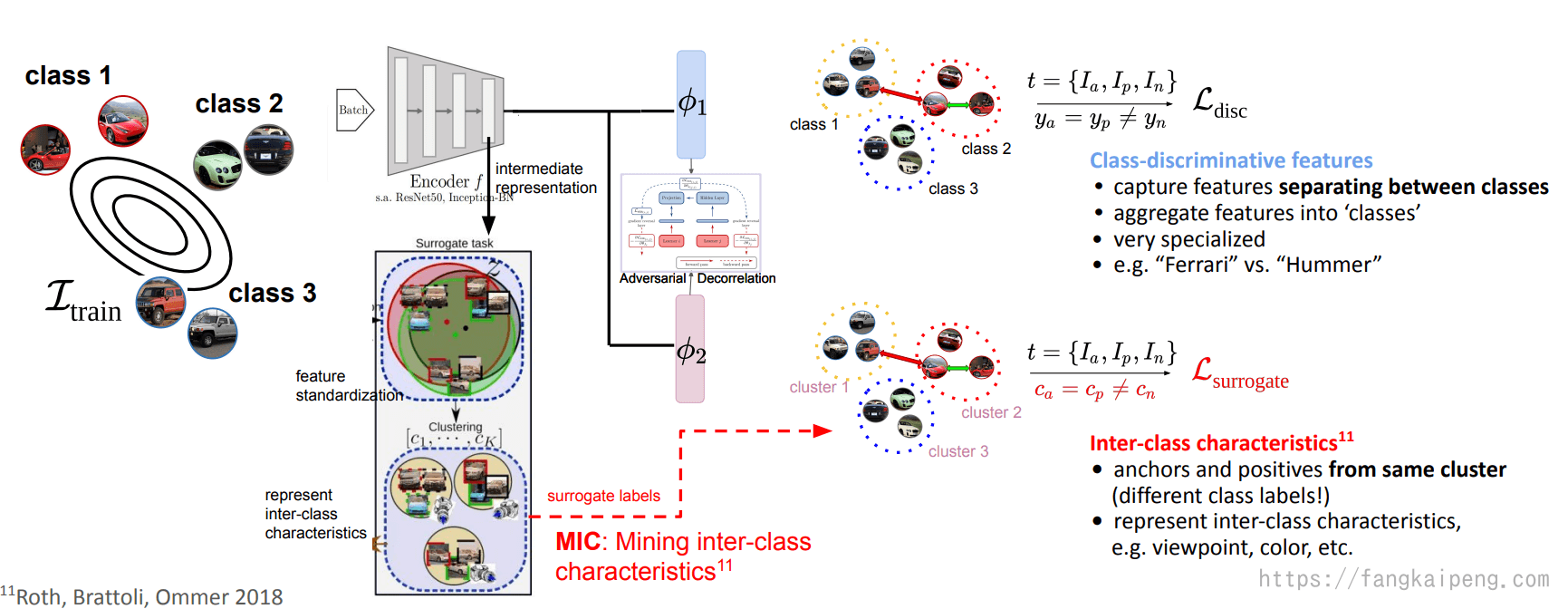
前面的这些方法,都是关注图片不同种类的特征(Class-discriminative features),即这些特征专属于不同的类。那么能否挖掘一下类间的特征,也就是所有类可能都有的,比如按照视角、颜色等归类的特征。如下图,就使用了两个独立的Encoder,他们共享CNN提取的特征,第一个Encoder只学习类别特征,使用Ground True label进行学习。第二个Encoder用于挖掘类间的特征,其label是这样得到的:首先他会对CNN提取的特征进行standardization,进一步消除类别特征,然后进行一个聚类,得到K个簇,然后采样的时候,anchor和positive来自相同的簇(可能属于不同类),和negative属于不同簇,这样就能学习和类别无关的特征了。同时,由于两个encoder共用同一个CNN的representation,所以可能会学到一样的特征,所以,在两个encoder间还是用了一个对抗的损失,以此拉开两个encoder的差距,使他们各司其职。
更进一步,Sharing Matters for Generalization in Deep Metric Learning这篇论文中提到,真实的图片可能有很多的特征,比如颜色、形状等,但是只有 discriminative characteristics 才会被学习,因为这些特征可以很好地区分每个类。但是这样就会丢失其他很多的特征,使得模型不能很好地泛化到不可见类中。所以,为了让DML能够很好地泛化,我们需要学习很多补充特征。而他们发现,仅仅从按照簇进行采样,会导致随着训练的进行,每个簇会由少数的几个类别主导,使得每次采样得到的图片很可能属于同一个类别,这就导致学到的特征还是非常discriminative ,所以他们更进一步限定,anchor、positive、negative都属于不同的类。下图是训练的embedding可视化结果,左边学习的是类别discriminative 的特征,可以发现,属于同一类品牌的汽车聚为一类。右边学习的是类间特征,可以发现,汽车朝向相同的归为一类,或者颜色都为蓝色的归为一类。同时学习这些特征,使得DML的泛化能力增强。
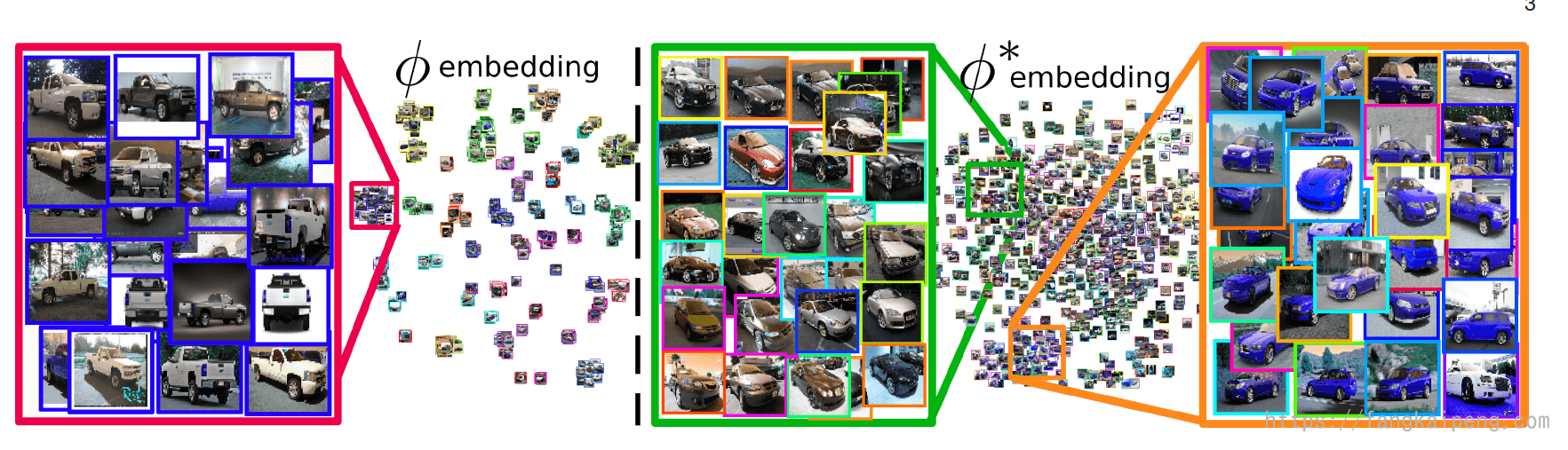
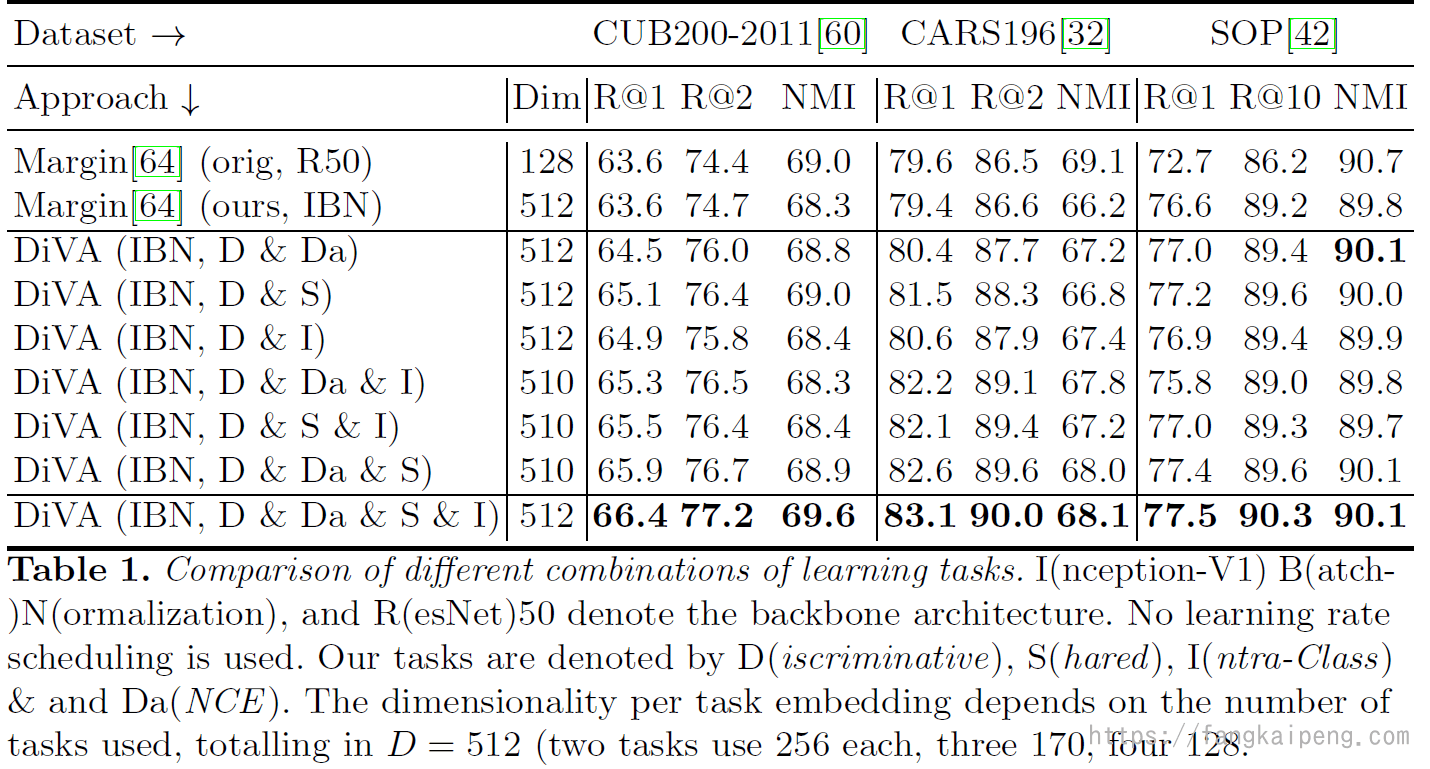
再进一步,将上面的思想都进行汇总,在模型中同时引入四种类型的特征:Class-discriminative features、Class-shared features、Intra-Class Features、Sample-Specific Features,就是DiVA的思想了。

