CS231n第十一节:生成模型
本系列文章基于CS231n课程,记录自己的学习过程,所用视频资料为 2017年版CS231n,阅读材料为CS231n官网2022年春季课程相关材料
本节将介绍一些无监督学习的内容,介绍一些生成模型,包括PixelRNN、PixelCNN、VAE、GAN
1. 无监督学习
和监督学习的最大区别就是数据中无标签,这带来的好处是可以轻松的获得大量的数据用于训练,比较常见的应用有:聚类、降维、特征学习、密度估计。

2. 生成模型
生成模型的定义就是给定一个训练数据,然后生成一些新的样本,保证和所给的训练集有一样的分布。即下图所示,假设训练集中满足分布

生成模型主要有以下这些应用场景:
- 生成逼真的艺术品图片,拥有超高的分辨率,着色等。
- 时间序列数据的生成模型可以用于仿真和规划(在强化学习中应用)。
- 训练生成模型还可以使隐式表征的推断成为有用的通用特征。
需要一提的是,可以将生成模型分成两大类,即隐式密度模型和显式密度模型,显式密度模型会显式地给出一个分布
目前常见(到2017年)的生成模型分类如下:
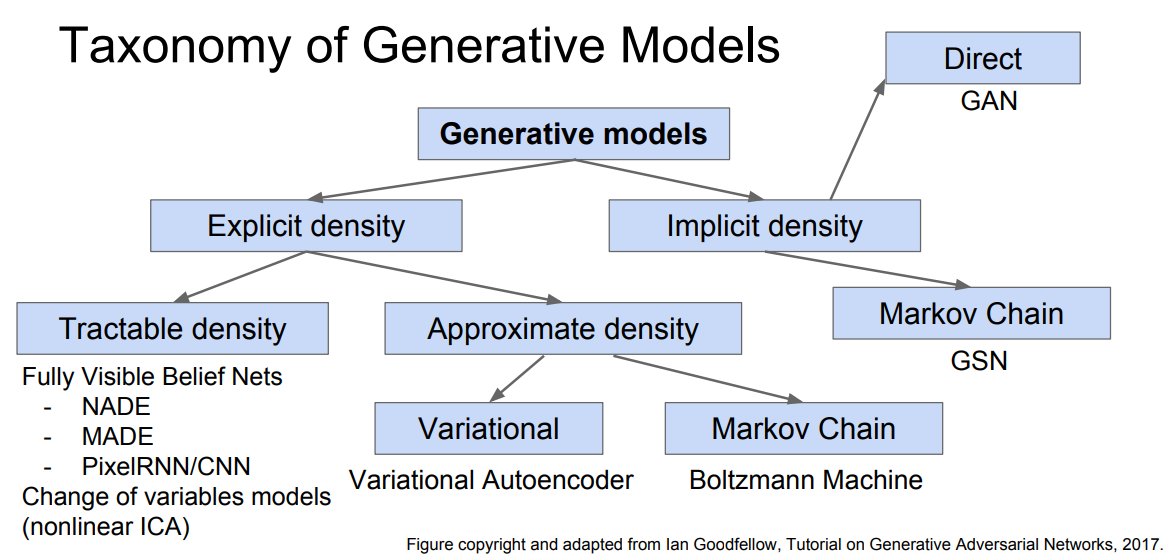
本文将介绍其中的PixelRNN、PixelCNN、VAE、GAN
2. PixelRNN 和 PixelCNN
2.1 定义
