CS231n第二节:线性分类器
本系列文章基于CS231n课程,记录自己的学习过程,所用视频资料为 2017年版CS231n,阅读材料为CS231n官网2022年春季课程相关材料
上一节介绍了图像分类问题——从固定的类别集合中选出一个标签分配给一张图片的任务,解释了图片分类问题的难点。同时,介绍了KNN分类器,它的原理是将待预测的图片与训练集中的所有图片比较,将最相近的图片的表情作为带预测图片的标签。KNN有很多的缺点,比如需要存储整个训练集,空间利用率低,预测所需的时间长。
本文主要介绍一种更加强大的处理图片分类问题的方法,这一方法可以延伸至神经网络以及CNN。这种方法主要由两部分组成:评价函数和损失函数,前者用于将原始的数据映射成某一分类的得分情况,后者用于量化预测结果和真实结果的差距。接着,我们就可以将图片分类问题转化成一个最优化问题, 即通过改变评价函数的参数最小化损失函数。
1. 从图像到标签值的映射
首先我们定义一个评价函数,用于将图片的像素映射为每一类别的得分,具体来说,假设我们有一个训练集,其中的每个样本
我们以最简单的线性分类器为例,即我们定义评估函数为 :
上式表示,我们将图片
需要关注的是:
- 使用矩阵乘法
的效率很高,因为矩阵乘法通常可以使用并行化处理。 - 我们不会改变输入数据
,我们通过设置参数 来改变对于某个数据在每个类别下的得分情况。使用我们的目标是通过某种途径设置参数 使得整个训练集中的样本的得分情况与各自真实的标签匹配。 - 采用这种方法的好处是,一旦我们通过训练集得到合适的参数
后,我们就可以丢弃训练集,只要存储所有的参数即可。当遇到一个新的样本,我们可以直接使用这些参数通过评估函数预测它属于哪个类别。这是区别于KNN空间利用率低的一大优势。 - 不同于KNN在预测时需要将待测样本与整个训练集比较,使用这种方法只需要将待测样本与参数矩阵做乘法和加分即可,在时间效率上也是很大的提升
2. 对线性分类器的解释
2.1 直观理解
如下图就是线性分类器的工作过程,对于一张图片,假设是个黑白的

从上述例子我们可以看出,线性分类器首先将一个RGB通道的图片的每个位置的像素进行加权后求和,将求和后的值作为该分类器所属类别的分数(分数最高的分类器所属的类别作为这张图片的预测类别)。那么线性分类器的原理是什么呢?评估函数通过调整参数,使得其有能力倾向于或者不倾向于图片某个位置的某个颜色。举例来说,对于一张船的图片,图片的周围很可能有很多的蓝色(表示在大海中),那么对于船的分类器就可能对图片四周位置的蓝色通道的权重设置成一个正数,而对相同位置的红色通道和绿色通道的权重设置成一个负数,这样对于某张图,如果满足图片四周位置的蓝色通道的数值大,而其他通道数值小(在图片中表现为四周为蓝色),那么它的评估得分也就会高。
2.2 几何理解
运用线性分类器后,我们将每张图片都转变成了一个