以下是对比试验的结果,可以发现引入的特征越多,效果越好:
2.4 Proxy-based DML
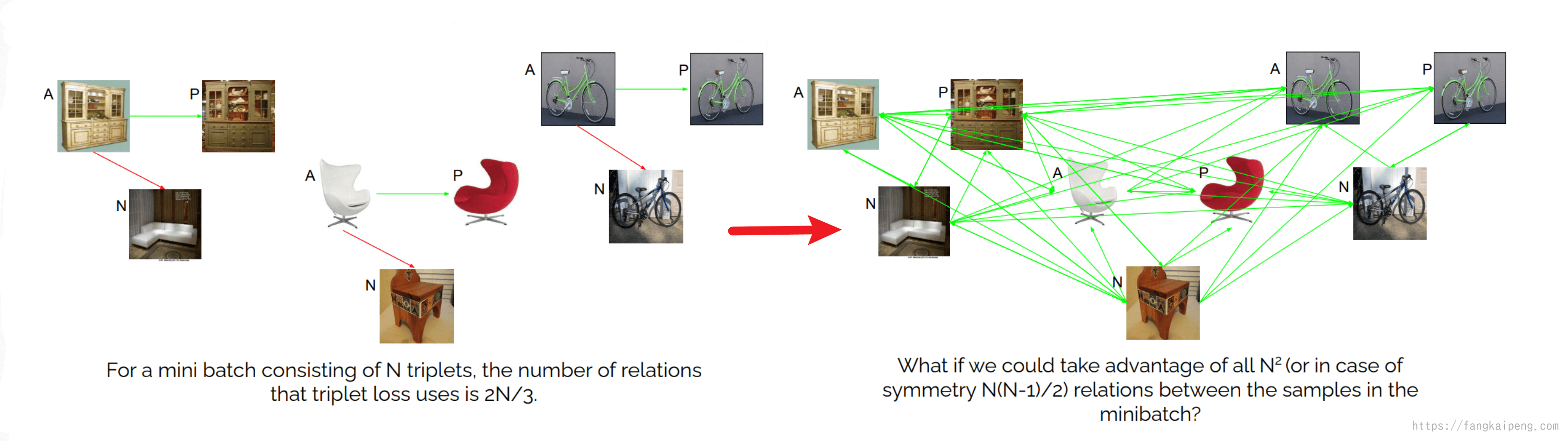
Triplet loss的问题
如下图所示,Triplet loss对于数据间关系的利用率很低,只用到了一部分(如左下所示),那么能否利用整个数据集中所有的关系呢(如右下所示)?
目前有两种主流的做法:
- Proxy losses
- Information propagation losses.
在介绍Proxy losses之前,再回顾一下classification loss,在classification-based DML中,我们使用分类的思想,对于的FC层,我们经过softmax转化成logits,实际上就是将FC层中的权重矩阵
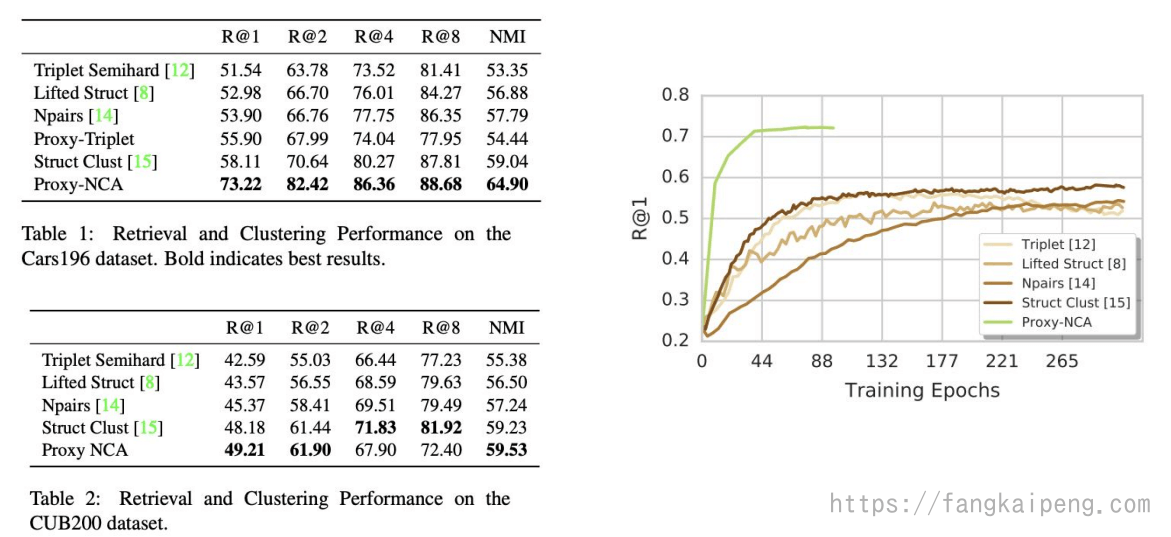
Proxy-NCA
其主要思想是使用代理的方式,即使用几个代理来代表整个数据集,这样在训练的时候,每个数据样本只要和代理比较就行,减少了关系数量。同时,这样的采用也更加高效,模型无论是准确率和收敛速度都有提高。

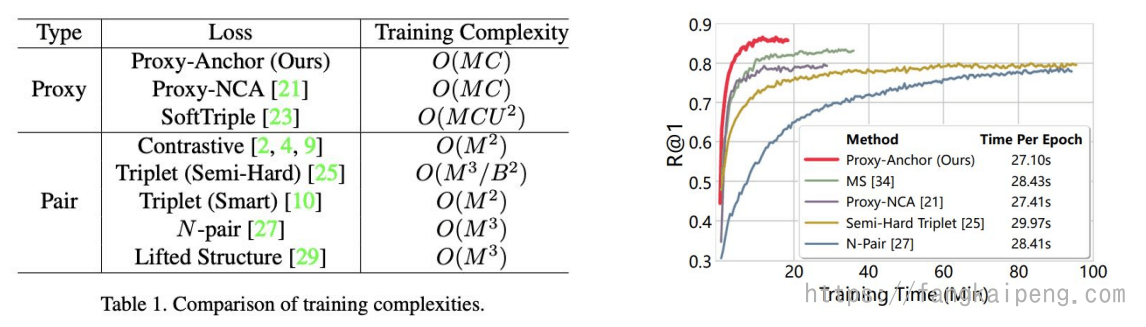
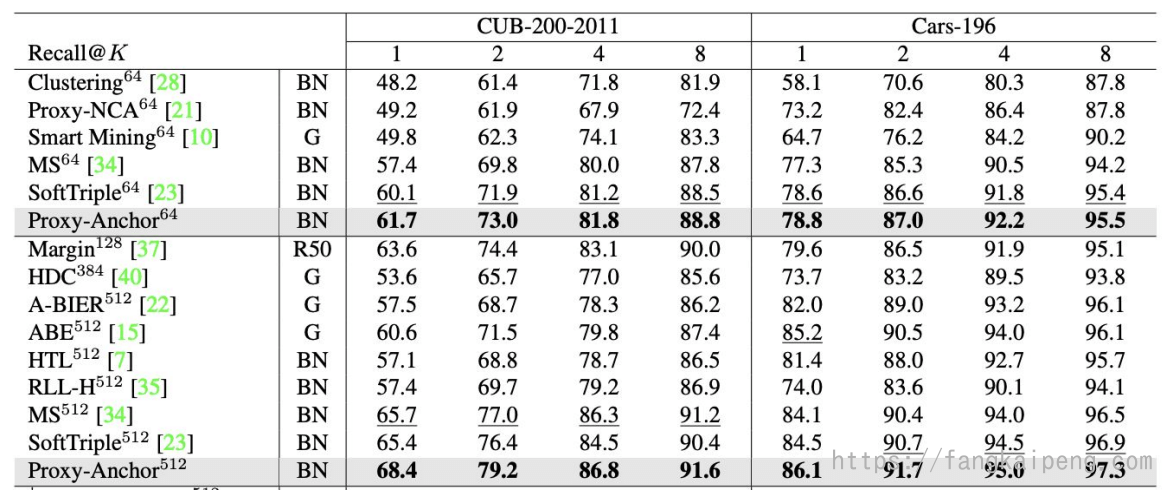
Proxy-Anchor
Proxy-NCA中将正样本和负样本用Proxy代理来替代,Proxy-Anchor中则将Anchor用代理来替代,如下图所示:

