CS231n第十节:目标检测与分割
本系列文章基于CS231n课程,记录自己的学习过程,所用视频资料为 2017年版CS231n,阅读材料为CS231n官网2022年春季课程相关材料
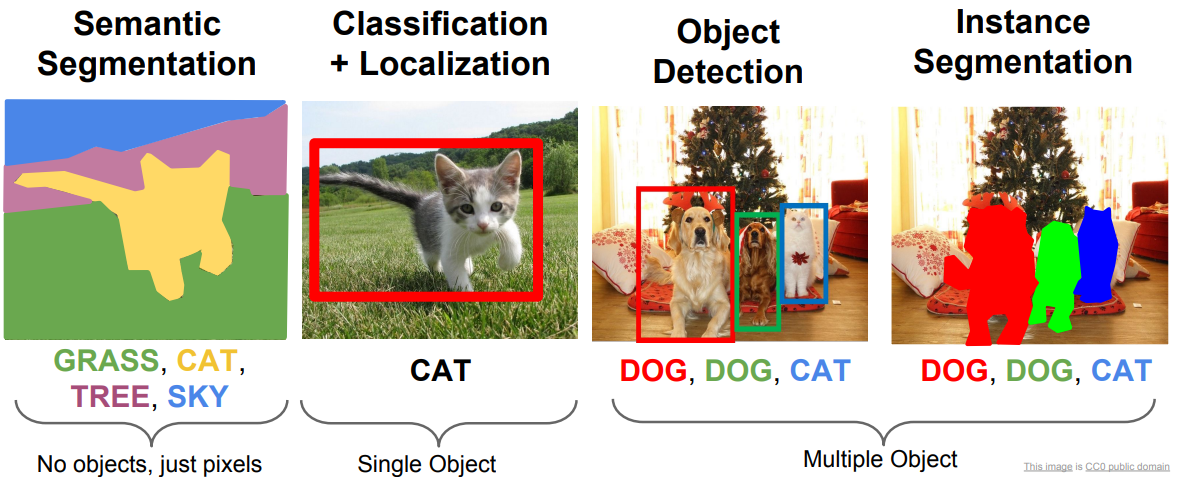
本文主要介绍了一些其他的计算机视觉的问题,包括语义分割,分类和定位,目标检测,实例分割。
1. 语义分割
1.1 定义
语义分割任务目标是输入一个图像,然后对每个像素都进行分类,如下图左,将一些像素分类为填空,一些分类为树等等。需要注意的是,语义分割单纯地对每个像素分类,因此不会区分同类目标,比如下图右边有两头牛,但是分类的结果中不会将两头牛区分开来,而是一视同仁,这也是语义分割的一个缺点。

1.2 实现方法1:滑动窗口
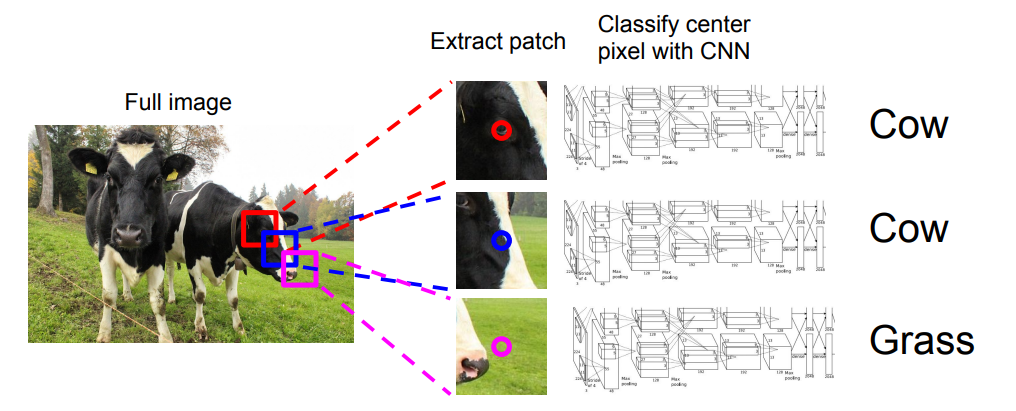
一个很直观的实现方法就是使用滑动窗口,将整张图片以滑动窗口的形式提取出很多微小的图片块,然后将这些图片块放入CNN中,让CNN来区分图片块的中间像素属于哪一类。但这不是最理想的方法,因为这种方法的计算复杂度非常高,因为要对每个像素准备一个单独的小图片块。 但实际上,稍微思考就能发现,其实对于相邻的像素,它们所属的图片块是有重叠的,这些重叠的计算是可以共享的。所以,实践中,没人使用滑动窗口的方法,但至少是第一个很直观能想到的方法。
1.3 实现方法2:全卷积
原始思路
另外一个实现语义分割的方法是直接训练一个全卷积神经网络,网络中包含多个卷积层,不进行下采样等缩小尺寸的操作,并对输入进行0填充使得空间尺寸保持不变,并最终得到一个
值得注意的是,语义分割的数据集是很难制作的,因为需要对每个像素点打标签。由此可以很自然地想到损失函数可以定义成一个交叉熵函数,对每个像素的预测结果和其标注的类别计算交叉熵损失,然后将所有像素的损失相加或求平均得到最终的损失函数。
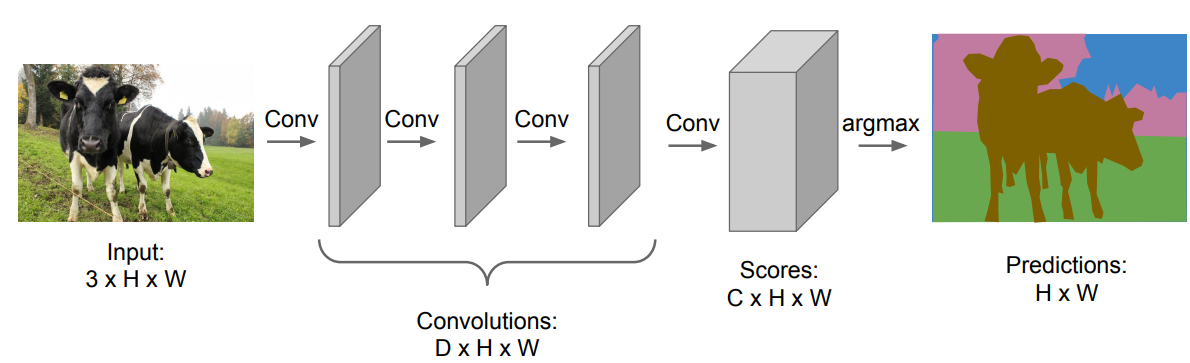
但这里有个问题,就是我们使用多个卷积层并且通过0填充的方式保持输入和输出的尺寸不变,这会导致计算量也会变得巨大,并且卷积层的参数也会占很大的内存。
改进的全卷积