这两种网络除了属于显式密度模型,还属于全可见信念网络 (Fully visible belief network),他们以最大化下图所示的似然函数为目标来训练一个模型。
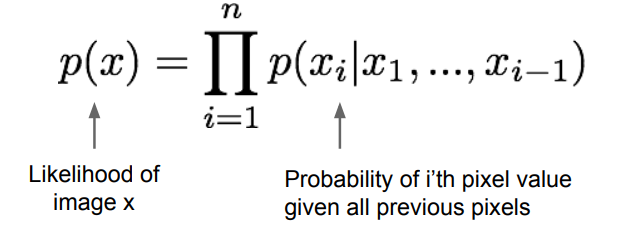
具体解释是:
首先解释这个式子的含义。对于生成一张图像,我们可以按照某个顺序逐一生成每个像素,假设第一个像素生成的概率为
似然和概率的理解不是很好,这里有点理不太清。
由于等式右边的每个像素的条件概率是很复杂的,所以我们可以使用神经网络来表达这些像素的概率分布。而上式提到的条件概率的定义是,给定所有下标小于
2.2 PixelRNN
在 PixelRNN 中,我们定义先后顺序如下:
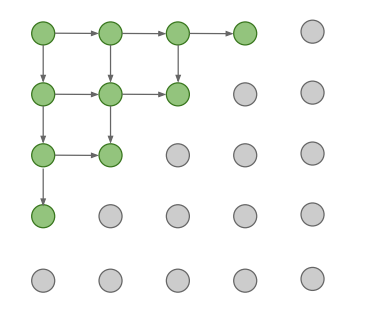
即,从输入图片的某个角落开始,如图中的左上角,然后逐步向右下角逐像素地拓展,由于RNN每个时间步的输出都依赖之前的输入,所以可以使用一个RNN来计算每个像素的条件概率值,一般使用LSTM来进行处理。接着,以最大化似然函数值来更新RNN参数即可。这样的效果不错,但是一个明显的缺点,就是按照顺序逐元素地计算并训练网络是十分慢的,同时在测试阶段,也是按照逐元素地生成像素,所以也会很慢。
2.3 PixelCNN
