0. 前言
算是第一次正经的调研吧,之前就做过论文复现和 “不成功” 的调研。至于为什么不成功呢?主要因为我是0基础的科研小白,所以对调研目的的认知错误。其实在年前做过一次关于 Out-of-distribution 的调研了,但是为什么现在又花了差不多一周的时间重新做了一次呢?因为我一开始调研的目的是了解一下这个领域,看看有没有可以用于我当前方向的方法(我当前的方向比较新,只能从类似的任务中借鉴)。所以,我第一次调研的时候,就直接把OOD的方法和我当前的方向做比较,如果没有什么关联就跳过。实际上这是错误的一种调研。
回来和导师交流后,导师说调研是problem-driven的,而不是approach-driven的,意思是要对调研方向有整体的把握,理清任务的setting和当前的问题,得出一些总体性的结论,而不是简单的看一下这个领域用到的方法是什么。这样做的原因是,首先你对你自己的方向可能没有很深的认知,单纯比较调研方向的方法能否为我所用,可能会受制于当前认知的限制,错失很多潜在可用的方法。其次,对调研方向有一个整体的认知,可以让你更好地搭建自己的知识树,拓宽眼界。
总体来说,调研需要了解的有:
- Task的setting (任务设定、数据集、评价指标、Baseline)
- Task面临的problem (深层的难点是什么)
- 解决problem的approach (代表性的方法有哪些)
- 主要团队和时间线 (了解趋势)