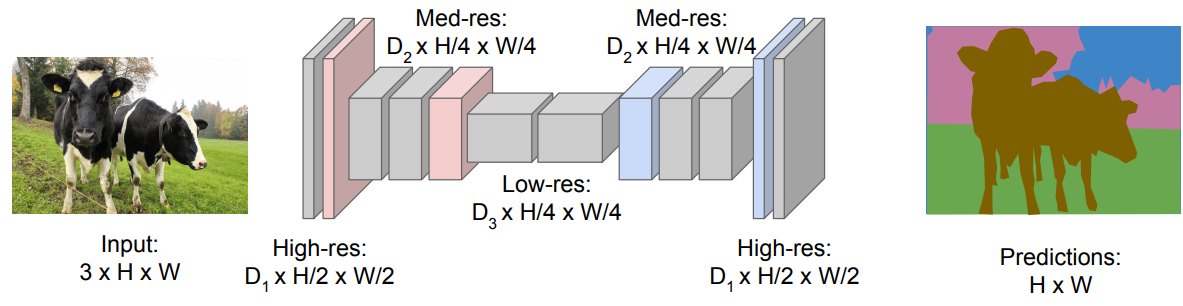
所以,更常见的网络结构如下,即先保留原始图像的“清晰度”进行几层卷积层的处理,然后进行下采样操作降低图片的“清晰度”,然后再进行卷积操作,最后将图片上采样恢复回原来的尺寸。
1.4 上采样操作
固定的上采样操作
在全卷积中,我们会使用到上采样和下采样操作。下采样很常见,比如池化操作或者改变卷积核的步长都可以实现下采样。那么,如何进行上采样呢?一种常见的上采样操作就是去池化(Unpooling) ,比如说下图中的 最相邻去池化 和 Bed of Nails 池化。最相邻去池化就是将周围用相同的数字填充,而 Bed of Nails 则是直接用0填充。
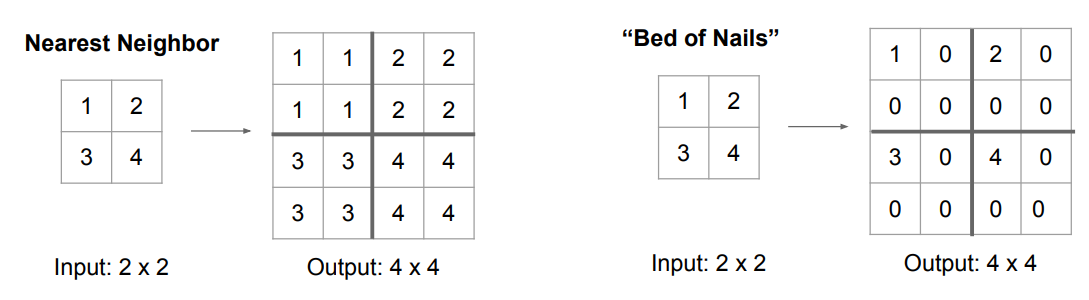
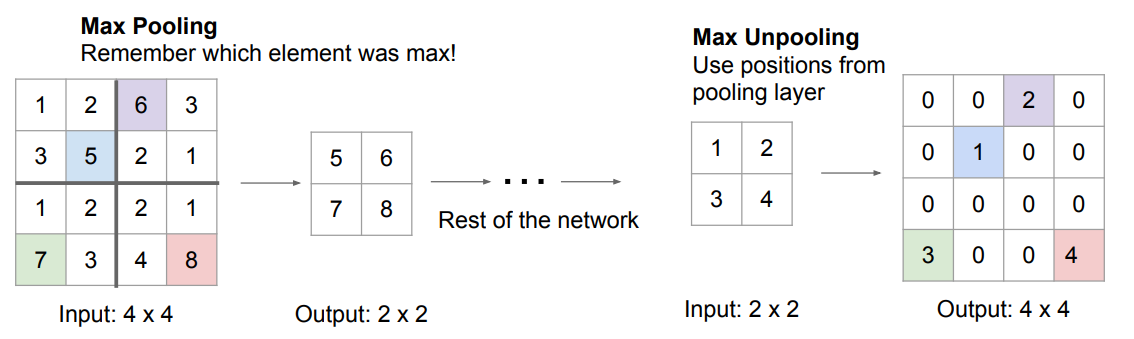
由于网络讲究对称性,所以比较常用的是最大去池化(对应最大池化操作),如下图所示,网络先使用最大池化操作,然后再使用最大去池化操作恢复输出的尺寸,对于最大去池化,在最大池化操作时会记住每个最大的元素的位置,然后在最大去池化时将每个元素填会最大元素所在的位置,并将其它位置填充为0。这样做的好处是,经过最大去池化操作后,能够一定程度上恢复一些每个像素在空间上的空间关系和信息,有利于不同物体边缘上的像素的分类。
可学习的上采样:卷积转置
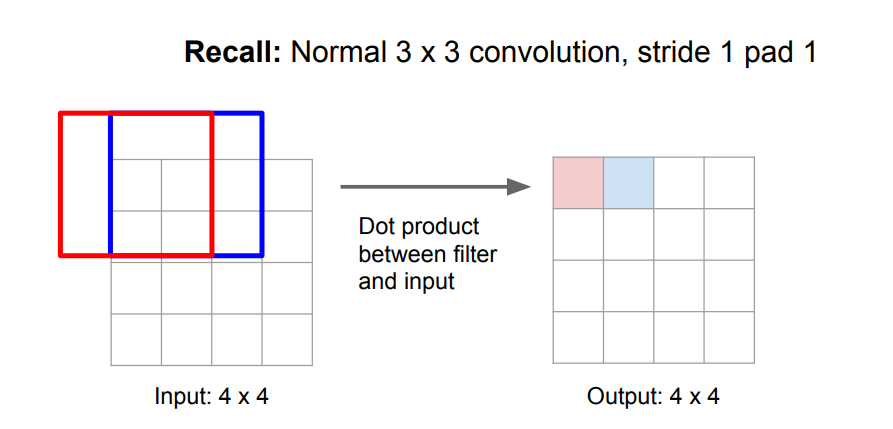
类比改变卷积核步长来实现的下采样,这种使用卷积核进行下采样的方式由于带着权重,所以是一种可自学习的下采样,那么,是否也可以仿照这种思路,设计一种可学习的上采样呢?那就是卷积转置。首先,先来回忆一下卷积操作:
如下图是一个
如下图同样是一个
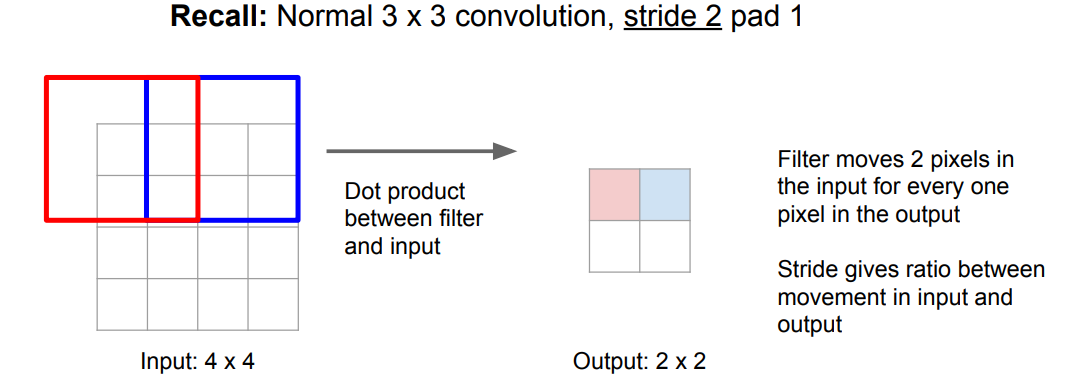