在 PixelCNN 中,我们也是从某个角落开始向外移动,但会使用CNN来处理元素之间的关系,如下图,灰色区域表示此时已经处理过的像素,当前正在处理黑色位置的像素。此时我们使用一个卷积核,其感受野如下图黑色框所示,这里可以看出,卷积核的感受野不是一个完整的正方形。这是因为,我们条件概率的定义是,以当前像素之前的像素为条件,所以,当前像素之后的像素信息是不能被获取的。这种特殊的卷积可以用一个掩码的方式来实现。由于 Pixel CNN 中计算时只使用到了图像中的像素信息,所以我们其实可以直接并行计算出所有像素的结果(使用矩阵乘法)。而不用RNN那样,受制于序列顺序关系(每次输出结果受上一次的输入影响),一次只能算一个像素。所以,在训练阶段,CNN会比RNN快,但是在测试阶段,CNN同样也是逐像素生成图片,速度依然很慢。
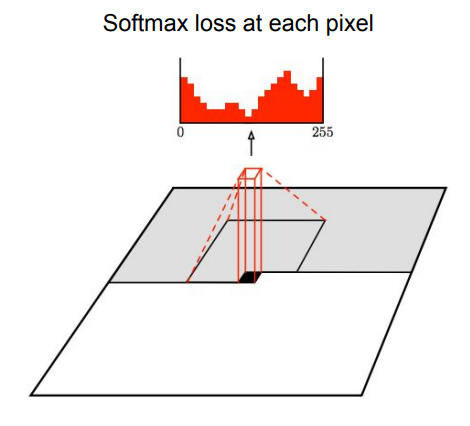
此外,在实现时,使用256个卷积核,在每个位置都会生成256个结果代表像素的0-255的取值,然后就可以当做是个分类问题,使用交叉熵损失函数来优化模型。
如下图是生成的一些图片的效果:

PixelRNN 和 PixelCNN 能显式地计算似然
3. 变分自编码器VAE
本章节部分参考了 北京邮电大学 鲁鹏 的计算机视觉课程
3.1 自编码器
自编码器是为了无监督地学习出样本的特征表示,原理如下:
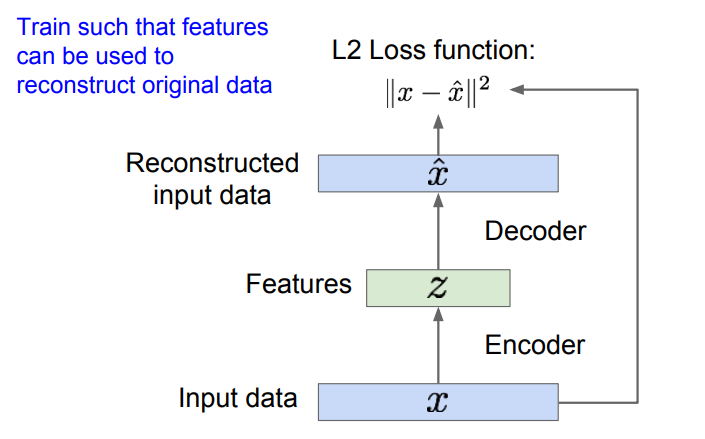
如上图,自编码器由编码器和解码器组成,编码器将样本