- 宏观性的结论
- 借鉴到自己的Task中
好了,唠叨完了,进入正题!下面是对本次调研的一个笔记(其实就是把PPT又重新转换成了笔记的形式)。
1. 任务定义
1.1 背景和任务定义
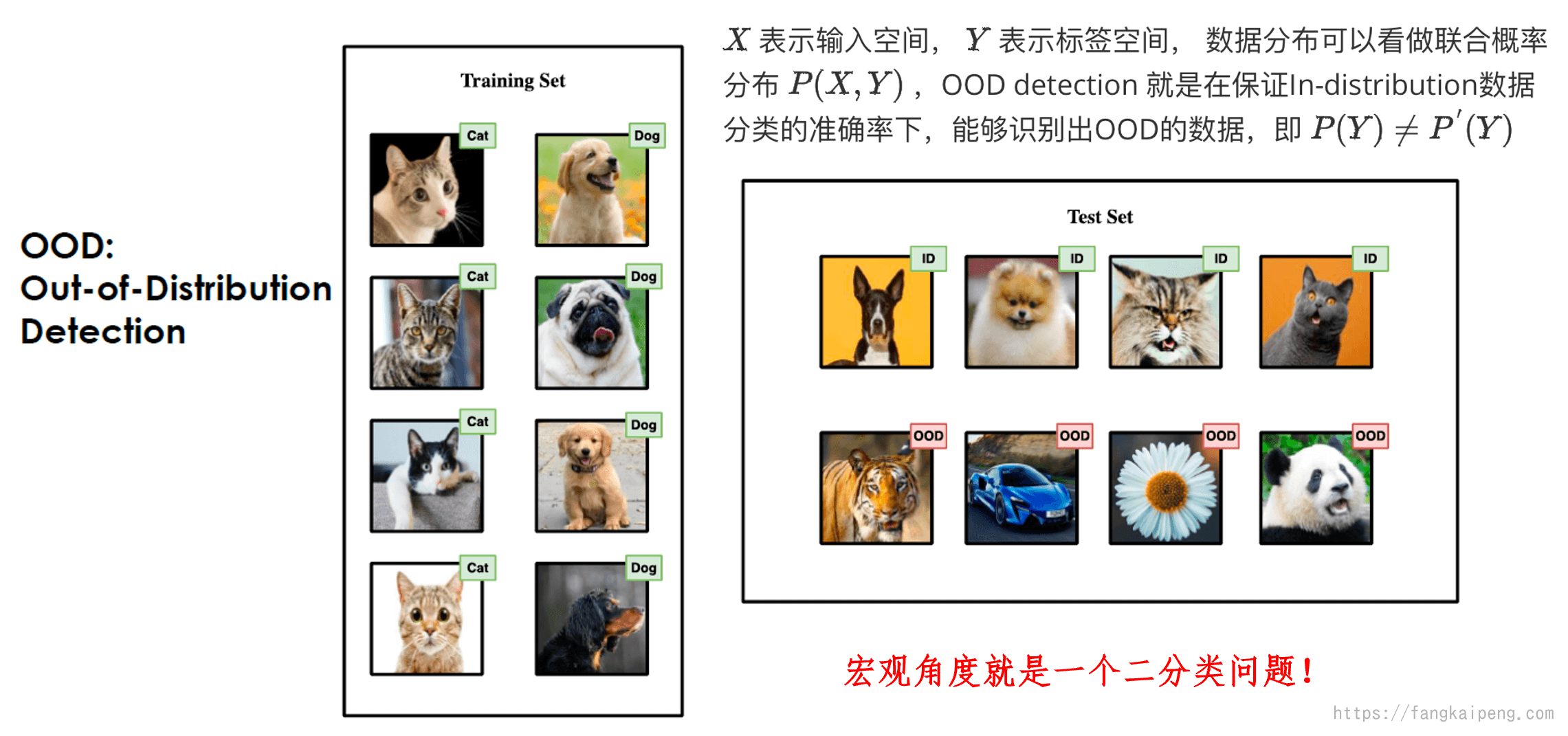
OOD detection任务(后面简称OOD)解决的问题就是如何检测出 Out-of-distribution 的样本,同时能维持In-distribution样本分类的准确率(数学定义见下图)。那么什么是In/Out distribution呢?distribution shift主要分为两种,一种是semantic shift,一种是covariant shift,前者表示训练集和测试集的label space不同,后者表示训练集和测试集数据本身的分布不同。而OOD主要关注的是semantic shift,因为OOD提出的背景是在open-set的场景下,模型可能会遇到很多在训练阶段没见过的类别,而模型依然会给这些样本预测一个很高的置信度(认为其属于某一类训练集中的类别),这也成为over-confidence,这也的模型是不可信的。理想情况是,当模型遇到没见过的样本,会学会拒绝,不进行分类,只对见过的样本进行分类,因此提出了OOD detection任务。
注:这里的见过和没见过指的是,这些样本属于的类别是否属于训练集中的类别
1.2 数据集和评价指标