转置卷积则可以看成是一个逆过程, 卷积核的框会在输出矩阵上移动,同样步长表示框一次移动的像素个数。每一次移动,都会将输入矩阵的值与卷积核的框中所有值一对一相乘,然后将结果放入框中对应的位置。如果两次移动的卷积核的框有重叠,那么在重叠部分前后两次相乘的结果会进行相加。注意,步长控制的是输出矩阵上卷积核的框移动的距离,而在输入上,每次都只移动一个元素。也就是说,步长是控制输出尺寸和输入尺寸的比例,这与卷积下采样相反。即,卷积下采样中,步长越大,那么相同输入尺寸的情况下,输出尺寸就会越小;而卷积置换操作中,如果步长越大,相同输入尺寸下,输出的尺寸会越大。
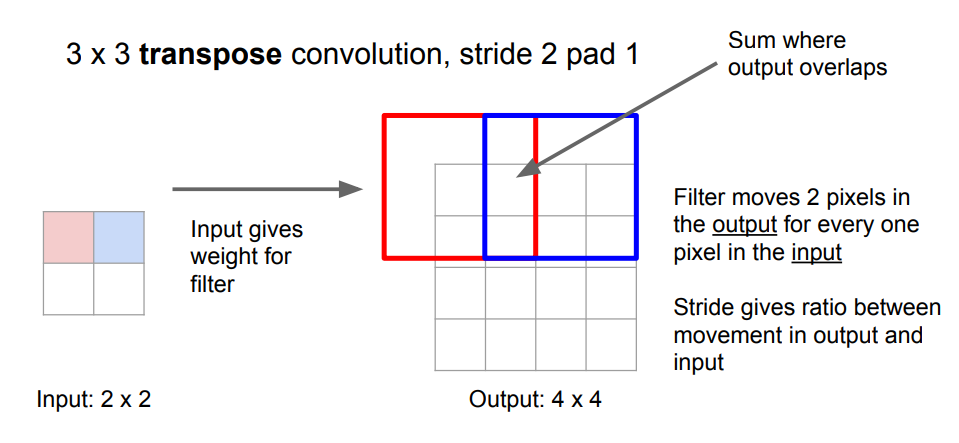
此外,置换卷积(Transpose Convolution),在很多地方有很多别名:Deconvolution (不是个好名字) ,Upconvolution,Fractionally strided convolution,Backward strided convolution。
下面是一个更具体的,在一维中的示例,其中输入为一个
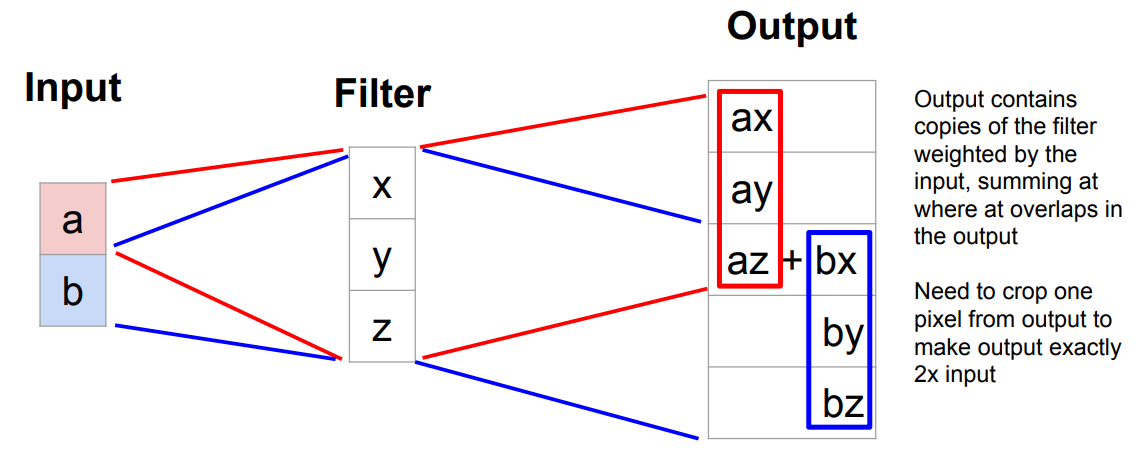
那么,为什么叫置换卷积呢,这里的Transpose具体指什么呢?我们知道 Transpose 在矩阵运算中代表转置,实际上置换矩阵从矩阵运算的角度看,就是将卷积核对应的矩阵置换得来的,具体分析如下:
假设我们有一个4×4的矩阵,需要在上面使用一个3×3的卷积核进行卷积操作,不做padding,步长为1。如下面所示,输出为2×2的矩阵。
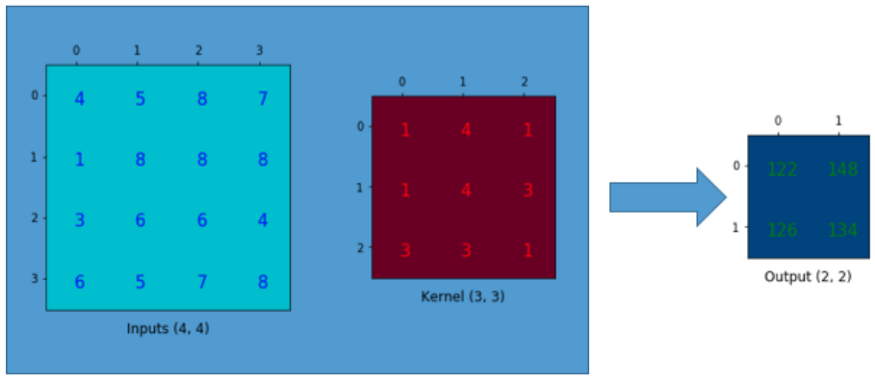
观察卷积核,我们可以将卷积运算换成矩阵乘法的形式,首先将卷积核表示成一个卷积矩阵:

同时,将输入矩阵拉直成一个向量:
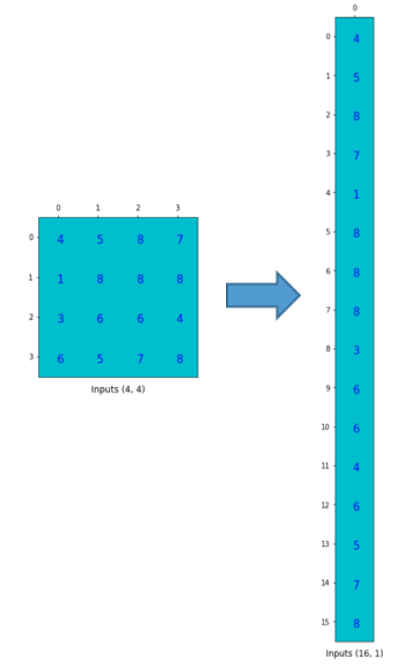
我们可以将4×16卷积矩阵与16×1输入矩阵(16维列向量)相乘。
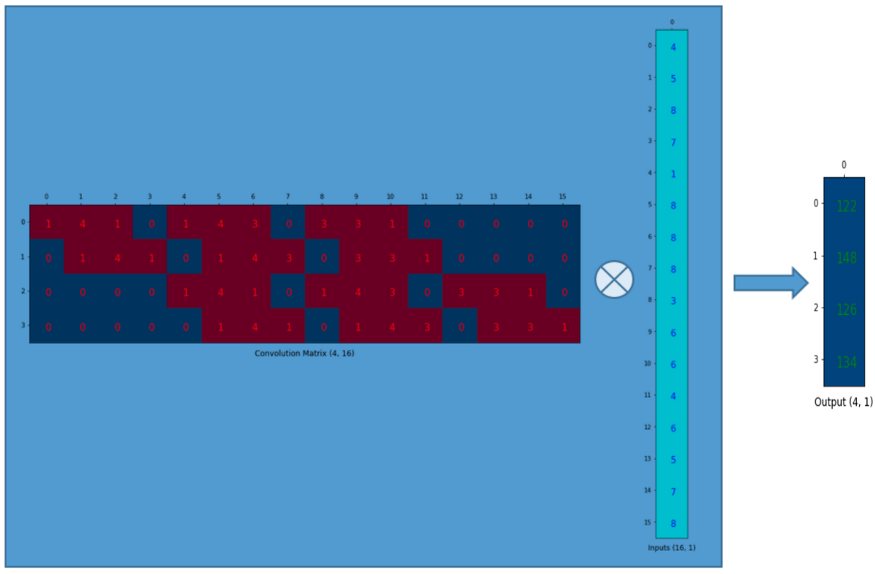
输出的4×1矩阵可以被reshape成2×2的矩阵,得到与之前相同的结果。

总之,卷积矩阵就是对卷积核权值重新排列的矩阵,卷积运算可以通过使用卷积矩阵表示。也就是说使用卷积矩阵,你可以从16 (4×4)到4 (2×2)因为卷积矩阵是4×16。那么,如果你有一个16×4的矩阵,你就可以从4 (2×2)到16 (4×4)了。于是,我们将卷积矩阵转置,顺利得到了一个16×4的矩阵,为了生成一个输出矩阵(16×1),我们需要一个列向量(4×1),然后就可以进行矩阵乘法来做卷积:
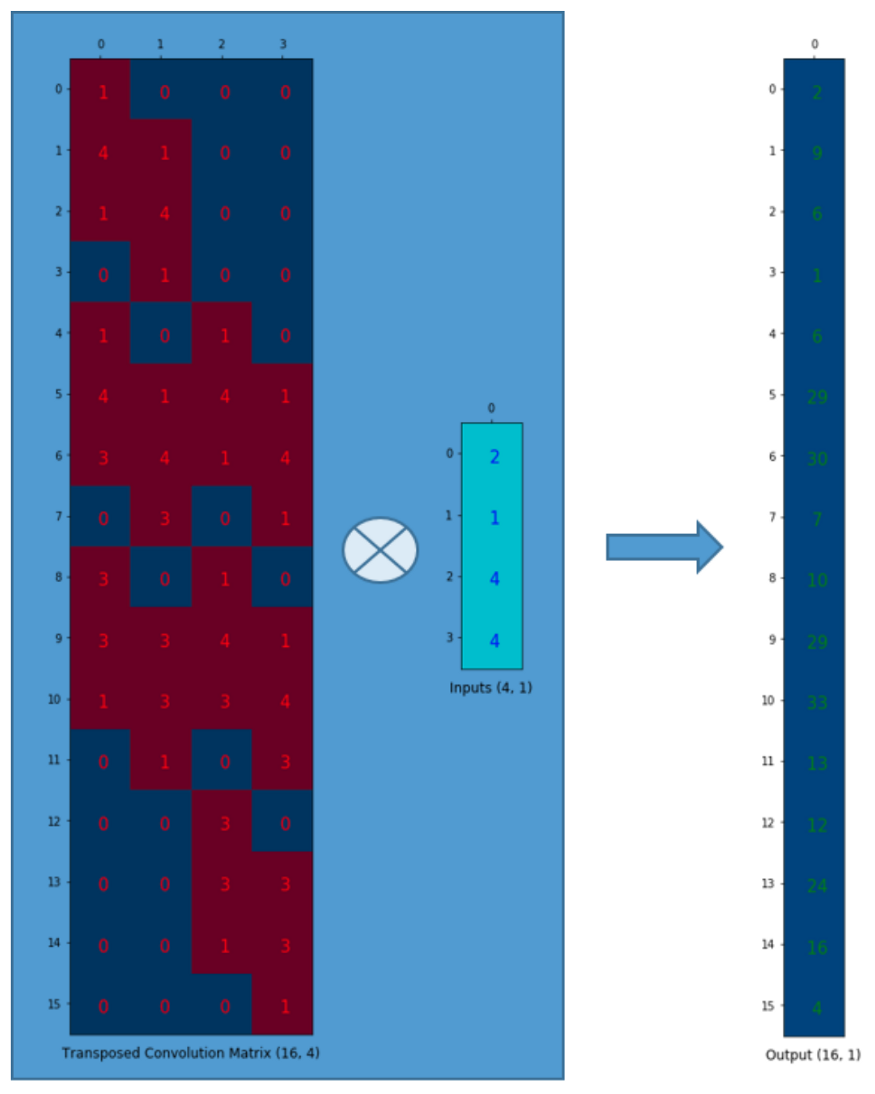
最后,将输出reshape成4×4,于是我们就将一个较小的矩阵(2×2)上采样到一个较大的矩阵(4×4)了。

需要注意的是,上采样时,卷积矩阵中的实际权值不一定来自某个下采样的卷积矩阵,而是可以自由学习的。重要的是权重的排布是由卷积矩阵的转置得来的。也就是说,尽管它被称为置换卷积(或者转置矩阵),但这并不意味着我们是取某个已有的卷积矩阵并使用转置后的版本。重点是,与标准卷积矩阵(一对多关联而不是多对一关联)相比,输入和输出之间的关联是以反向的方式处理的。
2. 分类和定位
2.1 实现方法
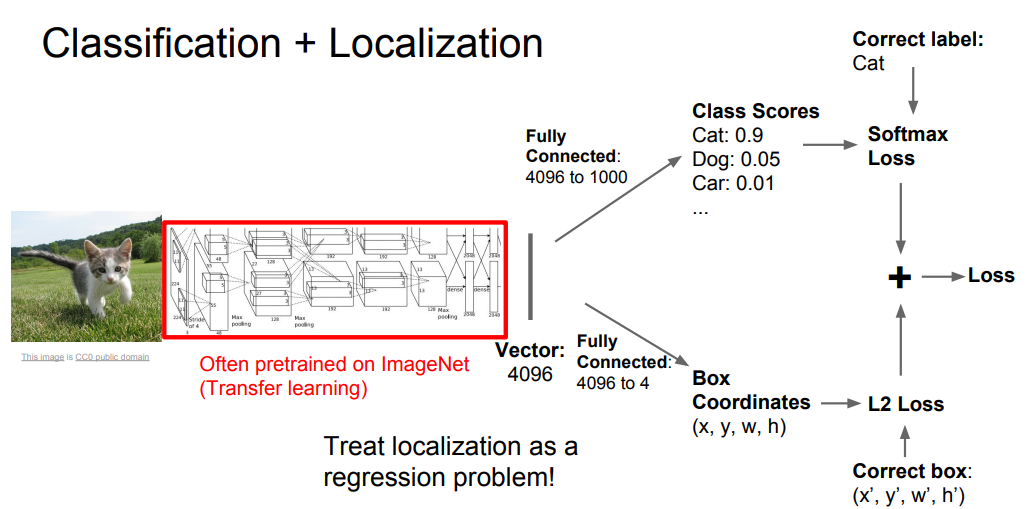
分类任务的定义应该很清楚了,而有时候除了想知道图片属于什么类别,也想知道这个类别的物体在图片中的位置,这就需要用到定位了。 和前面的语义分割不同,分类和定位的任务会提前知道输入的图片中存在需要定位和分类的物体,且最终输出的结果只会对其中一个物体进行分类和定位。处理这个问题所使用的网络结构如下:
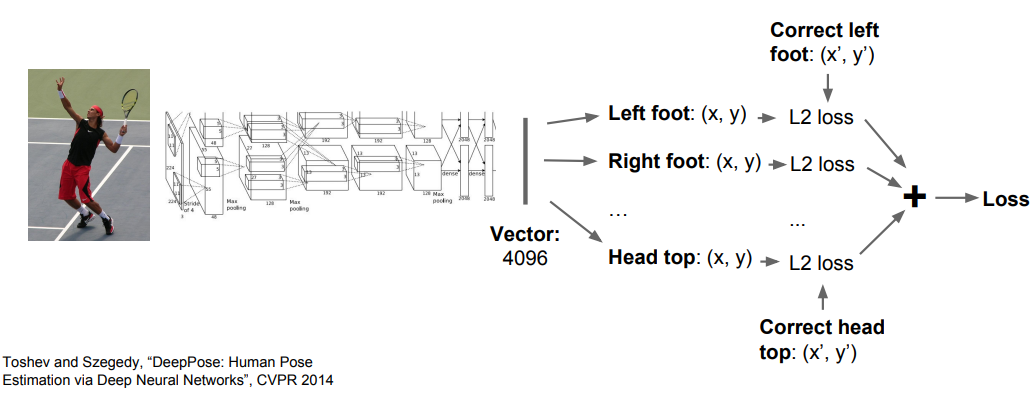
一般情况下都会先首先使用一个预训练的模型进行迁移学习,最终得到一个特征向量(如下图中 4096 维的输出),然后分别将这4096维的向量使用全连接映射成一个1000维的输出和一个4维的输出。其中,1000维的输出代表类别的预测得分,4维的输出代表定位框的左上角顶点的坐标以及长宽数值。对于分类任务的预测结果,将其与真实标签值对比,使用交叉熵损失函数评估。对于定位框,将其看成回归任务,使用L2损失函数评估其与真实定位框数据的差异。然后将两个损失函数的值相加作为整个网络的损失函数,接着就可以进行反向传播和参数更新来训练网络了。