编码器可以有多种形式,最先提出的是包含非线性层的线性组合,然后有了深层的全连接网络,后来又使用 CNN,我们通过神经网络对输入数据
解码器主要是为了重构数据,它输出一些跟
训练好完整的网络后,我们会把解码器的部分去掉,使用训练好的编码器实现特征的提取。通过编码器得到输入数据的特征,然后我们就可以使用这些特征训练一个分类器,实现监督学习中的分类任务。
所以,使用无标签数据训练得到的模型,可以帮助我们得到普适特征(比如上述自编码器映射得到的特征),它们作为监督学习的输入是非常有效的(有些场景下监督学习可能只有很少的带标签的训练数据,少量的数据很难训练模型,可能会出现过拟合等其他一些问题),通过上述方式得到的特征可以很好地初始化下游监督学习任务的网络。自编码器具有重构数据、学习数据特征、初始化一个监督模型的能力。这些学习到的特征具有能捕捉训练数据中蕴含的特征的能力,换句话说,通过编码器我们可以获得了一个含有训练数据中变化因子的隐变量
3.2 VAE思想
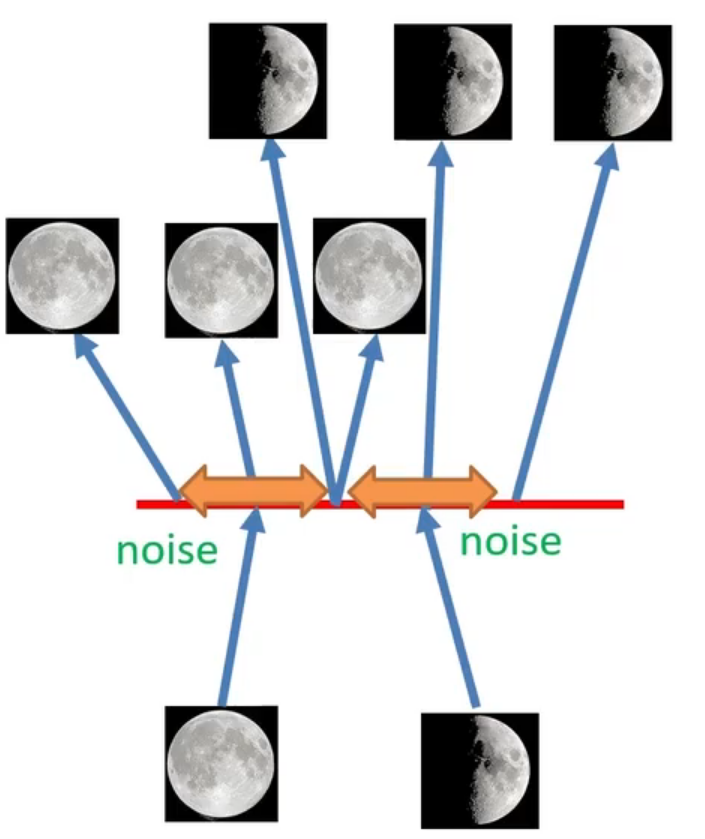
上一节提到我们使用编码器和解码器训练了一个可以提取输入中隐变量的编码器,其中编码器负责提取这个隐变量,解码器负责将隐变量映射回图片,协助模型训练。那么,既然解码器负责生成图片,那么我们能否利用这个解码器,使用随机的编码来生成一些新的图片呢?这不就是本文在讨论的生成模型的任务吗。但是,问题没有那么简单,因为我们训练的神经网络只是稀疏地记录了一对一的映射关系。举个例子,如下图所示。假设使用编码器我们将一张满月和一张半弦月映射成了两个编码(即隐变量