OOD任务中主要有两类数据集,ID和OOD数据集,ID数据集用于训练,OOD数据集用于测试。此外还有辅助数据集,用于辅助训练,后面会介绍到。常用的评价指标为下图中的加粗,具体含义自行google。

2. 相似任务
具体含义详见论文:Generalized Out-of-Distribution Detection: A Survey
3. 发展状况
3.1 时间线
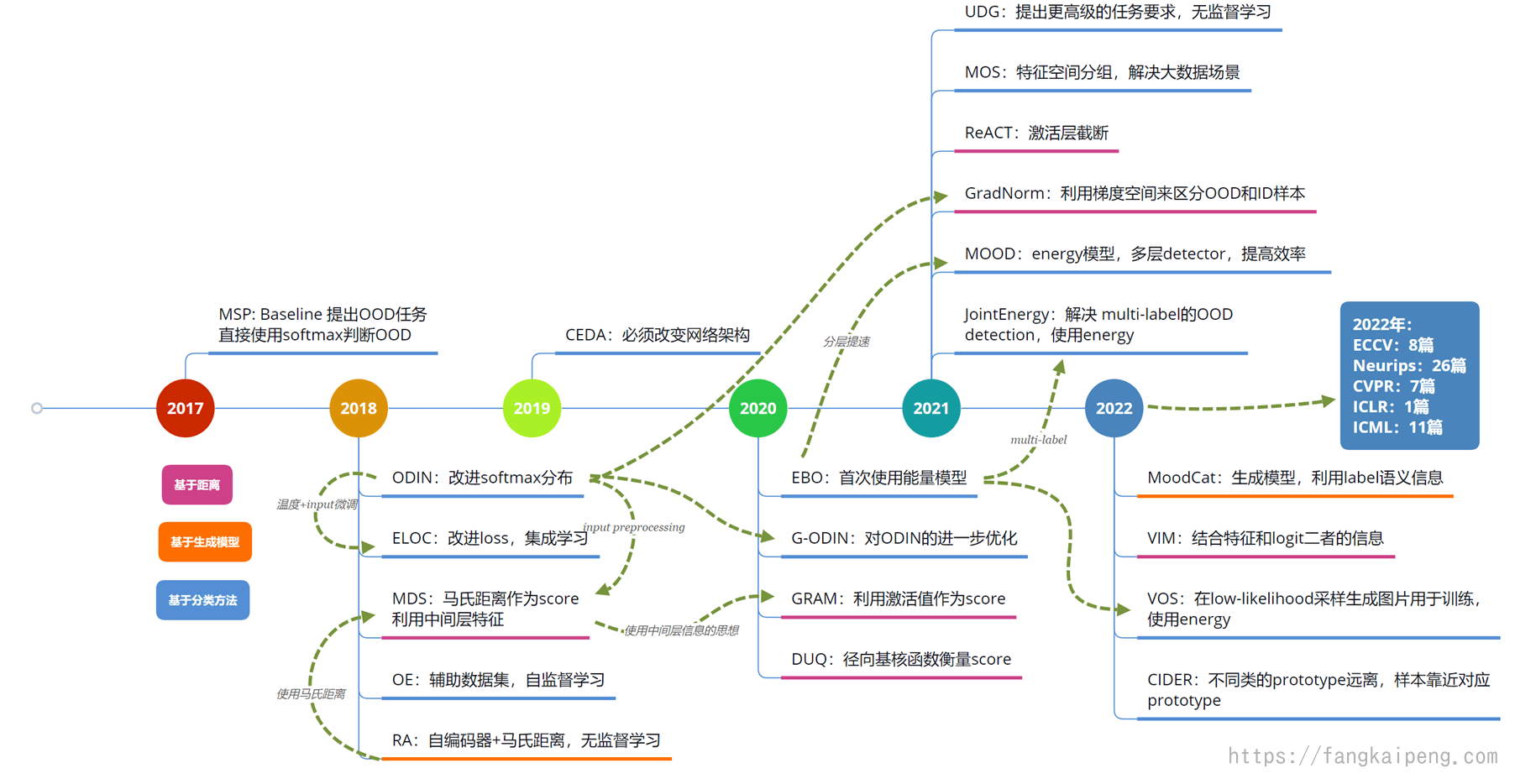
3.2 主要团队

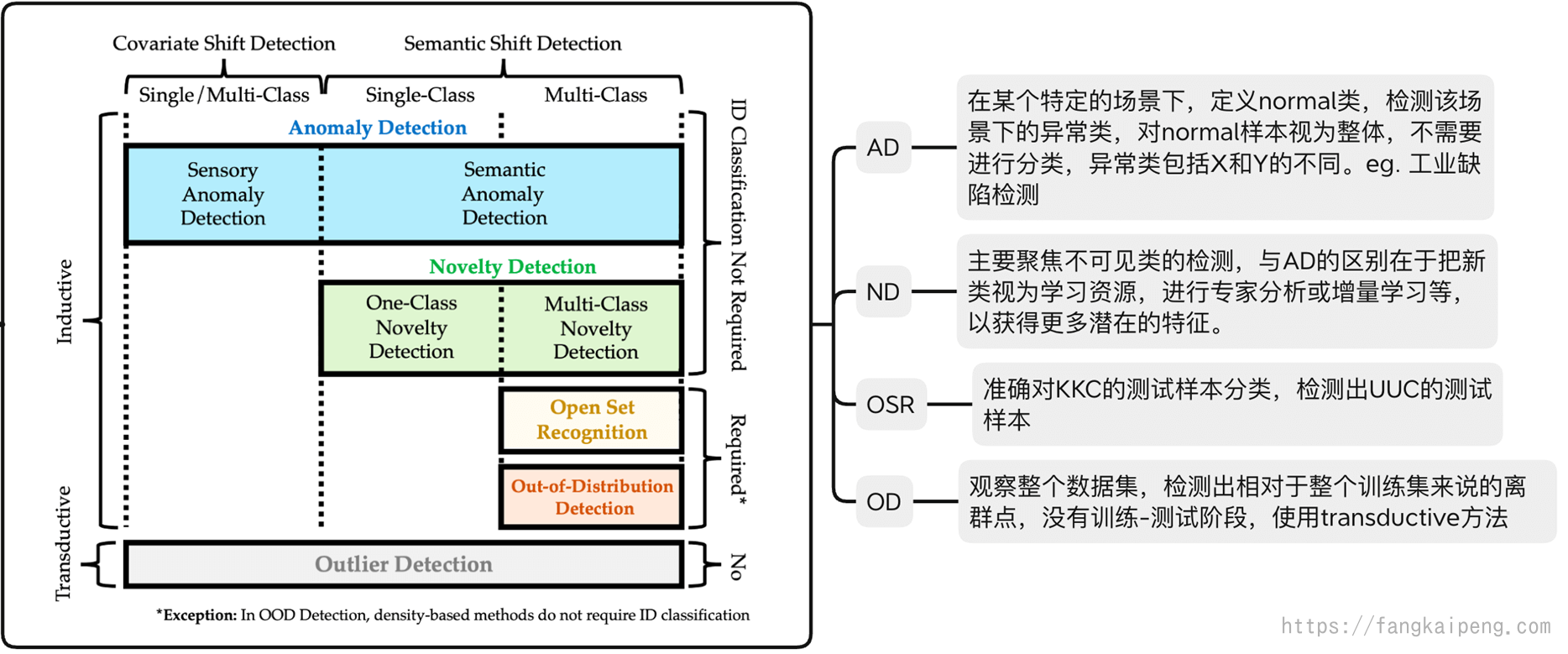
4. 任务分类
4.1 本质问题
我认为当前OOD detection的主要问题是如何解决以下两个难点,也刚好对应深度学习的两个阶段:
- 训练阶段:如何更好地表示模型,即如何挖掘出数据中对OOD有用的信息,如何提取出更好的特征(比如让ID和OOD在特征空间中相互远离)
- 测试阶段:如何更好地利用数据,即如何更好地利用挖掘出的信息和特征(比如拉开ID和OOD得分分布的差异)
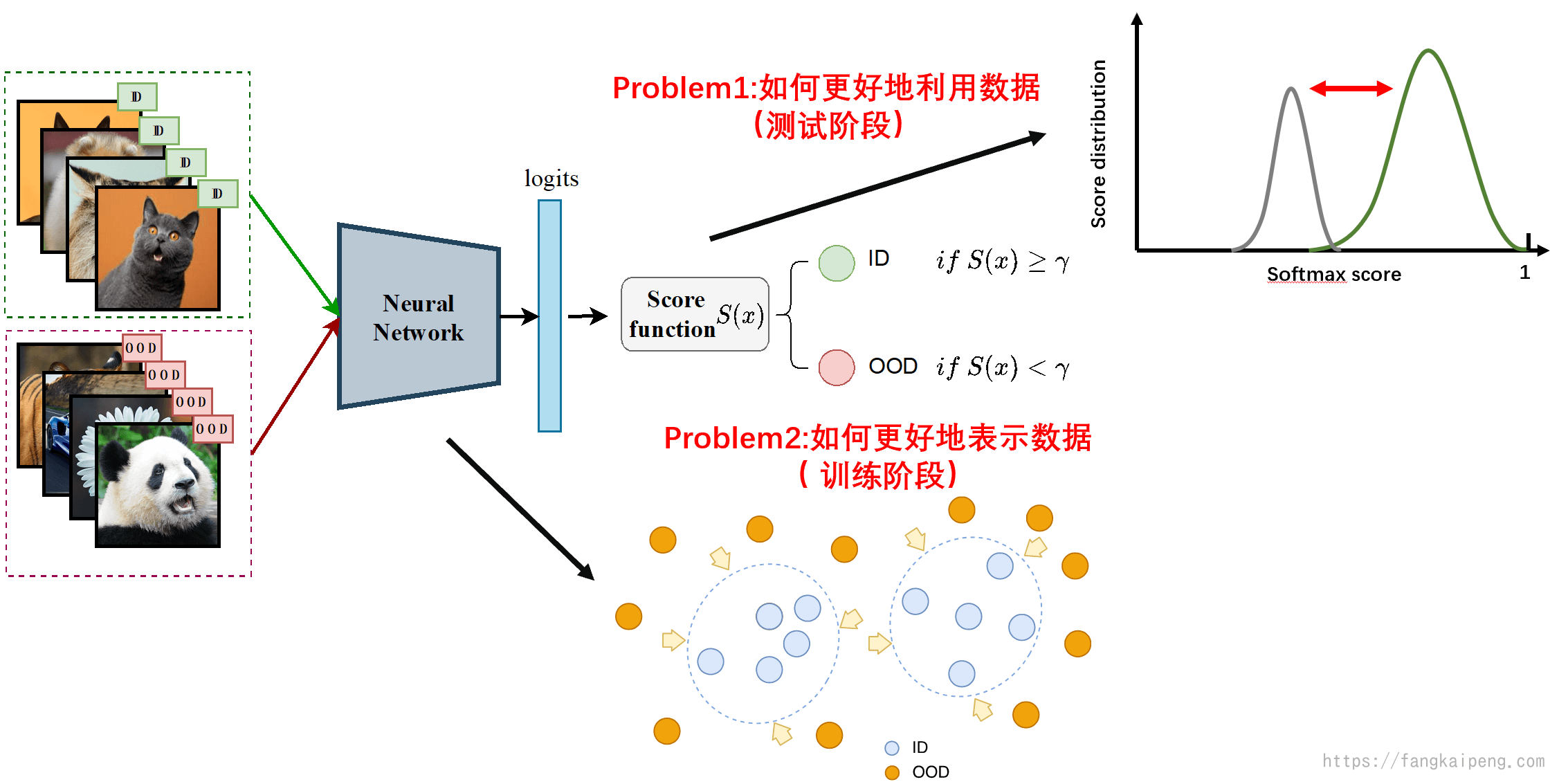
4.2 测试阶段任务分类
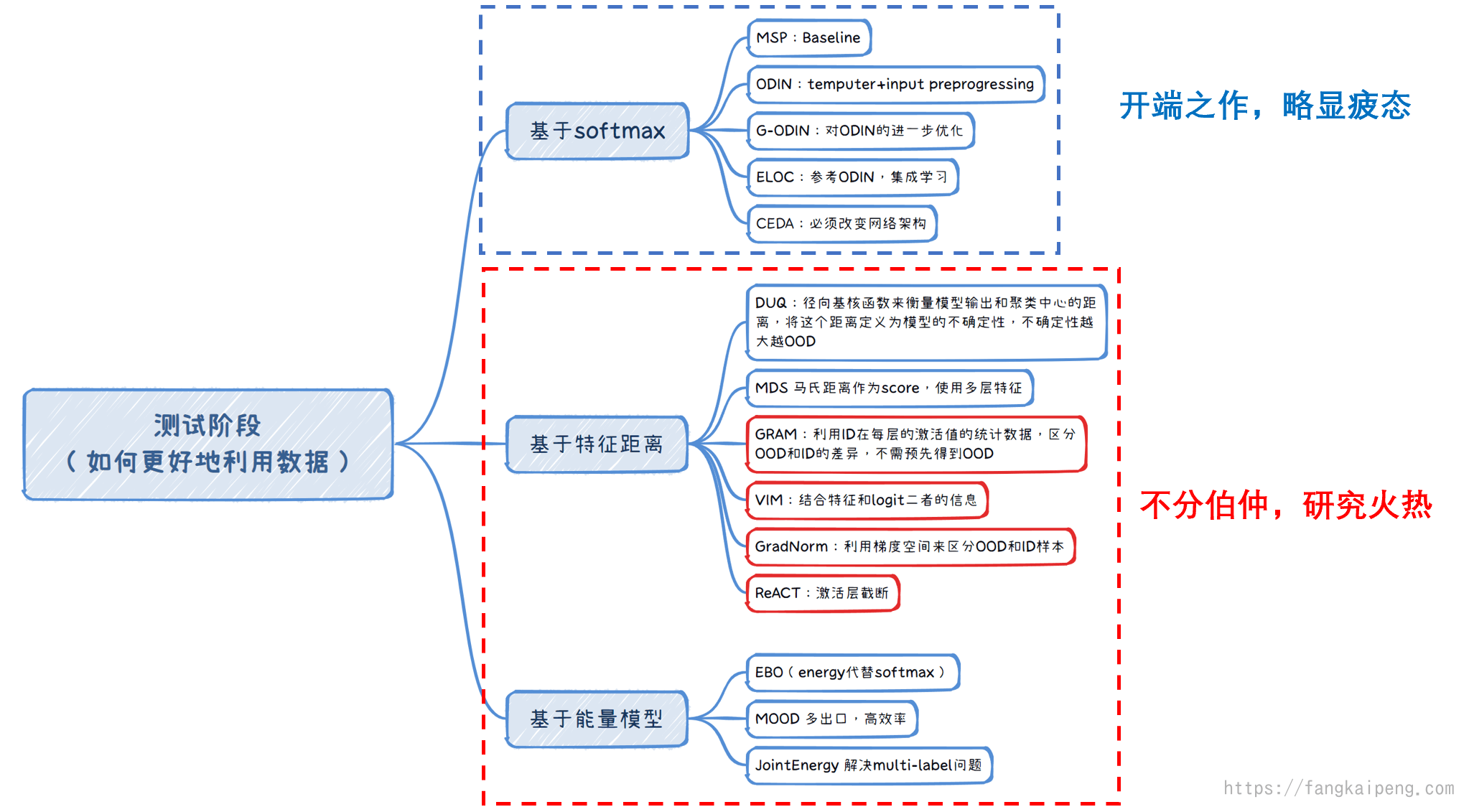
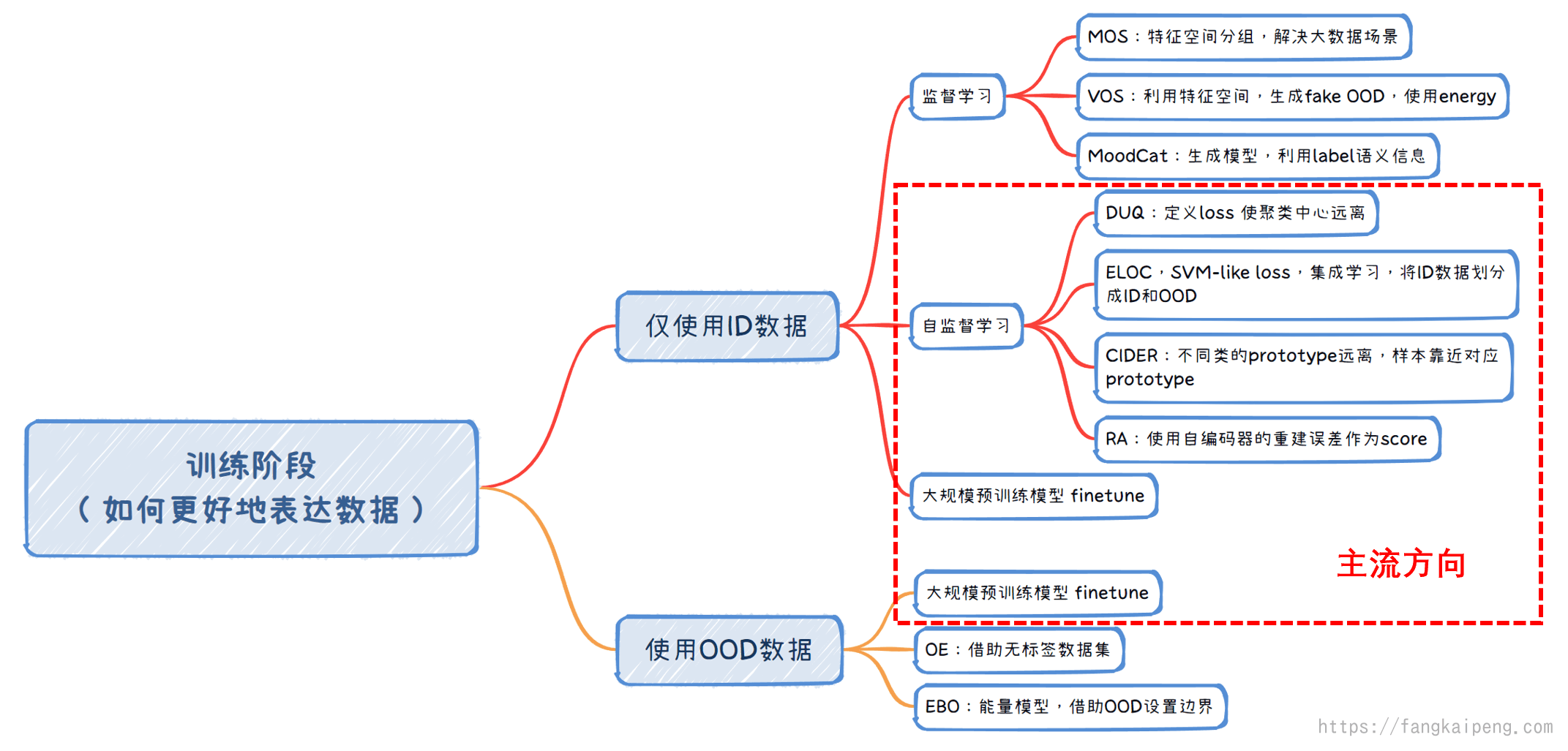
4.3 训练阶段任务分类
5. 测试阶段代表方法
5.1 基于SoftMax的方法