实验发现,其复杂度和Proxy-NCA相同,但收敛速度和准确率都更高。
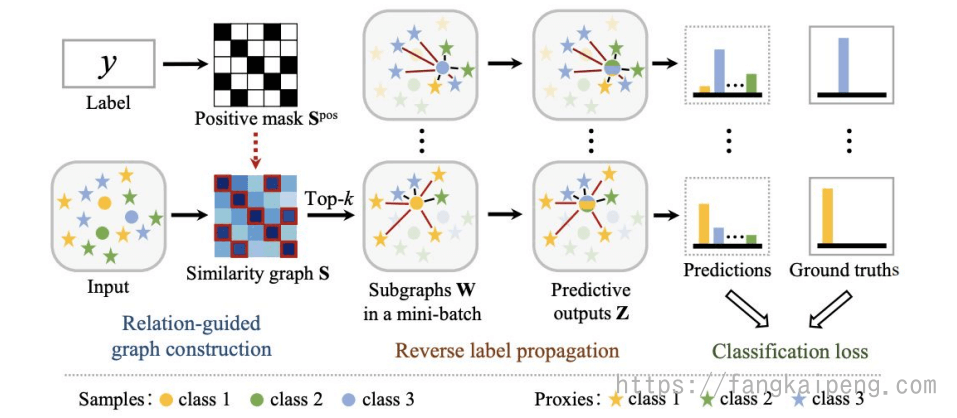
Combining proxies with label propagation
使用了label propagation算法,和ProxyNCA不同的是,对于每个类采用多个代理来表示,并且使用一个相似度图来建模数据以及代理之间的全局关系。同时将这个相似图分解成多个KNN子图,并且使用Label propagation来更新优化KNN子图上节点之间的关系。
训练效果:
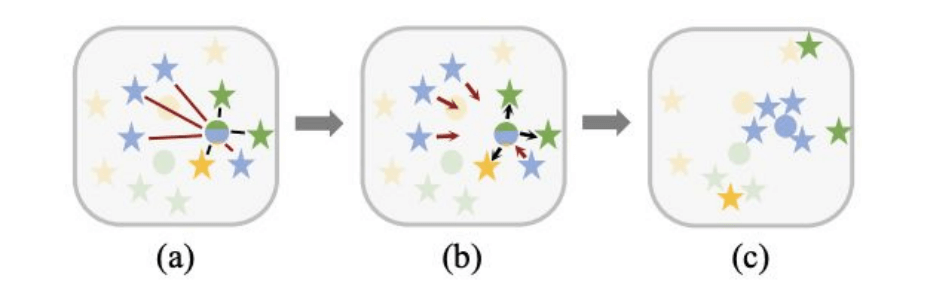
2.5 Information propagation
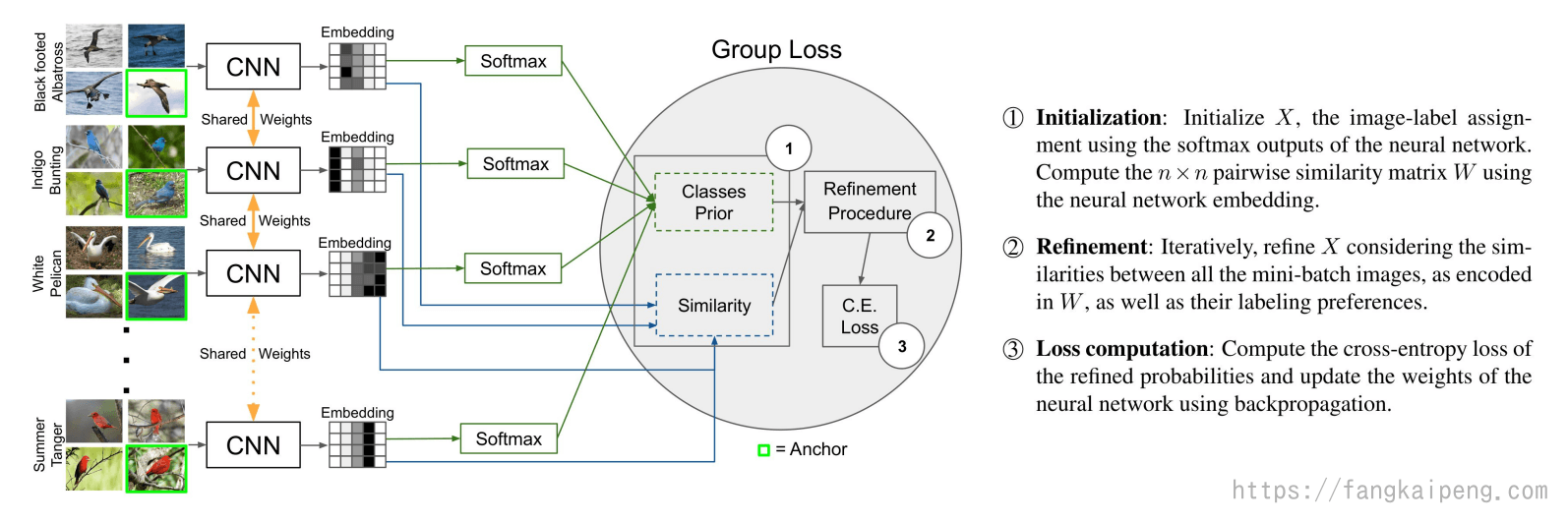
Group Loss
Group Loss的目标是进一步完善模型的预测结果,其主要框架如下图所示,在整个模型训练中对于一个包含 n 张图片的mini-batch,我们的目标是给每个图片都分配一个类别标签(总共 m 个类别)。其中 $X$ 表示一个
-
初始化:
首先初始化 $X$,将图片送入一个共同的CNN提取embedding,然后经过softmax后得到 $X$ ,其中会随机将几个图片作为Anchor,将他们的softmax直接用label的one-hot形式代替。然后,将n张图片两两之间计算一个相似度,得到一个
的相似度矩阵。相似度使用Pearson’s correlation,计算公式为: -
调整:
以迭代的形式,重新调整我们的 $X$ 矩阵,主要是根据我们的相似度矩阵来调整。此外,初始化中随机分配的Anchor的softmax值是不会被调整的(已经是one-hot形式了)。所以,其实就是利用这些Anchor的label信息,配合我们的相似度矩阵来调整其他照片的softmax结果,具体来说,就是和Anchor越相似,那么其softmax结果也就越趋向和Anchor相似。
-
Loss计算:
最后就是用交叉熵来计算loss,然后更新CNN的参数。
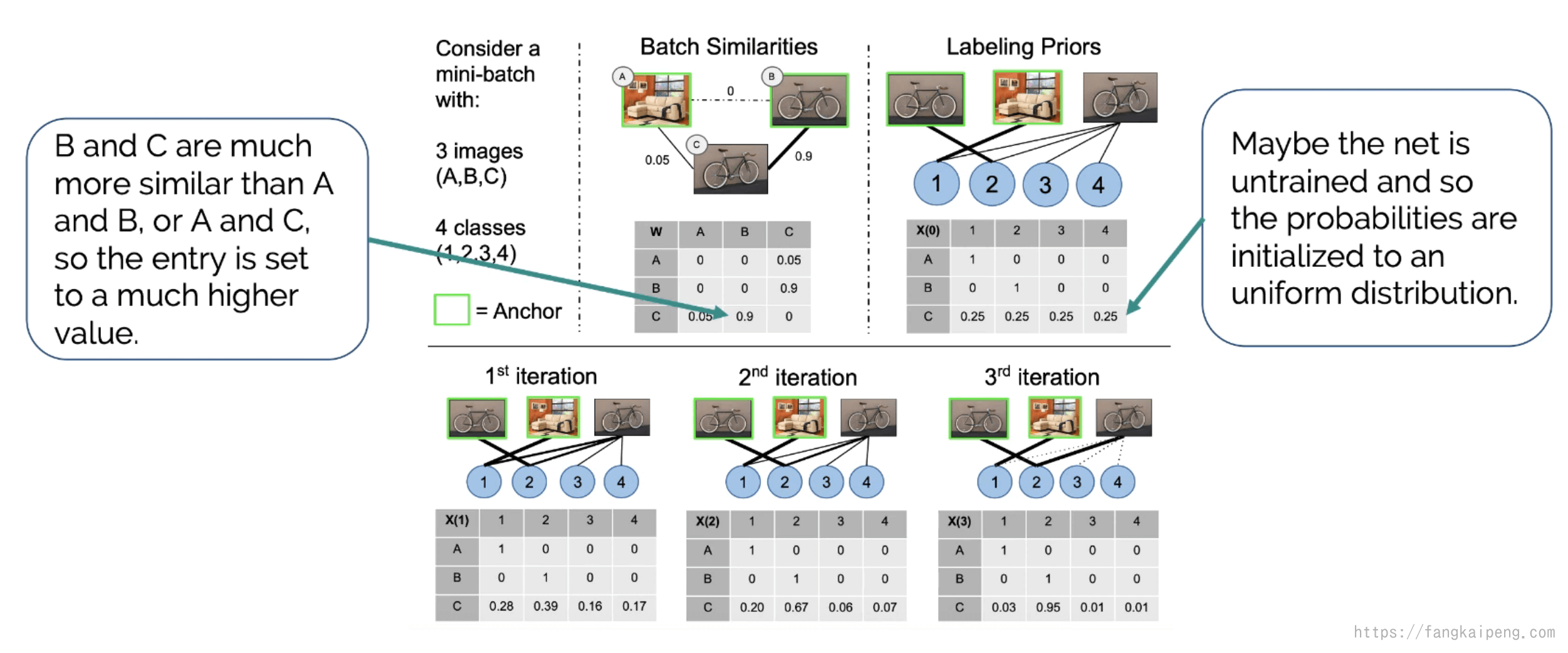
下面看一个toy example:
如图所示,我们的mini-batch中只有三张图片,其中B和C的embedding相似度高,A和C的相似度比A和B的高,初始时,我们将A和B都作为Anchor,
Group Loss的数学表示式如下:
这是一个迭代的形式,表示第

由此,我们可以得知Group Loss和softmax cross-entropy loss是极为不同的,Group Loss中没有需要学习的参数,其作用是教导网络不仅训练出一个分类正确的embedding,同时还要保证属于同一类的图片的embedding是非常相似的。
下面给出算法的流程:

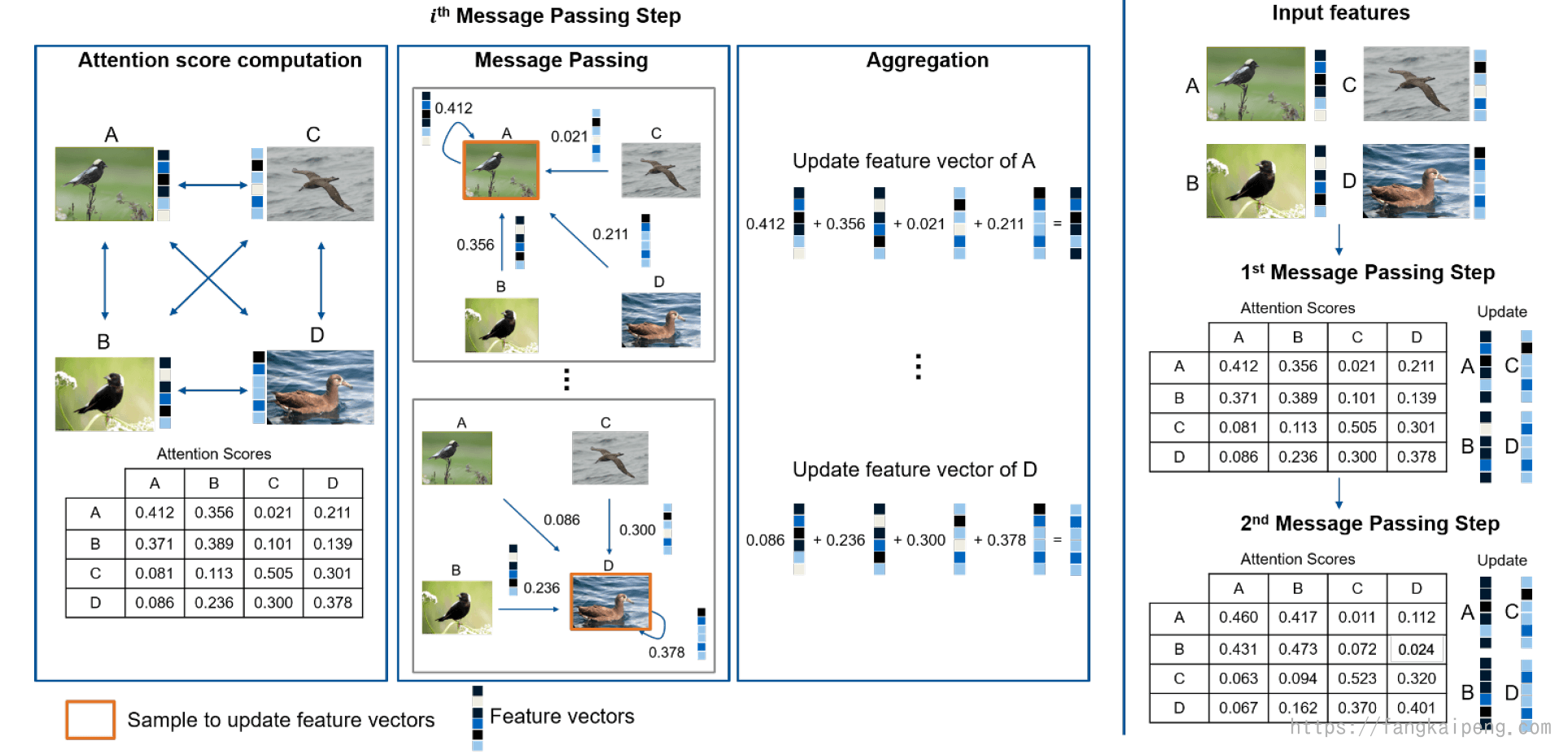
Message Passing Framework
Group Loss中给每个Anchor的softmax logits分配固定的one-hot形式,实际上就是将label的信息引入进来,然后实际上,我们的embedding中也有很多丰富的信息,而这些在Group Loss中没有使用到(虽然用embedding计算了相似度,但是相似度实际上是我们的优化目标,而不是利用这些相似度来做什么)。所以,在Message Passing Framework中,进一步使用了embedding的信息。提出的框架如下:
同样是用一个共享的CNN提取embedding,区别在于,它不是直接计算softmax,而是将整个embedding作为节点,构建了一个message passing networks,然后再进行K次Message Passing,来更新这些embedding,最终用交叉熵得到loss更新网络。
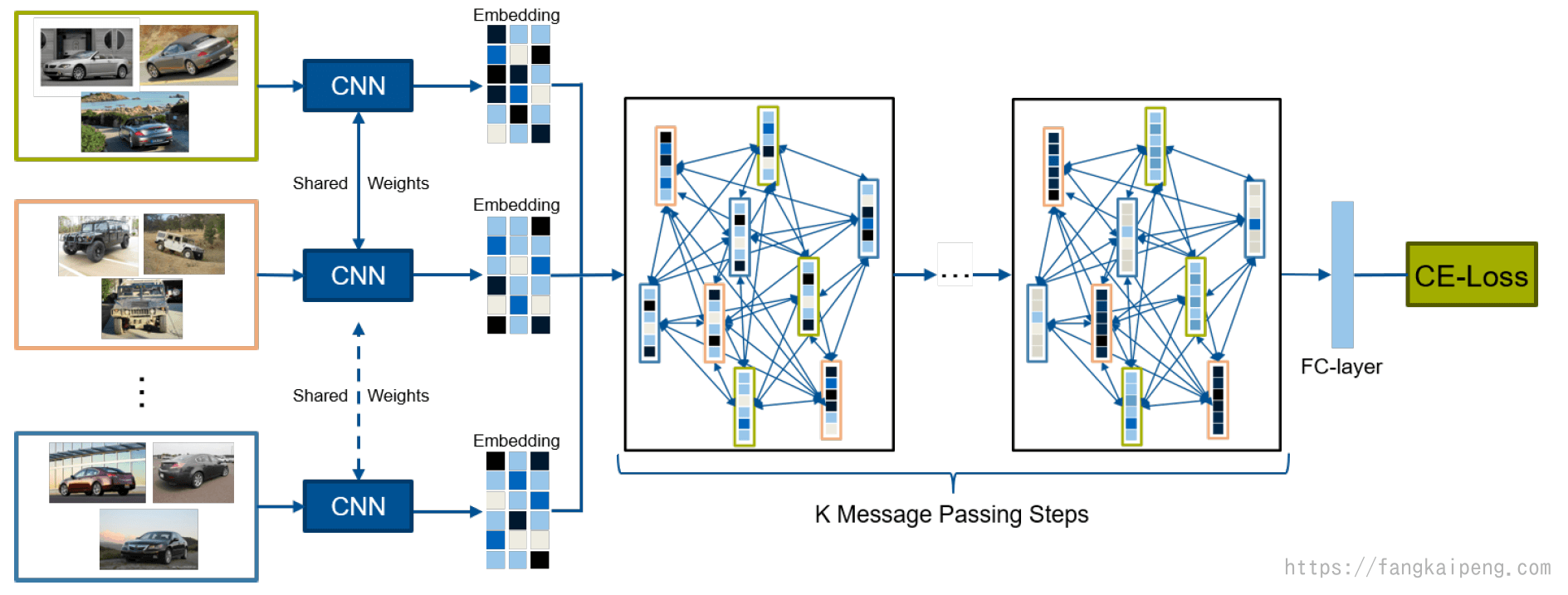
具体来说,Message Passing的过程如下图所示:
首先是使用embedding构建了一个网络,然后对于每个节点之间有一个Attention Scores,相当于边权,类似Group Loss中的相似度,但这里的Attention Score是一个权值,由网络训练更新得到。接着是,利用Attention Scores来改变我们的embedding,对于每个node,都会受到整个batch中其他图片的embedding影响,受影响的程度由Attention Scores决定。进行若干次迭代后,将这些影响结果相加作为最终这个node的embedding。下图最右边可以看到,经过2次迭代,属于同一类的图片的embedding也更加相似了。
3. Best Practice DML
3.1 验证DML
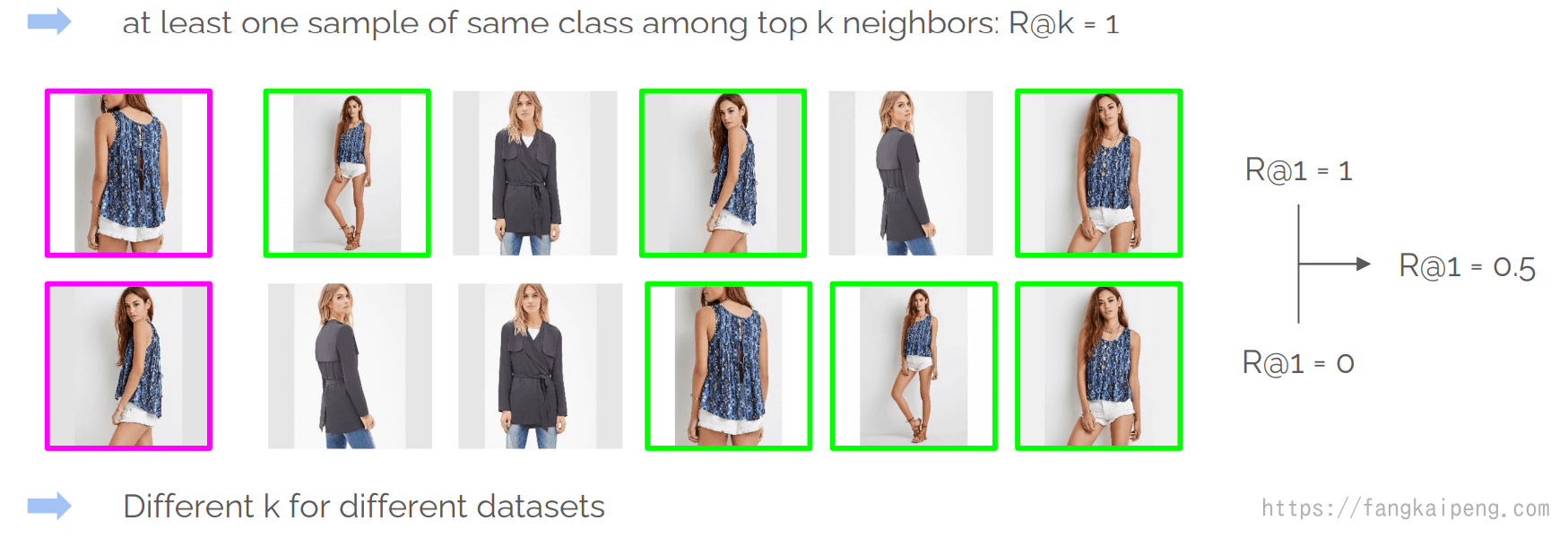
DML通常应用在图像检索问题上,对于图像检索,测试时数据集分为query set 和gallery set,每次从query set中取照片作为查找对象,在gallery中进行检索。那么评价检索性能,一般使用Recall@k,即对前k个最相似的检索结果求Recall,然后对多次的检索进行求平均,如下图:
有时候query set 和gallery set没有进行明显区分,即只有一个大数据集,里面的图片同时作为query和gallery进行测试,此时就可以使用Normalized Mutal Information(NMI)作为我们的评价指标。首先对我们的embedding进行K-means的聚类,然后对我们的聚类结果和真实标签计算一下NMI,作为评价指标:

3.2 数据集
比较常用的数据集如下:

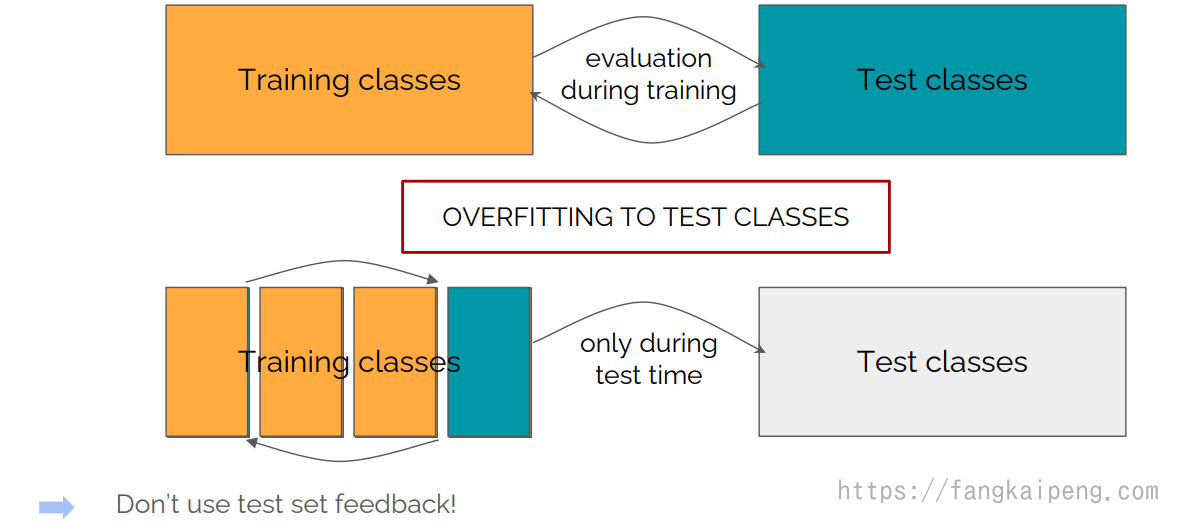
需要注意的是,这些数据集都没有验证集,所以验证集和测试集相同。但是这样容易导致模型对测试集过拟合,导致评价不准确。所以训练时可以使用k-ford交叉验证:
3.3 SOTA结果

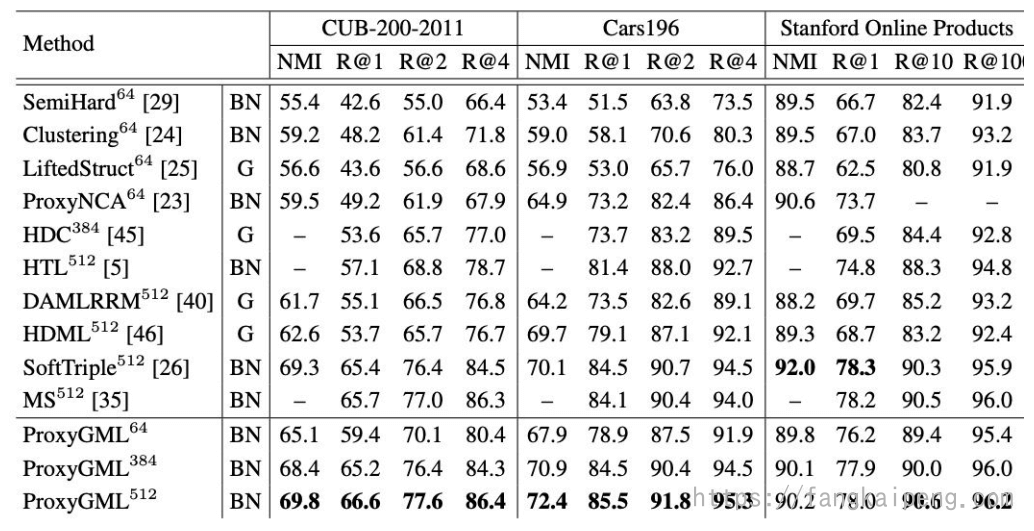
Table 1. Retrieval and Clustering performance on CUB-200-2011, CARS196 and Stanford Online Products datasets. Bold indicates best, red second best, and blue third best results. The exponents attached to the method name indicates the embedding dimension. BB=backbone, G=GoogLeNet, BNI=BN-Inception and R50=ResNet50.
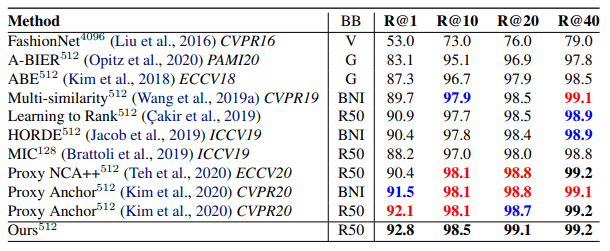
Table 2. Retrieval performance on In Shop Clothes
最近使用Transformer作为backbone网络的模型性能有很大的提升:
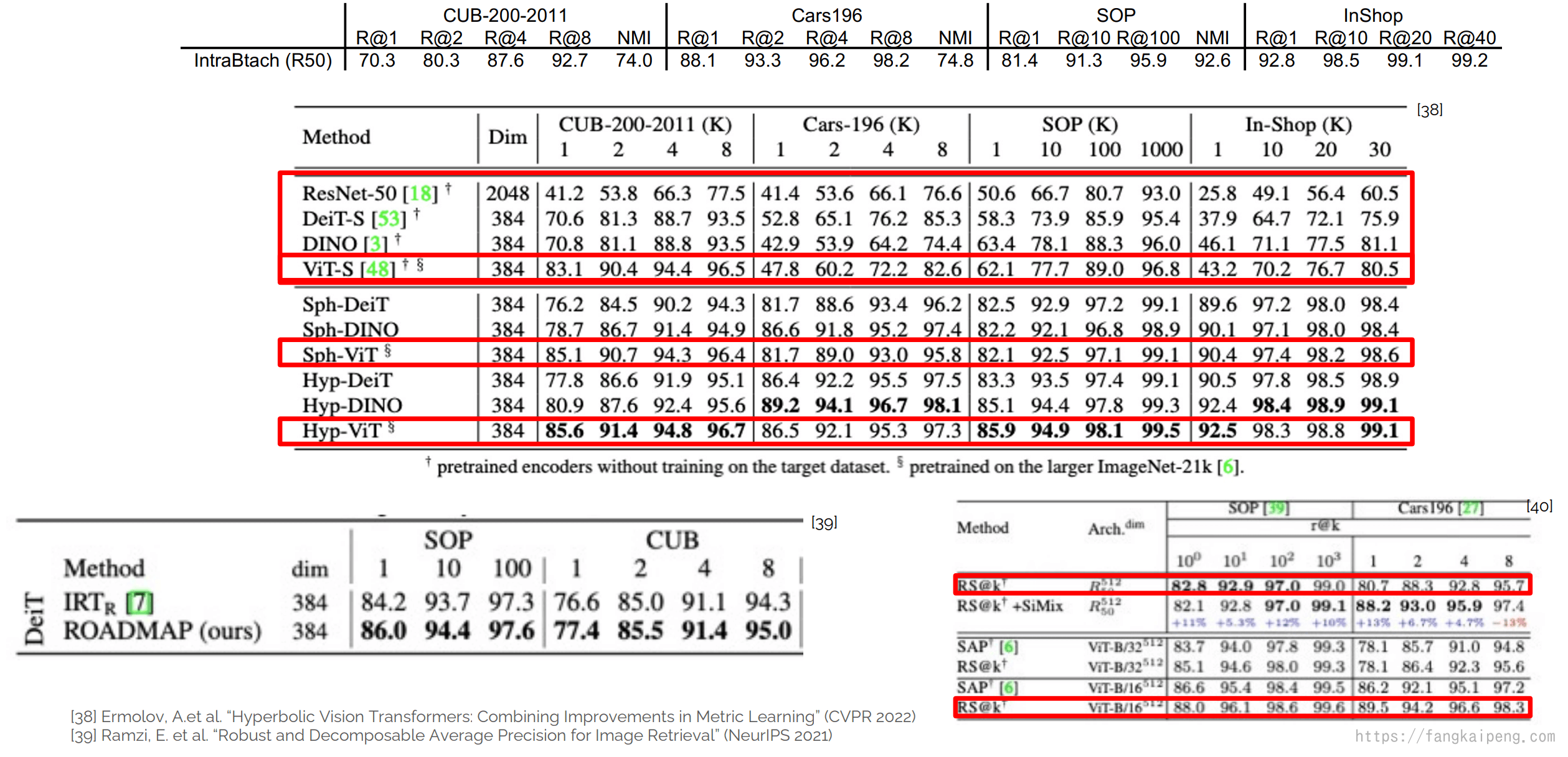
3.4 标准的训练流程
在DML中,目前有很多公认的标准化训练流程,首先是Data Augmentation:

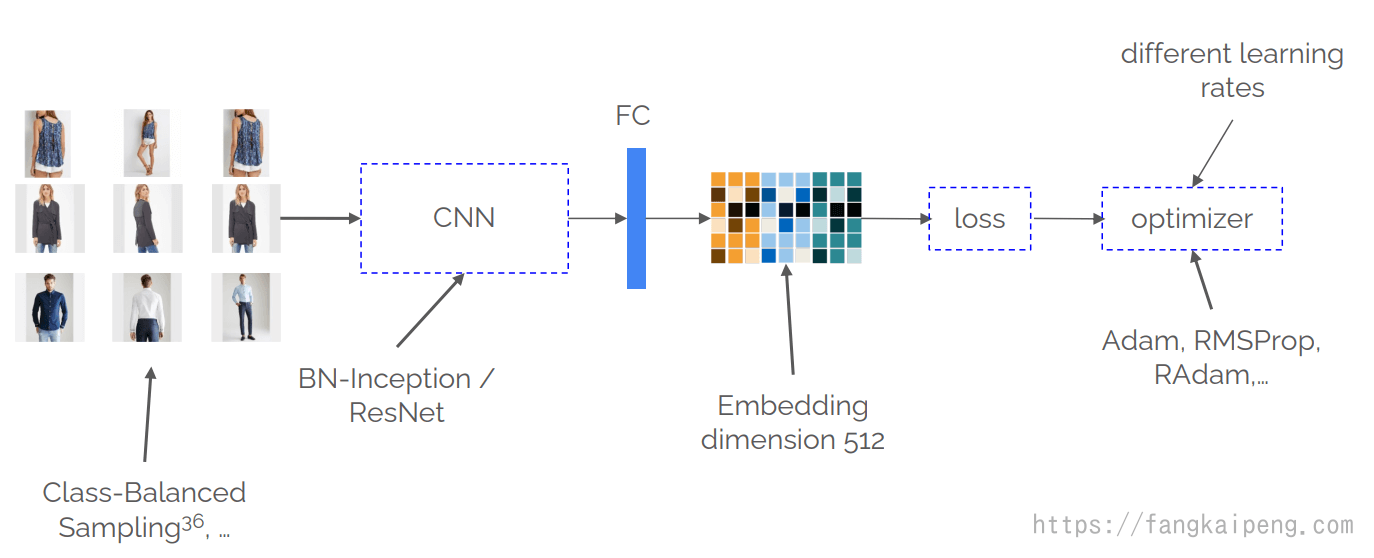
然后是训练的Pipeline:
其中,Class-Balanced的采样方法可以保证在训练时每个类都可以公平地进行比较。
3.5 炼丹Tricks
DML也有很多“玄学”提升performance的Tricks:
- 数据处理的时候裁切更大的图片:

-
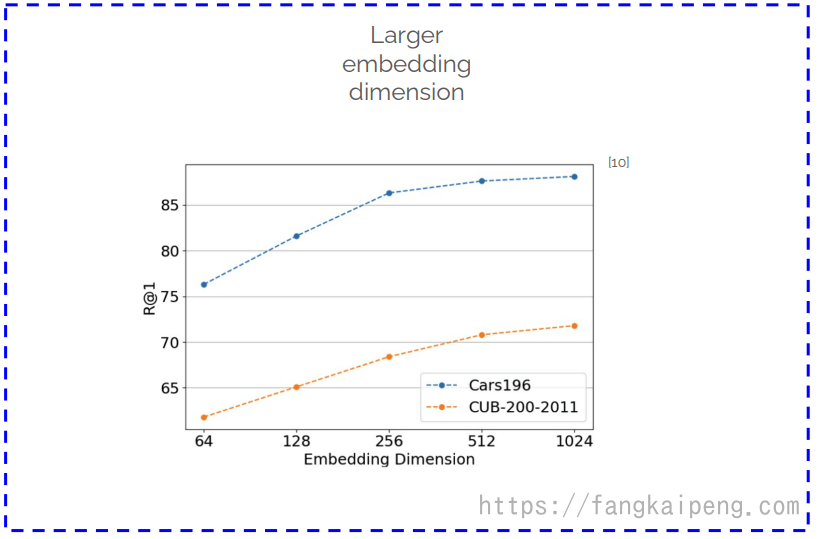
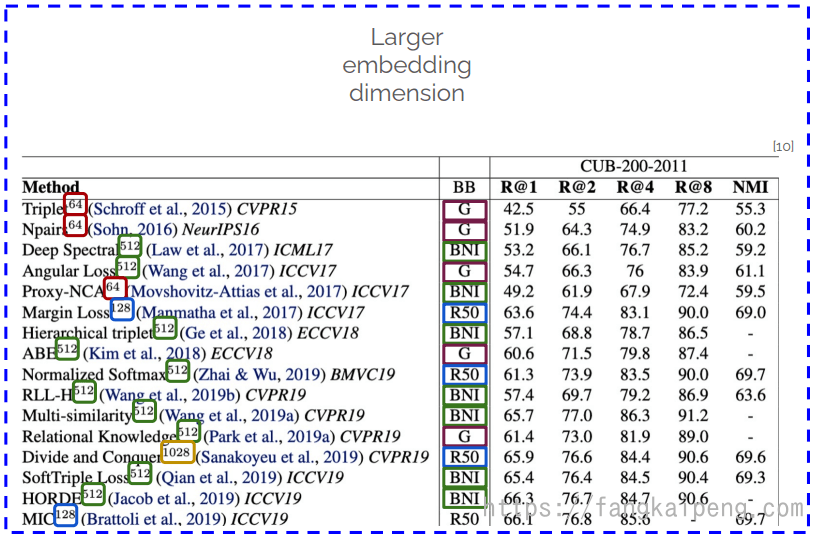
使用更大的embedding维度,但是要小心由此带来的计算消耗,因为在检索的时候需要将query的图片和整个gallery图片的embedding进行比较:
-
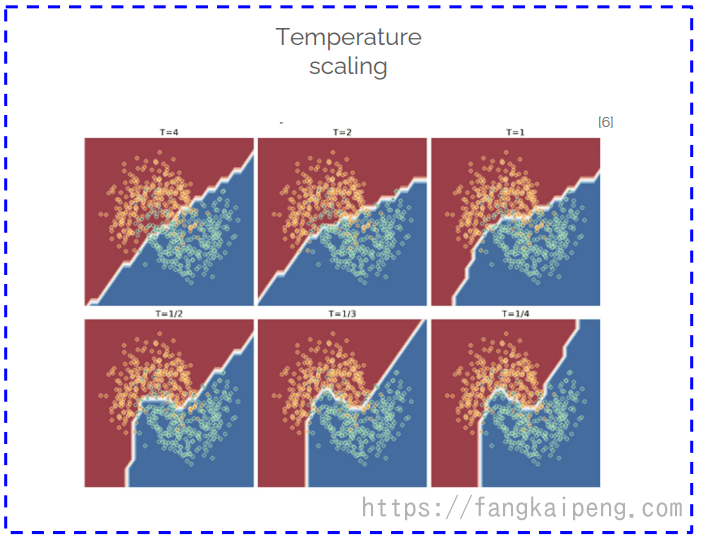
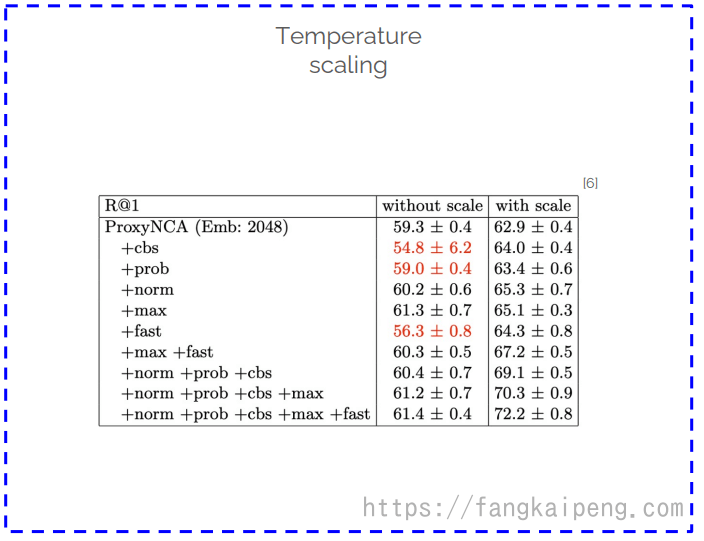
使用 Temperture scaling,这其实是知识蒸馏中的概念。在知识蒸馏中使用大于1的温度系数,可以使得决策边界更加平缓,而在DML中发现,应该使用大于1的温度系数,这样可以使得模型的性能有大幅的提升,其原因可能是使用大于1的温度系数,使得模型的决策边界更加精准,对问题过拟合了(有点反直觉,但就是能提升性能)。
-
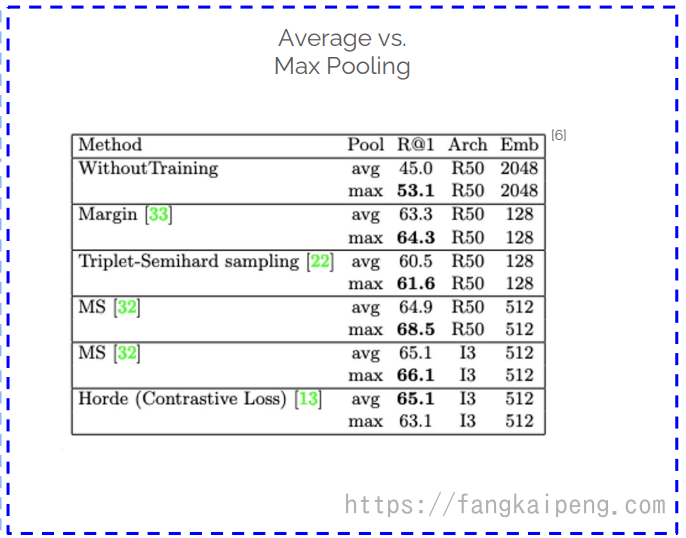
使用平均池化或最大池化,实验发现,针对大部分的method使用max polling有更好的效果:
-
– normalization: 其思想是,长度标准化前后的向量,虽然在角度上差异不大,但是长度相差可能会很多,这一定程度上可能导致一些信息的丢失,所以将标准化前后的向量按照一定的比例相加进行混合,可以保留长度的一些信息。
Elezi, I. et al. “The Group Loss++: A deeper look into group loss for deep metric learning”, PAMI (2022/03)
-
Re-Ranking:
-
Flip-Evaluaion:




最后,tutorial中里还进行了友情提示:
请不要偷偷摸摸地在你的模型中使用这些tricks,要和以前的work公平的进行比较!
3.6 更好的评价指标
前面介绍了两种评价指标,Recall和NMI,那么这两个评价指标是否足够好,可以足够精准地衡量一个模型的好坏呢?答案是NO!
如下图,有两种数据的三种不同的embedding分布情况,可以发现,他们的NMI、F1和Recall指标基本都是一样的,但是他们的embedding分布情况截然不同,这就说明上述的这些评价指标不够鲁棒,也就不能准确反映模型的好坏。比如,下图中,明显是最后一种embedding最好,两类数据区分的最好,但是他们的Recall和NMI基本相同。并且,使用NMI需要先进行一次聚类,这就导致我们获得的评价指标不是直接得来的,还进行了一个中间处理,这就可以使用seed在初始化的时候调整模型,让模型的指标表面上看起来更好。

下面介绍两个更好的评价指标:
R-Presicion
其中

MAP@R
如下图第一行,P@3 = 2/3,P@4 = 2/4,P@5=3/5,@k就表示,考虑检索结果的前k个中有几个检索正确的。最后的MAP,就是将k=1到所有的结果取平均。

最后,还是上面的结果,可以发现这两个评价指标更加鲁棒:

3.7 论文打假
前面介绍了那么多的Tricks,还有很多没提到的炼丹技巧。同时,前面提到,检索所使用的数据集没有划分出验证集和测试集,通常是验证和测试都使用同一份数据,这会导致评价指标失真。于是,在 Musgrave, K. et al “A Metric Learning Reality Check.” ECCV (2020) 这篇论文中,作者对之前的work进行了打假,即对之前论文提出的模型严格地使用完全一样的参数,进行训练和检测,具体参数如下:

结果也非常魔幻,作者发现,这些论文提出的方法实际上和最早的模型性能差别不大,甚至更差:

下图更加直观,左边是每篇paper中所展示的模型提升趋势,右边是实际的模型性能:
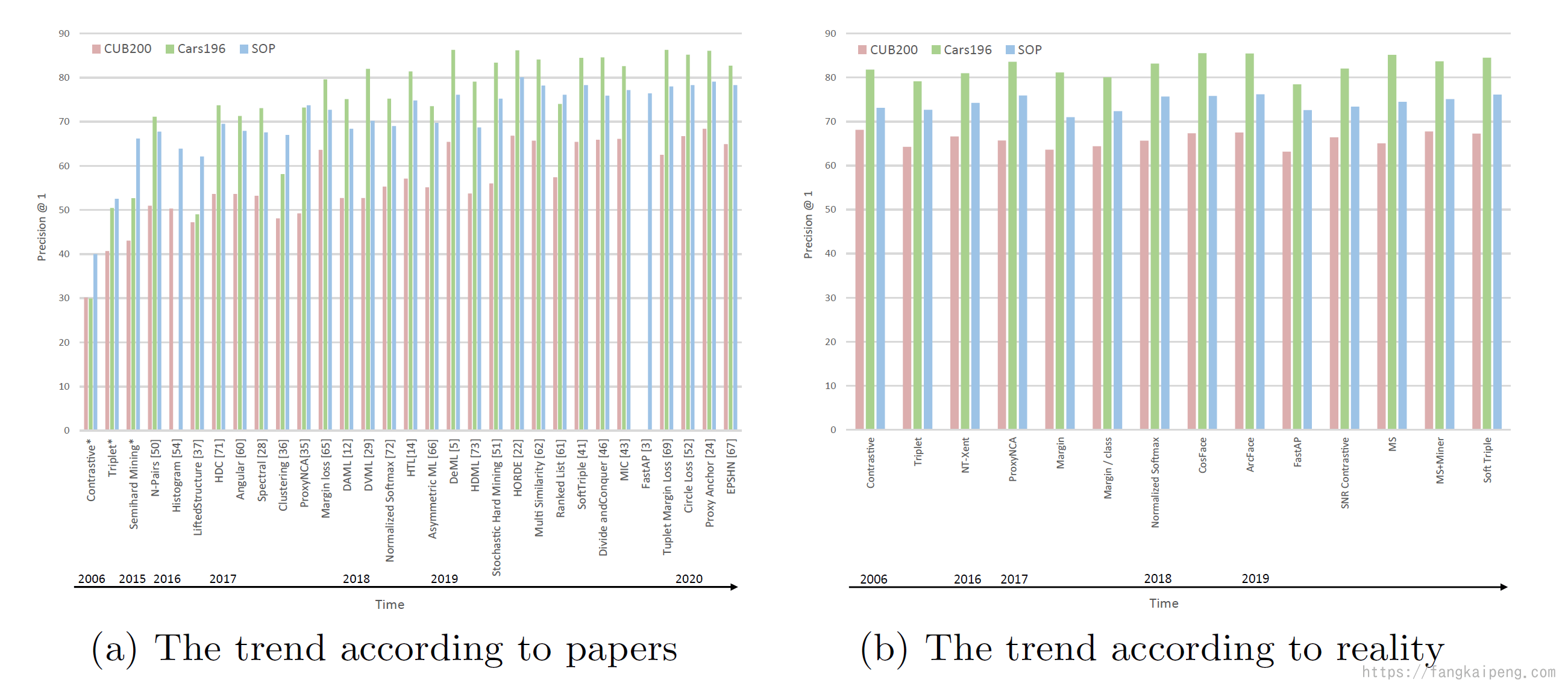
但这里也引发了一个思考:
在训练模型的时候我们真的必须严格保证,具有一样的学习率、一样的weight decay、一样的batch size,然后比较模型的性能吗?我们难道不应该使用跟好的优化器、更好的augmentation techniques,而是故步自封使用老技术吗?演讲者给出了一个优化的办法:在论文中同时展示使用标准方法训练的结果,和进行炼丹优化后的结果,这样可以有更公平的比较和更信服的结果。
下面是两个github的仓库,包含主流的DML方法的实现:
4. DML中评估真实的OOD-G性能
4.1 OOD-G概念
DML的目标是学习一个representation,可以反映
首先,评估OOD-G能力的最大一个问题就是,测试集分布的可能性是几乎无限的,如下图右所示。也就是说,我们在评估时需要考虑测试集分布的广泛,以及从训练集泛化到某个测试集的难易程度。
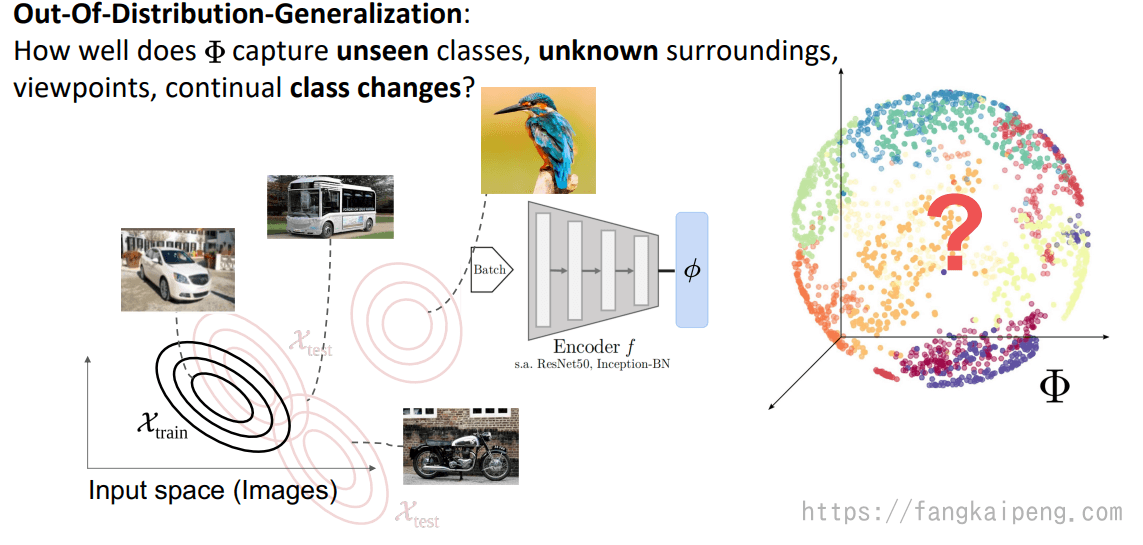
4.2 当前评估方法的缺陷
然而,实际情况是,在验证模型时,只会考虑一个单一的固定比例的数据集划分,所以这个从训练集向测试集泛化的难易程度是固定的。同时,也存在通过超参数调优来提升模型性能的情况,这也会导致模型实际上是对某种分布的测试集拟合了,而不是真正的泛化能力的提升。
所以,为了制定一个真实的衡量OOD-G性能的协议,下面这篇论文提出了一个要求:
- 首先是某个训练集和测试集之间泛化的困难程度需要可以衡量、改变以及控制。
- 同时验证的时候需要考虑多种不同难度的泛化。
- 数据集的构造需要相互独立,以此可以更好地比较不同划分方式的数据集。
Characterizing Generalization underOut-Of-Distribution Shifts in Deep Metric Learning
论文中提出了一个方法:ooDML,用来衡量DML中的OOD-G性能。
4.3 衡量泛化难度
首先介绍一下FID的概念,其实它和Metric Learning的思想很像,我们要衡量两个数据集的分布差异,但是他们可能服从不同的分布,就无法直接比较。所以FID就先使用一个预训练的Inception V3模型,将数据集中的每个样本都转变成一个特征,相当于将两个数据集映射到了同一个空间下,并且这里有一个假设就是,Inception V3输出的embedding是服从高斯分布的。这样,我们就能比较两个数据集的差异了,具体则是用到了两个数据集的均值和方差,公式如下。

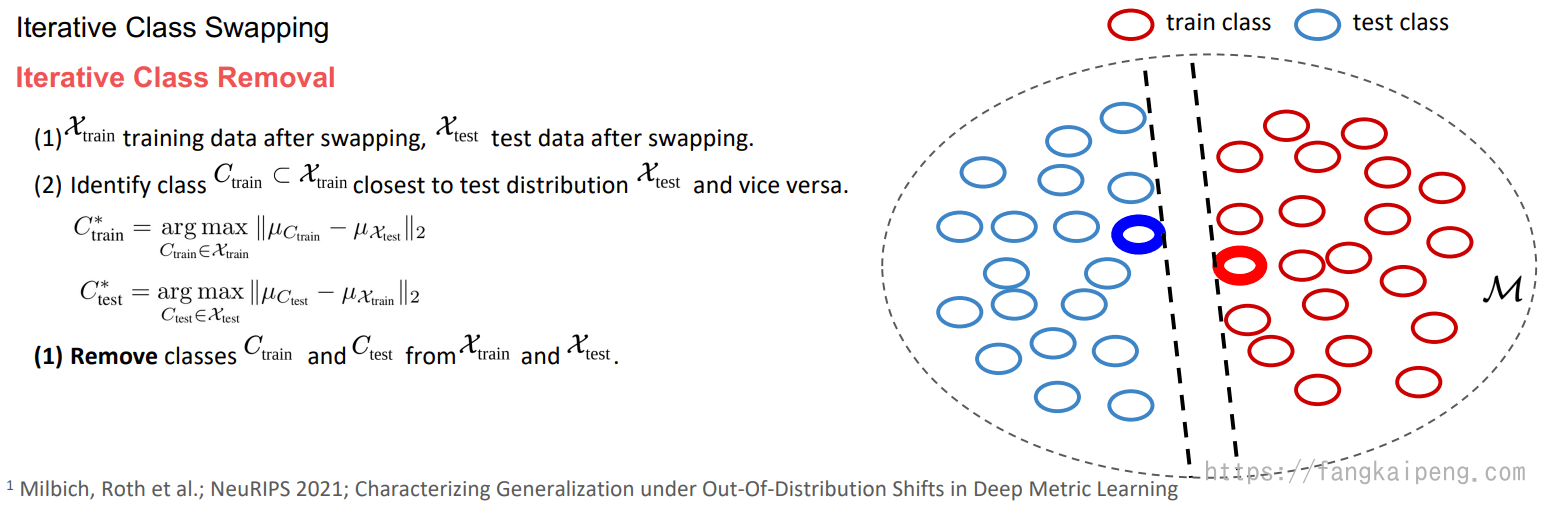
那么现在有衡量两个数据集差异的方法了,也就有了衡量从训练集泛化到测试集的难易程度了,自然是两个数据集差异越大越难泛化。衡量的问题解决了,下面就是改变和控制。论文中提出了迭代得交换类和删除类的方法,下面分别介绍。
4.4 控制泛化难度
首先是以一定的策略交换测试集和训练集中的整个类(即交换两个类的全部样本)。具体选择哪两个类进行交换,取决于下面的公式。其思想就是交换差异大的两个类。