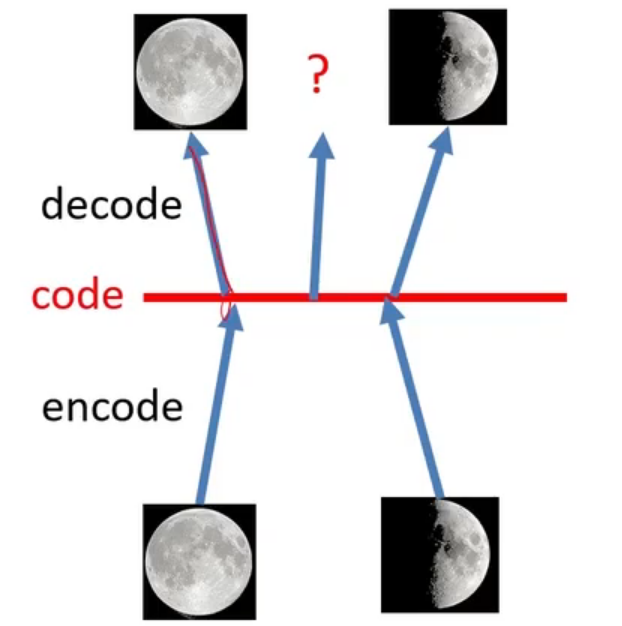
VAE不是直接输出隐变量
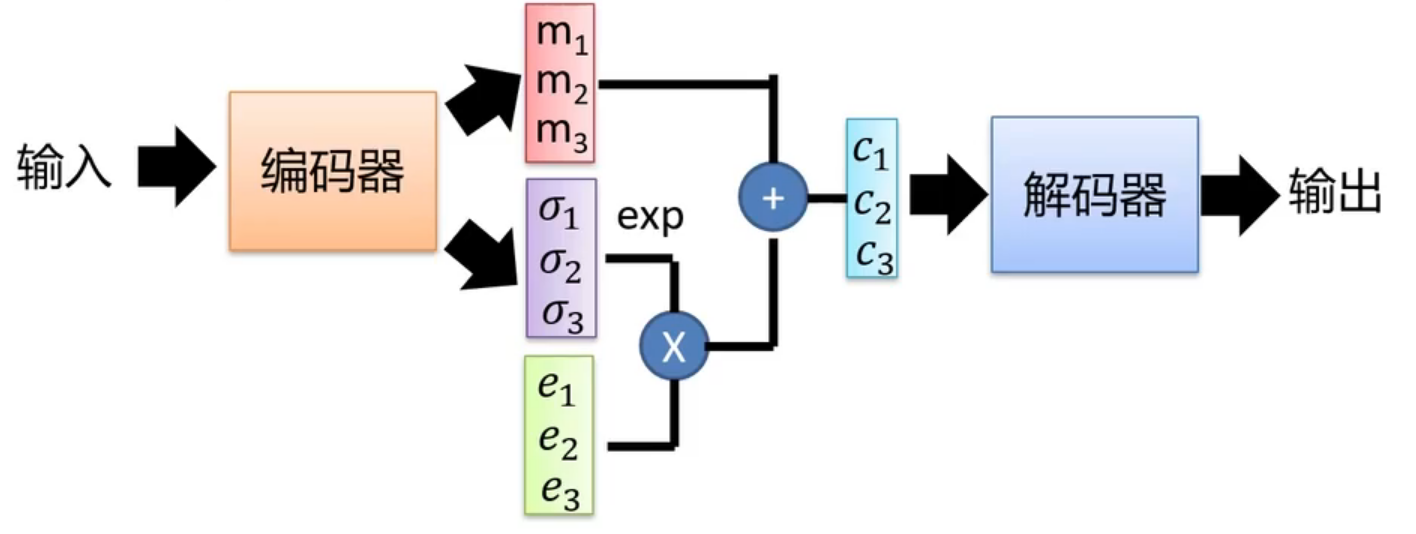
再来看训练过程,如果我们和自编码器一样只使用L2 损失项作为损失函数的话,那么上图所示的模型会退化成一个自编码器,因为模型完全可以将
其中
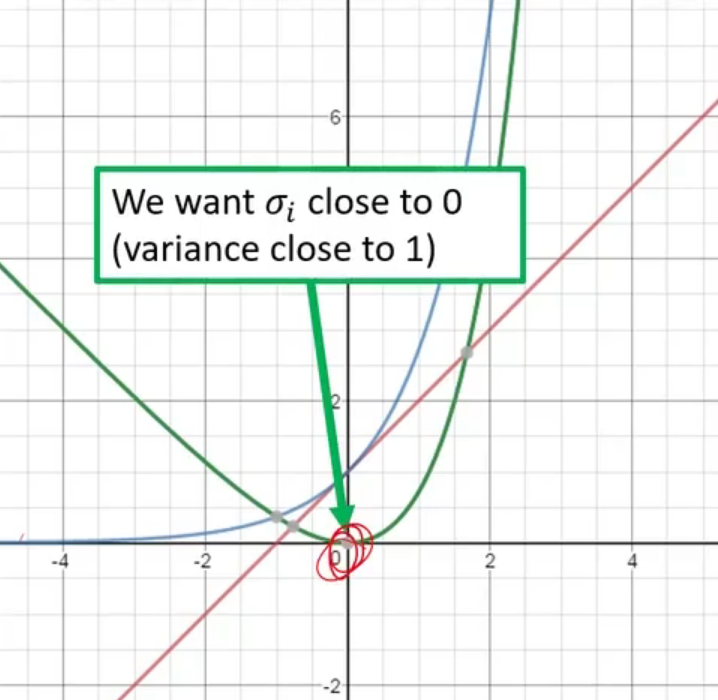
下面再来考虑,为什么VAE先生成概率分布,然后再使用一个噪声从概率分布中采样得到一个编码。如下图,对于一张满月的图,由于现在是一个正态分布,所以原来使用自编码器生成的编码位置的周围一些码空间也会以一定概率被采样用于学习如何生成满月图片,对于半弦月也同理。所以,在半弦月和满月之间的位置会被同时采样用于学习生成满月和半弦月,那么如果我们从这些位置采样,就会生成一张介于满月和半弦月之间的图片,这是因为它即要满足满月的特征,又要满足半弦月的特征。
3.3 VAE推导
本人学习时能力有限,学的比较乱,有些概念和定义理解不是很深刻,以后慢慢填坑吧
混合高斯模型
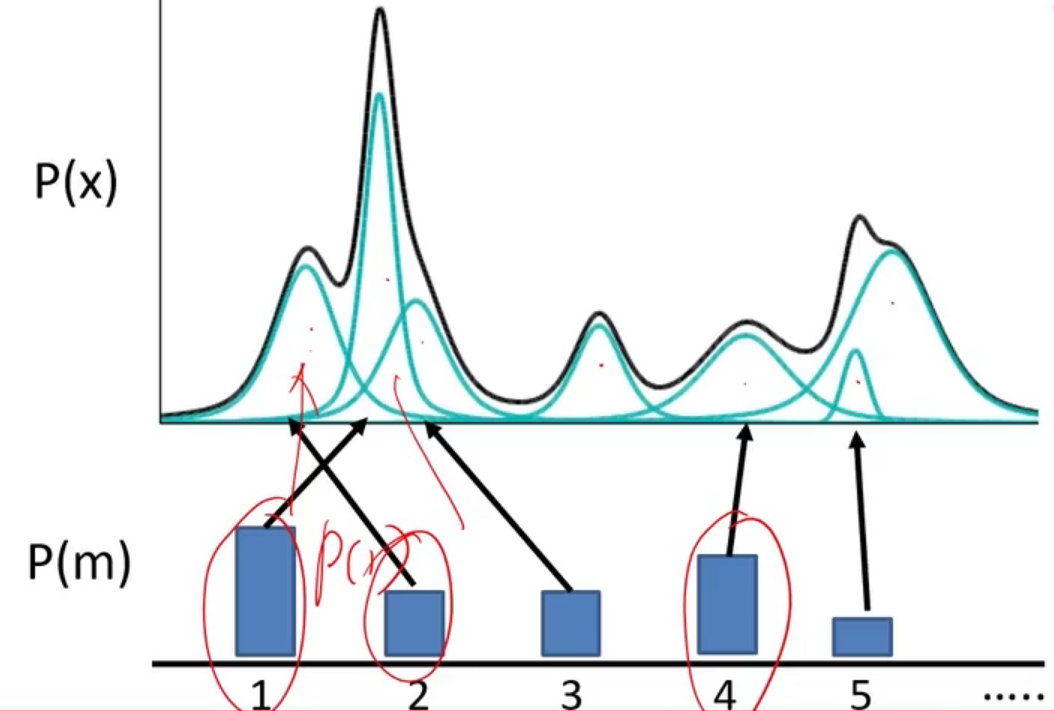