这种定义损失函数的方式可以称为多重任务损失。现在我们有两个损失值,我们想同时最小化。而这两个损失值的重要程度如果有轻重之分时,就需要在这两个损失值上加上一些作为权重的超参数,然后做加权求和。这不好处理,因为这个加权超参数需要你来设定,但它和我们见到过的其他超参数有所不同,因为这种超参数会改变损失函数的值。具体来说,一般在调整超参数时,你会取不同的参数值,进行几轮训练,比较输出的损失值,看看它们发生了怎样的变化。但这里的超参数会直接影响损失值,所以这就要一些技巧了。实际应用中,为了解决问题,你需要根据不同情境采用不同的超参数取值。我一般会采取的策略是,用你关心的性能指标组成的矩阵来取代损失值。这样一来你实际上是在用最终性能矩阵上做交叉验证,而不是仅盯着损失值来选择参数。
2.2 其他应用
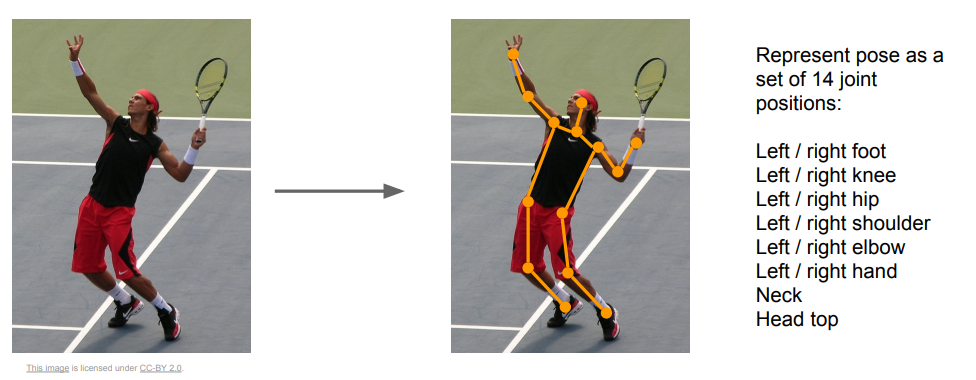
同样,上述的思路可以用于人体的姿势估计,实现方法也是类似的,使用多任务损失来实现。
3. 目标检测
3.1 定义
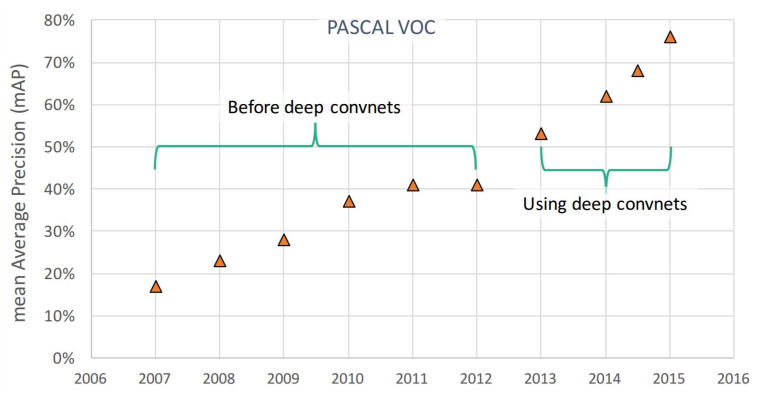
目标检测的目标是,对于一个输入的图片,会将其中所有的物体都进行框选定位,然后给出对框中物体所属类别的预测。如下图展示了在PASCAL VOC数据集上历年准确率的变化,可以看到在2012年左右,目标检测发展停滞,直到2013年出现深度学习后,准确率又开始了飞升。
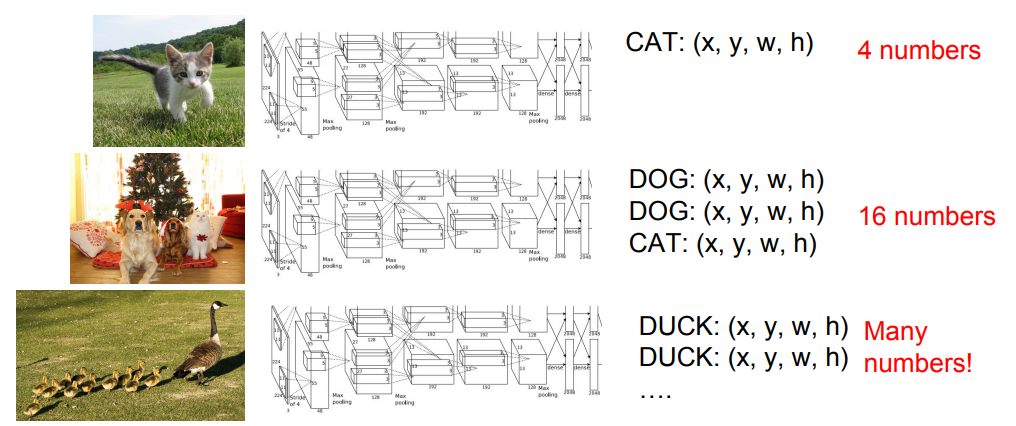
在前面的分类和回归问题中,我们提到了定位可以看成一个回归问题,那么目标检测中的定位是否也可以看成回归问题呢?答案是不行。原因在于,在分类和回归任务中规定了只会输出一个定位框,所以其输出的个数是定死的。而在目标检测中,会识别出图中的所有物体,也就是说,有多少个识别框取决于图片中有多少物体,输出值的个数是不定的,所以很难将其等同于回归任务。
3.2 滑动窗口
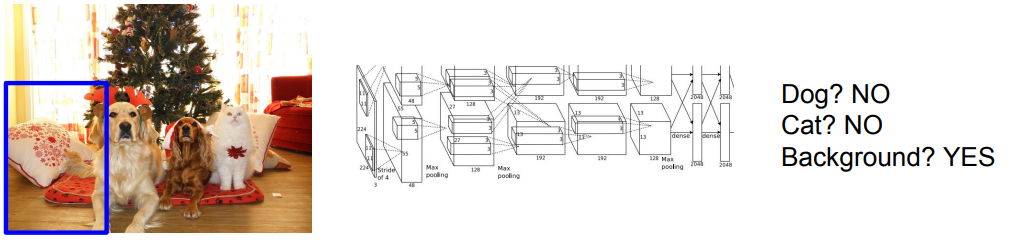
类似于语义分割中介绍的,我们也可以使用滑动窗口将输入的原始图片划分成几个小图,然后将这些小图片依次送入一个CNN中进行识别。如下图,窗口位于背景中,送入CNN中识别,CNN会给出预测结果。需要注意的是,CNN除了输出给定类别中的一个类别作为预测结果外,如果送入CNN的图片中没有包含一个物体,那么CNN会输出背景作为预测结果。