A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks
OOD detection任务的开篇之作,作为Baseline,其检测OOD样本原理非常简单:
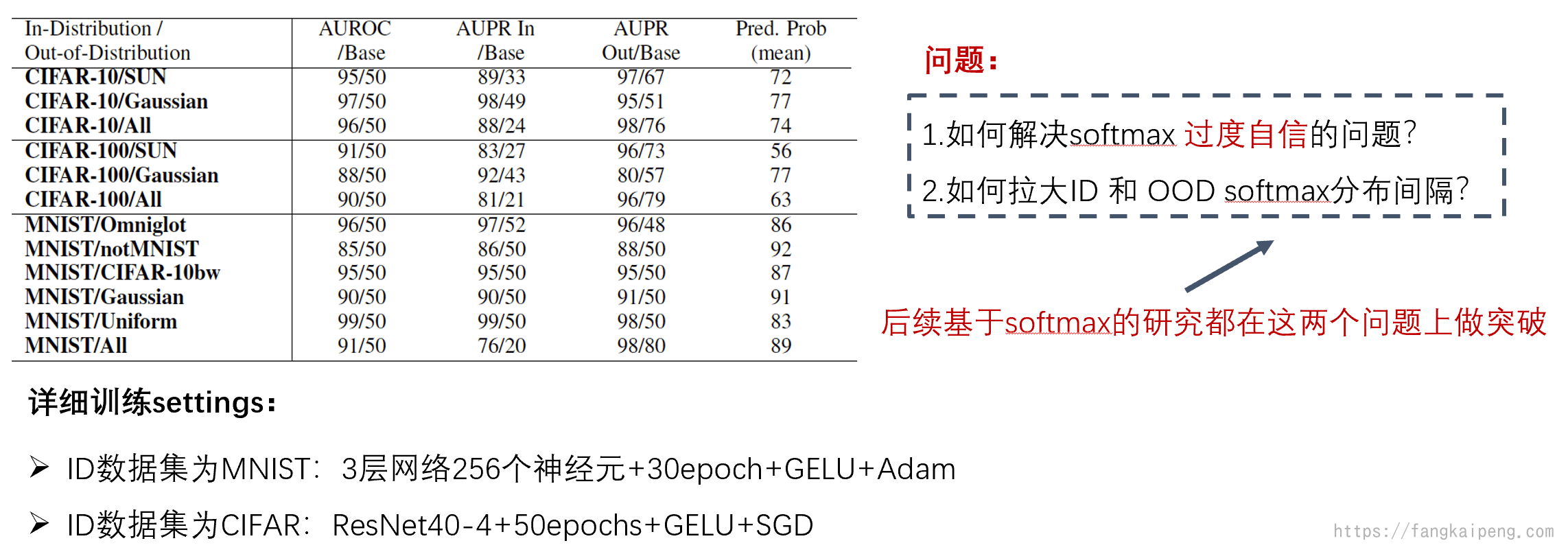
直接依据模型输出的Softmax值,作者发现ID样本的最大softmax分数大于OOD样本的最大softmax分数,因此就可以设定一个阈值来区分OOD和ID样本了。
下面是实验结果,可以发现AUROC和AUPR的数值都比随机(表中的Base)好。其中AUPR In表示将ID数据作为正样本,AUPR Out表示OOD作为正样本。Pred.Prob(mean)表示模型对于OOD样本输出的最大softmax的平均值,可以发现数值上任然较高,这也说明,虽然可以用softmax的值作为划分依据,但是模型对OOD样本也能输出一个较高的softmax,也就是过度自信了。
总的来说,基于softmax的方法需要解决的问题可以归纳为下图中的两个。
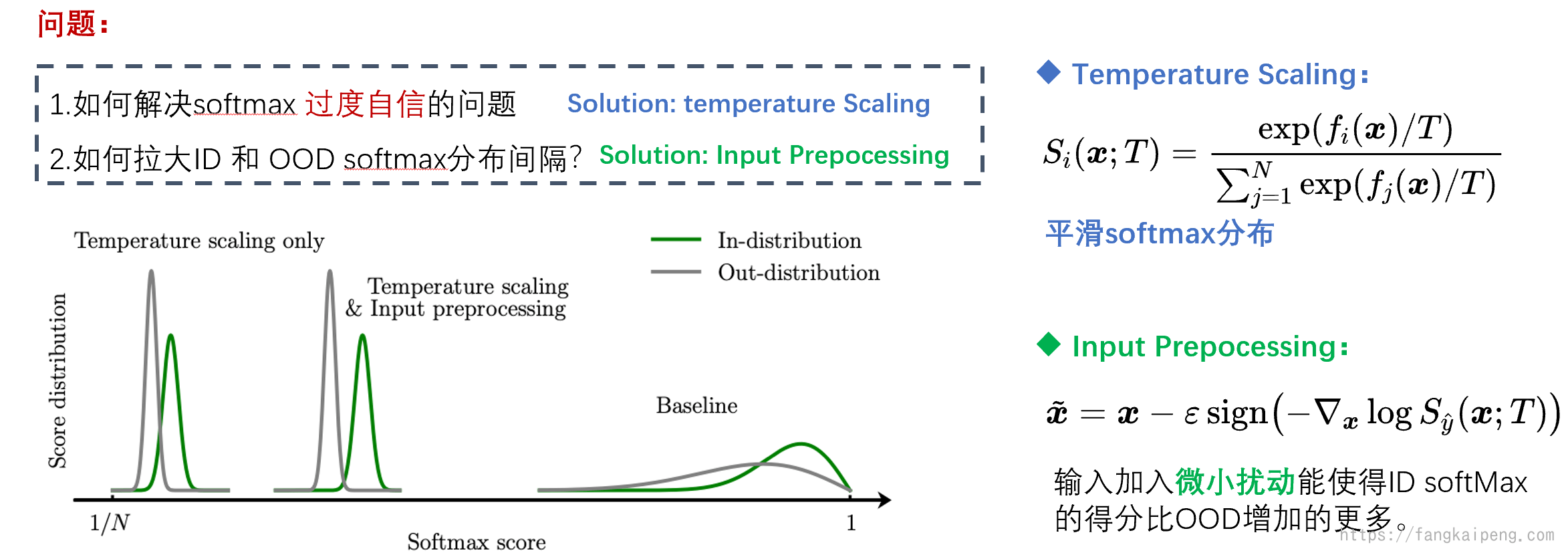
Enhancing The Reliability of Out-of-distribution Image Detection in Neural Networks