我们可以使用分布来描述一个事物,正态分布(即高斯分布)是一个很经典的分布,自然界很多东西都符合正态分布,但是使用单一的正态分布表达能力有限,于是我们就想到使用多个正态分布组合起来表示,如下图所示,黑色的曲线表示需要去拟合的真实分布,我们可以用若干个高斯分布来共同实现对真实分布的拟合。我们使用
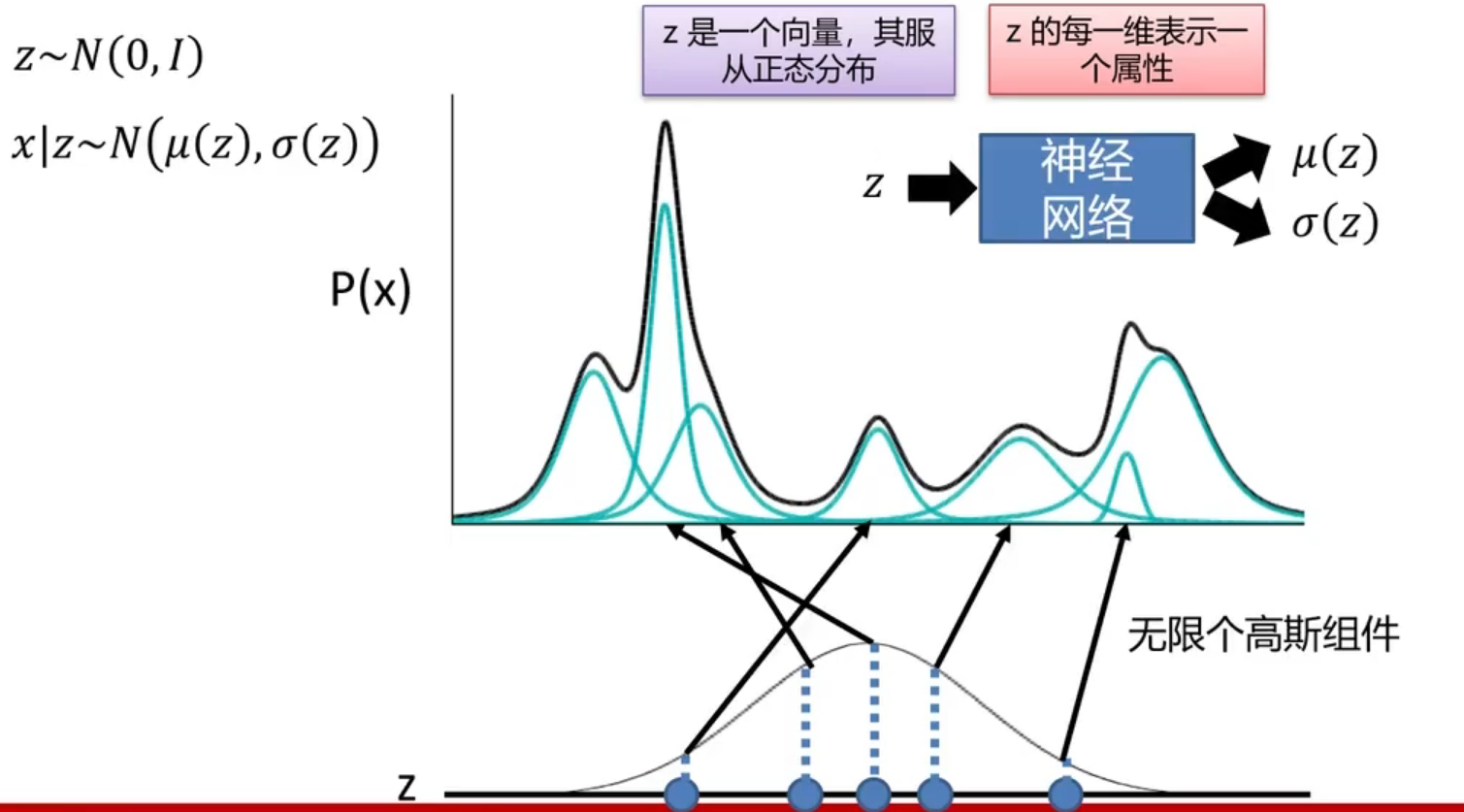
VAE中使用混合高斯模型
首先,我们编码器先获得一个服从正态分布的向量
个人理解,可能就是通过一个CNN提取出一个特征向量(比如1000维的特征向量),然后将特征向量作为输入送入编码器作为
。
极大似然估计
现在,我们就需要寻找一个办法可以来训练这个神经网络使得其对于任意的
其中,
也就是说,我们希望神经网络可以通过更新参数,使得生成的一系列分布,让他们的似然值尽量大,也就和输入数据的真实分布越接近。但是这个式子无法用于求最大值,因为其中的
也就是说,我们如果想要
其中,右边一项等于

3.4 总结
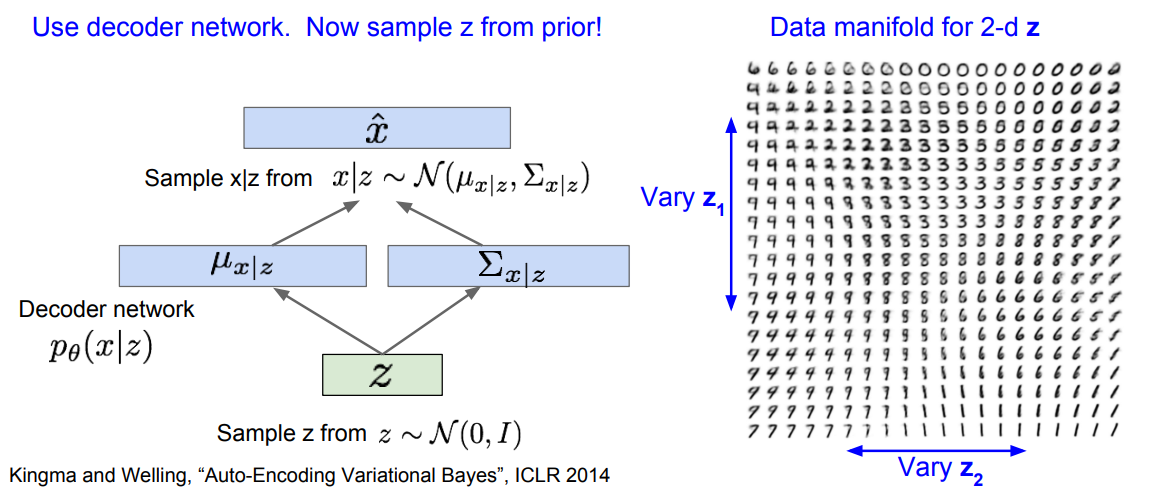
使用VAE训练后,将编码器去除,只保留解码器,于是就可以在码空间中任意取值,解码器就会自动生成图片,如下图所示。

4. 生成对抗网络GAN
GAN 的全称为 Generative Adversarial Nets,它解决了训练样本的分布维度高,难以采样的问题。其解决方法类似VAE,使用一个简单的分布进行采样, 然后使用神经网络学习一种映射可以将其转变到训练样本的分布。