但是由于一张图片中的物体出现的大小、位置、比例都是不确定的,所以如果使用暴力的方式滑动窗口,那可能需要尝试成千上万次才能有个较好的结果,这是十分耗费计算资源的。
3.3 候选区域法
暴力的滑动窗口十分耗费计算资源,人们常用另外一种方式来获取原始图片上的一些小图片,称为候选区域法(Region Proposals),这不是一种深度学习中常见的方法,而是一种传统的计算机视觉方法。它采用了一种类似信号处理的方法来处理图像,找到物体可能存在的备选区域,再应用卷积神经网络对这些备选区域进行分类,这样做比穷尽所有可能的位置和范围要来的更容易一些,也更快一些。

3.4 R-CNN
R-CNN方法就使用了候选区域法。具体来说,首先使用候选区域法来获得大概2000个感兴趣的区域(Regions of Interest RoI),然后使用一个CNN来分别提取每个RoI中的特征,接着就类似分类和定位任务中的思路,使用一个分类器对RoI中的物体进行分类,R-CNN中使用的是SVM作为分类器。值得注意的是,这里同时还对每个RoI做了一个回归,即对RoI的边界进行了回归预测。其想法是,使用候选区域法得到的RoI一定程度上可以足够定位到每个物体了,但实际并不够完美,那么就可以基于这个RoI的定位框,使用回归来微调(比如某个RoI中定位了一个人,但是没有将这个人的头包含进去,分类时可能可以识别出这是一个人,但是定位框不够准确,使用回归可以将定位框向上挪动,使得定位框包含人的头)
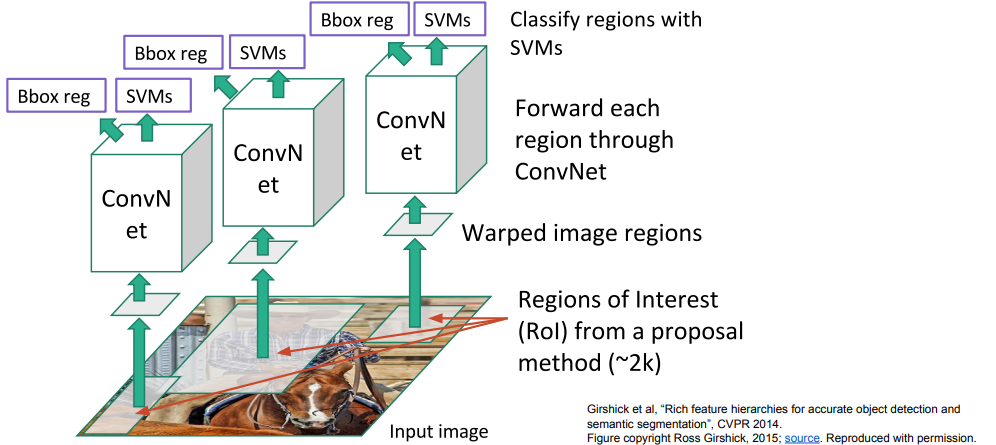
R-CNN的缺点:
- 由于对于一个输入的图片就要提取2000个RoI的特征并训练,所以它速度还是很慢(虽然比暴力穷举快)
- 同时,由于要将提取的特征存储,需要占用大量硬盘空间
- 在进行预测的时候由于需要很多次前向传播,所以速度也很慢,比如使用VGG16的R-CNN处理一张图片需要47s
- 使用的候选区域法毕竟只是一个固定的死算法,不够智能,无法自学习。
3.5 Fast R-CNN