如上图所示,有三根直线分别代表汽车分类器、鹿分类器、飞机分类器,以红色的汽车分类器为例,如果某个点刚好在线上,则汽车种类的得分为0,红色线上的箭头表示在这个方向上汽车得分为正,在反方向则为负。由此我们可以得出,评估函数中的
2.3 模板匹配角度
对于参数
如下图是使用CIFAR-10作为训练集训练得到的分类器,从

观察图片,可以发现一些有意思的事情,马的分类器可视化出来的是一个双头马,这说明在CIFAR-10的训练集中有头朝左和头朝右的马,于是分类器将这种特征合并在模板中。再比如车的分类器,可以隐约看出一个车的形状,并且车的颜色以红色居多,这说明在CIFAR-10的训练集中红色的汽车居多。这也说明了一个问题,当分类器遇到一个其他颜色的车时,它的识别效果可能就会变差,也说明这个分类器的泛化能力不是很好。这是由数据集和模型的局限性导致的,在之后介绍的神经网络中,通过隐藏层,就能比较好的解决这个问题(当然也需要一个更好的数据集)。
2.4 偏置项合并
前面介绍到我们的评估函数为:
参数为
参数合并的示意图如下:
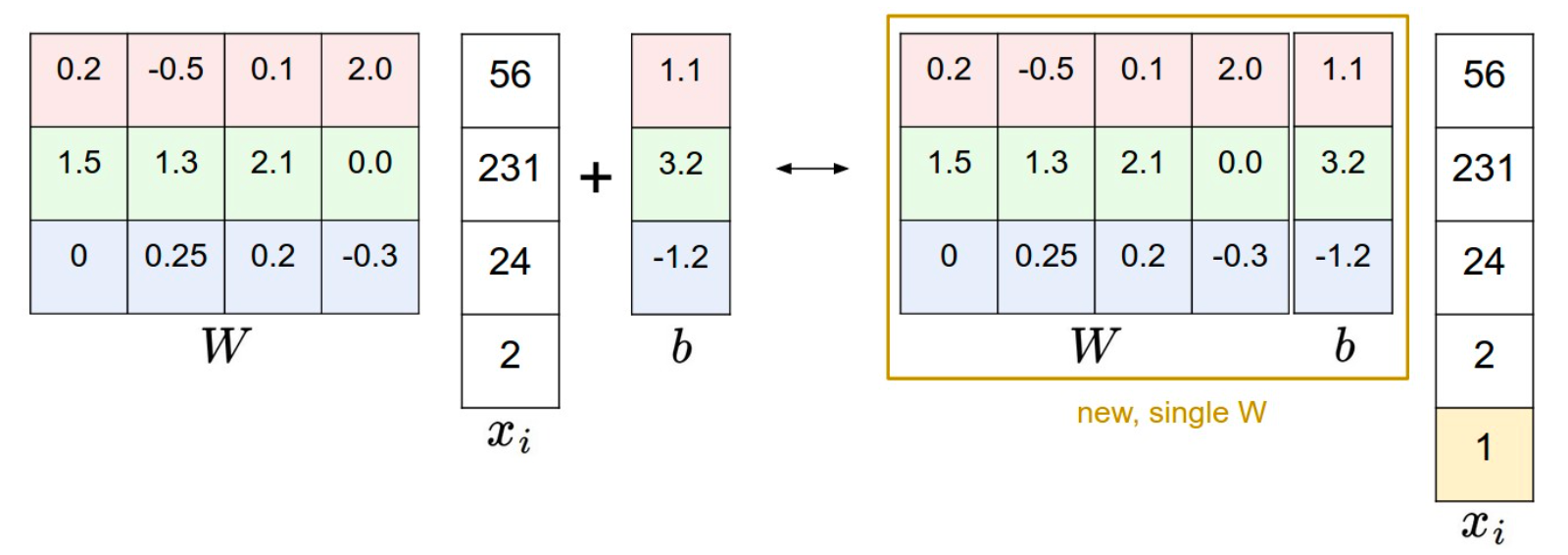
2.5 数据预处理 normalization
在前面的过程中,我们都是直接使用原始的图片数据来训练。在机器学习中,对输入的特征进行归一化是一种很普遍的做法。具体来说,我们图片的每个像素的数据范围是
3. 损失函数
在上一节,我们定义了一个评估函数,通过设置评估函数的参数
3.1 多分类SVM的损失函数
损失函数的定义方式有很多,先来介绍一种常用的损失函数——多分类SVM的损失函数。多分类SVM的损失函数希望每个图片对应的真实样本的预测得分比其他类别的得分高出一个间隔。我们定义第
其中
对于第一个类别的预测得分13,不会在损失函数中计算,因为这是真实种类对应的预测得分。接着是第二个类别的预测得分-7,由于该种类的预测得分远小于真实种类的预测得分(13),所以通过与 0 取max的方式

此外还有一点需要说明的,在多分类SVM的损失函数中使用的
3.2 正则化 Regularization
不过对于上述的损失函数,还有一个漏洞。设想一下,我们有一个参数为
换句话说,我们希望有一种方式可以采取一种合适的偏好来选择一种权重集合来消除这种歧义。我们只需在损失函数后增加一个正则项 $R(W)$ 即可实现,最常用的正则项为平方
从式子中可以看出,正则化只是对权重进行的,与训练数据无关,加上正则项后,多分类SVM的损失函数变为:
前半部分表示由于预测样本导致的损失值,后半部分表示权重的损失值,其中
最后需要说明的是,不同于权重,偏置项不会影响输入数据对评估函数输出的影响,所以一般不会对偏置项进行正则化,不过其实在实际应用中,是否对偏置项正则化影响不大。另外,引入正则项后,损失函数永远不可能为0,除非将权值全设为0,但这是很不理智的一件事。
3.3 损失函数的代码实现
3.4 $\Delta$ 的设置