4.1 两个玩家的游戏
在GAN中,有两个神经网络:
- 生成网络:期望能够产生尽量真实的图片,进而欺骗判别器
- 判别网络:期望能够准确地区分真假图片
如下图所示,可以将生成网络比作一个制造伪钞的骗子,而判别网络比作一个验钞机。骗子就期望可以制造尽量逼真的网络骗过验钞机,使得其可以在市场流通。而验钞机则希望,尽可能地能区分出伪钞和真钞。这样一个模型的训练流程是这样的,一开始只有真钱,骗子随机生成一个图片作为假钞送入验钞机,由于验钞机一开始没有辨别真伪的能力,所以认为这个伪钞是真的。当然,这个伪钞会被贴上一个标签来标识这是个伪钞,于是银行系统发现了这个伪钞没有被验钞机识别出来。于是,验钞机学习这个1.0版本的伪钞和真钞之间的区别,更新升级至2.0版本,成功区分出这个1.0版本的伪钞。接着,骗子继续使用同样的方式随机生成一张1.0版本的伪钞,发现无法欺骗验钞机了。于是,骗子也开始升级自己的技术,学习真钞中的特征使得生成的伪钞更接近真钞,于是骗子生成了2.0版本的伪钞,成功骗过了验钞机。验钞机继续学习2.0版本的伪钞和真钞的区别,升级至3.0版本……如此往复,直到骗子的伪造能力非常高超以至和真钞几乎没有区别为止。可以看到,模型的学习过程就是两个网络相互抗衡斗争的过程,这也是GAN中的Adversarial的来源。