于是就有工作对上面的方法进行改进,具有代表性的就是ODIN,首先使用温度系数来平滑softmax分布,以此解决OOD样本过高置信度的问题。然后使用input prepocessing来拉开OOD和ID之间的距离。其原理是,给输入的图片增加一个微小的扰动,可以使得ID样本的softmax 最大得分比OOD增加的多,这样就能拉开差距了。具体方法是借助梯度实现的,不过多介绍。
Why relu networks yield high-confidence predictions far away from the training data and how to mitigate the problem
这篇论文对ReLU网络的本质进行了理论分析,认为ReLU网络本身就不适合用于OOD检测,因为他是一个分段线性函数,如下图所示,方框代表训练数据集所在分布,可以发现,在分布外的区域,网络也有很高的置信度。

不过,虽然本质无法解决,但是也可以通过一些方法缓解这种过度自信的问题,作者提出了ACET这个方法,其原理就是在数据分布的边缘进行采样,生成样本辅助训练,可以一定程度缓解过度自信的问题。

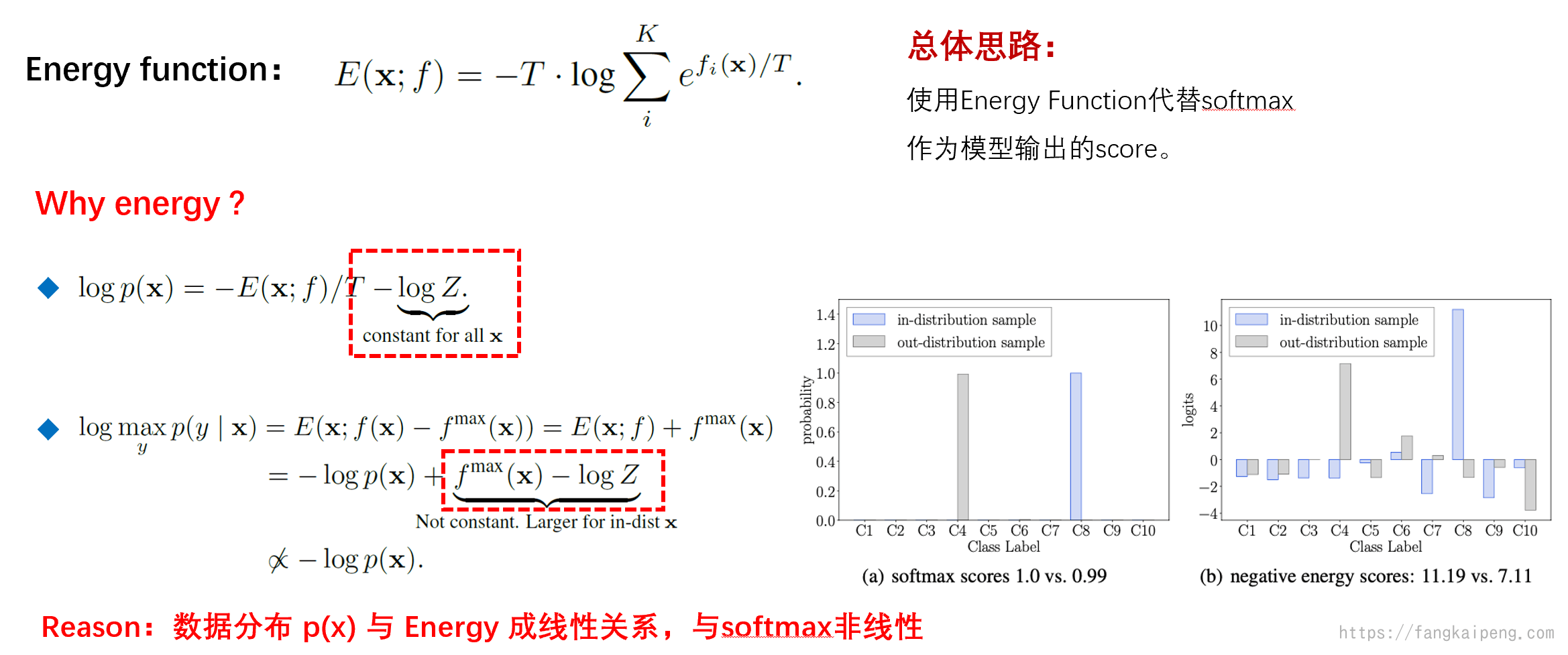
5.2 基于Energy的方法
将Energy首次使用到OOD问题中是在这篇论文中,Energy-based Out-of-distribution Detection,也就是直接使用energy function代替softmax,文中也给出了使用energy优于softmax的原因,如下图的公式所示,详细推导见论文。