随着交换次数的增加,发现FID也在增加,如下图,表面了这种交换策略的可行性:
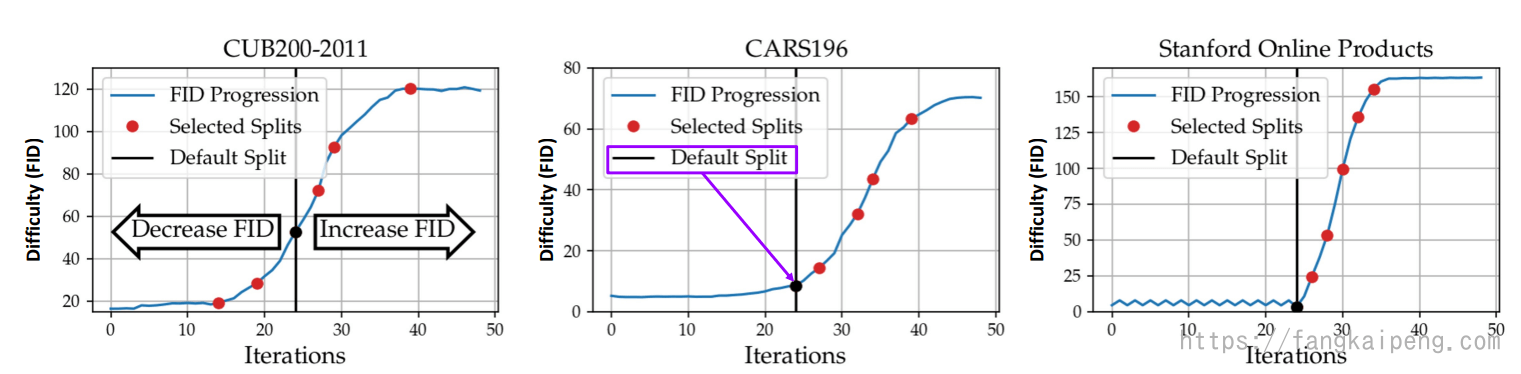
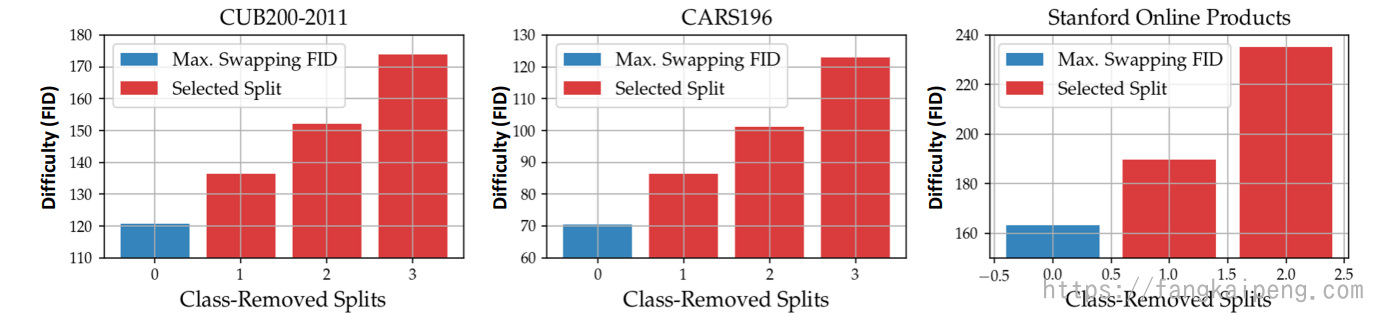
但是可以发现,经过几十次迭代后,FID的增长趋于平缓,为了进一步增加FID,论文中提出了删除类的办法。其思想就是删除位于两个数据分布相邻位置的类(这些类比较相似)。
实验后发现,删除若干类后,FID能进一步增加:
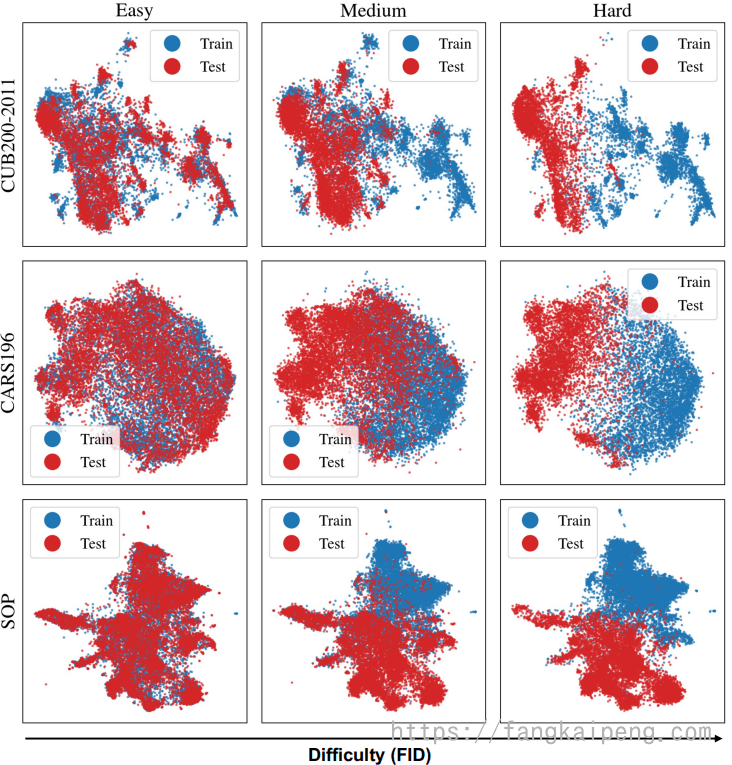
如下图是不同数据集在不同FID下的可视化结果:
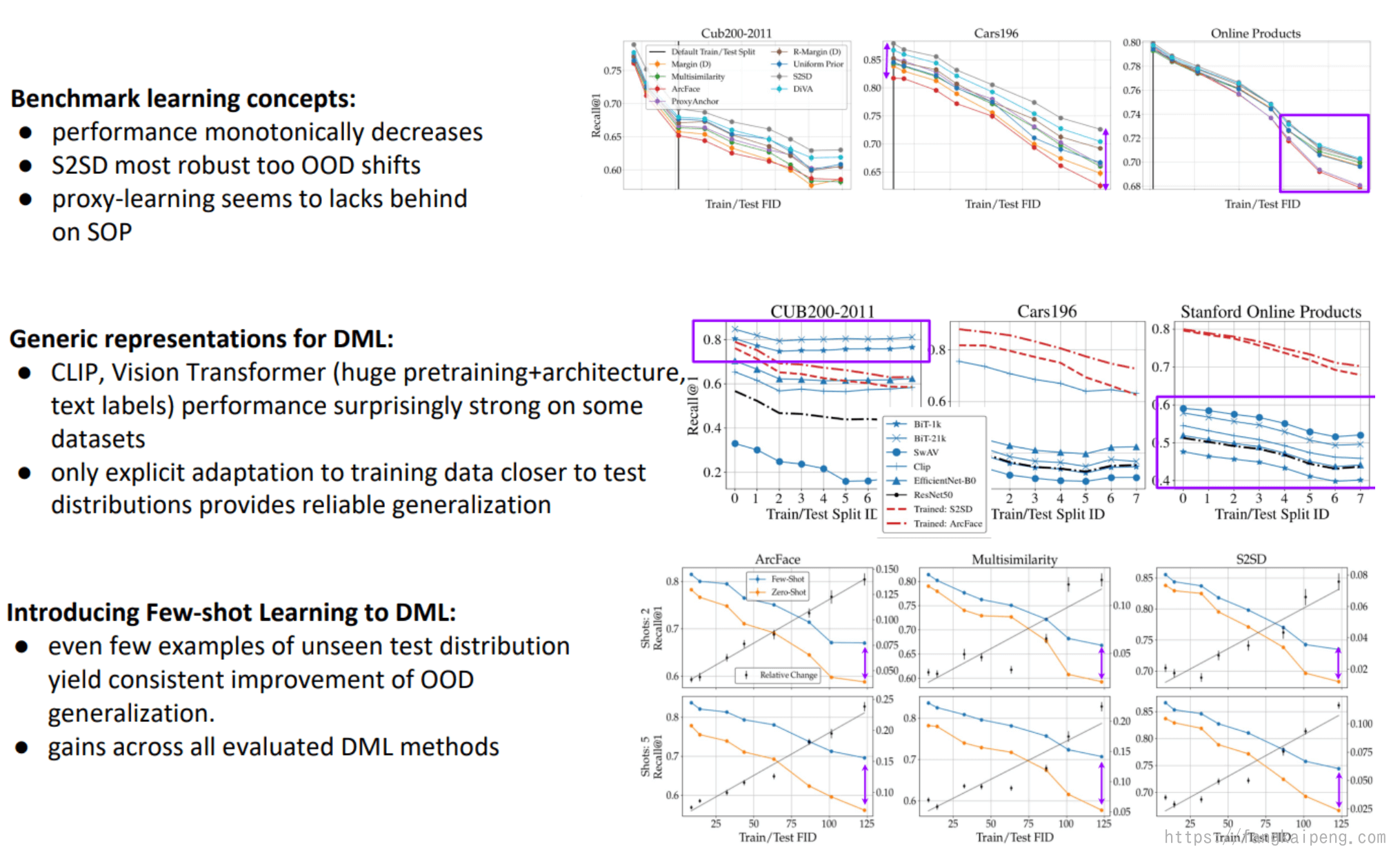
4.5 一些实验结论
5. DML在其他领域的应用
这一章主要涉及DML在一些具体领域的使用,没有深入研究,贴上PPT,备用。