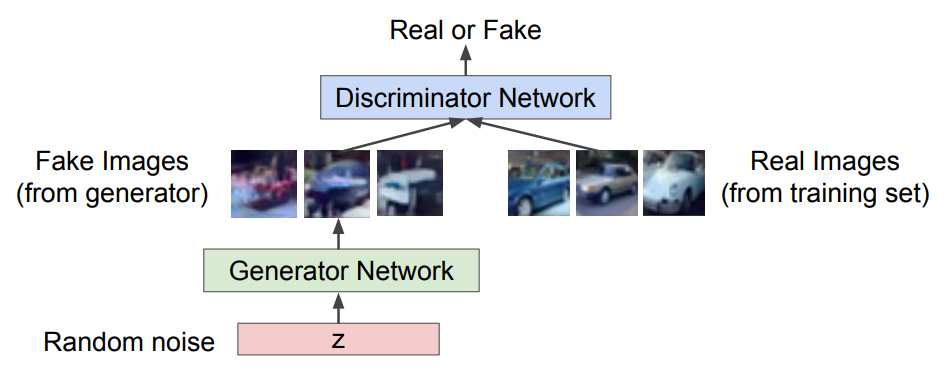
4.2 目标函数
将上述的对抗过程写成数学表达形式,如下所示。其中,
所以,上式的意思我们可以分两步来看:
首先,我们希望通过调整
其次,我们还希望通过调整
总的而言,其训练方式如下:

4.3 训练流程
既然有了目标函数,我们就可以训练模型了,训练过程中,我们将目标函数拆分开交替进行:
- 首先使用 梯度上升 进行
,即训练判别器。一般来说,训练都是以判别器开始的。因为,一开始我们就可以随机生成图片,假设训练集中有1000张图片,那么我们就可以随机生成1000张图片,然后训练判别器使其能够区分这2000张图片即可。 - 然后进行 梯度下降 进行
,即训练生成器。 - 将上述两个过程交替进行即可。
然后实际训练时,对于生成器的训练不会使用 梯度下降 和最小化的目标函数,如下图的蓝色曲线为
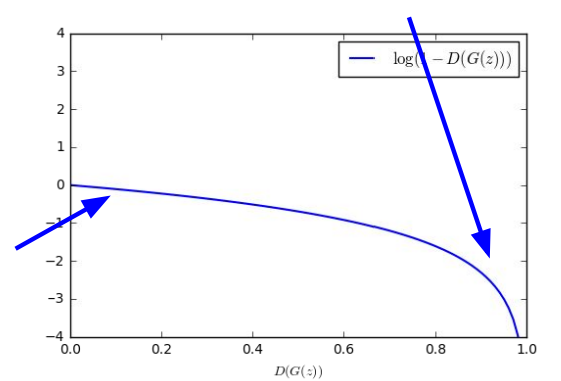
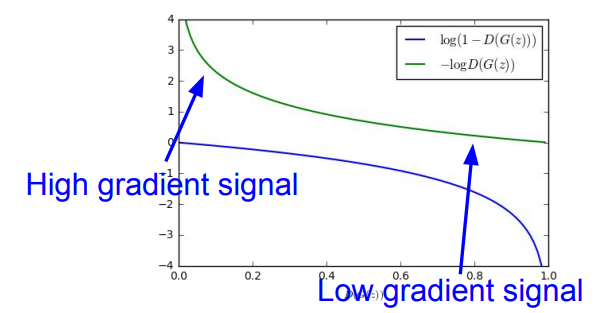
所以,我们会使用下式代替:
其图像如下图绿色曲线所示,它就有很好的特性,即初始时梯度大,最后梯度小,符合训练的需要,实际训练中基本都用这个式子。
4.4 算法描述

4.5 总结


确实,这部分这个小姐姐讲的还不如国内鲁鹏老师讲的好,豁然开朗
确实,BUPT+1分~