从上面的损失函数可以知道,除了权重以外,还有两个超参数 $\Delta$ 和
4. Softmax 分类器
除了多分类SVM分类器以外,还有一种常见的 Softmax 分类器,Softmax分类器其实就是二元逻辑回归分类器在多分类问题上的延伸。不同于 SVM 将
上式中的
4.1 信息学层面解释
在信息论中有一个交叉熵的概念,它主要用于度量两个概率分布间的差异性信息。在介绍交叉熵之前先介绍一些基本概念。
4.1.1信息量:
信息量的概念在平时生活中也经常遇到,下面举两个例子,比如你获得了两个信息:
- 明天太阳从东边升起
- 明天的双色球彩票号码为1234567
从直观来讲, 第一个信息的信息量比第二个小,因为第一个信息是必然发生的,而第二个信息的发生概率很小。也就是说信息量的大小取决于这个信息消除了多少不确定性,而这个信息所描述的事件发生的概率越小,则这件事情发生了所带来的信息量也就越大,也就是说信息量的大小和事件发生的概率成反比。对于事件 $x$ 信息量的公式定义为:
4.1.2 熵(Entropy):
对于给定的离散随机变量
信息量度量的是一个具体事件发生所带来的信息,而熵是指该某一事件可能的结果所蕴含的不确定性的平均水平,以抛硬币为例,如果抛一枚质量均匀的硬币,那么朝上还是朝下的概率是相同的,那么此时抛一枚硬币的不确定性是最大的。但如果硬币质量不均匀,正面的概率比反面大很多,那么抛一枚硬币这个事件的不确定性就比均匀硬币要小了。也就是说,熵的概念是衡量某个事件的平均不确定性,而信息量描述的是接受该信息后消除的不确定性的量值。熵的本质其实就是对于一个事件信息量的期望。
4.1.3 相对熵(KL散度)与交叉熵:
KL散度:
这是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵。在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息量。假设对于同一个随机变量 $x$ 有两个单独的概率分布
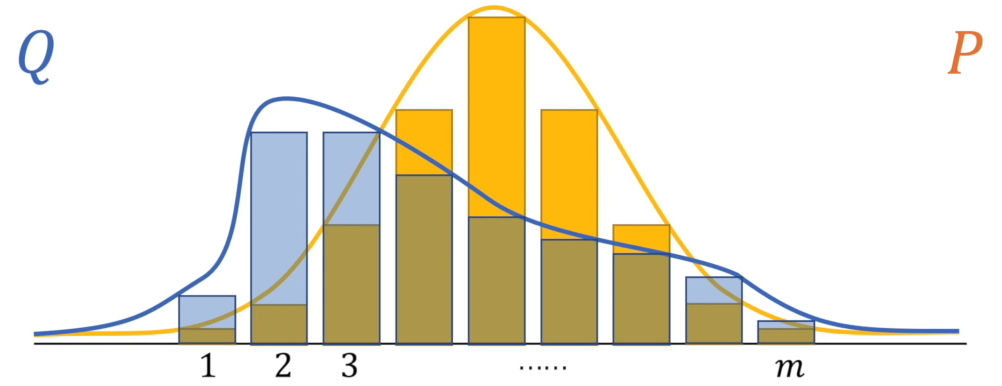
也就是说,如果使用
交叉熵:
在相对熵公式中,前面一半是
4.1.4 在分类问题中的应用:
在分类问题中,经常将交叉熵函数与 softmax 函数相关联,这是因为 softmax 函数对一组数据的每个数据进行计算后,可以将这组数据中的每一个都映射到 (0,1) 区间上,并且其和为 1,符合概率的定义,而交叉熵恰恰是对概率分布进行计算,因此通常将 softmax 函数的输出结果作为交叉熵函数的输入,将二者构造为复合函数。在模型训练过程中,通常将每个输入的真实标签值设置为分布 p,预测值设置为分布 q,利用交叉熵函数计算出的值作为损失值用于更新权重。在这里,设 softmax 函数对输入数据 $x$ 预测为第
举个例子,假设有三个类别,输入的数据 $x$ 属于第一类,那么期望的输出为