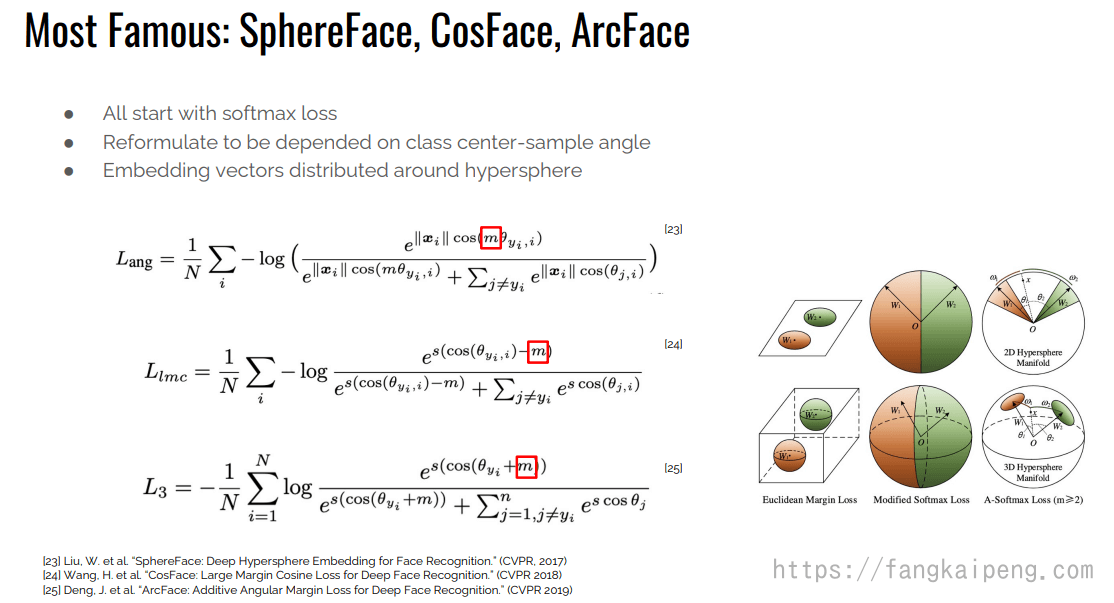
5.1 Face Recognition

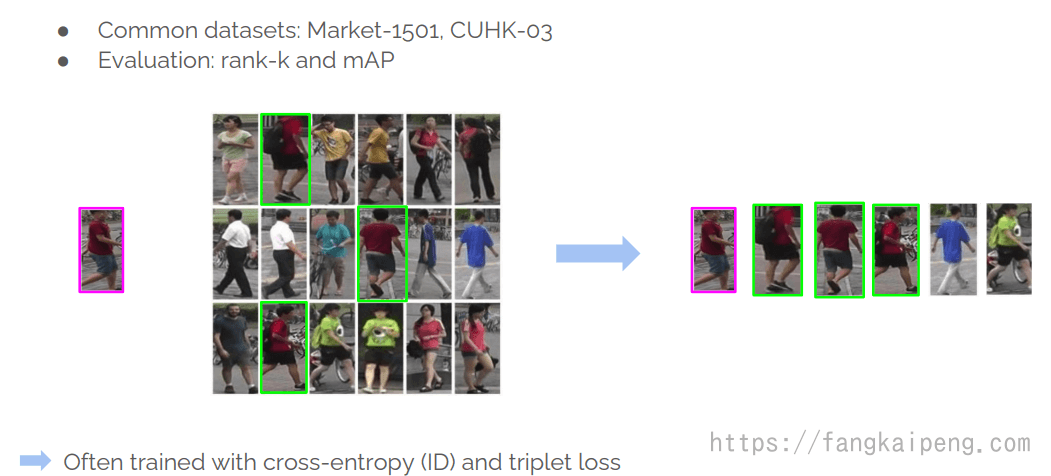
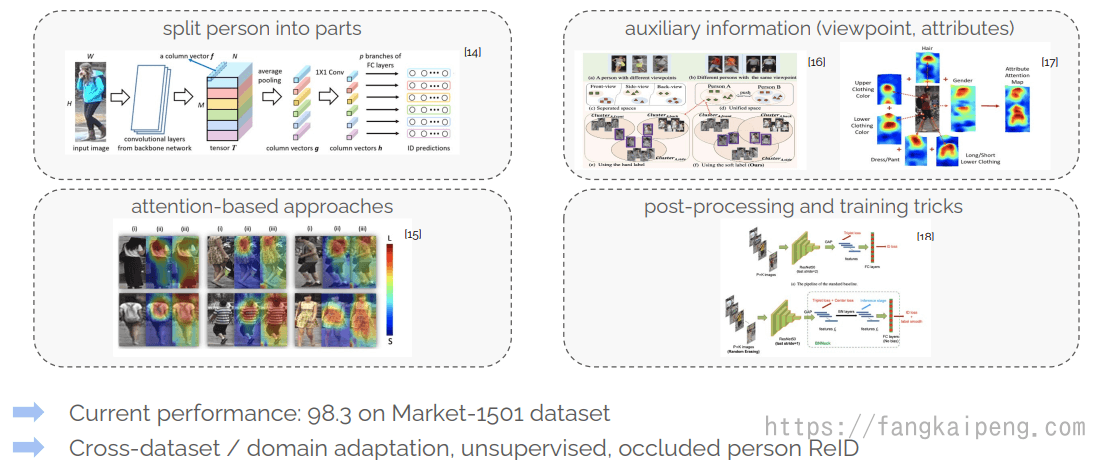
5.2 Person ReID
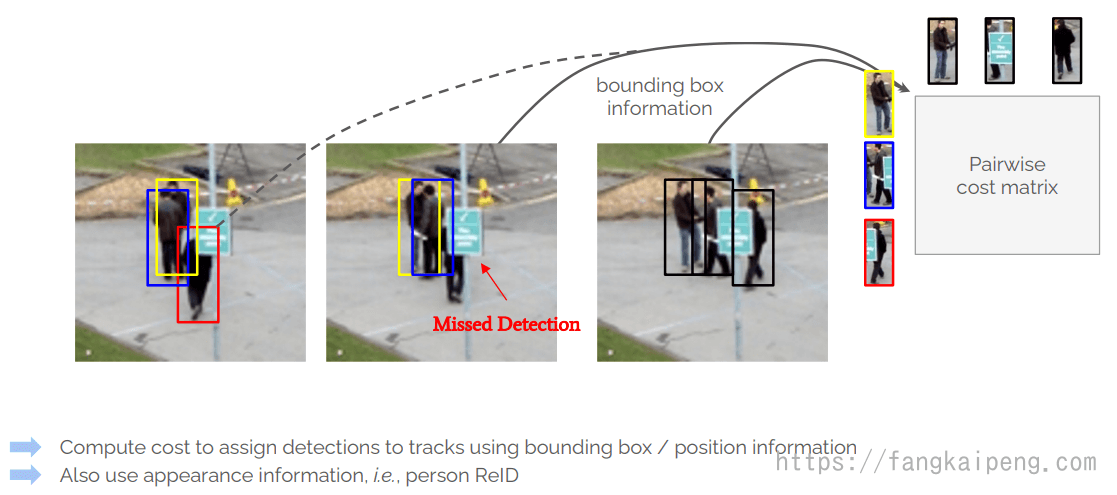
5.3 Multi-Object Tracking
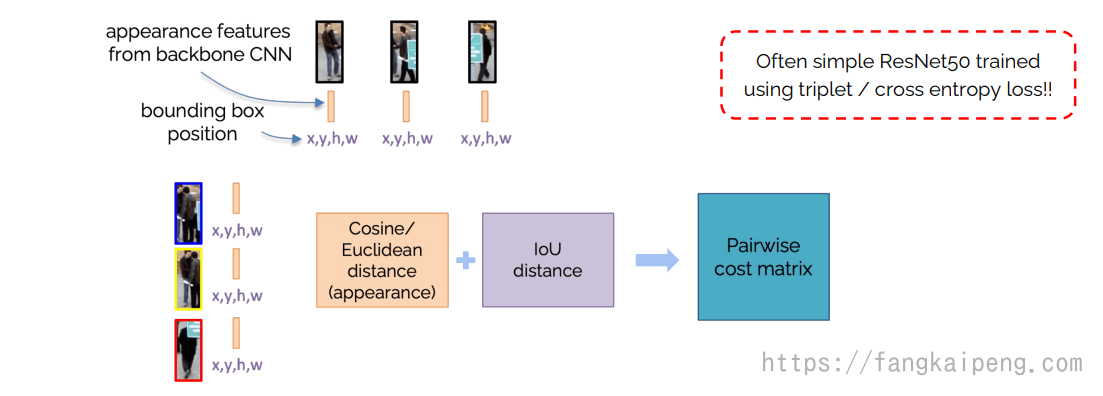
5.4 Zero- / One- / Few-Shot Learning


5.5 Self-Supervised Learning

Contrastive Learning

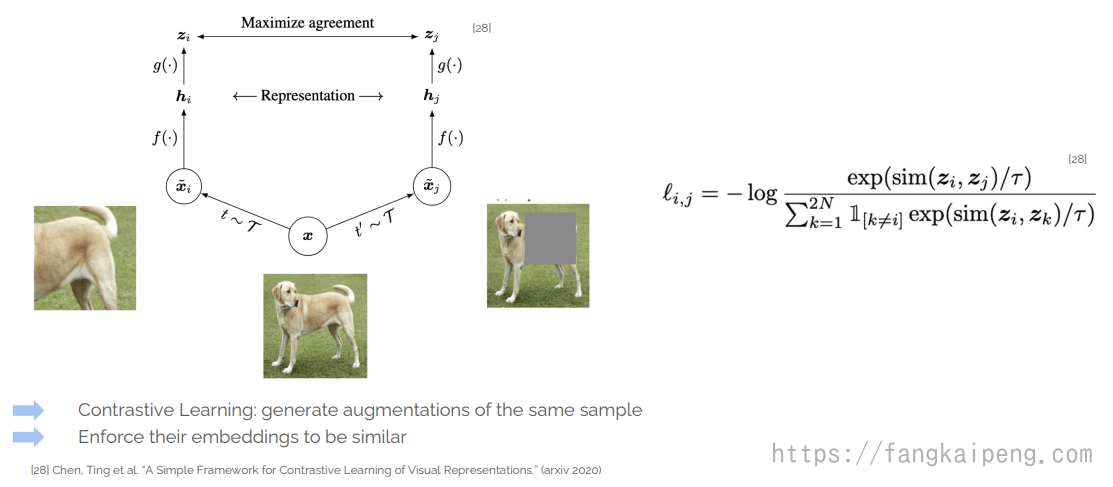
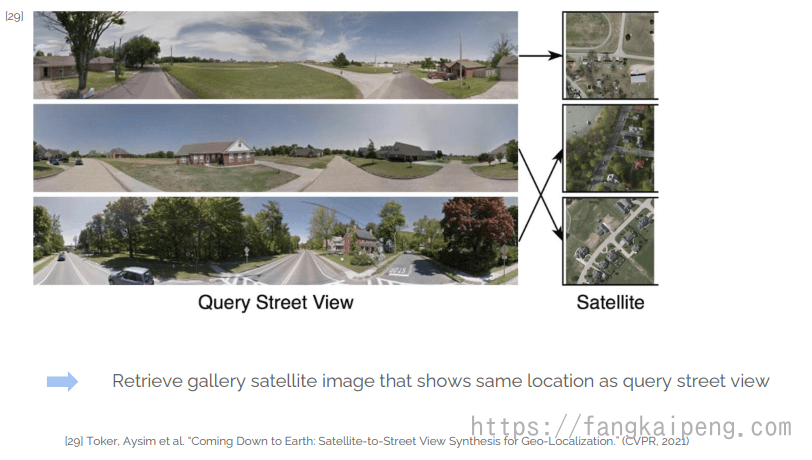
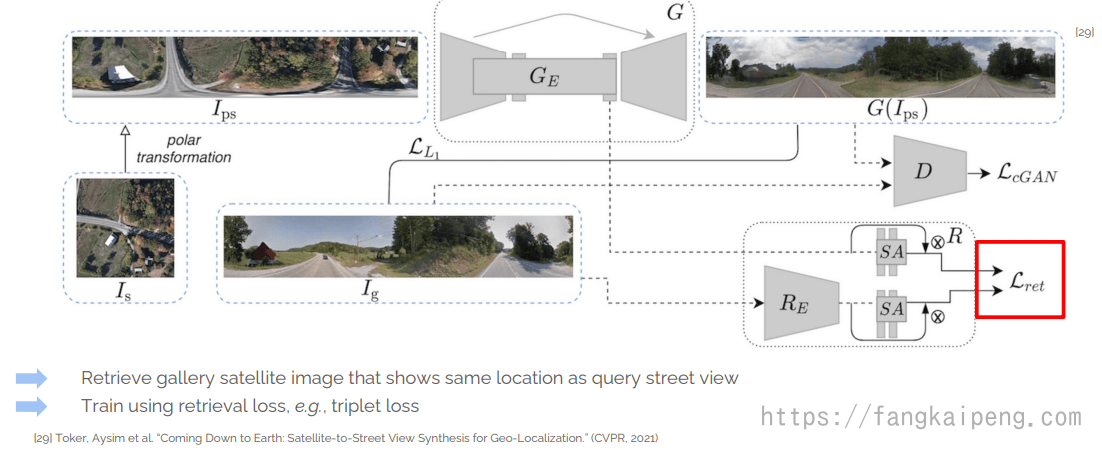
5.6 Geo Localization

写得很好很详尽,收藏了慢慢看
谢谢