其结论就是,softmax函数与数据分布不成正比,所以无法很好的表达输入的数据,而energy和数据分布是成线性的。值得注意的是,后续提出的很多方法都使用energy function代替softmax作为score function了。
5.3 基于特征距离的方法
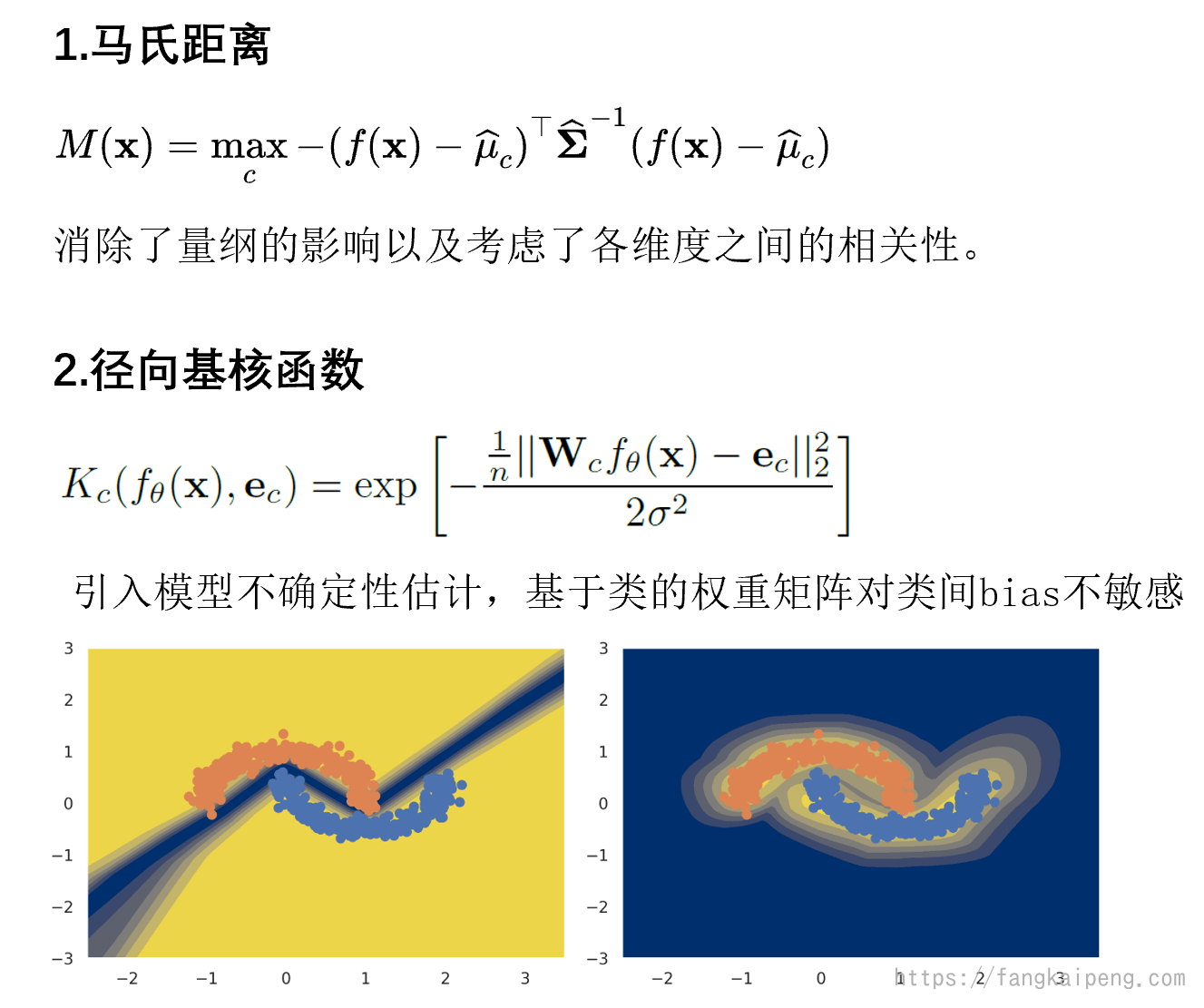
这一类方法,我认为可以归纳成两类(下图蓝色和红色两类):
- 蓝色这一类的特点是得到每个类别的一个prototype,然后计算样本到每个prototype的距离,距离哪个prototype越近,则认为输入的样本属于哪一类,当这个最近的距离大于某个阈值,则判定这个样本为OOD样本。
- 红色这一类则没有prototype,而是直接比较ID样本和OOD样本在模型计算过程中的差异,比如OOD和ID样本的特征值、logit数值、梯度值、激活值。然后将差异之和作为标准,大于某个阈值判定为OOD样本。

下面先介绍一下第一类方法,主要就是各类距离函数的选取,用的最多的就是马氏距离。而这类方法的主要问题有两点:
- 如何设计更好的距离函数,对输入的变动更加敏感。
- 如何获得更好的prototype,使其包含更多语义信息 。
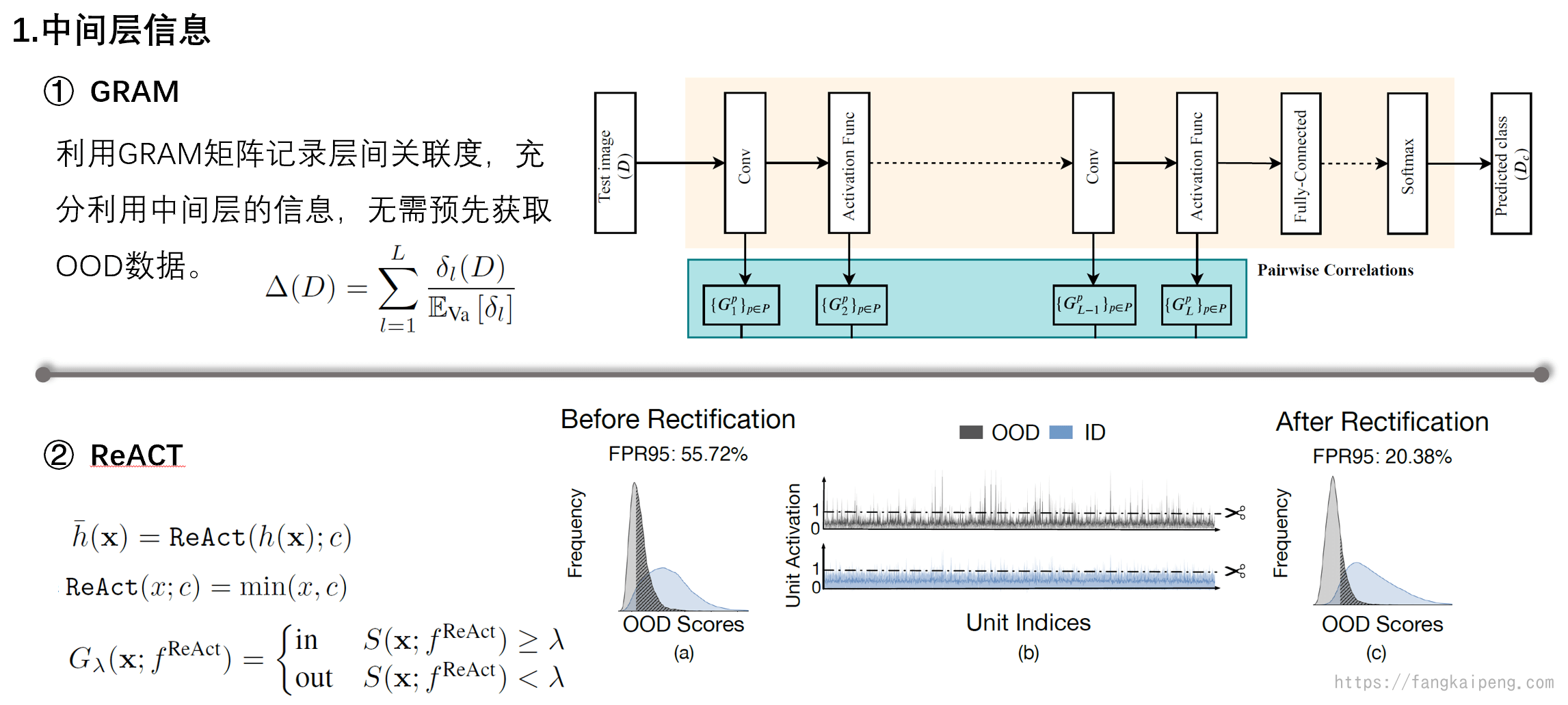
然后介绍第二类方法,即考虑数据本身的方法。