对R-CNN的一些缺点进行优化改进,出现了Fast R-CNN算法,它和R-CNN的区别是先将原始图片送入CNN中提取特征,同时使用候选区域的方法获取RoI,然后将RoI映射至CNN提取得到的特征矩阵中,经过 RoI Pooling 处理后得到一致的尺寸,然后放入全连接层分别进行分类和回归。可以看到,先进行CNN提取特征的好处是,可以重复使用提取的特征,而不用对每个RoI重新提取一次特征,这大大加快了训练速度。同样,这样的做法也使得占用的空间变少,预测的速度变快。
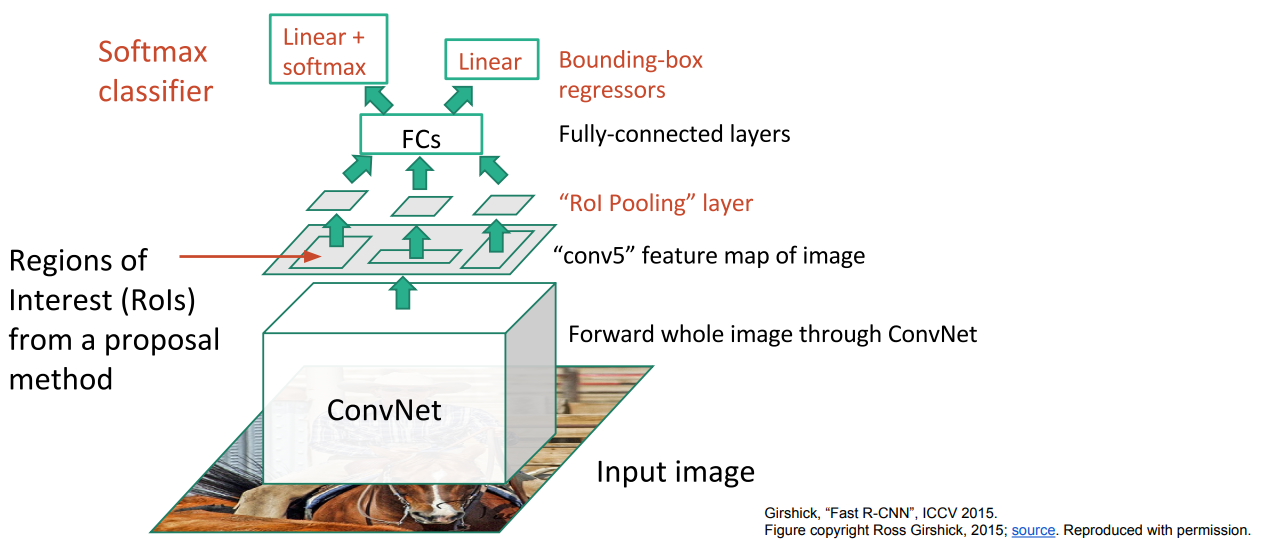
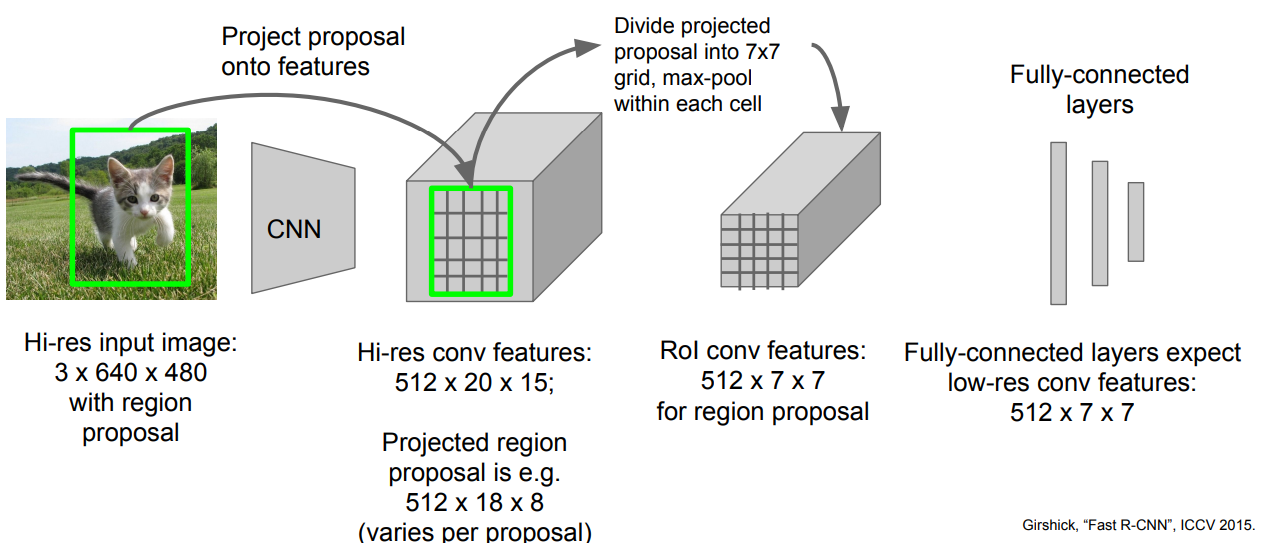
其中涉及到的 RoI Pooling 层工作方式如下:
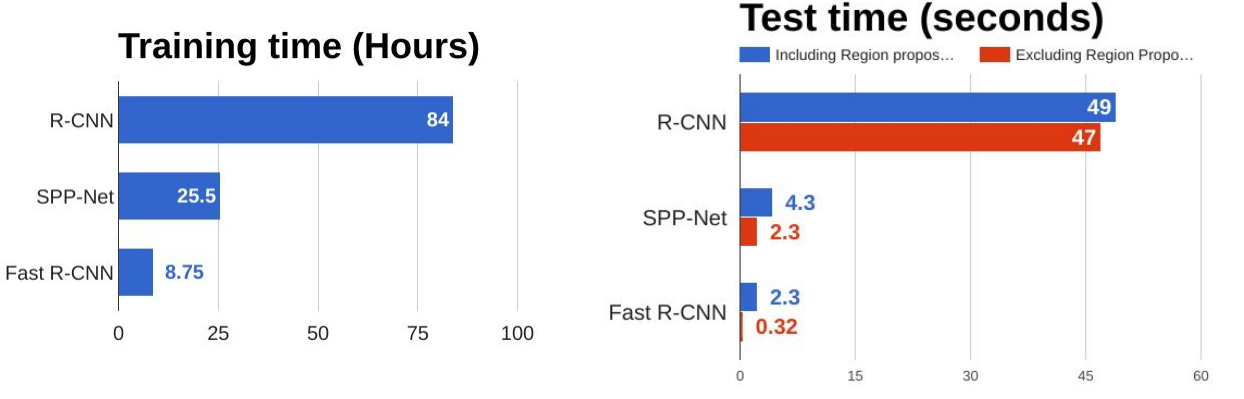
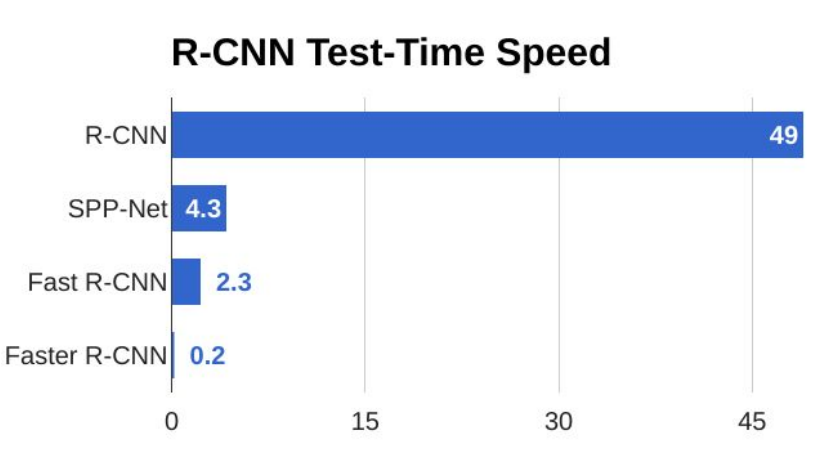
下图是R-CNN、SPP、Fast R-CNN 三种网络的一个对比,SPP也是使用了候选区域法的一种网络。可以看到,Fast R-CNN速度巨大提升,值得注意的是,在测试时如果包含候选区域法时,处理一张图片耗时2.3s,而如果不使用候选区域法,那么只需要0.32s,也就是说候选区域法占了大部分时间,也就是说网络的预测耗时瓶颈变成了候选区域法。
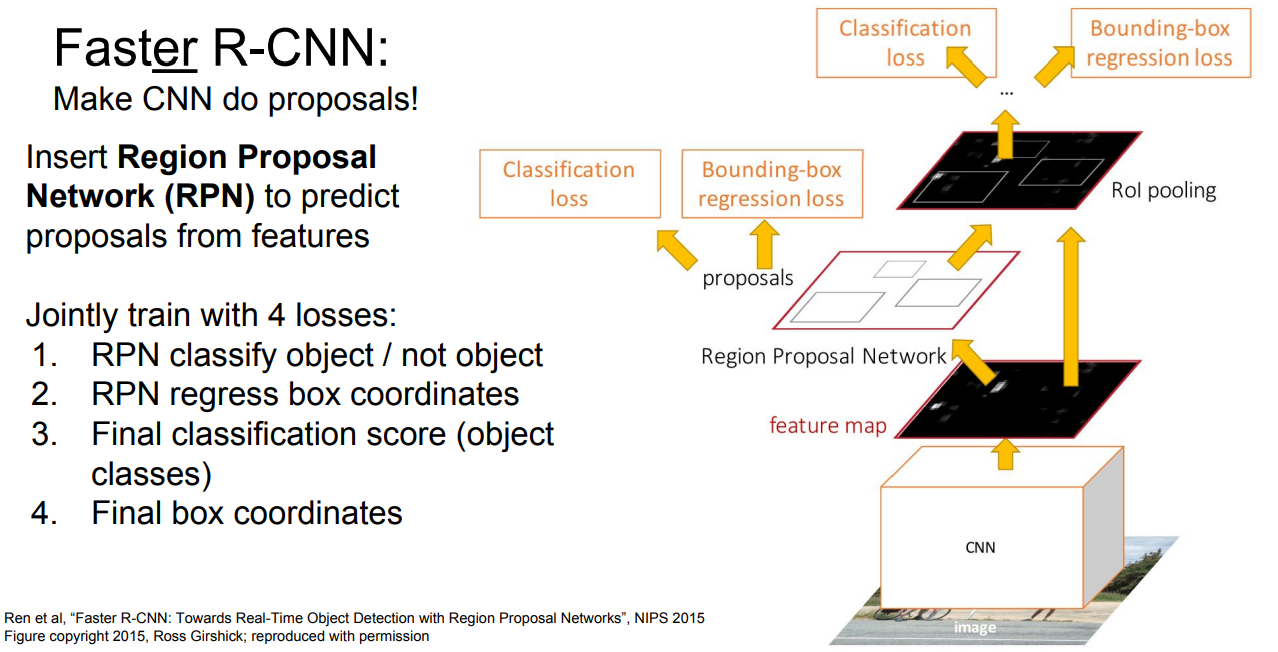
3.6 Faster R-CNN
为了解决网络预测时的瓶颈问题,又诞生了Faster R-CNN,其思路就是直接让网络自学习提取RoI:
首先,也是对原图使用CNN提取特征,然后使用得到的特征图,训练一个 候选特征网络 RPN ,同时将RPN提取出的RoI送入RoI Pooling 进行统一尺寸后进行和Fast-RNN相同的处理。也就是说,此时,整个网络有4个损失值,RPN中的分类损失值(一般可以当做一个二分类损失函数,即判断候选框中是一个物体还是一个背景),RPN的候选框坐标的回归损失,最终对候选框内物体分类得分的损失,以及最终经过微调后的候选框的损失。
下图是测试时间的对比:
3.7 YOLO/SSD