可以看到,
在回头来看Softmax分类器,Softmax首先通过
这里的
这里的
4.2 概率层面解释
前面说到 Softmax 分类器首先将评估得分转变为一个概率分布,也就是说我们可以把整个模型当做一个以
由于
4.3 代码实现
在代码实现的过程中需要注意的是,由于涉及指数运算,所以分子和分母的数据可能会很大,对于两个很大的数字做除法可能会导致精度问题。通常,在实现的过程中,我们使用下面的技巧:
这里的
f = np.array([123, 456, 789]) # example with 3 classes and each having large scores
p = np.exp(f) / np.sum(np.exp(f)) # Bad: Numeric problem, potential blowup
# instead: first shift the values of f so that the highest number is 0:
f -= np.max(f) # f becomes [-666, -333, 0]
p = np.exp(f) / np.sum(np.exp(f)) # safe to do, gives the correct answer
5. SVM和Softmax对比
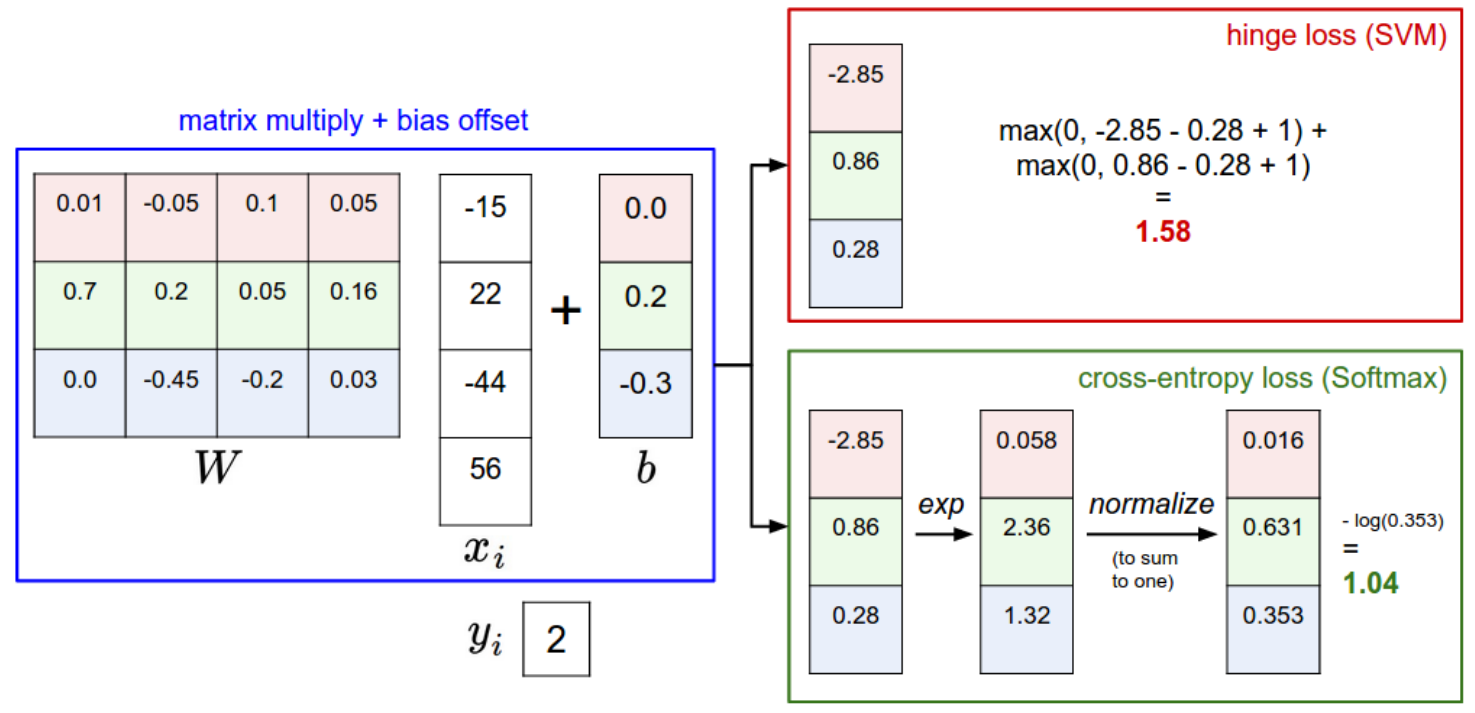
上图展示了SVM和Softmax的区别,对于一个输入的数据,两个分类器首先都是计算相同的得分
SVM和Softmax的性能差距很小,不过还是有一些差异的。相比于Softmax,SVM更佳,这可以看做是SVM的缺陷也可以看做是SVM的特点,比如说某个样本的预测得分为

最后一段SVM更佳有一个错别字哟
已修改~
|´・ω・)ノ
3.1 多分类SVM的损失函数:
如果使用很小的随机值初始化W,训练初期所有的分数接近于0并且差不多相等,预计多分类SVM的损失函数。
答案是:(C – 1) * 间隔,C是分类数。
这是一个有用的调试策略,在刚开始训练时,我们应该想到预测的损失函数有多大,如果第一次迭代不符合预期,程序可能有bug。
https://www.cnblogs.com/zingp/p/10375691.html
深入理解L1、L2正则化
文中SVM损失函数部分:“最后需要说明的是,不同于权重,偏置项不会影响输入数据对评估函数输出的影响,所以一般不会对偏置项进行正则化,不过其实在实际应用中,是否对偏置项正则化影响不大。另外,引入正则项后,损失函数永远不可能为0,除非将权值全设为0,但这是很不理智的一件事。”
为什么权值全设为0后损失函数可能为0呢?对于前半部分也就是由于预测样本导致的损失值,就算权值全为0,那也仅仅是导致每个样本的得分为0,如果此时Δ不为0,那么前半部分应该不为0,那么损失函数也不应该为0,不知道我的想法是否有问题