首先是利用中间层信息的方法,即利用activation来判断是否为OOD,主要有下面两种。
然后是利用梯度空间中的信息以及logit和特征的结合。
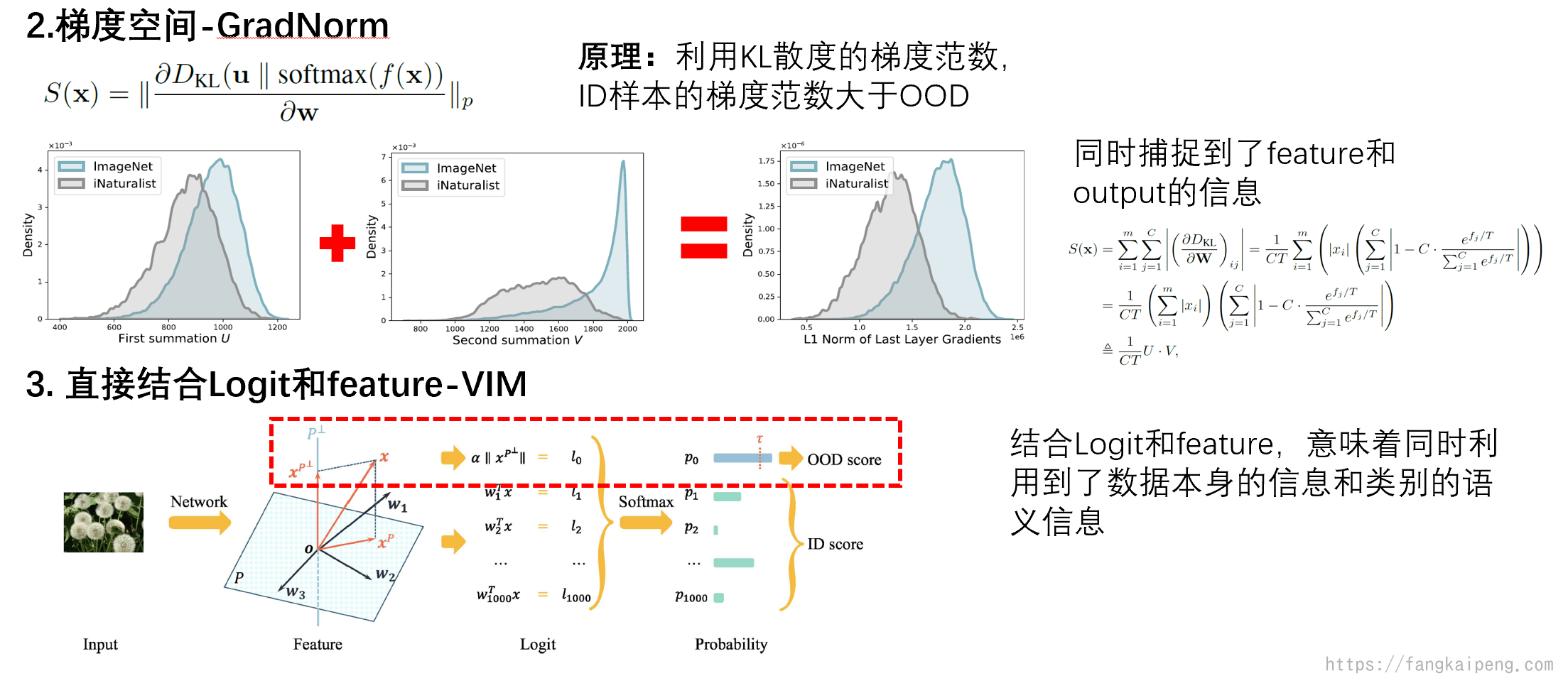
值得一提的是VIM,这一方法同时利用了Logit和特征值来判断是否为OOD。我们知道,特征值是模型提取的数据本身的信息,而Logit则是模型特征与每一类别的关联度。也就是说,同时利用Logit和feature,相当于同时使用了数据本身的信息和语义信息。而这种同时挖掘数据本身的分布和样本空间的分布成为近阶段主流。
6. 训练阶段代表方法
6.1 仅使用ID数据
下图所示说明了,模型如果对ID数据能有一个好的分类性能,那么OOD检测的效果相对来说也会好。所以,如何提升ID分类性能也是一个可以研究的方向,自然而然,使用大模型进行OOD成为了很自然的事情。
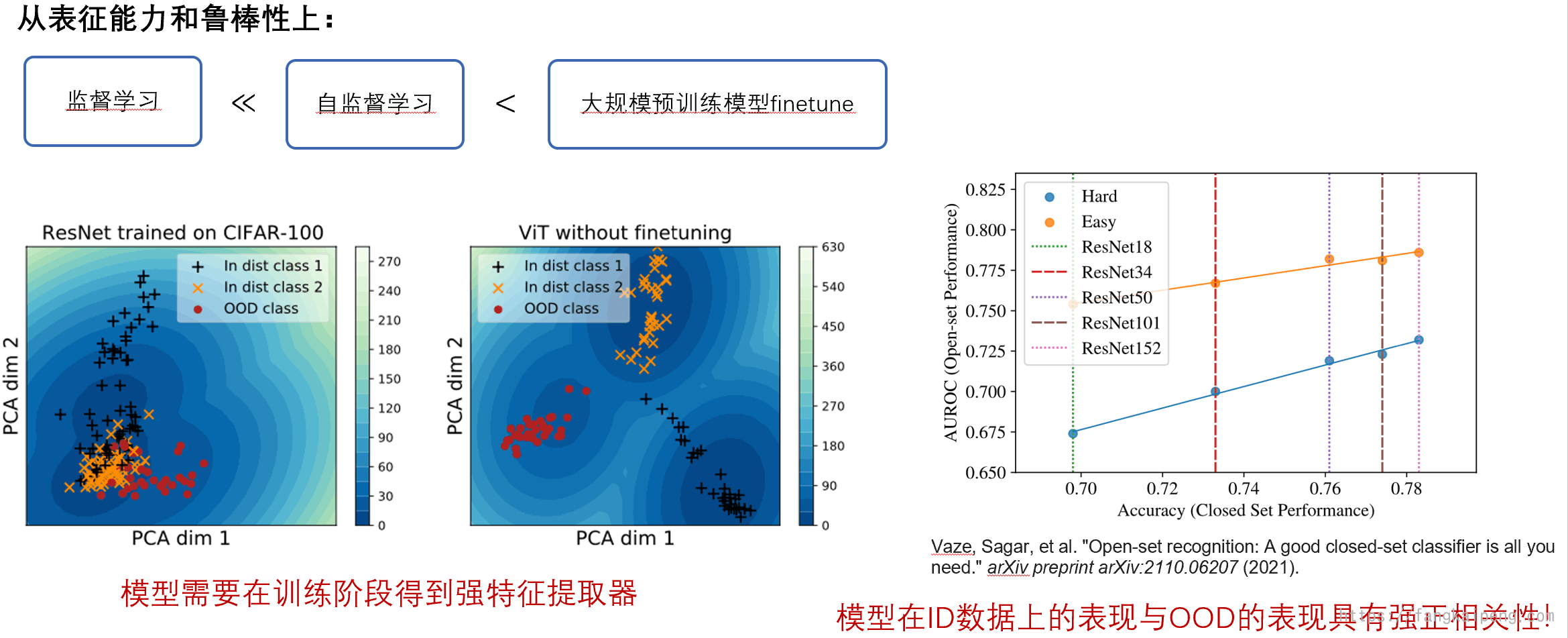
6.2 使用OOD数据

6.3 预训练大模型
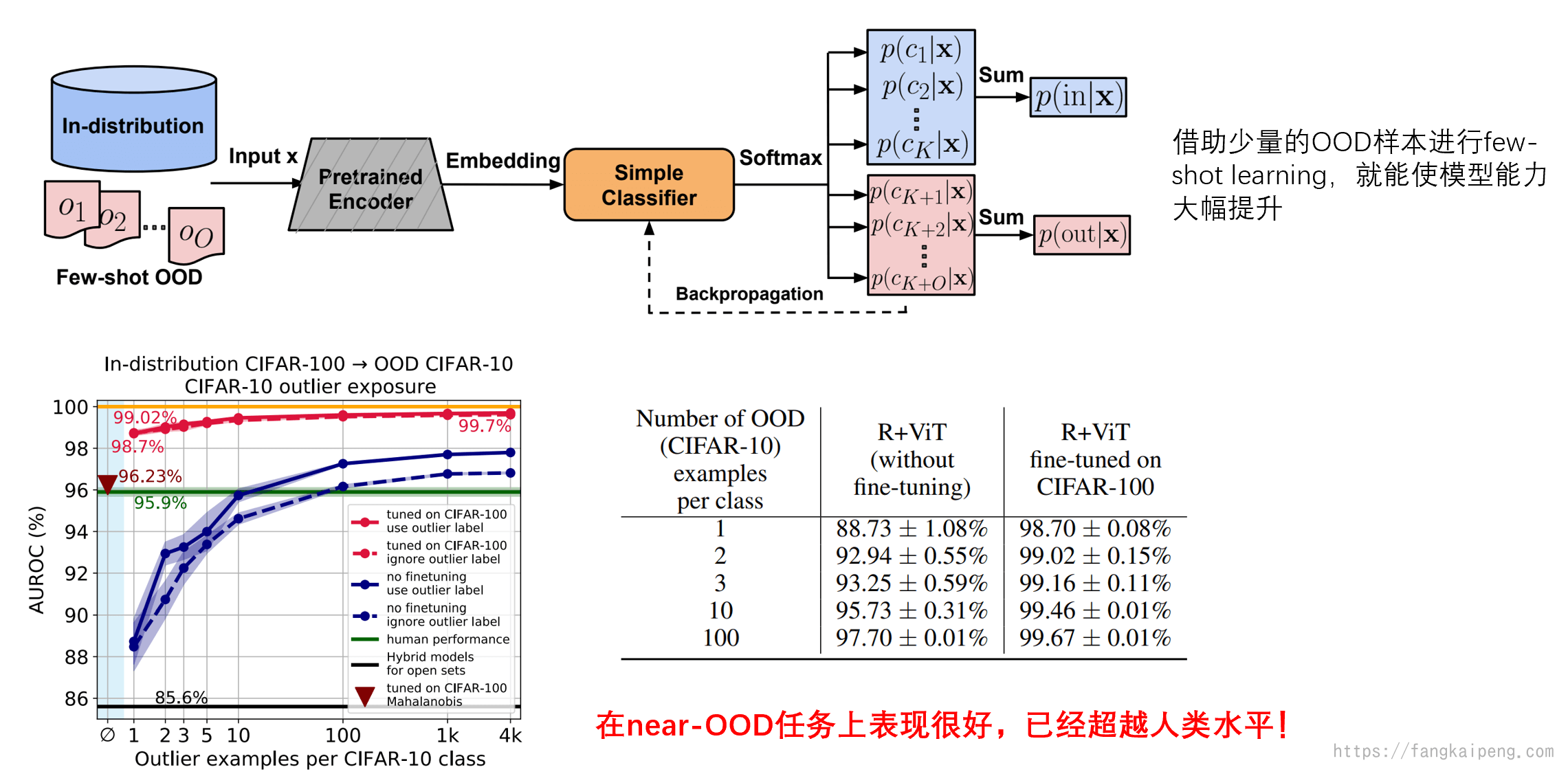
由于预训练大模型的研究比较火热,并且效果非常好,所以单独拿出来说。首先,前面已经介绍过了,使用预训练大模型的好处在于,大模型中有非常丰富的特征,并且在ID分类上能达到很好的效果,而OOD检测性能和ID分类性能又成正相关,所以使用预训练大模型finetune能达到很好的效果。下图展示的是使用少量的OOD数据进行fine-tuning大模型的效果。可以看到,预训练大模型借助少量的OOD样本,就能获得巨大的性能提升,并且超越了人类的水平。
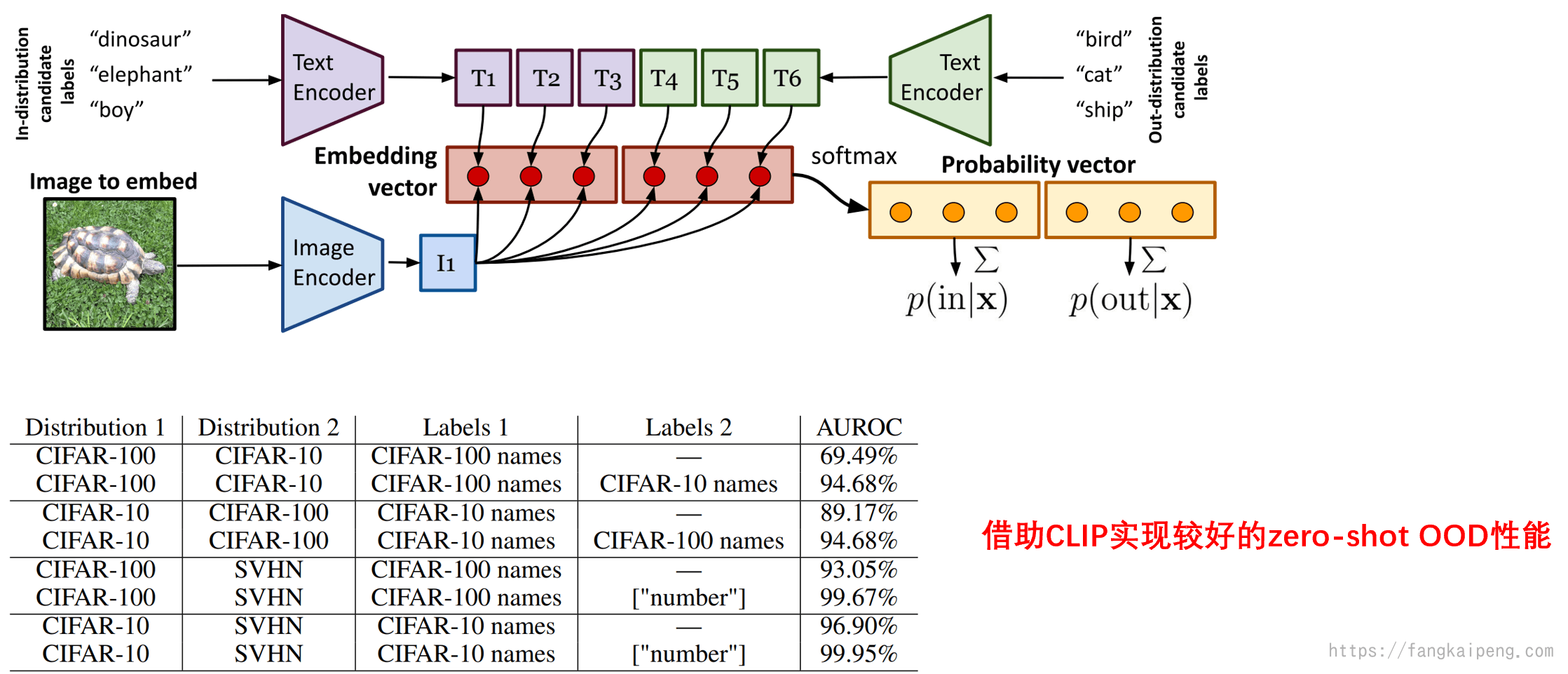
下图展示的是使用CLIP进行OOD检测的方法,借助CLIP中丰富的特征和语义信息,训练中可以不借助OOD样本,只需要输入一些OOD的label,就能达到不错的效果,实现zero-shot的OOD。
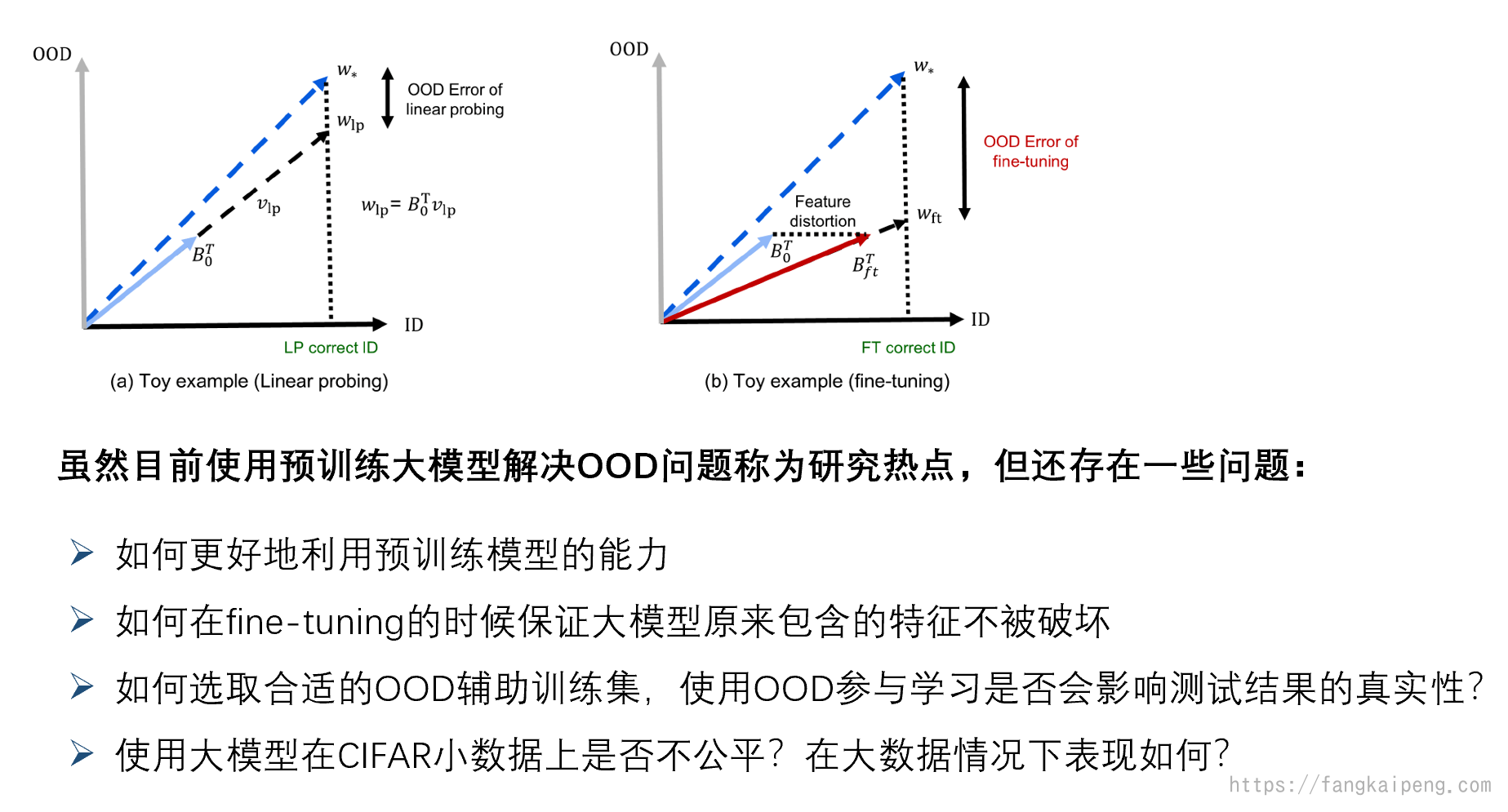
不过,预训练大模型目前也有一些问题,有研究发现,对预训练大模型进行整体的fine-tuning会导致性能损失严重(与只调优分类头比较)。其主要原因在于,fine-tuning的时候会破坏大模型原有的特征。
7. 结论


写的真不错
谢谢
写的很棒顶一下,想请问作者 倒数第二个图是哪篇呢~
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution
awesome
awesome
你好 请问Clip 的zero-shot OOD的 (倒数第三个图片)是哪个文章, 感谢
Exploring the Limits of Out-of-Distribution Detection
参考文献呢
你好,请问MDS是哪篇论文呀
good good