R-CNN、Fast R-CNN和Faster R-CNN中的“R”代表区域(Region),它们都是基于区域候选的方法来做目标检测的(称作Region-based methods for object detection)。除了这样的方法,还有一些直接一个过程做完所有事情的网络,比较典型的有YOLO和SSD。
YOLO和SSD不再对每个候选框单独处理,而是将目标检测视为回归问题,使用某种CNN,将所有的预测框同时给出。
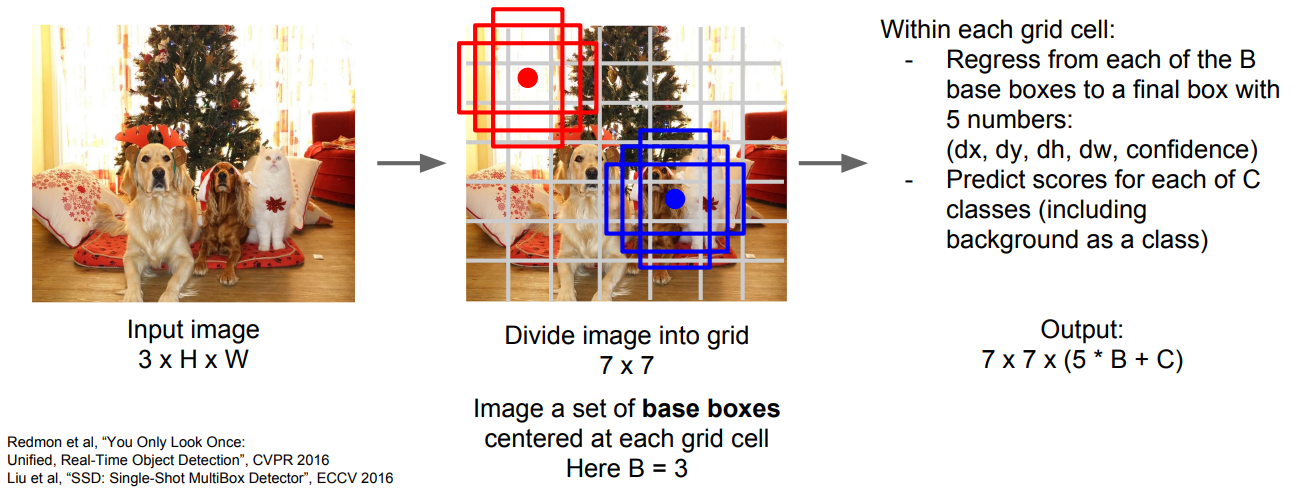
首先,将整张图片划分为几个粗略的网格(Grid)(比如7×7的网格),在每个网格中存在固定数目(设这个数字为B)的base bounding box。
我们要预测的东西有:
- 真实框与base bounding box的差异
- 给出每个base bounding box的置信度,即包含目标的可能性
- 这个bounding box属于各类别的分数
综上,所以最终网络会输出7x7x(5B+C)个数字。其中C为类别数,每个7×7的网格中有B个base bounding box,每个base bounding box需要回归5个数字(4个表示修正坐标的数字和1个表示置信度的数字)。
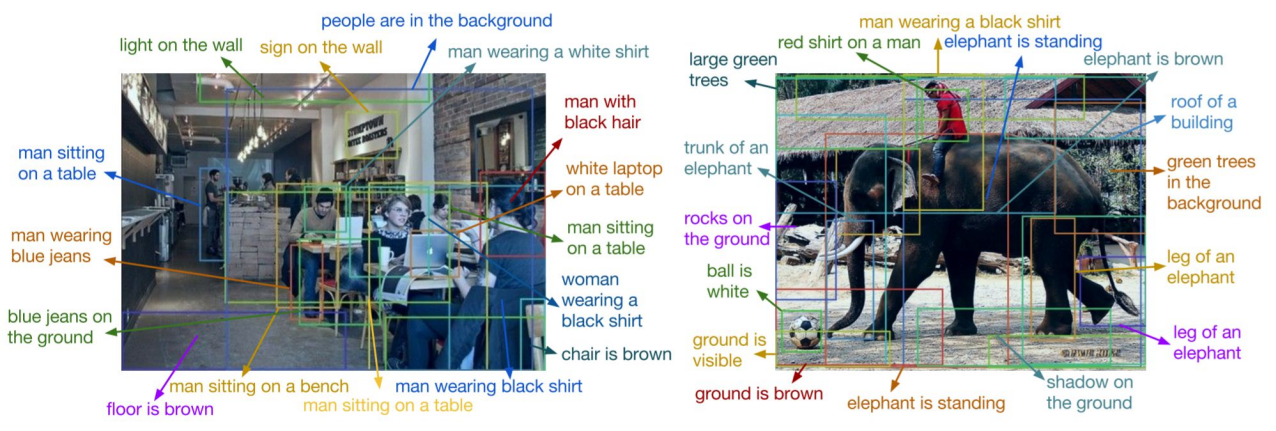
3.8 目标检测+字幕
将目标检测和标注字幕结合起来,就可以实现对图片的密集地标注标识(Dense Captioning)
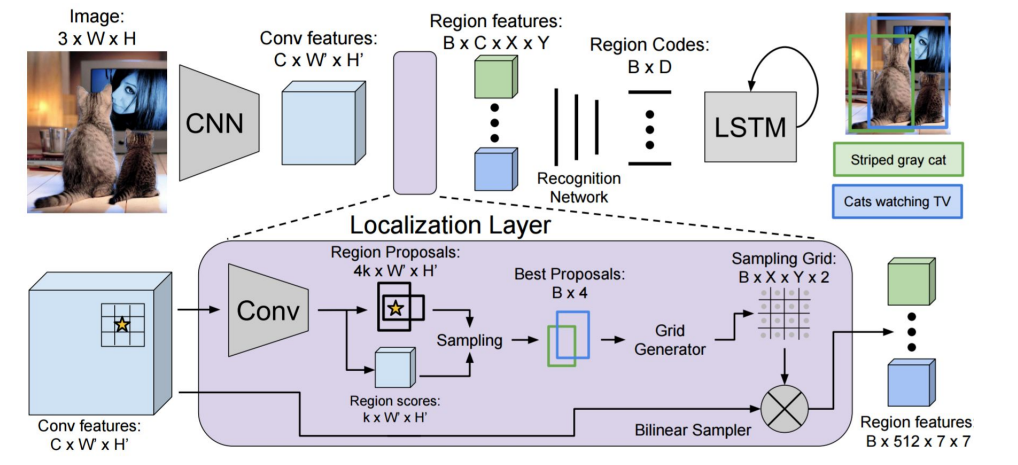
4. 实例分割
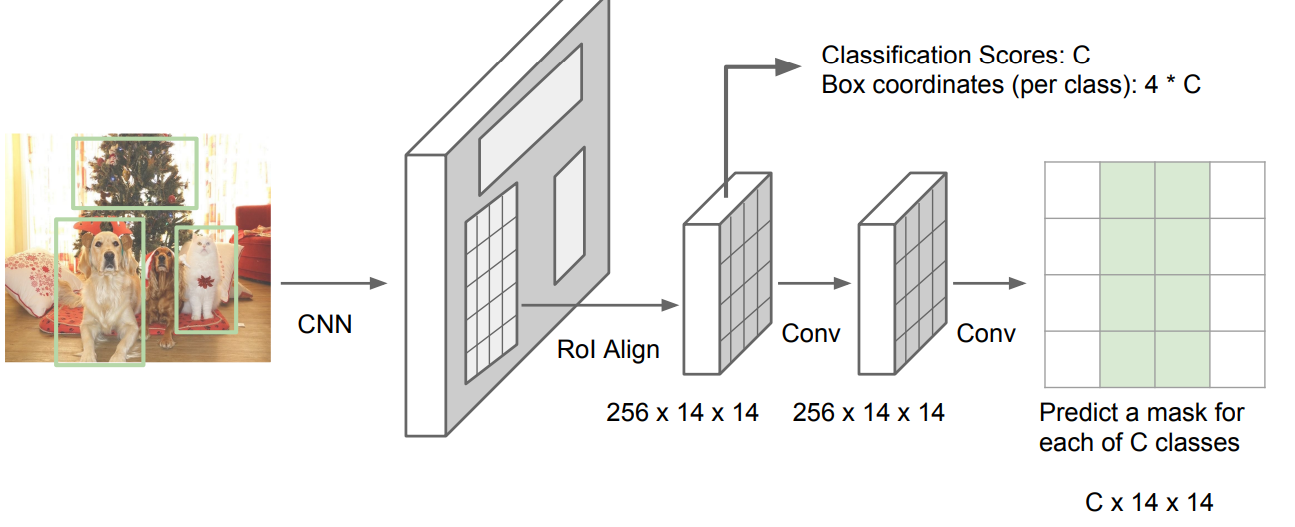
实例分割做的最好的网络是Mask R-CNN,它是本文提到的大部分方法的综合,首先也是使用一个CNN来提取特征,然后和Faster R-CNN类似,训练一个RPN网络来提取候选区域RoI,然后将每个RoI投影到提取的特征中,接着是两个分支,一个分支预测物体的类别和定位框的坐标,另外一个分支对每个RoI进行一次语义分割,即对每个像素都判断是否属于某个物体,网络设计如下图:
最终实现的效果如下:

同样,也可以在实例分割中加入姿势检测,只要多加一个与人体关节相关的损失函数即可:

